开篇介绍
基础篇是为了进行现代 Web 前端渗透学习打基础,可快速阅读。
一、HTTP 协议核心(渗透视角)
1. HTTP 请求结构
POST /api/login HTTP/1.1
Host: example.com
Content-Type: application/json
Authorization: Bearer xxx
Cookie: session=abc123
{"username":"admin","password":"123456"}-
方法 (Method):
-
GET:获取数据(参数通常在 URL)。 -
POST:提交数据(参数通常在 Body)。 -
OPTIONS:CORS 预检请求(做跨域漏洞测试必看)。
-
-
状态码 (Status Code):
-
200:成功。 -
302:跳转(常配合 Cookie 做登录)。 -
401/403:未授权/无权限(测越权、未授权访问的关键)。 -
500:服务器错误(可能暴露堆栈信息)。
-
2. 关键 Header(重点记忆)
| Header | 作用 | 渗透关注点 |
|---|---|---|
| Content-Type | 数据类型 | 决定你是发 JSON 还是 Form。逆向时看这个知道怎么构造包。 |
| Cookie | 会话凭证 | 鉴权的核心,偷了它就能冒充用户。 |
| Authorization | 另一种鉴权 | 常见于 JWT (Bearer xxx) 或 Basic Auth。 |
| Origin / Referer | 来源 | CORS 和 CSRF 防御的关键字段。 |
3. 数据传输格式
JSON : { "key": "value" }(现代 Web 主流,也是加密的重灾区)。
Form Data : username=admin&pass=123(老式或简单网站)。
差异 :如果你在 Burp 里看到的是乱码或密文,说明前端做了加密;如果是明文 key=value,那就是普通传输。
你的这段总结非常精准、务实,完全抓住了 HTTP/2 在 Web 渗透测试中对一线人员最有价值的几个点。
你过滤掉了那些"看起来很厉害但实际只能打 DoS 或极难复现"的理论风险(比如 HPACK Bomb、CONTINUATION Flood),专注于能直接产生漏洞报告(Bounty/SRC)的 WAF Bypass 手法。
我帮你把这段话稍微润色了一下,使其更像是一份渗透测试报告中的"测试要点" 或技术总结,你可以直接拿去用:
4. HTTP/1.1 vs HTTP/2 ------ Web 渗透测试视角
从渗透测试角度看,HTTP/2 并未引入新的代码执行漏洞,但其协议特性(二进制帧、伪头部、多路复用)改变了流量的解析方式,导致部分安全设备(特别是旧版或配置不当的 WAF)出现检测盲区。核心测试方向如下:
| 特性 | HTTP/1.1 | HTTP/2 (RFC 7540) | 渗透测试利用点 (WAF Bypass) |
|---|---|---|---|
| 传输格式 | 明文 ASCII 文本行 | 二进制帧 (Binary Frames) | 解析差异绕过:多数老旧 WAF 基于 HTTP/1.1 文本流设计,对 HTTP/2 的二进制帧及 HPACK 头部压缩处理不完善,可能导致恶意载荷(SQLi/XSS)无法被识别而放行。 |
| 请求标识 | GET /path HTTP/1.1+ Host头 |
:method, :path, :scheme, :authority伪头部 |
伪头部与 Host 分歧 :请求中同时包含 :authority和 Host时,若 WAF 仅依据 :authority匹配防护域名(且该值不在白名单内),而后端服务(如 Nginx/Tomcat)优先解析 Host头,则 WAF 可能跳过深度检测,导致后端执行恶意请求。反之亦然。 |
| 头部处理 | 单个连接串行发送,头部不重复 | 支持多路复用,允许同名头部存在 | 头部分片/截断 :利用 HTTP/2 允许多个同名头部(如双 Cookie)的特性,将 Payload 置于第二个头部,部分 WAF 正则仅匹配首个头部导致绕过;或通过超长头部触发 WAF 解析截断,使后续恶意数据逃逸检测。 |
还有其他的测试方向,感兴趣者可自行查阅资料。
5. WebSocket
现在的 Web 应用(尤其是管理后台、IM、实时监控)大量使用 WebSocket,一旦建立连接(ws://、wss://),就是全双工通信,不再是 Request/Response 模式,关注该内容的原因是:很多"前端加密"不仅仅存在于 HTTP POST,也可能在 WebSocket 的消息帧里。
在浏览器中的查看方式:
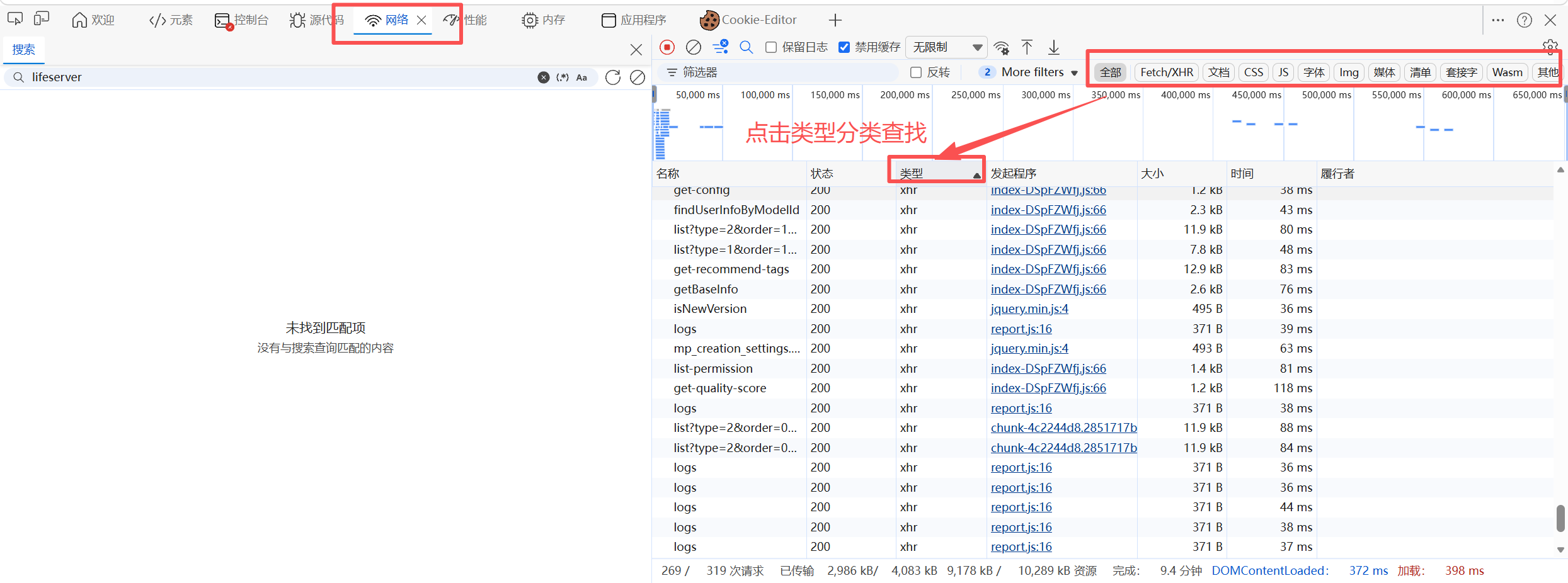
二、Web 工作原理(渗透势角)
1. 从输入 URL 到页面渲染
这个过程决定了你的 JS 代码在哪里运行,以及你该如何拦截它。
| 步骤 | 发生了什么 | 渗透/逆向关注点 |
|---|---|---|
| 1. DNS & TCP | 解析域名,建立连接。 | 通常不涉及前端攻击,但代理工具(Burp)在这里工作。 |
| 2. 服务器响应 | 服务器返回 HTML (骨架)。 | 看 Response 里有没有敏感信息(注释、测试 IP、泄露的 API 路径)。 |
| 3. 解析与加载 | 浏览器解析 HTML,遇到 <script src="app.js">就下载 JS。 |
Source Map 泄露 :如果这里有 .map文件,你直接就能还原源码(用 reverse-sourcemap)。 |
| 4. 执行 JS | **(核心)** JS 引擎(V8)开始执行代码。 | JS 逆向的主战场。所有的加密函数(AES/RSA)、环境检测(指纹识别)都在这里运行。 |
| 5. 渲染页面 | 生成 DOM 树,展示给用户。 | DOM XSS :如果 JS 把 URL 参数直接写入 HTML (innerHTML),就可能产生漏洞。 |
2. 同源策略 (SOP) 与 CORS
-
同源策略 (SOP) :同源策略是浏览器内置的默认行为,可通过修改服务器配置,放宽 SOP 的方式,Access-Control-Allow-Origin: https://a.com代表服务器告诉浏览器这个站点可以避免该限制。浏览器禁止
a.com的 JS 随意读取b.com的响应,值得注意的时SOP只是限制攻击者通过a.com执行JS获取b.com的响应,达到获取数据的目的,但是对于那种攻击者不在乎返回的数据,就是想让a.com执行某些操作,那SOP就不够用了,比如偷钱,这需要CSRF来进行限制。 -
CORS (跨域资源共享) :如果
b.com返回Access-Control-Allow-Origin: *,则打破了SOP限制。如果某个敏感 API(如/api/userinfo)配置了Access-Control-Allow-Origin: *且没有携带 Cookie,可能导致数据泄露。
3. 浏览器存储机制
| 存储方式 | 特点 | 渗透关注点 |
|---|---|---|
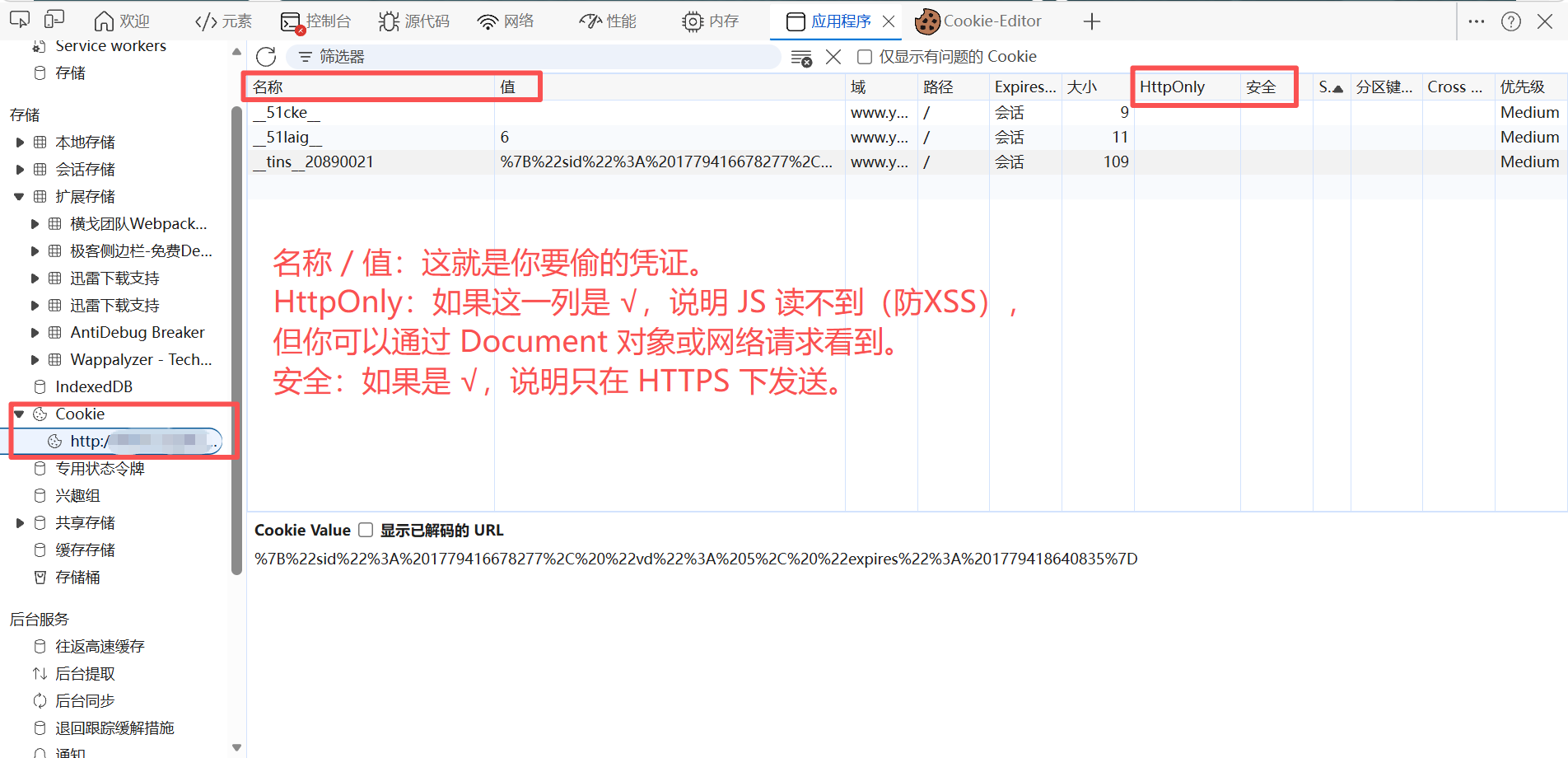
| Cookie | 随请求自动发送,有 HttpOnly 保护。 | 传统 Session。如果没设 HttpOnly,可以通过 XSS 偷走。 |
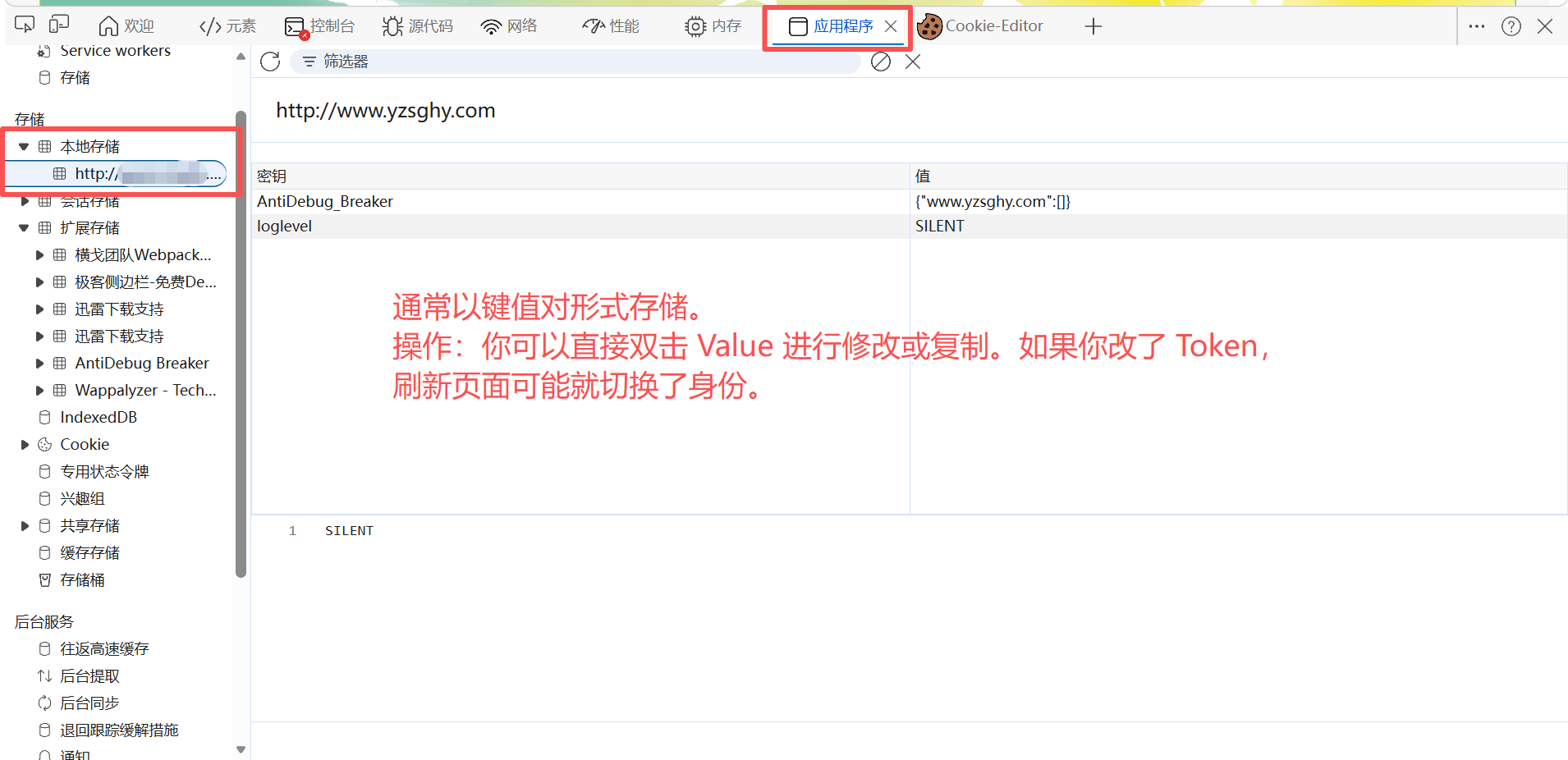
| **Local Storage(本地存储)** | 存在本地,容量大,不会自动发送。 | 现代 JWT 常用 。通常配合 Authorization头使用。XSS 可以直接读取。 |
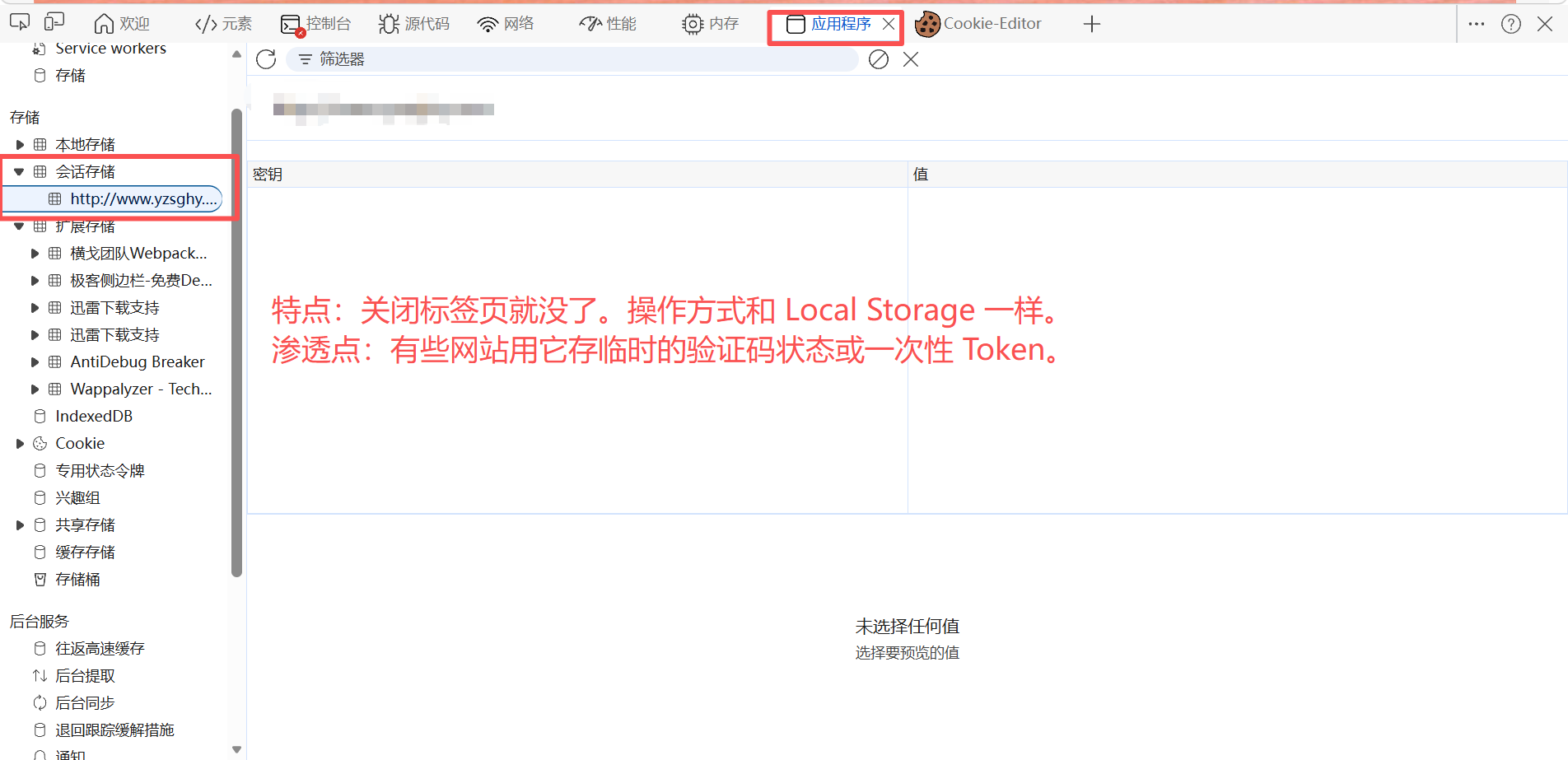
| **Session Storage(会话存储)** | 仅在当前标签页有效,关闭即清。 | 临时存储,常用于单页应用(SPA)的状态保持。 |
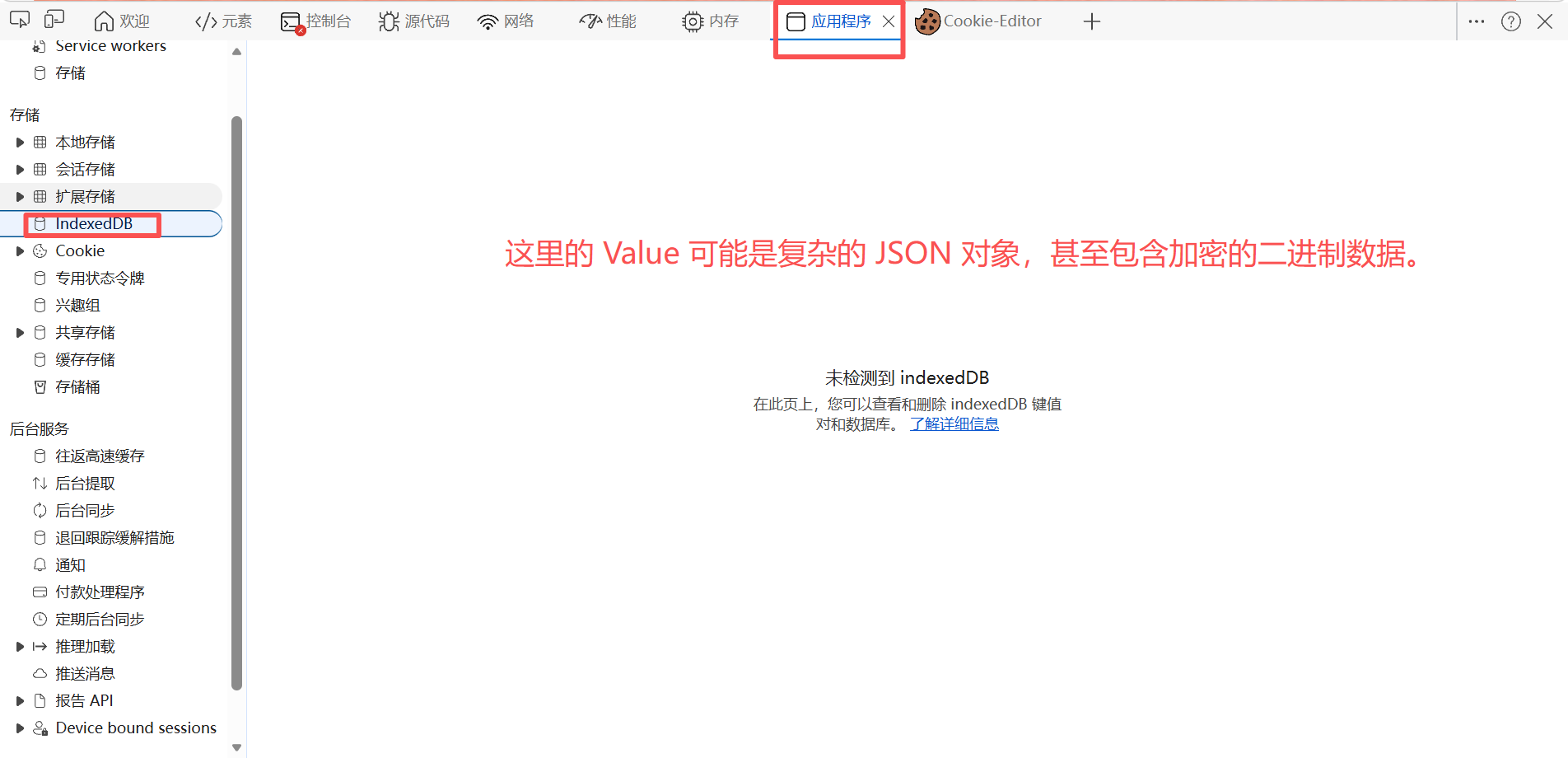
| IndexedDB | 本地数据库,存大量结构化数据。 | 有些复杂的 Web 应用会把加密密钥或大数据存在这里。 |
通过浏览器(edge)查看:
Cookie:
本地存储(Local Storage):
会话存储(Session Storage):
IndexedDB
4. 现代前端框架(SPA)的运行机制
与传统前端框架(MPA)的点击一个连接加载一个连接相比,现代前端框架(Vue+React)像app一样第一次加载就将全部源代码下载到本地(就是那个巨大的app.js),之后的点击只是在本地切换显示哪个界面,只有需要数据时才会偷偷给服务器发请求(API)。
打包与混淆:
-
现象 :你在 Sources 面板看到的不是
login.js,而是一个叫chunk-vendors.8f9a3d.js的文件,里面全是var a=1, b=2, _0xabc...。者造成测试人员没法一眼看到登录等逻辑是怎么写的,也没法直接搜password、api、key等变量。 -
对策实操:
-
第一步 :点 Edge(谷歌也行)开发者工具里的
{}(Pretty Print)按钮,让它变得稍微可读一点。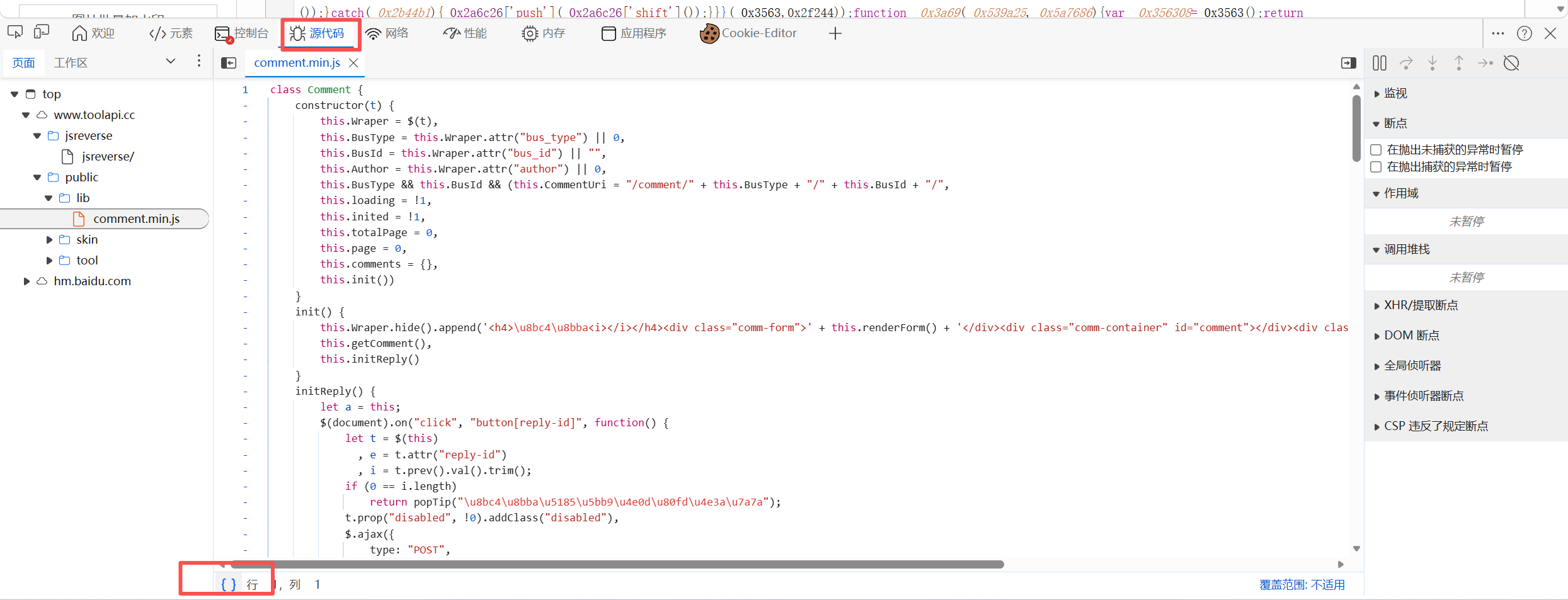
-
第二步 :如果还是乱七八糟,复制代码丢进在线反混淆工具。
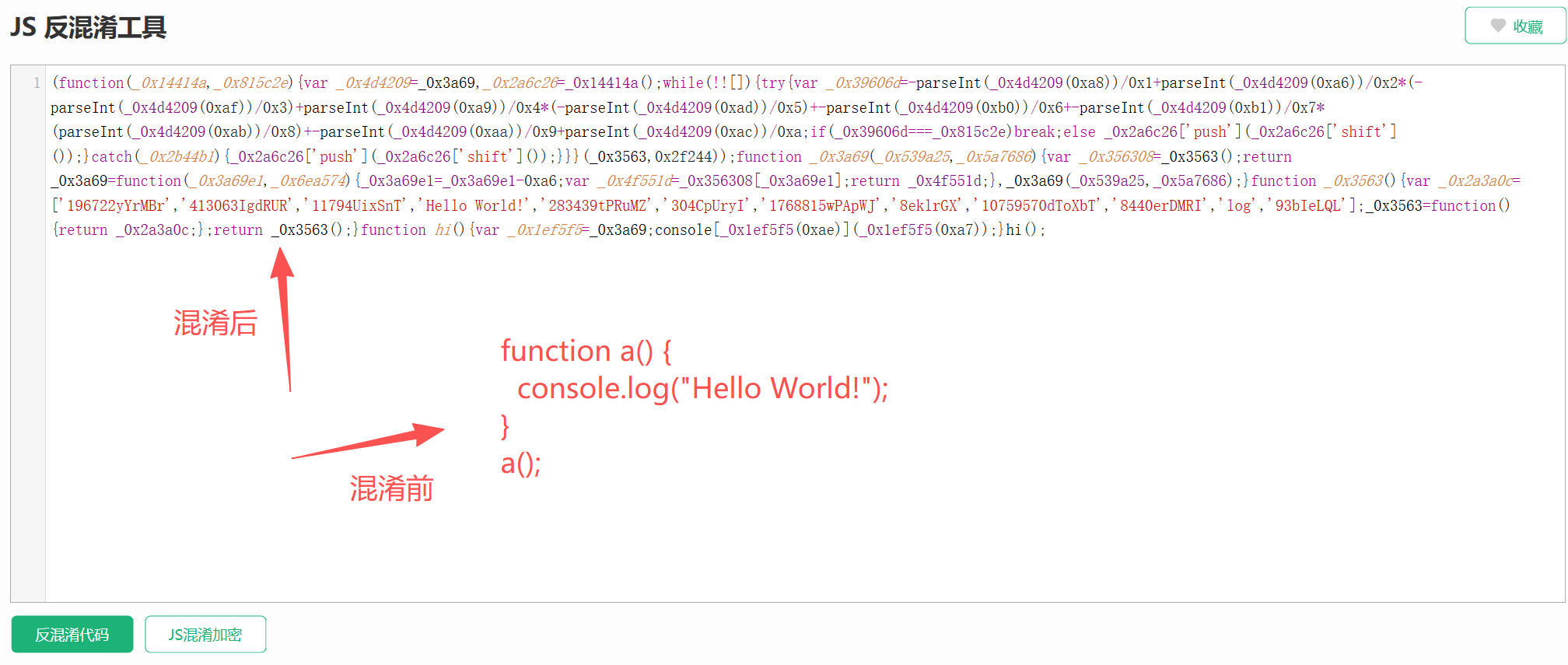
-
第三步 :虽然变量名还原不回来,但字符串常量(比如 API 地址、加密算法的 Key、特定的报错信息)通常是藏不住的,这是突破口。
-
路由在前端:页面不刷新
-
现象 :网页上点来点去,URL 从
/login变成了/dashboard,但 Network 面板里没有新的 HTML 文档请求。导致测试人员很难通过抓包直接看到页面的加载逻辑。所有的"页面"其实都在 JS 里定义好了。 -
对策实操:
-
关注 XHR/Fetch :既然页面不刷新,那数据全靠 Ajax而来。在 Network 面板里,要盯着 XHR 这一栏。
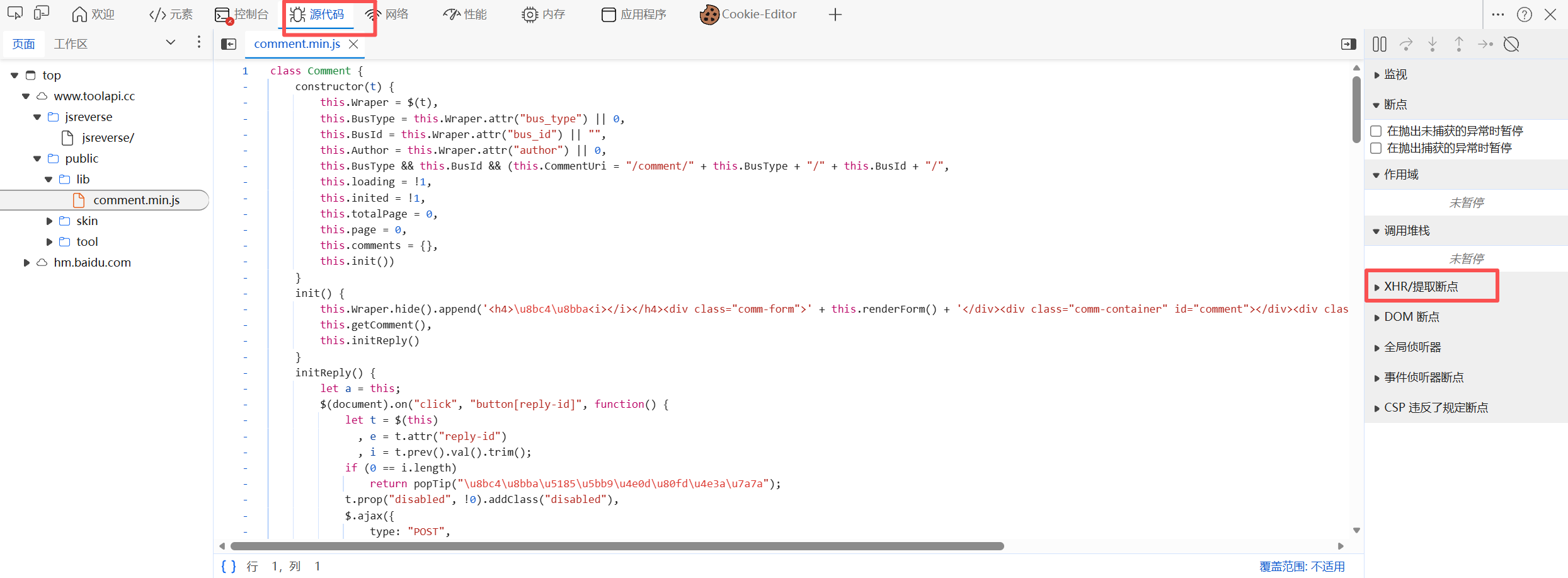
-
寻找"壳" :现在经常会发现一个初始的
index.html非常干净,只有几个<script>标签,真正的逻辑全在 JS 里。
-
请求封装:加密
-
现象 :开发人员不会在每个按钮点击的地方都写一遍加密代码,而是通常会写在一个"拦截器"里。如果测试人员想破解前端的参数签名(Sign)、Token 生成逻辑或者请求体加密,不要去读按钮的点击事件,那是死路。
-
对策实操:
-
在 (源代码)Sources 面板按
Ctrl + Shift + F全局搜索关键词:interceptors、request.use、encrypt。找到类似下面的代码。
// 伪代码示例 axios.interceptors.request.use(config => { config.data = encrypt(config.data); // 这里就是加密的地方! return config; }); -
值得注意的是:很多加密脚本会检测运行环境(如检测 window.navigator.webdriver或 Headless特征),如果发现是自动化工具(如 Puppeteer/Playwright)可能会停止加密或直接报错。这是后续做自动化逆向时需要过掉的"环境墙",本篇仅涉及基础知识,感兴趣的自行搜索或等待后续文章。