1. 迁移学习相关概念
(所谓迁移学习:一是 必须有一个预训练模型,二是 必须进行微调;)


1.1 预训练模型 (Pretrained model)
一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型。在NLP领域,预训练模型往往是语言模型。因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的 预训练模型有 BERT,GPT, roBERTa,transformer-XL等。(预训练模型特点:模型结构一般较复杂且是在众多语料下训练好的模型,可拿来直接用)
1.2 微调 (Fine-tuning)
根据给定的预训练模型,改变它的部分参数或者为其新增部分输出结构后,通过在小部分数据集上训练,来使整个模型更好的适应特定任务。
1.3 两种迁移方式
直接使用预训练模型,进行相同任务的处理,不需要调整参数或模型结构,这些模型开箱即用 。但是这种情况一般只适用于普适任务,如:fasttest工具包中预训练的词向量模型。另外,很多预训练模型开发者为了达到开箱即用的效果,将模型结构分各个部分保存为不同的预训练模型,提供对应的加载方法来完成特定目标。
更加主流的迁移学习方式是发挥预训练模型特征抽象的能力,然后再通过微调的方式,通过训练更新小部分参数以此来适应不同的任务。这种迁移方式需要提供小部分的标注数据来进行监督学习。
关于迁移方式的说明:*直接使用预训练模型的方式,已经在 fasttext的词向量迁移中学习。接下来的迁移学习实践将主要讲解通过微调的方式进行迁移学习。
1.4 NLP常见的预训练模型



2. Transformers库的使用
学习目标 :
了解并掌握管道方式完成基本NLP任务
了解并掌握自动模型方式完成基本NLP任务
了解并掌握具体模型方式完成基本NLP任务
(Transformers库是python的第三方库,有训练模型有两种迁移方式:一种开箱即用、另一种在小样本数据集或者垂直领域的业务数据集中做二次开发训练。
开箱即用的预训练模型中有三种方式:① 管道方式、②自动模型方式、③具体模型方式;管道模型最简单,高度封装;Bert模型一般用具体模型方式;后续的大模型可以用自动模型方式;)
2.1 了解Transformers库
2.2 Transformers库三层应用结构
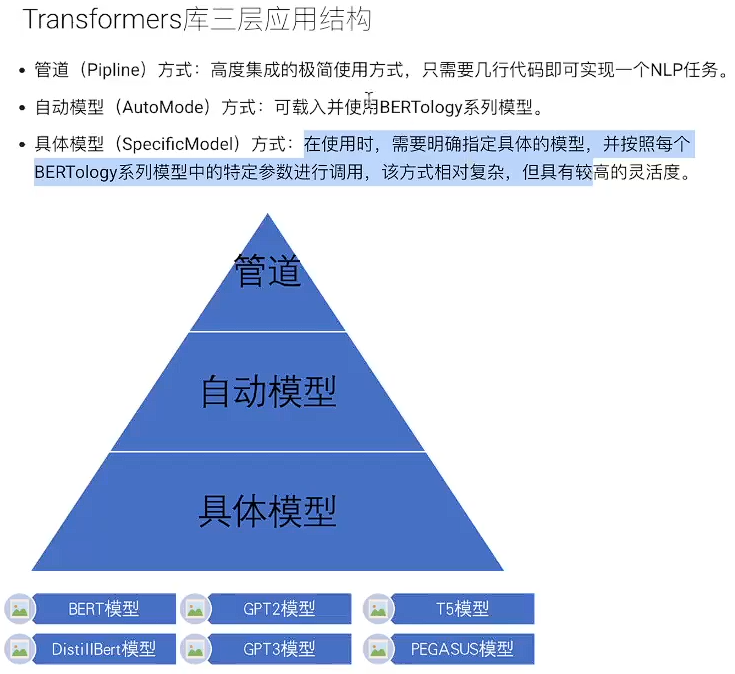
2.3 (方式一) 管道方式完成多种NLP任务
2.3.1 文本分类任务
做文本分类的模型:chinese_sentiment
python
# todo 1.完成情感分析(文本分类)任务
def dm_text_classification():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="sentiment-analysis", model='./model/chinese_sentiment')
# 使用模型进行预测
result = model("我非常喜欢这个模型")
print(f'情感分析预测结果result为:{result}') # [{'label': 'star 5', 'score': 0.610307514667511}]
if __name__ == '__main__':
dm_text_classification()2.3.2 特征提取任务


特征提取任务属于不带任务头的输出,为了把原始句子中每个单词变成词向量,且用 bert系列模型是768维。除了特征提取任务,其它任务都是带任务输出头的,它相当于一个具体的任务,一旦模型出来就直接给结果;所以特征提取任务相当于一种特殊的任务;一般做迁移时第一步要做特征的提取;
原本句子中按字切分,有9个词,输出结果是11。原因是:预训练模型输出的结果,会默认在句子前后加上两个特殊的token,一个是CLS, 一个SEP:CLS代表这个句子的开始、SEP代表这个句子的结束;
做 特征提取任务的模型:bert-base-chinese
python
# todo 2.完成特征抽取任务
def dm_feature_extraction():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="feature-extraction", model='./model/bert-base-chinese')
# 使用模型进行预测
result = model("我非常喜欢这个模型")
print(f'特征抽取result为:{type(result)}') # <class 'list'>
# 预训练模型输出的结果,会默认在句子前后加上两个特殊的token,一个是CLS, 一个SEP
print(f'特征抽取result为:{torch.tensor(result).shape}') # [1, 11, 768]
if __name__ == '__main__':
dm_feature_extraction()2.3.3 完型填空任务

既然叫 遮蔽语言任务,则pipeline中的task='fill-mask';得到模型后对样本进行预测,掩码的token必须是 MASK ,因为模型只认它,会对这个位置进行预测,写其它的会报错;一次只能预测出一个mask,如果想预测后面的,可使用for循环;
做完形填空的模型:chinese-bert-wwm
python
# todo 3.完成完形填空任务
def dm_fill_mask():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="fill-mask", model='./model/chinese-bert-wwm')
# 使用模型进行预测
result = model("我想明天去[MASK]家吃饭")
print(f'完形填空任务result为:{result}')
if __name__ == '__main__':
dm_fill_mask()2.3.4 阅读理解任务
阅读理解任务又称为"抽取式问答任务",即输入一段文本 和一个问题 ,让模型输出结果 。
做阅读理解的模型:chinese_pretrain_mrc_roberta_wwm_ext_large
python
# todo 4.完成阅读理解(QA)任务
def dm_qa():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="question-answering", model='./model/chinese_pretrain_mrc_roberta_wwm_ext_large')
# 准备语料
context = '我叫张三,我是一个程序员,我的喜好是打篮球。'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']
# 使用模型进行预测
result = model(context=context, question=questions)
print(f'阅读理解任务result为:{result}')
if __name__ == '__main__':
dm_qa()运行结果 :start起始索引,end结束索引,包左不包右

2.3.5 文本摘要任务
摘要生成任务的 输入一段文本 ,输出是一段概况、简单的文字 。做摘要的模型:distilbart-cnn-12-6
python
# todo 5.完成文本摘要任务
def dm_summary():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="summarization", model='./model/distilbart-cnn-12-6')
# 准备文本送给模型
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."
# 使用模型进行预测
result = model(text)
print(f'文本摘要任务result为:{result}')
if __name__ == '__main__':
dm_summary()2.3.6 NER任务
2.3.6.1 什么是 命名实体识别NER?
1. 命名实体 :通常我们将人名,地名,机构名等专有名词统称命名实体 .如:周杰伦,黑山县,孔子学院,24辊方钢矫直机.
2. 命名实体识别(Named Entity Recognition,简称NER ):就是识别出一段文本中可能存在的命名实体 ;
3. 命名实体识别的作用:同词汇一样,命名实体也是人类理解文本的基础单元,因此也是AI解决NLP领域高阶任务的重要基础环节;
2.3.6.2 NER任务
实体词识别(NER)任务是NLP中的基础任务。它用于识别文本中的人名(PER)、地名(LOC)、组织(ORG)以及其他实体(MISC)等。例如:(王B-PER)(小I-PER)(明I-PER)(在0)(办B-LOC)(公H-LOC)(室H-LOC)。其中0表示一个非实体,B表示一个实体的开始,I表示一个实体块的内部。
实体词识别本质上是一个分类任务(又叫序列标注任务),实体词识别是句法分析的基础,而句法分析优势NLP任务的核心。
(如对于一段话 "我是张三,我来自北京":有两个实体:人名(张三)、地名(北京);
模型如何预测 "张三"是人名、"北京" 是地名?:首先其核心目标是对每个 字 打标签 :B-person、I-person、B-location、I-location、O:B即Begin代表实体的开始、I既代表中间也代表结尾、O什么类型都不属于 它不属于一个实体:对于句中的 "我是"、 ","、 "我来自"都会标记为O;"张"会标记为 B-person、"三" 会标记为 I-person;即模型会对每个字打标签(再组装起来),打完标签后自行规则匹配,找到以B开头的 一定是实体开头、再根据后面的注释判断是人名还是地名;实体词识别本质上是一个分类任务(又叫序列标注任务),即给定一段话,对序列中的每个字都要进行标注,不用分词,直接对字进行标注 。)
NER命名实体识别任务 使用的模型是:roberta-base-finetuned-cluener2020-chinese
python
# todo 6.完成NER任务
def dm_ner():
# 调用piepline方法,返回的是模型的对象
model = pipeline(task="ner", model='./model/roberta-base-finetuned-cluener2020-chinese')
# 准备文本送给模型
text = "我是张三,我来自北京"
# 使用模型进行预测
result = model(text)
print(f'NER 任务result为:\n{result}')
if __name__ == '__main__':
dm_ner()2.4 (方式二) 自动模型完成多种NLP任务
2.4.1 文本分类任务
文本分类是指模型可以根据文本中的内容来进行分类 。例如根据内容对情绪进行分类,根据内容对商品分类等。文本分类模型一般是通过有监督训练得到的。对文本内容的具体分类,依赖于训练时所使用的样本标签。(对一段话或一个样本给它打上一个类别标签,大多是单标签多分类任务;)
代码分析:
① 加载分词器 :AutoTokenizer.from_pretrained(...):from_pretrained来自预训练,所有的模型加载分词器时都使用此命令,来加载模型路径名,得到一个分词器对象;② 加载模型 :因为做情感分类任务,使用模型 AutoModelForSequenceClassification.from_pretrained(...)对句子分类;③ 将文本送入模型 ,但不能直接送,my_tokenizer.encode(...)必须先经过分词器的处理将其先转成张量才能送给模型 ,得到模型处理结果:即对于tokenizer的使用,都用的是一个方法即encode()编码方法对原始句子进行处理:先分词,再转成数字形式;my_tokenizer.encode(text=sentence, return_tensors='pt', padding="max_length", truncation=True, max_length=20):return_tensors='pt'即返回张量,pt pytorch-tensor返回pytorch框架中的一个张量;padding填充;truncation截断,max_length最大句子长度,即设置完最大句子长度后会进行比较在进行补齐或截断;return_tensors='pt'返回的是张量、max_length设置最大句子长度、padding按照最大句子补齐、truncation按照最大句子长度截断; (使用预训练模型会自动在结果前后加上两个特殊token:CLS和SEP,对应的index分别是101、102;)
python
import torch
from transformers import AutoModel, AutoConfig, AutoTokenizer
from transformers import AutoModelForSequenceClassification
# todo:1.文本分类任务
def dm_text_classification():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained('./model/chinese_sentiment')
# 2.加载模型
my_model = AutoModelForSequenceClassification.from_pretrained('./model/chinese_sentiment')
# 3.准备语料
sentence = '人生该如何起头'
# 4.需要将原始的语句进行tokenizer
# 4.1 将my_tokenizer.encode(sentence)结果转换成张量
# result = my_tokenizer.encode(sentence)
# tensor_x = torch.tensor([result])
# 4.2 直接返回张量的结果
# padding="max_length"按照最大长度补齐 max_length最大句子长度,
# truncate=True按照最大句子长度截断,return_tensors='pt'返回的是张量
tensor_x = my_tokenizer.encode(sentence, return_tensors='pt', padding="max_length", truncation=True, max_length=20)
print(f'文本分类任务 输出结果为:{tensor_x}')
print(f'文本分类任务 输出结果形状为:{tensor_x.shape}')
# 预测时,如果用到类预训练模型:加上 eval()
my_model.eval()
# 5.将上述的 tensor_x[1,9] 送入模型
output = my_model(tensor_x)
print(f'文本分类任务 输出结果为:{output}')
print(output["logits"])
print(output.logits)
# 预测最终类别对应的索引
idx = torch.argmax(output.logits, dim=-1).item()
print(f'文本分类任务 最终类别对应的索引为:{idx}')
if __name__ == '__main__':
dm_text_classification()运行结果:
使用预训练模型会自动在结果前后加上两个特殊token:CLS和SEP,对应的index分别是101、102;
当max_length=20时:源文本长度加首尾2个token,再在后面全部补0 ;当max_length=5时:截断源文本 7,最终结果长度为5(包含cls、sep两个词,一共长度为max_length) ,即原文本截掉4位长度;

2.4.1 my_model.eval() 和 with torch.no_grad()
预测时,如果使用到了预训练模型 ,需要加上 eval()即my_model.eval()评估模式;(这里在测试时,相当于别人训练好的模型 ,重新加载 再进行预测。之前用的较多with torch.no_grad(): 两者效果等价;但有不同:with torch.no_grad()使用场合无限制,但eval()一般是用到预训练模型时使用 ,因为预训练模型里面有两个重要点:① 只要模型中用到了dropout随机失活,② 模型用到了Linear Norm规范化,必须要加上 eval(),因为它的关键作用是不更新记录;关键点在于:
① 因为在训练时是需要让模型dropout随机失活 防止过拟合的,但是一旦模型训练完,神经元就不能失活了,因为里面每个神经元的权重都是有的,只是权重大小不同;所以说 加了eval之后,随机失活的功能才会失效,才能保证每个神经元都能参与预测的过程; ;
如图:每迭代一个样本 随机失活神经元(假如1个);随机失活的核心思想是集成学习:如 对于第一个样本,第2个神经元失活起效果了,其权重为0;第2个样本则第3个样本起作用了,其权重为0,但其它神经元又好了;所以可相当于不同的模型融合在一起,最终得到一个很好的效果,叫做集成学习;dropout的底层思想就是机器学习中的集成学习;一旦模型训练完,神经元就不能失活了,因为里面每个神经元的权重都是有的,只是权重大小不同;所以说加了eval之后,随机失活的功能才会失效,才能保证每个神经元都能参与预测的过程;② 因为在训练时要进行linear Norm规范化,它有标准值和方差,为了让测试集也要符合训练集语料的均值和方差,用eval后可以让语料按照linear norm,之前训练的标准来执行 ;
因此,只要模型中涉及到 dropout层和norm标准化层 必须加上eval(),否则会导致结果不断发生改变,每次预测的值都不一样;
为了方便可以将my_model.eval()和 with torch.no_grad()两个都写上。
之前做的案例人名分类器、英译法案例都没用到eval,因为案例中没用到dropout或linear norm,只是在搭建transformer模型时有用到,现在的预训练模型内部都用到了dropout和linear norm;my_model.eval()计算梯度,但不更新 不参与运算;而 with torch.no_grad()连梯度都不计算;我们之前使用torch.no_grad()是为了节约内存,因为model.eval()计算梯度但不参与运算,那么计算完的结果保存到缓存或者内存当中;