你用 Claude Code 写代码时,有没有遇到过这种情况:你只是提出一个普通需求,某个项目里的 Skill 却自动被执行了。你没有显式点名它,模型却像是知道什么时候该用它一样。
这背后有三件事要搞清楚:模型怎么知道有哪些 Skill 可用?它怎么决定在什么时机调用?Skill 集合变化了怎么办?
1. 一个自动 commit 的场景
项目根目录下有两个配置:
bash
my-project/
├── src/
│ └── utils/
│ └── format.ts
├── .claude/
│ └── skills/
│ └── auto-commit/
│ └── SKILL.md
└── AGENTS.mdauto-commit/SKILL.md 定义了提交行为的规范:
markdown
---
description: 按 conventional commit 规范提交代码,当完成代码修改或新增文件后调用
---
当用户完成代码修改后,执行 `git commit`。使用 conventional commit 格式:`<type>(<scope>): <description>`。AGENTS.md 里写了一条行为指令:
markdown
改完代码后自动 commit。用户只说了一句话:
bash
用户: 帮我在 src/utils/format.ts 里加一个格式化日期的函数模型读取了 AGENTS.md,写入代码,然后自动调用了 commit Skill,执行了 git add 和 git commit,最后返回了提交信息:
bash
模型: 代码已写入,并已提交:
feat(utils): add date format function
commit hash: a3f8b2c整个过程可以用一张时序图概括:
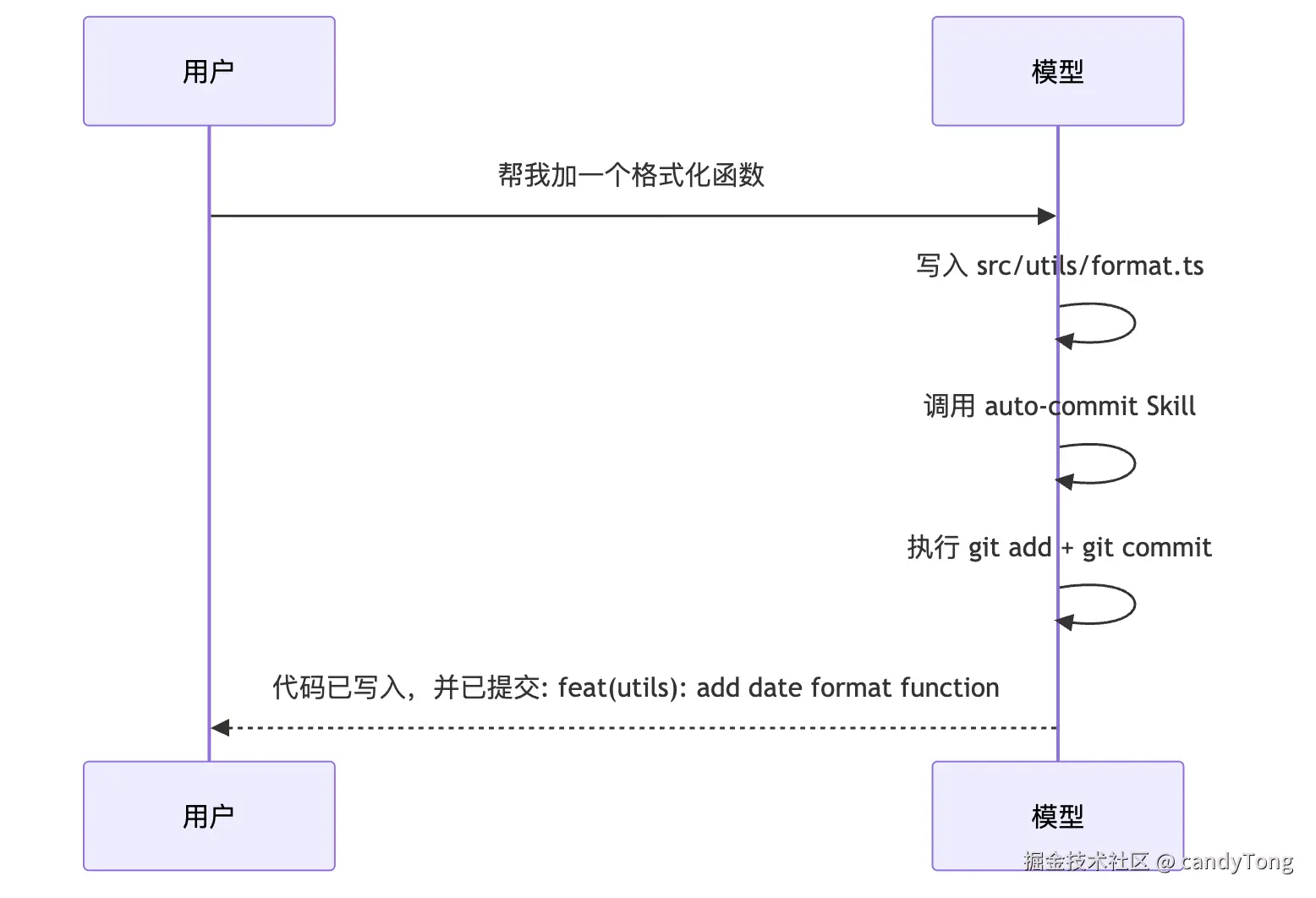
上面是 Agent 运行的表面过程。真正的问题是:模型改完代码后,为什么会主动去调用 commit Skill?它是怎么知道有这个 Skill 的?又是怎么决定在这个时机调用的?
这不是硬编码规则,也不是预先注入的指令。要回答这些问题,需要理解三件事:静态注入 (模型怎么知道有哪些 Skill)、Skill 工具 (模型怎么调用 Skill)和动态注入(Skill 集合变化时怎么办)。
2. 静态注入:模型怎么知道有哪些 Skill
先建立一个小词汇表,后面读源码时会更容易对上:
| 名词 | 作用 |
|---|---|
Skill |
用户通过 SKILL.md 定义的一组能力说明和执行指令。 |
Command |
Claude Code 内部的统一表示。Skill 被解析后也会变成一个 Command,所以源码里经常看到 findCommand()、getSkillToolCommands()。 |
SkillTool |
模型真正能调用的通用工具。模型不是直接调用某个 Skill,而是调用 SkillTool({ skill: "name" })。 |
skill_listing |
注入给模型看的隐藏提醒消息,用来告诉模型"当前有哪些 Skill 可以通过 SkillTool 调用"。 |
AGENTS.md |
项目级行为指令,告诉模型"应该做什么";它不是 Skill,也不提供具体 Skill 的调用入口。 |
2.1 注入时机
Claude Code 不在 system prompt 中预置 Skill 列表,而是通过 skill_listing 附加信息注入。
在 Claude Code 中,attachment 是系统在每轮对话中自动附加到消息列表里的额外内容片段,以 system-reminder 形式注入,对用户界面隐藏,只有模型能看到。skill_listing 就是其中一种。
用户发送消息后,系统在调用模型之前,先注入 attachment,skill_listing 就在其中:

getAttachments() 负责各种附加信息:
typescript
// src/utils/attachments.ts --- getAttachments 简化后的结构
export async function getAttachments(
input,
toolUseContext,
ideSelection,
queuedCommands,
messages,
querySource,
) {
// maybe(label, fn): 容错包裹器,fn 抛异常时返回空数组不影响其他附加信息;
// 返回空数组时在后续 flat+filter 阶段被跳过;同时记录每个 label 的执行耗时
const allThreadAttachments = [
// ...
maybe('changed_files', () => getChangedFiles(context)),
maybe('dynamic_skill', () => getDynamicSkillAttachments(context)),
maybe('skill_listing', () => getSkillListingAttachments(toolUseContext)), // ← 在这里
maybe('plan_mode', () => getPlanModeAttachments(messages, toolUseContext)),
// ...
];
return [...allThreadAttachments.flat()].filter(
a => a !== undefined && a !== null,
);
}skill_listing 在 allThreadAttachments 里,所以每次用户输入都会检查------在模型看到用户消息之前,系统就决定是否需要注入新的 Skill 列表。第一次用户输入时,所有 Skill 被注入;之后通过去重机制,只有当存在尚未通知的 Skill 时才真正写入内容。
注入后,模型看到的内容大致如下:
bash
<system-reminder>
The following skills are available for use with the Skill tool:
# skills: 用户/项目 .claude/skills/
- auto-commit: 按 conventional commit 规范提交代码...
# bundled: Claude Code 内置
- some-builtin-skill: ...
# mcp: MCP 服务器提供
- some-mcp-skill: ...
# plugin: 插件提供
- some-plugin-skill: ...
</system-reminder>列表里的 Skill 来源各不相同:bundled 是 Claude Code 内置的,skills 是用户或项目 .claude/skills/ 目录下的,plugin 是插件提供的,mcp 是 MCP 服务器提供的。
这条消息对用户界面隐藏,只有模型能看到。每条 Skill 的短描述来自 SKILL.md frontmatter 里的 description,如果还声明了 when_to_use,也会拼进去。
3. Skill 工具:模型怎么调用 Skill
知道了"模型怎么知道有哪些 Skill",接下来是"模型怎么调用"。
3.1 Skill 不是工具,是工具的路由
这里有一个容易混淆的地方:Skill 和 Tool 的注入方式完全不同。
Skill 不是独立工具,而是一个工具的路由 。模型只看到一个通用的 Skill 工具,参数只有 skill: string 和 args: string:
json
{
"name": "Skill",
"description": "Execute a skill within the main conversation",
"input_schema": {
"type": "object",
"properties": {
"skill": { "type": "string", "description": "The skill name" },
"args": { "type": "string", "description": "Optional arguments" }
}
}
}它通过名字查找并触发对应的 Command,而不是像 Bash、Read 那样直接执行。
补充一点:在 Claude Code 中,Skill 和 Command 本质上是同一个实现。SKILL.md 文件被 createSkillCommand() 解析后,直接返回一个 Command 对象(type: 'prompt')。SkillTool 内部调用 findCommand() 查找的也是 Command。所以文章中说"Skill"或"Command",指的是同一套机制。
3.2 SkillTool 的核心逻辑
typescript
// src/tools/SkillTool/SkillTool.ts --- 只保留路由核心
export const SkillTool = buildTool({
name: 'Skill',
async validateInput({ skill }, context) {
const commandName = skill.trim().replace(/^\//, '');
const command = findCommand(commandName, await getAllCommands(context));
if (!command) return { result: false, message: 'Skill not found' };
if (command.disableModelInvocation) {
return { result: false, message: 'Cannot invoke' };
}
return { result: true };
},
async call({ skill, args }, context) {
const commandName = skill.trim().replace(/^\//, '');
const command = findCommand(commandName, await getAllCommands(context));
if (command.context === 'fork') {
return executeForkedSkill(command, commandName, args);
}
return processPromptSlashCommand(commandName, args);
},
});关键流程:
validateInput--- 把 Skill 名字归一化,然后在 Command 表里查找;找不到就拒绝调用。call--- 再次按名字取出 Command;fork类型交给子 agent,普通类型则解析对应的SKILL.md。- 普通 Skill 的结果 ---
processPromptSlashCommand()会把SKILL.md解析成后续要注入的消息,模型下一轮再按这些指令继续执行。
SKILL.md 的指令内容不是工具返回的文本,而是作为用户消息注入对话。模型看到的是一条"新用户消息",内容是 SKILL.md 中的指令。这让模型认为有人告诉它"去执行 git commit"。
3.3 模型靠三个信息做匹配
模型决定调用 auto-commit,靠的是三个信息的组合:
第一,AGENTS.md 中的行为指令
markdown
改完代码后自动 commit。这告诉模型:完成代码修改后应该去执行 commit。
第二,SkillTool 的工具提示
bash
When a skill matches the user's request, this is a BLOCKING REQUIREMENT:
invoke the relevant Skill tool BEFORE generating any other response about the task.这段提示告诉模型:发现匹配的 Skill 就必须调用,不要跳过。
第三,skill_listing 附加信息中的短描述
bash
- auto-commit: 按 conventional commit 规范提交代码,当完成代码修改或新增文件后调用这段短描述主要来自 SKILL.md frontmatter 里的 description,如果 Skill 还声明了 when_to_use,也会拼进 listing。换句话说,模型不是只看到一个名字,而是看到"名字 + description + 可选 when_to_use"形成的触发线索。
3.4 模拟对话
把这三个信息放到对话流程里看:
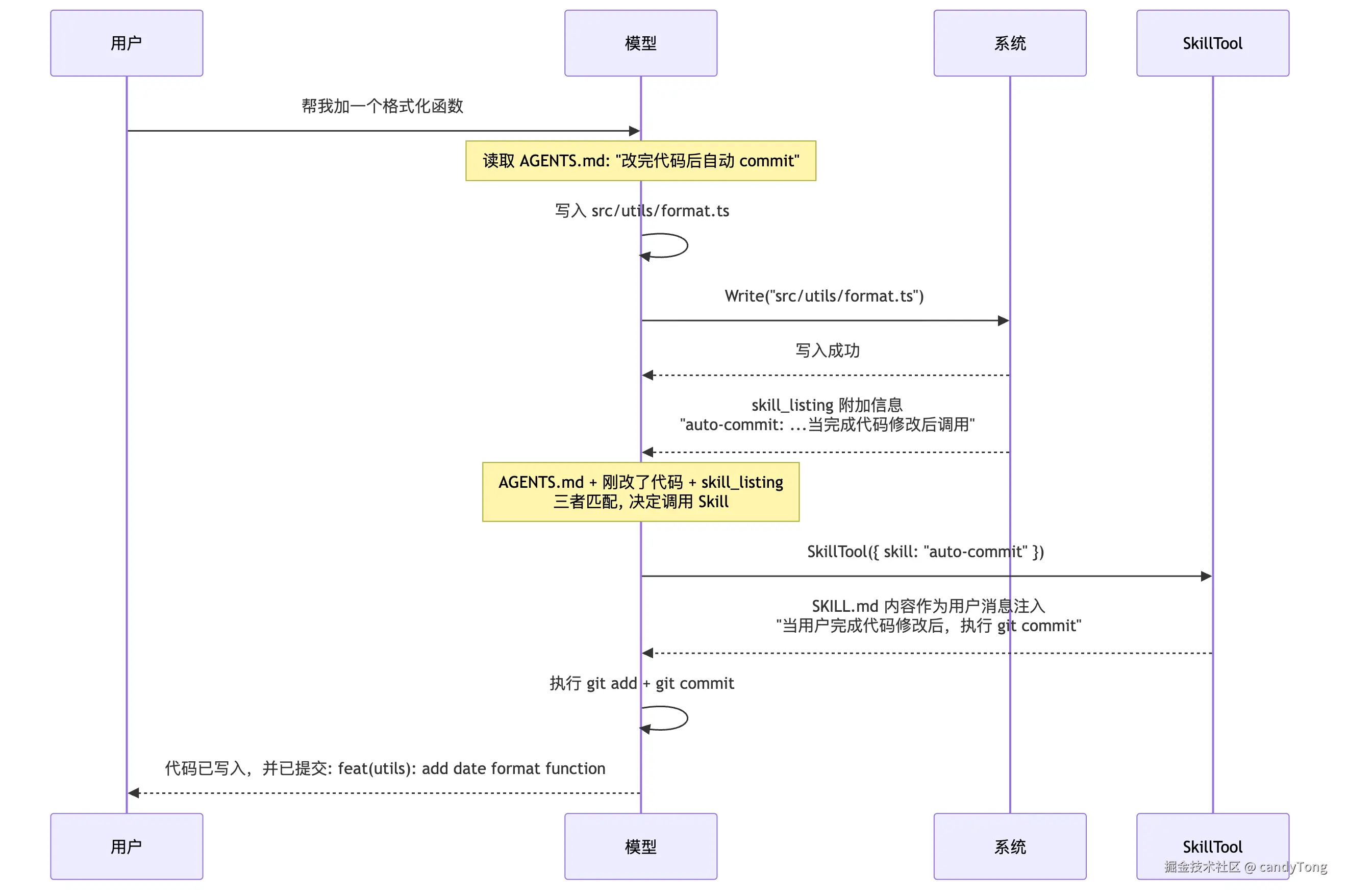
图里的关键点:
- 用户消息处理时,
skill_listing已经进入上下文(首次注入)。 - 工具执行成功后,
skill_listing再次被检查------但因为去重,不会重复注入。 - 模型把三件事对上:AGENTS.md 要求自动提交、刚刚确实写了代码、
auto-commit的短描述正好匹配,于是调用SkillTool。
SkillTool 返回的不是"已经提交好了"的结果,而是把 SKILL.md 内容注入给模型。模型看到这条新指令后,才继续执行 git add 和 git commit。
所以,模型不是靠硬编码规则触发 Skill,而是根据 AGENTS.md 指令 + listing 短描述 + 当前工具执行结果 主动匹配。description 和 when_to_use 写得越清楚,模型就越可能在正确的时机调用。
4. 动态注入:Skill 集合变化时怎么办
前面介绍了静态注入------模型在第一次收到用户消息时就能看到 Skill 列表。但这里有几个问题:
- 用户中途新增了一个 Skill,模型能知道吗?
- 用户删除了一个 Skill,之前注入的列表怎么办?
- 会话很长的时候,模型还会记得第 1 轮注入的列表吗?
Skill 集合不是启动时一次性确定的。用户可以随时创建、修改、删除 SKILL.md,项目不同模块也可能自带独立 Skill。系统需要在会话过程中持续感知这些变化。
4.1 Agent Loop 注入
Agent Loop 每轮工具执行完毕后,都会再次调用 getAttachments() 检查是否有新的附加信息需要注入:

对应的代码:
typescript
// src/query.ts --- queryLoop 简化后的结构
async function* queryLoop(params, consumedCommandUuids): AsyncGenerator {
while (true) {
const { message, toolUseBlocks } = await queryModel(messages);
if (toolUseBlocks.length > 0) {
const toolResults = await runTools(toolUseBlocks);
// 工具执行完毕, 再次收集附加信息
for await (const attachment of getAttachmentMessages(
null,
updatedToolUseContext,
null,
queuedCommandsSnapshot,
[...messagesForQuery, ...assistantMessages, ...toolResults],
querySource,
)) {
toolResults.push(attachment);
}
messages.push(...toolResults);
continue;
}
return message;
}
}4.2 去重与预算
getAttachments() 每一轮都会执行,如果每次都注入 skill_listing,会占用大量上下文。两个机制控制这个问题:去重检查 和预算控制。
getSkillListingAttachments() 的核心逻辑:
typescript
// src/utils/attachments.ts --- getSkillListingAttachments 核心逻辑
const sentSkillNames = new Map<string, Set<string>>();
async function getSkillListingAttachments(
toolUseContext,
): Promise<Attachment[]> {
if (!hasSkillTool(toolUseContext)) return [];
const allCommands = await getSkillToolCommands(cwd);
const newSkills = allCommands.filter(cmd => !sent.has(cmd.name));
if (newSkills.length === 0) return [];
for (const cmd of newSkills) {
sent.add(cmd.name);
}
const content = formatCommandsWithinBudget(newSkills, contextWindowTokens);
return [{ type: 'skill_listing', content }];
}去重检查 ------sentSkillNames 是一个 Map,key 是 agentId(主线程为空字符串),value 是已通知过的 Skill 名字集合。每个子 agent 有独立的集合,避免主线程发送后阻塞子 agent 的首次通知。每次都检查,但只有当存在尚未通知的 Skill 时才真正注入内容 。第一次注入后,所有 Skill 名字被标记为已发送,后续轮次 newSkills 为空数组,返回 []。
预算控制 ------即使首次注入也有上限,formatCommandsWithinBudget() 按上下文窗口的 1%(约 8000 字符)截断。每条描述先受 250 字符上限约束;如果总体预算仍然不够,bundled Skill 的 listing 条目会优先保留,非 bundled Skill 再做均分截断。
4.3 重置去重记录的时机
什么场景下会重置去重记录,触发重新注入?
- 插件重载 --- 安装或重新加载 Skill 插件后
- 清空对话 --- 执行
/clear命令后(清空对话历史,同时重置去重记录以重新发送完整列表) - Skill 文件变更 --- 磁盘上的 SKILL.md 文件被添加、修改或删除时(通过文件监听触发防抖重载)。重置后,下一次检查会重新读取文件系统,新增的 Skill 会被检测到并注入,已删除的 Skill 不会再出现在新列表中。但已经注入到历史上下文里的旧 listing 不会被"反向删除"------如果模型仍根据旧上下文尝试调用已删除的 Skill,
SkillTool会在当前命令表里查找失败并返回Unknown skill。
typescript
// src/utils/attachments.ts --- resetSentSkillNames
// Called when the skill set genuinely changes (plugin reload, skill file
// change on disk) so new skills get announced. NOT called on compact ---
// post-compact re-injection costs ~4K tokens/event for marginal benefit.
export function resetSentSkillNames(): void {
sentSkillNames.clear();
}4.4 嵌套目录发现
除了根目录 .claude/skills/,项目子目录下也可以有自己的 .claude/skills/。系统不会在启动时扫描整个项目树,而是等到模型操作某个子目录下的文件时,才沿路径向上搜索,发现并加载该目录下的 Skill。
bash
my-project/
├── .claude/skills/auto-commit/SKILL.md ← 启动时已加载
└── packages/
└── core/
└── .claude/skills/core-lint/SKILL.md ← 启动时不知道这个目录存在当模型读取 packages/core/src/index.ts 时,系统才发现 packages/core/.claude/skills/ 存在,加载 core-lint,后续轮次中模型就能看到它。搜索时会跳过 .gitignore 中的目录(如 node_modules)。
这使得项目不同模块可以自带独立 Skill,模型只在触碰到相关文件时才会发现它们。
4.5 压缩后的行为
压缩后不会重置去重记录------这是有意为之的。原因有三:
- 已使用 Skill 的上下文已保留 ------压缩过程中
createSkillAttachmentIfNeeded()会将已调用过的 Skill 内容(通过invoked_skills记录)注入压缩后的摘要,不会丢失 - 未使用的 Skill 大概率不相关------在长会话中,一个 Skill 如果几十轮都没被用到,说明它和当前任务无关,重新注入纯属浪费
- 重新注入会污染压缩后的上下文------压缩的目的是精简上下文,立刻重新注入约 4K tokens 会导致大量上下文消耗
invoked_skills 的记录和恢复分两步:
第一步,记录 ------每当 Skill 被调用,addInvokedSkill() 将 Skill 名字、路径、内容写入全局状态:
typescript
// src/bootstrap/state.ts --- addInvokedSkill
export function addInvokedSkill(
skillName: string,
skillPath: string,
content: string,
agentId: string | null = null,
): void {
const key = `${agentId ?? ''}:${skillName}`;
STATE.invokedSkills.set(key, {
skillName,
skillPath,
content,
invokedAt: Date.now(),
agentId,
});
}第二步,压缩时保留已调用 Skill 的内容 ------createSkillAttachmentIfNeeded() 从 invokedSkills 中取出已调用过的 Skill,按最近使用排序,截断后保留下来:
typescript
// src/services/compact/compact.ts --- createSkillAttachmentIfNeeded
export function createSkillAttachmentIfNeeded(
agentId?: string,
): AttachmentMessage | null {
const invokedSkills = getInvokedSkillsForAgent(agentId);
if (invokedSkills.size === 0) {
return null;
}
const skills = Array.from(invokedSkills.values())
.sort((a, b) => b.invokedAt - a.invokedAt)
.map(skill => ({
name: skill.skillName,
path: skill.skillPath,
content: truncateToTokens(
skill.content,
POST_COMPACT_MAX_TOKENS_PER_SKILL,
),
}))
.filter(skill => {
if (usedTokens + tokens > POST_COMPACT_SKILLS_TOKEN_BUDGET) {
return false;
}
usedTokens += tokens;
return true;
});
return createAttachmentMessage({
type: 'invoked_skills',
skills,
});
}转换成模型可见消息后,大致长这样:
text
<system-reminder>
The following skills were invoked in this session. Continue to follow these guidelines:
### Skill: auto-commit
Path: /path/to/.claude/skills/auto-commit/SKILL.md
---
description: 按 conventional commit 规范提交代码,当完成代码修改或新增文件后调用
---
当用户完成代码修改后,执行 `git commit`。使用 conventional commit 格式:...
</system-reminder>压缩后的行为可以概括为:不重新注入完整 skill_listing,只保留已调用过的 Skill 内容 。代价是:压缩后,未调用过的 Skill 可能从上下文中消失,模型不再记得它们存在。用户仍可以通过斜杠命令(如 /commit)手动触发。
4.6 长上下文的注意力衰减
去重机制还带来一个隐含的问题:在未压缩的长会话中,skill_listing 只在第一次注入一次,之后 sentSkillNames 阻止重复注入。到了第 50 轮,模型能不能记得第 3 轮注入的那份列表,完全取决于它的长上下文注意力机制。
系统从不主动重新注入同一份列表------sentSkillNames 只增不减,没有定时器,压缩后也不重置。唯一的重新注入路径是事件驱动的重置(Skill 文件变更、/clear、插件重载)。这是有意为之的设计赌注:信任模型的长上下文注意力能力。如果模型能力不足,可能遇到"明明有合适的 Skill,模型就是不用"的情况。
5. Skill 发现:语义匹配注入
前面描述的是 skill_listing 的基础行为:把所有可用 Skill 的短描述一次性推给模型。这个方案在 Skill 数量少的时候没问题,但当 user/project/plugin skills 增长到 200+ 时,全量注入的 token 开销就变得不可接受了。
skill_discovery 是 EXPERIMENTAL_SKILL_SEARCH feature flag 下的增强注入方式,用 Haiku 模型做语义匹配,只注入与当前任务相关的 Skill。两者不是二选一,而是同时生效 :skill_listing 被裁剪为一个精简的基础列表(只保留 bundled + MCP),skill_discovery 负责按需匹配 user/project/plugin Skills。前面 2-4 节描述的全量注入行为对应 flag 关闭时的场景,本节描述的是 flag 开启后的行为。
5.1 skill_listing 被裁剪
打开 feature flag 后,getSkillListingAttachments() 内部会做一次裁剪:
typescript
// src/utils/attachments.ts --- getSkillListingAttachments 内部
if (
feature('EXPERIMENTAL_SKILL_SEARCH') &&
skillSearchModules?.featureCheck.isSkillSearchEnabled()
) {
allCommands = filterToBundledAndMcp(allCommands);
}原来 skill_listing 包含所有来源的 Skill(bundled、skills、plugin、mcp)。裁剪后只保留 bundled 和 MCP 两类,user/project/plugin 的 skill 会被砍掉,由 skill_discovery 按需匹配注入。如果裁剪后结果超过 30 条(FILTERED_LISTING_MAX),会进一步回退到只保留 bundled。
5.2 skill_discovery 的触发路径
skill_discovery 有两条触发路径:
路径一:用户消息触发
用户发送消息时,在首次 API 调用前同步执行:
typescript
// src/utils/attachments.ts --- userInputAttachments 中
maybe('skill_discovery', () =>
getTurnZeroSkillDiscovery(input, messages, context),
);系统把用户输入、对话历史和上下文一起喂给 Haiku,Haiku 返回匹配到的 Skill 列表。结果在首次 API 调用前就位,模型一开始就能看到。
SKILL.md 展开时会设置 skipSkillDiscovery: true,避免 Skill 指令本身触发无意义的匹配。
路径二:Agent Loop 触发
Agent Loop 每轮循环开始时,尝试启动异步预取:
typescript
// src/query.ts --- Agent Loop 每轮循环开始时
const pendingSkillPrefetch = skillPrefetch?.startSkillDiscoveryPrefetch(
null,
messages,
toolUseContext,
);但并不是每轮都会真正调用 Haiku。startSkillDiscoveryPrefetch 内部有 findWritePivot 守卫------只有当本轮有工具真正写入了文件时才执行 Haiku 调用,否则直接跳过。预取与模型流式输出和工具执行并行,不阻塞主流程。
这个设计来自 prod 数据:早期实现每轮都调用 Haiku,结果 97% 的调用什么都匹配不到。改成 write-pivot guard 后,只在文件变更时触发,大幅减少了无意义的调用。
5.3 注入给模型的内容
模型在同一轮对话中可能同时看到两条 system-reminder:
bash
# skill_listing 发的(始终存在,只是内容变少了)
The following skills are available for use with the Skill tool:
- graphify: any input to knowledge graph...
- sensight: 实时查询各平台热榜...
# skill_discovery 发的(按需出现)
Skills relevant to your task:
- article-publish-review: 对技术文章做发布前审查
These skills encode project-specific conventions. Invoke via Skill("<name>") for complete instructions.当 skill_discovery 没有匹配到任何 Skill 时,skills 为空数组,整个 attachment 被过滤,不注入任何内容。
5.4 模型主动发现:DiscoverSkillsTool
除了系统自动注入,模型还可以主动调用 DiscoverSkillsTool 来触发发现。system prompt 中有一段引导:
bash
Relevant skills are automatically surfaced each turn as "Skills relevant to
your task:" reminders. If you're about to do something those don't cover --
a mid-task pivot, an unusual workflow, a multi-step plan -- call
DiscoverSkillsTool with a specific description of what you're doing. Skills
already visible or loaded are filtered automatically. Skip this if the
surfaced skills already cover your next action.模型在遇到任务转向、非常规工作流、多步骤计划等场景时,可以主动搜索系统可能遗漏的 Skill,而不是完全依赖自动注入。
5.7 两种注入方式对比
| 维度 | skill_listing | skill_discovery |
|---|---|---|
| 内容 | 基础 Skill 列表(bundled + MCP) | 按需匹配当前任务的 Skill |
| 匹配方式 | 名字 + description 全量展示 | Haiku 模型语义匹配 |
| Token 开销 | 固定,与 Skill 数量线性相关 | 只注入匹配到的几条 |
| 触发时机 | 首次用户输入 + 每轮工具执行后 | 用户消息时同步 + 文件写入时异步预取 |
| 无匹配时 | 仍然发送基础列表 | 整个 attachment 被过滤 |
| 远程 Skill | 不可见 | 通过 skill_discovery 发现 |
6. 设计取舍
| 决策 | 为什么 |
|---|---|
| 首次用户输入时即注入 skill_listing | Skill 列表在模型做任何事之前就进入上下文,确保模型从第一轮就知道有哪些 Skill 可用 |
| skill_listing 去重发送 | 避免每轮都重复通知,浪费 token |
| 预算控制截断描述 | 控制在上下文窗口的 1% 以内 |
| 压缩后不重置 skill_listing | 已使用 Skill 通过 invoked_skills 保留上下文;未使用的大概率不相关;重新注入会污染压缩后的上下文 |
| description 承载主要匹配信息 | 模型根据 description + 可选 when_to_use 判断何时调用,而不是只看到一个名字 |
| 消息级别注入,不是 API 工具定义 | Skill 是工具路由,不是具体工具;纯文本列表更灵活,不需要定义 schema |
| 模型主动匹配,而非预设规则触发 | 不写硬编码的触发逻辑,靠模型的推理能力灵活判断,降低维护成本 |
| 会话期间动态扫描文件系统 | Skill 集合不是静态的,用户可随时创建/删除,系统自动纳入变化 |
| skill_discovery 按需匹配 | Skill 数量膨胀后全量注入不可接受;Haiku 语义匹配只注入相关的,与裁剪后的 skill_listing 互补 |
| 只在文件写入时触发 skill 发现 | prod 数据显示 97% 的 Haiku 调用无结果;工具没有写文件时跳过匹配,大幅降低成本 |
7. 总结
静态注入 ------SKILL.md 被解析为 Command,短描述通过 skill_listing 在首次用户输入时注入模型上下文。之后每轮都检查但通过去重机制避免重复。文件监听在 SKILL.md 变化时触发重载,压缩后有意不重置去重记录,已使用的 Skill 通过 invoked_skills 保留。
Skill 工具 ------模型看到一个通用的 Skill 工具,通过 listing 中的短描述判断何时调用。Skill 本质上是工具的路由------模型通过名字查找 Command,SKILL.md 内容作为用户消息注入对话。
Skill 发现 ------skill_listing 只保留 bundled + MCP 的精简列表,user/project/plugin Skills 由 skill_discovery 通过 Haiku 语义匹配按需注入。远程 Skill 只能通过 discovery 路径被发现。模型还可以通过 DiscoverSkillsTool 主动触发发现。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也可以关注我。