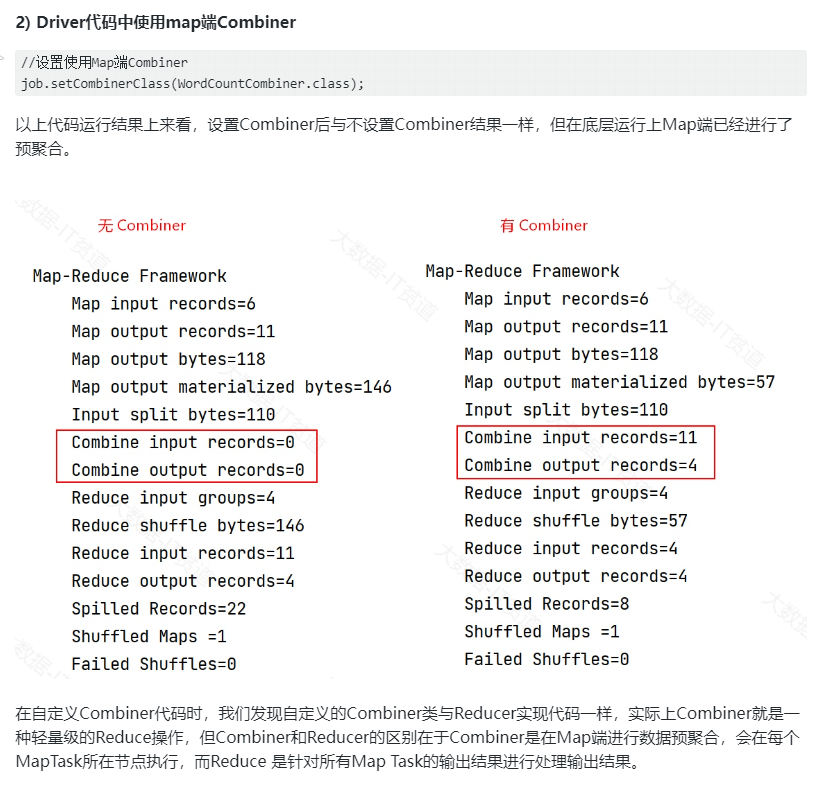
Combiner预聚合
Combiner是一个可选的优化步骤,在Map任务输出结果后、Reduce输入前执行。其作用是对Map任务的输出进行局部合并,将具有相同键的键值对合并为一个,以减少需要传输到Reduce节点的数据量,降低网络开销,并提高整体性能。
Combiner实际上是一种轻量级的Reduce操作,用于减少数据在网络传输过程中的负担。需要注意的是,Combiner的执行并不是强制的,而是由开发人员根据具体情况决定是否使用,一些情况下不适合使用Combiner,例如:对数据进行均值计算场景。
在MapReduce中使用Combiner预聚合需要两个步骤:
-
自定义类实现Reducer,实现reduce方法,完成聚合逻辑
-
在Driver中设置"job.setCombinerClass(YourCombiner.class)"在Map端使用Combiner预聚合
下面对WordCount案例进行改造,实现Map端进行相同单词的预聚合。
- 自定义类WordCountCombiner类实现Reducer类
java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
//创建写出的value
IntWritable total = new IntWritable();
//每组key会调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
//累加
for (IntWritable value : values) {
sum += value.get();
}
//设置当前key对应value结果值
total.set(sum);
//结果写出
context.write(key,total);
}
}
自定义Reduce端分组比较器
默认在MapReduce Reduce端每个key对应一组数据,一个Redcue Task可以处理多组key,默认哪些数据分配到相同的组就是按照key是否相等决定的。我们也可以通过在自定义分组比较器来决定将哪些数据看成同一个组进行处理(相同key)。
使用自定义Redcue端分组比较器需要如下两个步骤:
-
自定义Reduce端分组比较器
-
在Driver中通过"job.setGroupingComparatorClass(YourGroupingComparator.class)"进行设置。
案例需求
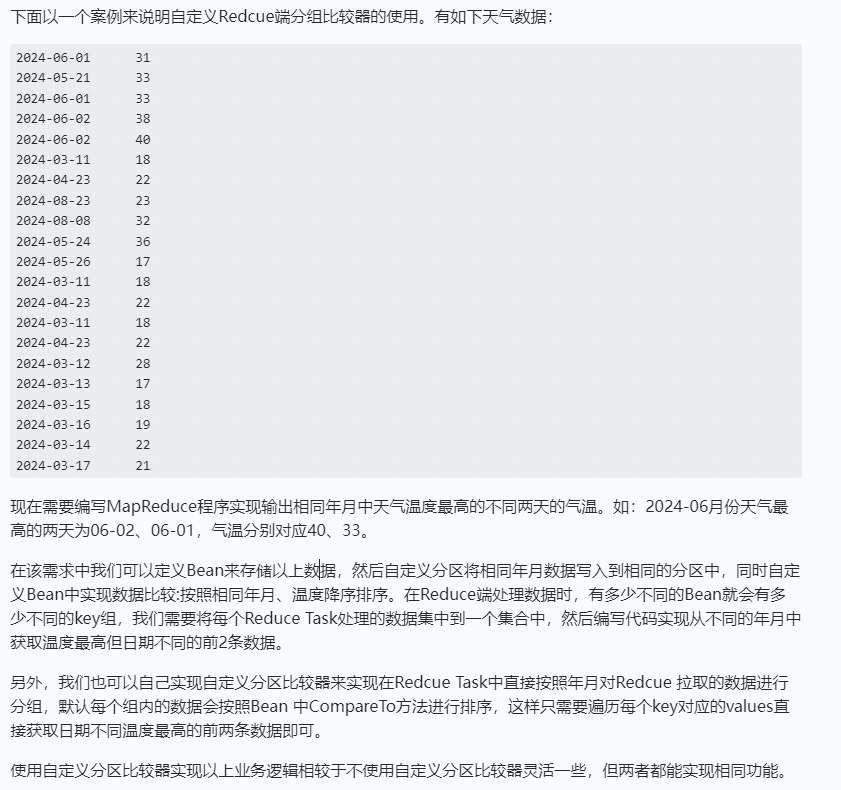
不使用自定义分组比较器实现
- Temperature
java
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 温度实体类
*/
public class Temperature implements WritableComparable<Temperature> {
private String year;
private String month;
private String day;
private Integer temp;
//空构造
public Temperature() {
}
//有参构造
public Temperature(String year, String month, String day, Integer temp) {
this.year = year;
this.month = month;
this.day = day;
this.temp = temp;
}
//getter setter
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
public String getDay() {
return day;
}
public void setDay(String day) {
this.day = day;
}
public Integer getTemp() {
return temp;
}
public void setTemp(Integer temp) {
this.temp = temp;
}
//toString()
@Override
public String toString() {
return year + "-" +month + "-" +day + "\t" +temp;
}
//序列化与反序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.year);
dataOutput.writeUTF(this.month);
dataOutput.writeUTF(this.day);
dataOutput.writeInt(this.temp);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
year = dataInput.readUTF();
month = dataInput.readUTF();
day = dataInput.readUTF();
temp = dataInput.readInt();
}
//两个对象如何比较数据
@Override
public int compareTo(Temperature o) {
//按照相同的年月、温度降序排序
int yearCompare = this.getYear().compareTo(o.getYear());
int monthCompare = this.getMonth().compareTo(o.getMonth());
if(yearCompare==0){
if(monthCompare==0){
//按照温度大的降序排序
return this.temp > o.temp ? -1:1;
}
return monthCompare;
}
return yearCompare;
}
}
- TemperatureReducer
java
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.*;
public class TemperatureReducer extends Reducer<Temperature, Temperature, Temperature,NullWritable> {
int cnt ;
String year;
String month;
String day;
//用来标记某个分区中是否处理过相同日期数据,map中key为年月,value:<day,年月计数>
HashMap<String, String> flagMap = new HashMap<>();
//相同的key分为一组,这里需要将分区中所有的数据拿在一起最后比较获取日期最大的数据
ArrayList<Temperature> list = new ArrayList<>();
@Override
protected void reduce(Temperature key, Iterable<Temperature> values, Reducer<Temperature, Temperature, Temperature, NullWritable>.Context context) throws IOException, InterruptedException {
Iterator<Temperature> iterator = values.iterator();
while(iterator.hasNext()){
Temperature next = iterator.next();
list.add(next);
}
//最后比较得到温度较高的两条数据,日期不能相同
for (Temperature temperature : list) {
year = temperature.getYear();
month = temperature.getMonth();
day = temperature.getDay();
//第一次处理某个年月日数据
if(!flagMap.containsKey(year+"-"+month)){
cnt = 1 ;
context.write(temperature,NullWritable.get());
flagMap.put(year+"-"+month,day+","+cnt);
}
//如果flagMap中包含年月数据,判断value是不是同一日期,是同一日期不输出,不是同一日期输出数据
if(flagMap.containsKey(year+"-"+month)&&!day.equals(flagMap.get(year+"-"+month).split(",")[0])){
//获取当前年月记录的条数
cnt = Integer.valueOf(flagMap.get(year + "-" + month).split(",")[1]);
cnt +=1;
//说明当前年月下不够2条数据
if(cnt == 2){
context.write(temperature,NullWritable.get());
}
flagMap.put(year+"-"+month,day+","+cnt);
}
}
}
} 使用自定义分组比较器实现
使用自定义分组比较器实现
相比以上代码,使用自定义分区比较器首先需要自定义类继承WritableComparator抽象类并实现构造和compare方法,在构造方法中需要调用父类构造传入排序对象类型及是否创建实例,在compare方法中实现决定将哪些数据放入同一组的比较逻辑。


自定义输出格式
在MapReduce中Reduce写出数据时根据不同的OutputFormat格式化类来决定数据如何写出,OutputFormat格式化类中通过getRecordWriter
方法获取RecordWriter对象进而将数据通过RecordWriter.write()方法写出到外部系统,默认写出格式类为TextOutputFormat(该类继承自抽象类FileOutputFormat,FileOutputFormat又继承自顶级的OutputFormat抽象类),即:一行行将数据写出到外部text文件中,生成的文件名称为part-r-00000、part-r-00001... 如果我们想要改变写出文件名称也可以通过定义类继承FileOutputFormat抽象类并实现对应方法即可。
自定义OutputFormat及使用自定义输出格式步骤如下:
-
自定义类继承FileOutputFormat并实现getRecordWriter方法
-
在getRecordWriter方法中返回自定义RecordWriter类,该类需要集成RecordWriter对象实现对应的数据写出逻辑。
-
在Driver中设置"job.setOutputFormatClass(YourOutputFormat.class)"使用自定义outputFormat。
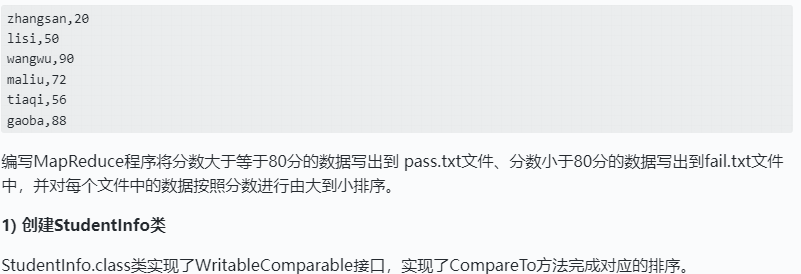
案例:学生成绩数据studentscore.txt,内容如下:
java
/**
* 学员信息
*/
public class StudentInfo implements WritableComparable<StudentInfo> {
private String name;
private int score;
// 无参构造方法
public StudentInfo() {
}
// 带参构造方法
public StudentInfo(String name, int score) {
this.name = name;
this.score = score;
}
// Getter和Setter方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "StudentInfo{" +
"name='" + name + '\'' +
", score=" + score +
'}';
}
// 实现序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(score);
}
// 实现反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
score = in.readInt();
}
@Override
public int compareTo(StudentInfo o) {
if(this.score > o.score){
return -1;
}else if(this.score < o.score){
return 1;
}else{
return 0;
}
}
}
- MyOutputFormat
MyOutputFormat类需要继承FileOutputFormat,并实现getRecoreWriter方法,返回RecordWriter对象完成自定义数据输出。
java
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MyOutputFormat extends FileOutputFormat<StudentInfo, NullWritable> {
// 获取RecordWriter对象
@Override
public RecordWriter<StudentInfo, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
// 根据job来创建文件输出流,需要传入job
MyRecordWriter myRecordWriter = new MyRecordWriter(job);
return myRecordWriter;
}
}
class MyRecordWriter extends RecordWriter<StudentInfo,NullWritable>{
private FSDataOutputStream passOutputStream;
private FSDataOutputStream failOutputStream;
//根据job来创建文件输出流
public MyRecordWriter(TaskAttemptContext job) throws IOException {
FileSystem fileSystem = FileSystem.get(job.getConfiguration());
// 创建及格成绩输出流
passOutputStream = fileSystem.create(new Path("D:\\mapreduce\\pass.txt"));
// 创建不及格成绩输出流
failOutputStream = fileSystem.create(new Path("D:\\mapreduce\\fail.txt"));
}
//写出数据
@Override
public void write(StudentInfo key, NullWritable value) throws IOException, InterruptedException {
int score = key.getScore();
if(score >=80){
passOutputStream.writeBytes(score+"\n");
}else{
failOutputStream.writeBytes(score+"\n");
}
}
//关闭资源
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// 关闭输出流并释放资源
IOUtils.closeStreams(passOutputStream,failOutputStream);
}
}- Driver
在Driver中通过设置"job.setOutputFormatClass(MyOutputFormat.class)"指定自定义outputFormat,在实现中指定了数据写出的文件,另外FileOutputFormat.setOutputPath(...)指定的路径中会存放"_SUCCESS"标志文件。
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ScoreDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取配置信息及job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置Driver 程序对应的jar/类
job.setJarByClass(ScoreDriver.class);
//3.设置Mapper和Reducer对应的类
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
//4.设置Mapper输出key、value类型
job.setMapOutputKeyClass(StudentInfo.class);
job.setMapOutputValueClass(Text.class);
//5.设置最终输出K,V类型
job.setOutputKeyClass(StudentInfo.class);
job.setOutputValueClass(NullWritable.class);
//设置自定义outputFormat
job.setOutputFormatClass(MyOutputFormat.class);
//6.设置数据输入和结果写出路径
FileInputFormat.setInputPaths(job,new Path("data/studentscore.txt"));
//使用了自定义输出类,结果数据会写入自定义输出类中指定的路径,这里设置的目录只是最后写出的_success标记文件路径
FileOutputFormat.setOutputPath(job,new Path("output6/"));
//7.运行任务,运行成功返回true
boolean success = job.waitForCompletion(true);
if (success) {
// 任务执行成功的逻辑
System.out.println("任务执行成功");
} else {
// 任务执行失败的逻辑
System.out.println("任务执行失败");
}
}
}