33
还是二分,不过对于搜索值target
如果比mid大,那么肯定是要继续往右找的
但如果比mid小,那就没办法判定是往左找还是往右找
或许可以将二分搜索封装成一次函数
每次使用这个函数就是在进行一次二分调查
find
先判定l<r
然后判定mid与target的关系
如果往右找,就是l=mid+1
对于比mid小的情况,展开两个二分搜索
往左搜索的情况:r=mid-1
往右搜索的情况: l=mid+1
对于比Mid大的情况,其实也是不一定的
那如果这样,就只能每个节点,都展开向左和向右的两个搜索方向了
但这样的话,不就退化成On了吗,差不多都搜索了
如何优化


由于保证了元素独一无二,所以不会出现等于的情况
实际上就是判断端点上的值大小情况
l端点值如果小于m的,说明l,m是有序的
不过m可能刚好为旋转前的最大元素,这样的话就刚好划分出两个有序数组
对于tar>nummid的情况
如果左侧是有序的,那就只能往右侧找
不过如果左侧如果不是有序的,那左侧和右侧也不能确定啊,也还是得两侧都尝试寻找
对于tar<nummid的情况
如果左侧是有序的,由于如果右侧也是有序时,mid就是最大值
所以右侧也是有可能存在的
这个时候还是得两侧同时寻找
即左侧如果有序,那就往左侧找
右侧有序,右侧也能找
那这样一句有序性的判断,好像只能实现部分的剪枝?
还是依据有序性,如果左半边无序,右半边有序,那就可以直接看右半边的端点,跟target的关系,如果大于,就说明确实是在右半边,否则就是左半边
这样就只剪枝到一个方向了


这里加个<=还是很有必要的,就是如果l和mid是同一个元素的情况
肯定会发生,如果没有=,那就是否认了l必定不是mid,即否定了区间里只有两个元素的情况
BufferPool
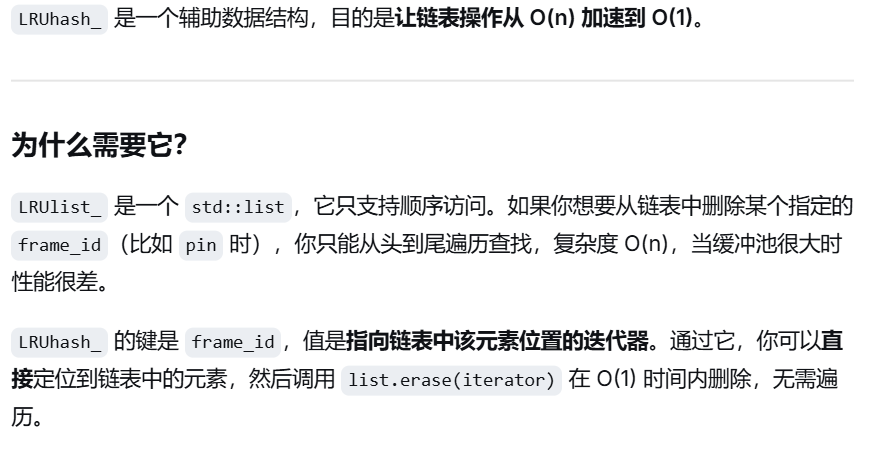
要找到可淘汰帧页的frame_id
这个帧号和页面号,什么关系?在磁盘上的文件,是按页面号划分的,实际的物理地址,页面号
那帧号就是指在内存当中的那个页面号吗?
那如何区分不同的磁盘文件呢?
对于find_victim_page,应该还没有执行删除,就只是寻找可替换的帧
那没有满的时候,就直接从空闲帧链表当中选一个就行,做好链表维护
满的话,就调用repalcer的方法来得到
结果保存到frame_id
对于upadte_page,帧和页面大小是一致的吗?怎么更新,就是从帧里获得数据,然后覆盖掉这个Page吗?"如果是脏页就需要写入磁盘"意思是说每个页维护了两种状态?先不说是怎么维护的,但为什么要写入磁盘?这个页面毕竟还是在Bufferpool当中的,又没有被替换出去,不应该是要被替换出去的时候才写入磁盘?
对于fetch_page,从buffer pool获取需要的页,这个页说到底应该还是指磁盘实际文件当中的那个分页号,如果page_table存在,就是存在一个帧映射到那个物理页,那帧应该就是虚拟页;返回这个虚拟页帧即可;如果不存在,就要找这个page,但是怎么知道去哪个磁盘文件里去找?假设知道,那就是先open这个文件,然后再read;之后就是建立一个新虚拟页帧来维护它,最后返回的是这个物理页面的数据;
unpin_page
new_page,这个新建的page,到底是指虚拟页帧还是磁盘上的物理页?可用的frame是什么意思?就是指还没和磁盘物理页建立联系的空虚拟页帧吗?"在fd对应的文件分配一个新的page_id",怎么知道这个new_page时,对应的是哪个磁盘文件的page?
就是说,难道每个文件,都有一个对应的buffer_pool_manager吗?而不是内存整体的一个BufferPool管理?
就是说,bufferpool是对数据库磁盘文件的一个缓冲,然后frame是磁盘物理文件上的,在内存当中的一个缓冲;frame是内存上的物理页,它的地址是物理地址,再往cpu走就是要虚实转换了
对于find_victim_page,为什么需要这个函数?
如果还有free_list,即可用的frame,那么直接用free_list
没满,直接调用LRU的victiom
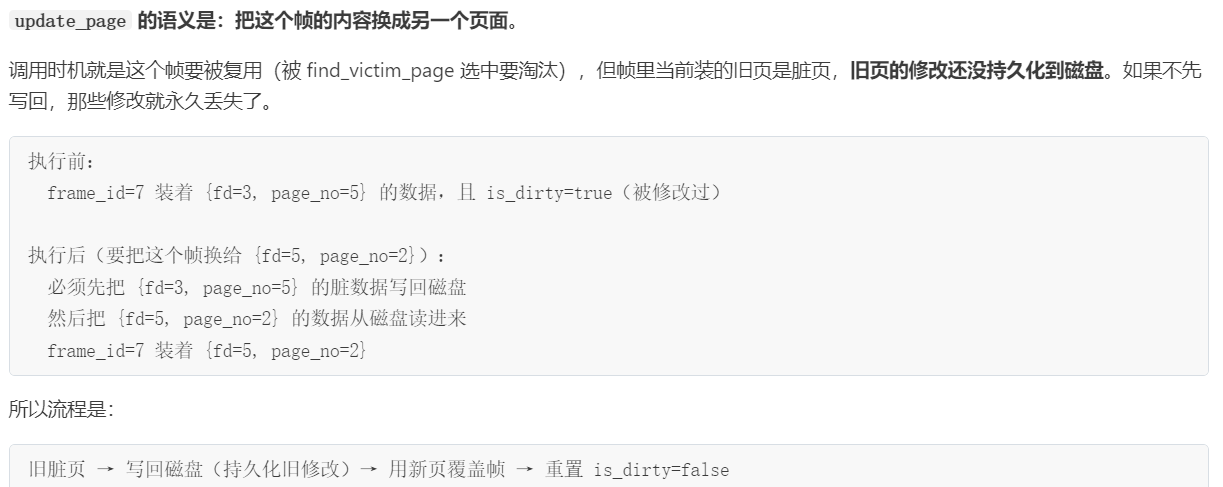
对于update_page,
如何知道是否是脏页?这个page就是原来的页面吗?一整个在磁盘上的物理页,在内存当中的存在?不应该是通过帧号,找到其对应的原来页面号,然后再通过那个页面号找到其原来的物理页吗?
调用这个update方法的,是怎么传入page数据的?
这个方法的参数都是什么意思?什么叫新的frame_id?不一直操作的是同一个frame?
我理解的,这个方法只需要两个参数,即要用的帧的帧号,以及新页面的pageID
先是通过帧号,按我刚才说的那个链条,完成对其旧页面的处理,然后再用pageId找到新页面,完成覆写
那现在三个参数,这个Page?

就是说这个page相当于一个中间数据,在find_victim的时候,承载旧页面,在Update之后,就是新页面,又或者说,这个page就是缓存本身,即frame承载数据的数据结构载体
在bufferPool当中的那个pages_数组是存什么的?bufferPool不是全局的吗?那pages_不应该是所有的帧数据吗?是帧数据吧?在获得数据的时候,也是靠帧号来获得数据的'
对于update_page,对于旧页面的处理,先是把旧页面给写到磁盘里;然后要清除frame和旧页面的映射,即清除frame在page_table_当中的记录,使其为新的page
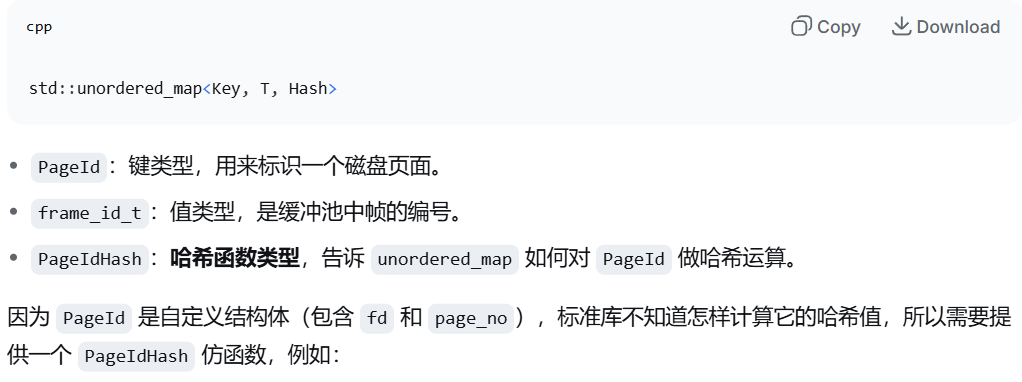
LRU策略
对于vicitim,直接得到list的最后元素,删掉它,并且同步删掉hash当中的数据
对于pin,也是,从list当中查找这个页面号,删掉它,然后同步删掉hash
对于unpin,应该插入,在list当中,在头部插入,然后在hash中同步插入