背景简述
在数据分析和AI应用开发中,数据清洗往往是最耗时、最繁琐 的环节。
常见的数据清洗工作包括格式校验、去重、异常值检测、缺失值填充、格式统一 等一系列任务。但对于大多数非技术人员或业务人员来说,这些工作的门槛并不低------没有编程基础很难高效完成。
更让人头疼的是,现实世界的数据往往是混杂的 :
- 结构化数据 (如CSV表格、数据库导出文件)可能存在日期格式不统一、数值范围异常、字段缺失等问题;
- 非结构化数据 (如PDF报告、抓取的网页文本)则可能包含乱码、冗余信息、格式混乱等挑战;
- 最棘手的是,两种数据交织在一起 ,清洗流程的复杂性呈指数级增长。
单靠一个Agent很难同时兼顾结构化/非结构化数据的质量校验、异常检测与修复协作。正因如此,采用多智能体分工协作 的方式成为破解这一难题的理想选择。
JiuwenSwarm Agent Swarm 的出现,为这一场景提供了新的解题思路。
一、JiuwenSwarm Agent Swarm 核心机制速览
在深入了解数据清洗 Agent 团队的搭建与实战之前,有必要先对 JiuwenSwarm Agent Swarm 的核心机制做一个快速概览。
JiuwenSwarm 是由华为支持的 openJiuwen 开源社区推出的智能 AI Agent 项目,其核心理念是"懂你所想,自主演进"。它在架构上模拟真实团队的协作方式,实现了一套 Agent Swarm 协同机制 :
┌─────────────────────────────────────────┐
│ Leader Agent │
│ • 需求分析 │
│ • 动态团队组建(按需生成角色) │
│ • 任务规划(含依赖关系) │
│ • 关键决策审批 │
└──────────────┬──────────────────────────┘
│ 事件驱动,实时感知进展
┌──────────┼──────────┐
▼ ▼ ▼
┌────────┐┌────────┐┌────────┐
│Teammate││Teammate││Teammate│
│ Agent 1││ Agent 2││ Agent 3│
└────────┘└────────┘└────────┘
│ │ │
└──────────┼──────────┘
▼
共享工作区(协同产出、文件锁定保证一致性)分工体系 :
- Leader Agent :负责任求分析、动态团队组建、任务规划与依赖关系建立。Leader 可根据目标描述动态分配角色 ,执行过程中发现人手不足或方向调整,还可以随时增减成员。
- Teammate Agent :各自领取任务、独立执行 、汇报结果,通过共享工作区 协同产出。
- 事件驱动 :整个过程由事件驱动,Leader 通过事件系统实时感知进展------谁认领了什么、谁完成了什么、谁遇到了问题,关键节点需由 Leader 决策,故障确保可自动恢复 。
更吸引人的是,JiuwenSwarm 支持一句话生成自己的 Agent 团队 。使用者不需要手动创建每个智能体并逐一配置通信规则,只需描述需求,Leader Agent 会自主完成团队组建和任务分配。
二、多智能体数据清洗协作的分工思路
将上述机制映射到数据清洗场景中,我们可以很自然地设计出一套**"按数据类型分工 + 统一汇总修复"的 Agent 团队架构**。
团队构成设计 :
|------------------|------------------|-------------------------------|
| Agent 角色 | 负责数据类型 | 核心任务 |
| 结构化校验 Agent | CSV、Excel、数据库表 | 格式校验、空值/异常值检测、字段类型检查、唯一性约束校验 |
| 非结构化清洗 Agent | PDF、网页文本、图片OCR文本 | 乱码清洗、格式标准化、关键信息提取、去重与摘要 |
| 汇总修复 Agent | 跨类型整合 | 接受前两个Agent的问题报告,按优先级制定修复策略并执行 |
| Leader Agent | 全局 | 分配任务、设定校验规则、监控进度、在关键节点作出决策 |
协作流程 :
- Leader Agent 接收用户的数据清洗需求(可包含自定义校验规则);
- Leader 根据数据类型自动拆分任务,分别下发给结构化校验 Agent 和非结构化清洗 Agent;
- 两个执行 Agent 独立开展工作,各自产出"校验报告+异常清单";
- 汇总修复 Agent 接收两份报告,合并去重异常清单,按优先级排序后执行修复或标记待人工审核;
- Leader Agent 实时监控进展,在关键决策点进行审批,故障自动恢复。
三、数据清洗 Agent 团队的协作流程详解
为了让大家更直观地理解这套流程,我们将其拆解为四个核心环节。
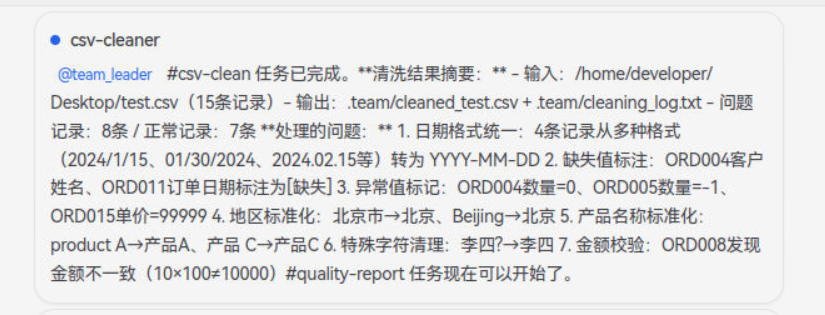
- 任务接收与智能分配
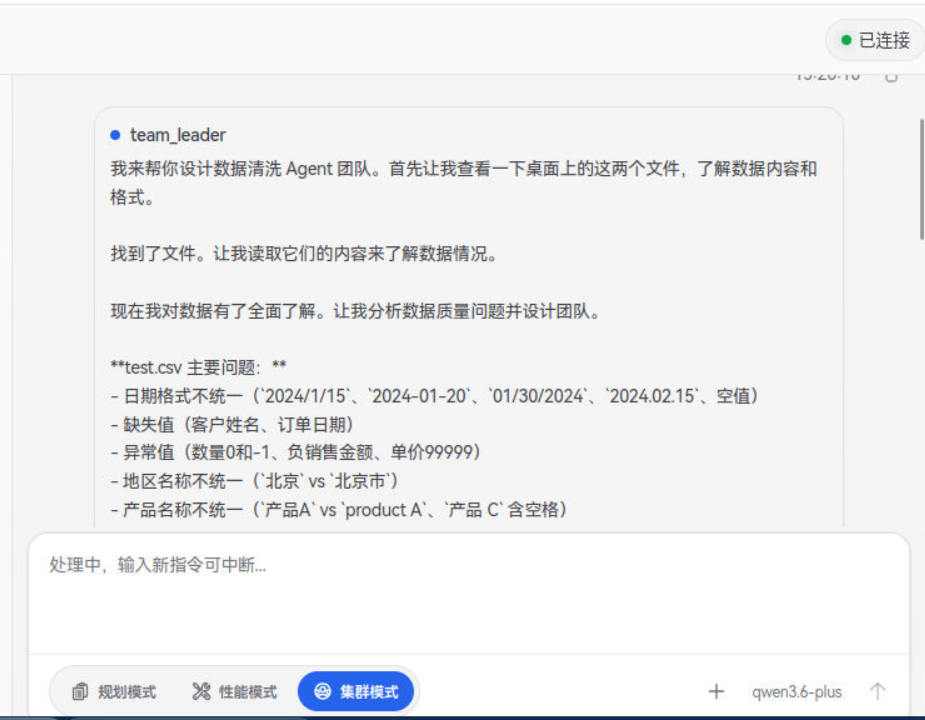
用户向 Leader Agent 提出清洗需求,
例如:"帮我设计一套数据清洗 Agent 团队,去清洗桌面上的CSV销售数据表和一个PDF季度报告,帮我检查数据质量并修正问题"。
CSV销售数据表:
订单ID,客户ID,客户姓名,订单日期,产品,数量,单价,销售金额,地区
ORD001,C001,张三,2024/1/15,产品A,2,100,200,北京
ORD002,C002,李四,2024-01-20,产品B,1,200,200,上海
ORD003,C001,张三,2024-01-25,产品A,3,100,300,北京市
ORD004,C003,,01/30/2024,产品 C,0,150,0,广州
ORD005,C004,王五,2024-02-01,产品A,-1,100,-100,深圳
ORD006,C005,赵六,2024/02/05,产品B,5,200,1000,上海
ORD007,C006,孙七,2024-02-10,产品C,2,150,300,广州
ORD008,C007,周八,2024.02.15,产品A,10,100,10000,北京
ORD009,C001,张三,2024-02-20,产品B,1,200,200,北京
ORD010,C008,吴九,2024-03-01,产品D,4,250,1000,杭州
ORD011,C009,郑十,,产品A,2,100,200,武汉
ORD012,C003,李四?,2024-03-10,产品B,1,200,200,广州
ORD013,C010,冯十一,2024-03-15,product A,2,100,200,Beijing
ORD014,C002,李四,2024-03-20,产品B,2,200,400,上海
ORD015,C011,陈十二,2024-03-25,产品C,1,99999,99999,深圳
2024年第一季 度销售报告:
2024年第一季 度销售报告
一、总体情 况
本季度公司销售业绩良好,总销售额达 5,500 元。与上季度相比增长了 15% 。
二、产品销量分析
产品A:销量 20 件,销售额 2,100 元。
产品B:销量 10 件,销售额 2,200 元。
产品C:销量 3 件,销售额 600 元。
产品D:销量 4 件,销售额 1,000 元。
三、地区分布
华 北地区(北京):销售额占比约35%。
华东地区(上海):销售额占比约25%。
华南地区(广州、深圳):销售额占比约30%。
其他地区(杭州、武汉):销售额占比约10%。
四、问题与建议
部分订单存在数据异常,如 ORD005 出现负销售,需核实。同时发现客户信息不完整,建议完善客户档案。另注:ORD015金额异常高,请财务核实。
五、备注
原始数据文件为:sales_data_q1.csv ,提取自财务系统。如有 疑问请联系数据管理员。
Leader Agent 首先进行需求分析,自动判断:CSV 文件属于结构化数据,应分配给结构化校验 Agent;PDF 或者Text报告属于非结构化数据,应分配给非结构化清洗 Agent。随后 Leader 动态创建对应的 Teammate Agent,并建立任务间的依赖关系(如"两个校验任务完成后,汇总修复才能开始")。
在任务规划过程中,Leader 还会根据用户描述自动提取校验规则------比如日期格式要求、数值合法范围、必填字段列表等------并下发给对应的执行 Agent。
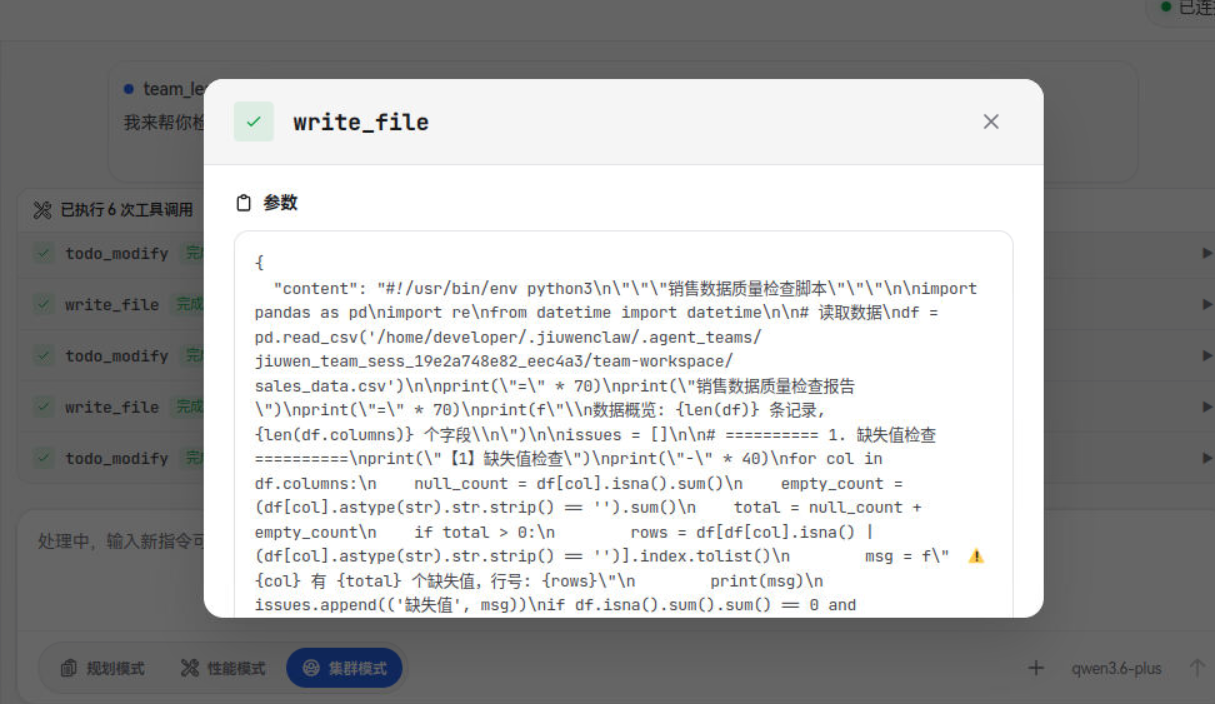
2. 并行执行:结构化与非结构化的分工处理
两个 Agent 各自独立开展工作:
- 结构化校验 Agent 读取 CSV 文件,按规则逐列检查:日期格式是否统一?销售金额是否出现负值?客户ID是否有重复?必填字段是否存在空值?每发现一个问题,就记录到校验报告中,注明行号、列名、问题类型和严重程度。
- 非结构化清洗 Agent 解析 PDF 报告,处理文本提取中的乱码、多余换行、段落断裂等问题。同时检查报告中的数字是否与表格数据一致,提取关键指标供后续交叉验证。

整个过程无需人工干预,两个 Agent 通过共享工作区协同产出,文件锁定机制保证了数据一致性。
3. 异常发现、分级与自动修复尝试
汇总修复 Agent 接收两份校验报告后,对异常进行合并与分级。例如:
- 错误级别 (如数据缺失、格式严重错误):自动标记,尝试调用填充/修正逻辑;
- 警告级别 (如数值略超范围、格式不统一但可读取):记录并附加修正建议;
- 信息级别 (如非关键字段的可疑值):仅记录日志,供人工复核。
部分问题可以自动修复------如将"2024/1/1"统一为"2024-01-01"格式;部分问题则需要Leader审批------如发现某条记录的金额异常偏高,Leader 会将其标记为"待人工审核",并向用户发出提醒。
值得注意的是,JiuwenSwarm 内置了自主演进 机制:当工具调用失败或需求理解错误时,系统会主动记录、分析根因,生成改进建议,由用户决定是否更新相应 Skill,越用越强。
4. 结果交付与可视化输出
最终,汇总修复 Agent 将产出三份成果:
- 清洗后的数据文件 :修正了所有可自动修复的问题;
- 异常处理报告 :列出所有发现的异常、处理方式及待人工审核项;
- 数据质量评分 :对清洗前后数据质量的量化对比。
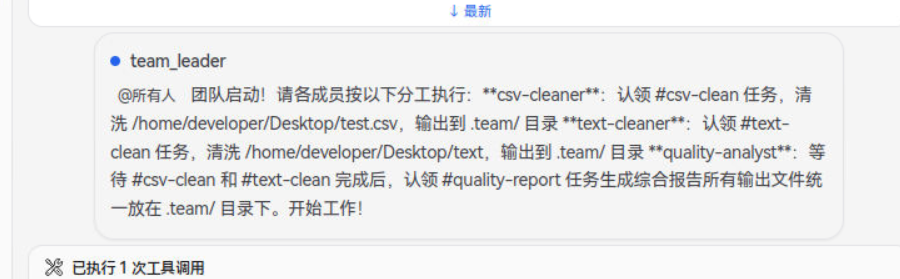
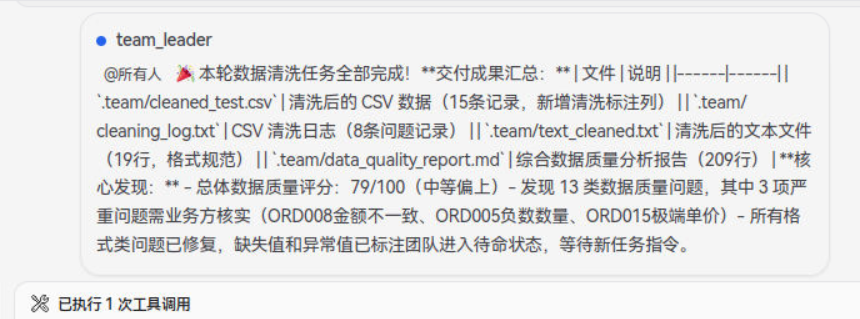
team_leader
本轮数据清洗工作已全部完成!
**📦 交付成果:**
| 文件 | 说明 |
|------|------|
| `.team/cleaned_test.csv` | 清洗后的 CSV 数据(15条记录,新增清洗标注列) |
| `.team/cleaning_log.txt` | CSV 清洗日志(8条问题记录) |
| `.team/text_cleaned.txt` | 清洗后的文本文件(19行,格式规范) |
| `.team/data_quality_report.md` | 综合数据质量分析报告(209行) |
**📊 核心发现:**
**总体数据质量评分:79/100**(中等偏上)
共发现 **13 类数据质量问题**,其中 3 项严重问题需业务方核实:
ORD008 金额计算不一致(10×100≠10000)
ORD005 负数数量(-1)
ORD015 极端单价(99999)
所有格式类问题已修复,缺失值和异常值已标注
团队已进入待命状态,随时可以接收新的数据清洗任务。
整个流程约在数分钟内完成,远比人工逐行检查高效。
四、体验亮点
1. 一句话建团队,零门槛上手
使用者无需编写任何代码,更不必手动配置 Agent 之间的通信规则。只需用自然语言描述清洗需求,Leader Agent 便会自动完成团队组建和任务分配。这让没有编程基础的业务人员也能轻松用上多智能体数据清洗能力。
2. 异常处理的闭环机制
从异常发现、分级、自动修复到人工审批,形成了一套完整的数据质量保障闭环 。特别是 Leader Agent 在关键节点的审批机制,在自动化与人工把关之间取得了很好的平衡。
3. 自演进能力让团队越来越"聪明"
JiuwenSwarm 支持 Skills 自主演进。当清洗过程中遇到新的异常模式,系统会记录并分析根因,生成改进建议,由用户确认后更新相应技能。这意味着你的数据清洗 Agent 团队会随着使用次数的增加而不断进化。
4. 全流程可观测,不再"黑箱"
整个协作过程基于事件驱动,用户可以实时看到每个 Agent 的工作状态、当前进度、遇到的问题。配合上下文压缩(上下文卸载)技术,即使处理大规模数据也不会因为上下文过长而"失忆"。
五、局限性思考与实际应用中的考量
1. 极端复杂数据场景下的可靠性
当数据量极大(如百万行级别)或数据质量问题极为复杂(如跨表逻辑矛盾、隐式语义错误)时,Agent 团队的自动修复能力可能面临挑战。建议在实际应用中,对关键业务数据保留人工复核环节。
2. 对LLM能力的强依赖
Agent 团队的校验规则提取和修复策略生成,本质上依赖底层大语言模型的能力。当底层模型在特定领域知识上存在短板时,可能影响校验准确性。好在 JiuwenSwarm 支持华为云 MaaS 等主流模型平台,可以根据场景灵活切换底层模型。
六、总结
JiuwenSwarm Agent Swarm 在多智能体数据清洗协作中表现亮眼------一句话建团队、分工明确、异常处理闭环、自演进成长 ,大幅降低了数据清洗的技术门槛。
在结构化/非结构化数据质量校验的分工协作上,Leader-Teammate 架构天然适配这一场景:Leader 负责全局调度和关键决策,Teammate 各司其职、并行执行,汇总修复 Agent 完成跨类型整合。整个过程由事件驱动,全流程可观测,关键节点有审批保障。
当然,面对极端复杂的数据场景,它仍有进步空间。但作为一个开源、可自主演进的多智能体协同框架,JiuwenSwarm 已经为数据清洗这一"苦差事"提供了一套足够实用且易于上手的解法。
如果你正在为数据清洗的繁琐流程头疼,不妨给 JiuwenSwarm 一个机会------让它组建一支专属的数据清洗 Agent 团队,看看它能为你省下多少时间。