摘要:Spark SQL 是 Apache Spark 中用于结构化数据处理的模块。本文将深入剖析 Spark SQL 的核心概念、架构演进、DataFrame 与 DataSet 的底层原理,以及实战编程技巧,帮助你全面掌握这一大数据利器。
一、Spark SQL 概述
1.1 什么是 Spark SQL
Spark SQL 是 Spark 用于**结构化数据(structured data)**处理的模块。它提供了 DataFrame 和 DataSet 两种编程抽象,让开发者可以用更简洁、更高效的方式处理大规模数据。
与传统的 Spark Core(基于 RDD)相比,Spark SQL 的最大优势在于:
- 内置优化引擎:通过 Catalyst 优化器自动生成最优执行计划
- 统一数据访问:用相同的方式连接 Hive、JSON、Parquet、JDBC 等多种数据源
- 兼容 Hive:可以直接在已有的 Hive 数据仓库上运行 SQL 或 HiveQL
- 标准连接:支持 JDBC/ODBC 连接,方便 BI 工具对接
1.2 Hive 与 Spark SQL 的演进关系
1.2.1 时代背景
Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具。但 MapReduce 计算过程中大量的中间磁盘落地消耗了大量 I/O,严重降低了运行效率。
为了提高 SQL-on-Hadoop 的效率,多种工具应运而生:
| 工具 | 特点 |
|---|---|
| Drill | 支持多种数据源的分布式 SQL 引擎 |
| Impala | Cloudera 开发的 MPP 查询引擎 |
| Shark | 基于 Hive 开发,运行在 Spark 引擎上 |
1.2.2 Shark 的诞生与局限
Shark 是伯克利实验室 Spark 生态环境的组件之一,它修改了 Hive 的内存管理、物理计划、执行三个模块,使之能运行在 Spark 引擎上。
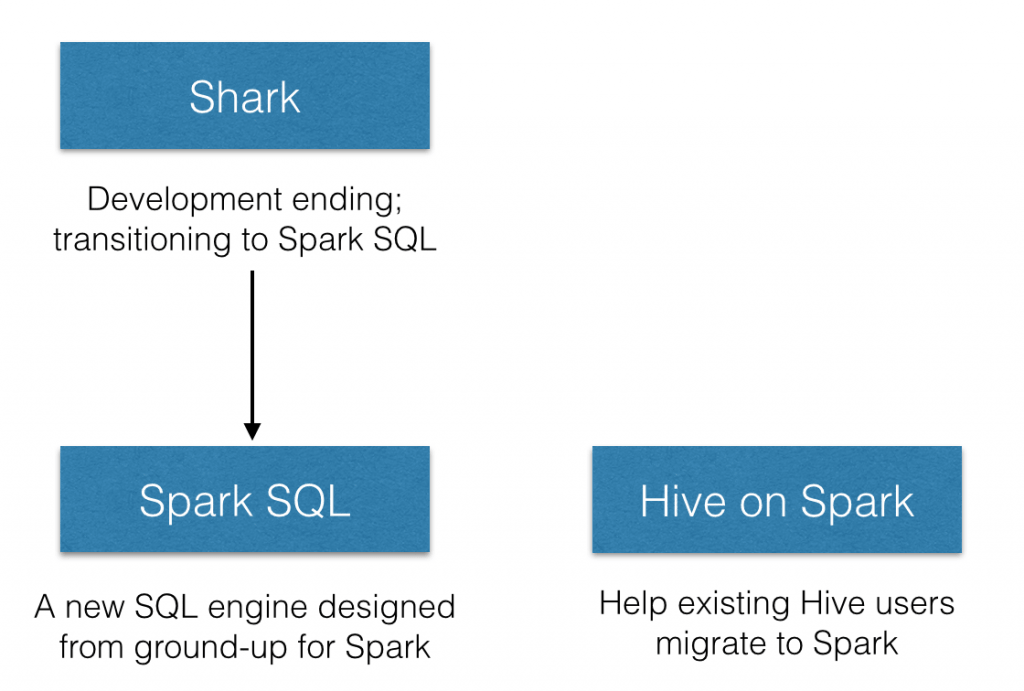
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍 的提升。
然而,Shark 对 Hive 的过度依赖(如采用 Hive 的语法解析器、查询优化器等),制约了 Spark "One Stack Rule Them All" 的既定方针。2014 年 6 月 1 日,Shark 项目停止开发,团队将所有资源转向 Spark SQL 项目。
1.2.3 Spark SQL 的两大分支
Shark 停止后,发展出两个支线:
- Spark SQL:作为 Spark 生态的一员继续发展,不再受限于 Hive,只是兼容 Hive
- Hive on Spark:Hive 的发展计划,将 Spark 作为 Hive 的底层引擎之一
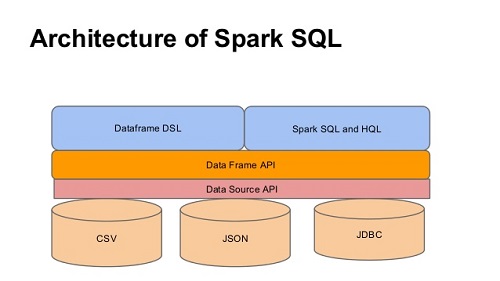
1.3 Spark SQL 的核心特点
1.3.1 易整合
无缝整合 SQL 查询和 Spark 编程,支持 Java、Scala、Python 和 R 四种语言。
1.3.2 统一的数据访问
DataFrame 和 SQL 提供了访问多种数据源的通用方式,包括 Hive、Avro、Parquet、ORC、JSON、JDBC 等,甚至可以跨数据源 Join。
1.3.3 兼容 Hive
Spark SQL 复用 Hive 的前端和元数据存储(Metastore),与现有 Hive 数据、查询、UDF 完全兼容。
1.3.4 标准数据连接
提供 JDBC 和 ODBC 连接,支持 BI 工具直接查询大数据。
二、核心抽象:DataFrame 与 DataSet
2.1 DataFrame 是什么
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。
2.1.1 DataFrame 与 RDD 的本质区别
| 特性 | RDD | DataFrame |
|---|---|---|
| 类型信息 | 无(运行时才知道) | 有 Schema(编译期确定) |
| 优化能力 | Stage 层面简单优化 | Catalyst 优化器深度优化 |
| API 风格 | 函数式(低门槛) | 关系型(更友好) |
| 嵌套数据 | 不支持 | 支持 struct、array、map |
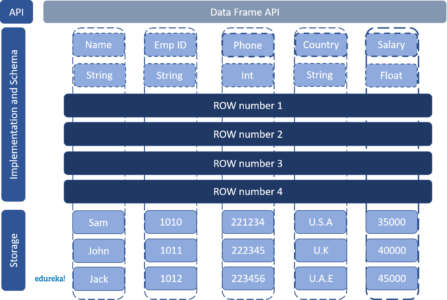
左侧 RDDPerson:Spark 框架本身不了解 Person 类的内部结构,只是将其视为普通对象。
右侧 DataFrame:提供了详细的结构信息,Spark SQL 清楚知道数据集包含哪些列,每列的名称和类型是什么。
2.1.2 Catalyst 优化器:查询计划优化
DataFrame 性能高于 RDD 的核心原因:优化的执行计划。
scala
// 示例代码:Join 后 Filter
users.join(events, users("id") === events("uid"))
.filter(events("date") > "2015-01-01")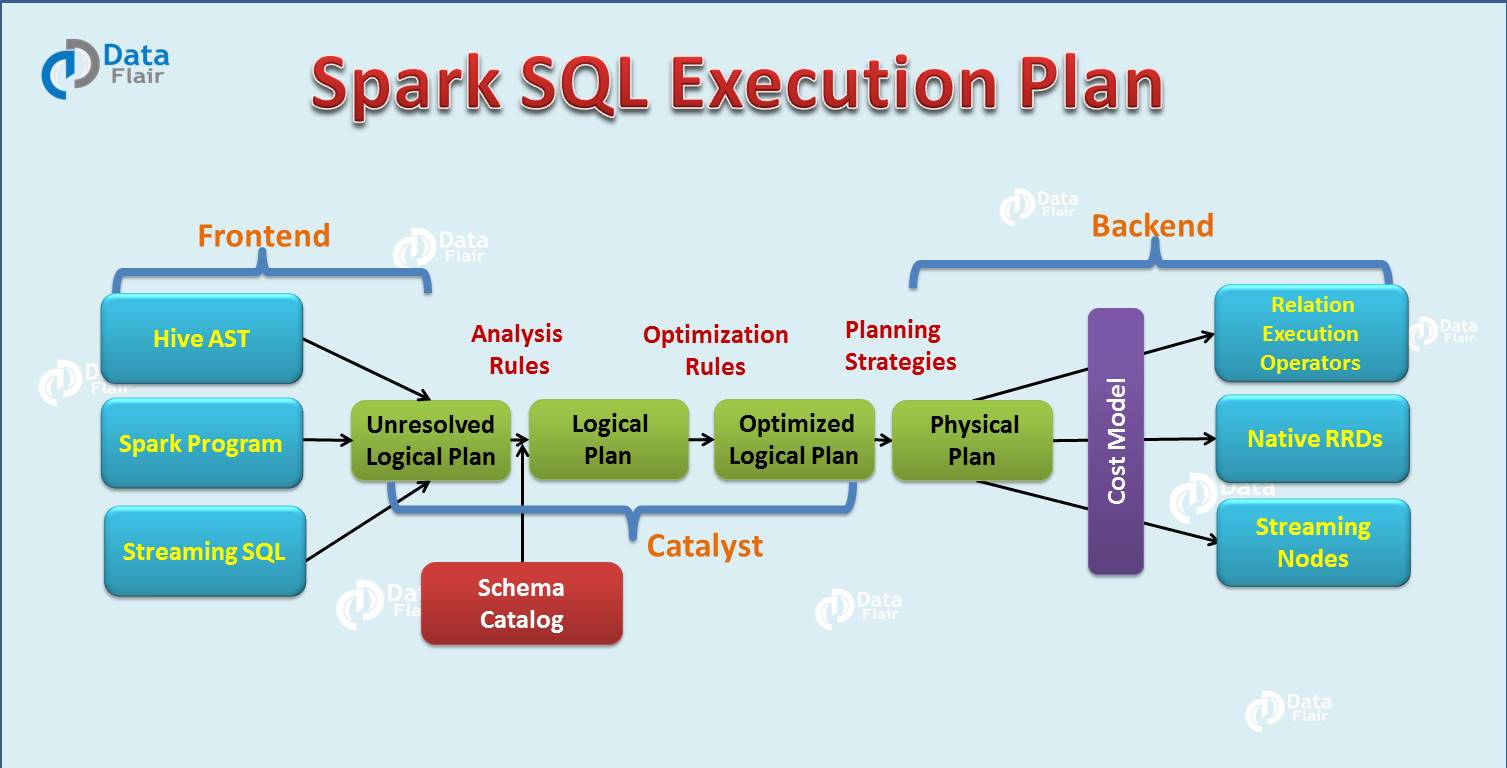
优化过程:
- 逻辑计划:先 Join 再 Filter
- 优化计划:将 Filter 下推到 Join 下方,先对 DataFrame 过滤,再 Join 较小的结果集
- 智能数据源优化 :将 Filter 直接推入数据源(如
SELECT * FROM events WHERE date > ...)
这种**谓词下推(Predicate Pushdown)**是 Spark SQL 性能提升的关键。
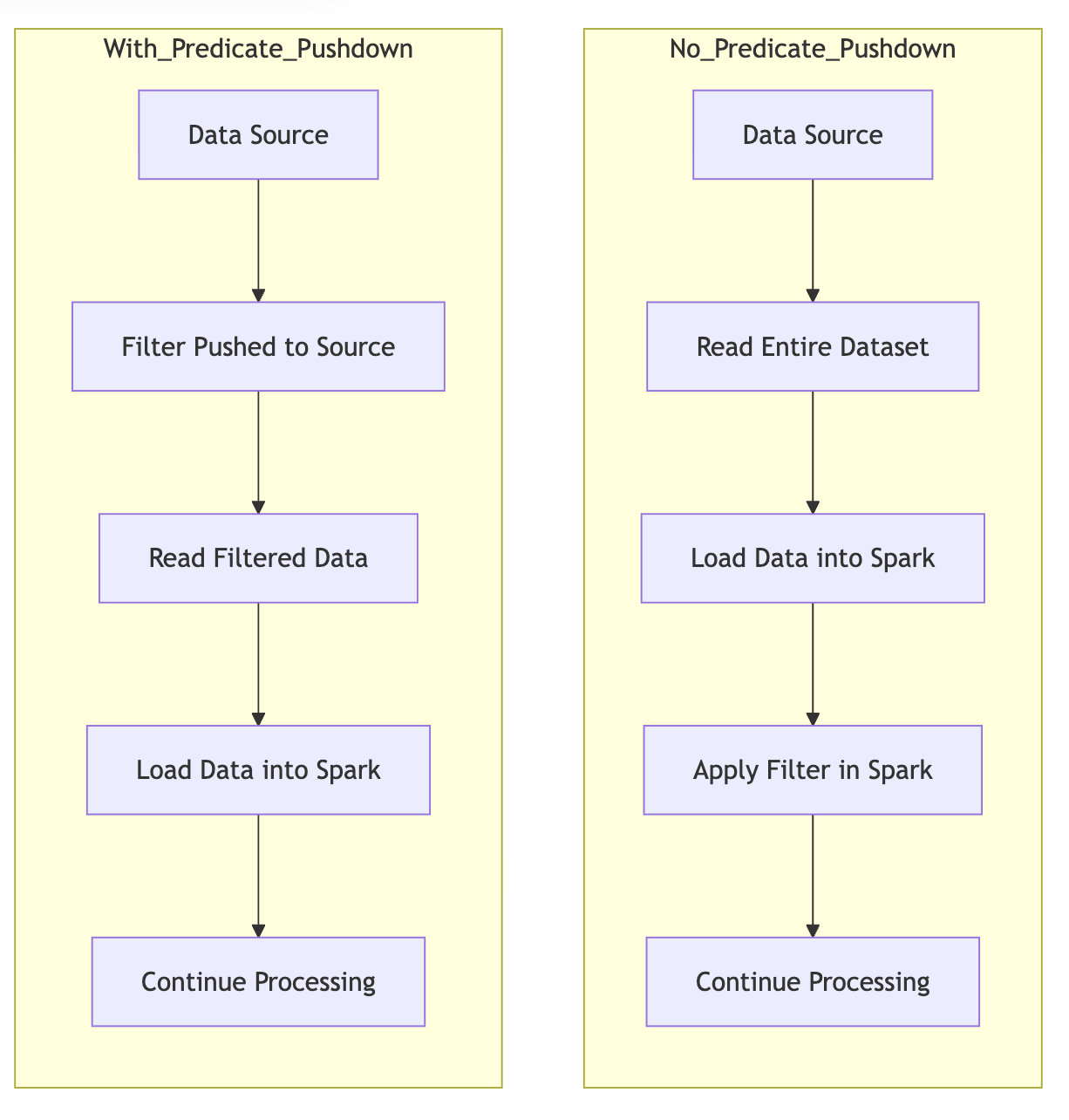
2.1.3 性能对比
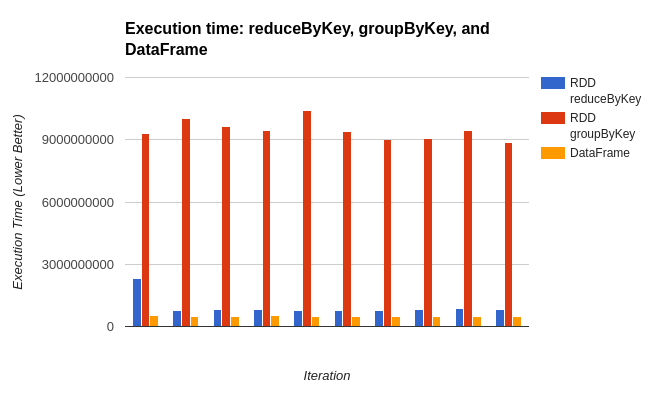
从图中可以明显看出:
- RDD groupByKey(红色):性能最差,执行时间最高
- RDD reduceByKey(蓝色):性能中等
- DataFrame(黄色):性能最优,执行时间最低

2.2 DataSet 是什么
DataSet 是 Spark 1.6 中添加的新抽象,是 DataFrame 的扩展。
2.2.1 DataSet 的核心特性
- 强类型 :如
DataSet[Car]、DataSet[Person] - RDD 的优势:强类型检查、强大的 Lambda 函数能力
- Spark SQL 的优势:优化执行引擎
- 样例类映射:用样例类定义数据结构,属性名称直接映射到字段名
2.2.2 DataFrame 与 DataSet 的关系
scala
type DataFrame = Dataset[Row]DataFrame 是 DataSet 的特例,每一行类型为 Row。可以通过 as 方法将 DataFrame 转换为 DataSet:
scala
case class User(name: String, age: Int)
val df: DataFrame = ...
val ds: Dataset[User] = df.as[User]2.3 RDD、DataFrame、DataSet 三者关系
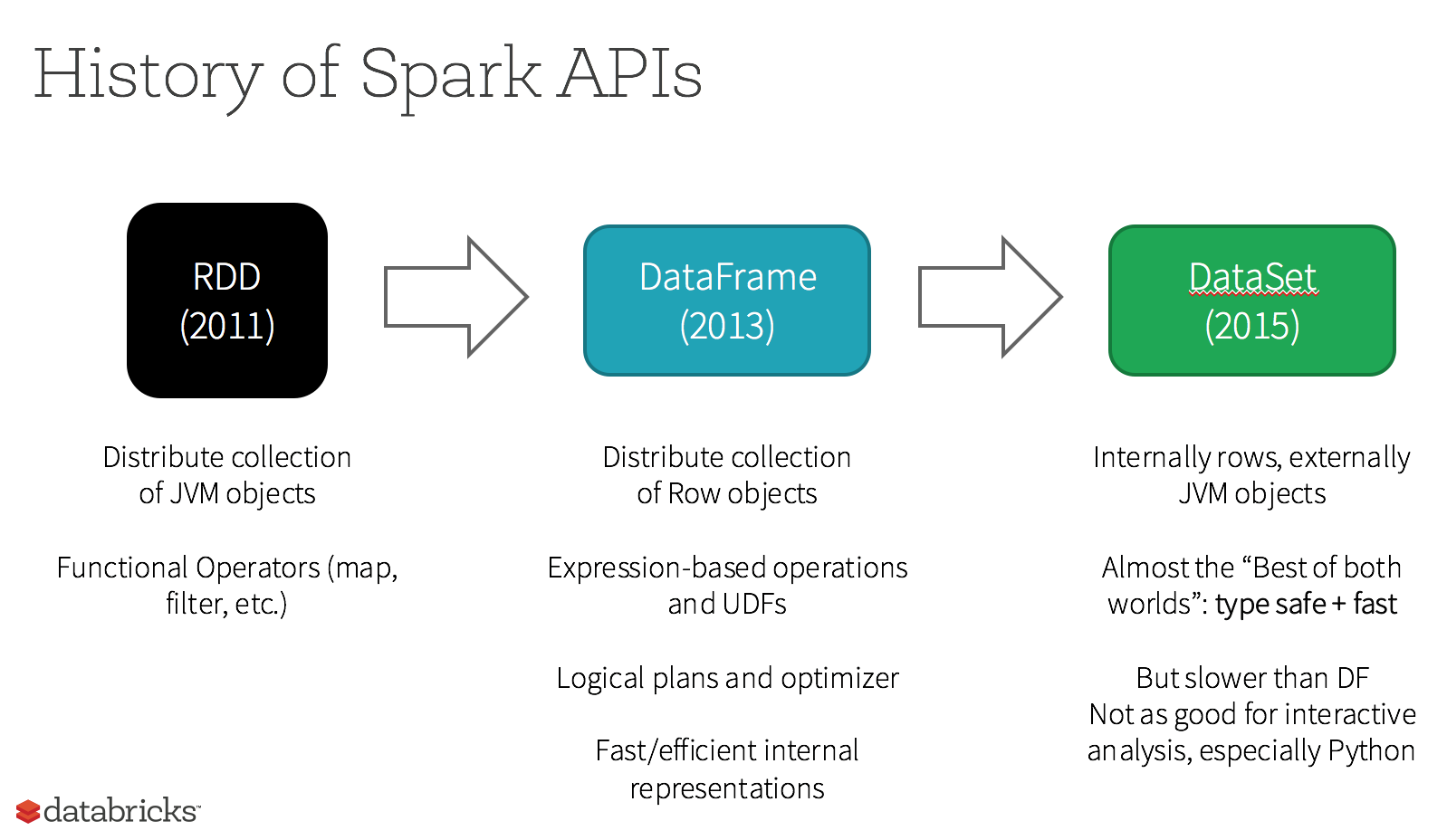
2.3.1 版本演进
- Spark 1.0 => RDD
- Spark 1.3 => DataFrame
- Spark 1.6 => DataSet
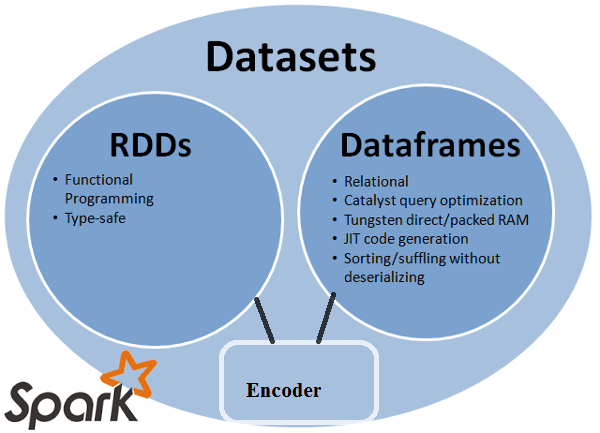
2.3.2 三者的共性
- 都是 Spark 平台下的分布式弹性数据集
- 都有惰性机制(Transformation 不会立即执行)
- 都有共同的函数(filter、排序等)
- 都需要
import spark.implicits._ - 都会根据内存情况自动缓存运算
- 都有 partition 概念
2.3.3 三者的区别
| 维度 | RDD | DataFrame | DataSet |
|---|---|---|---|
| 类型安全 | 是 | 否(Row 类型) | 是 |
| 语法错误 | 运行时 | 编译时 | 编译时 |
| 序列化 | Java 序列化 | Tungsten 二进制 | Tungsten 二进制 |
| GC 性能 | 差(创建大量对象) | 好 | 好 |
| 与 Spark MLlib | 同时使用 | 一般不同时 | 一般不同时 |
| Spark SQL 操作 | 不支持 | 支持 | 支持 |
2.3.4 互相转换
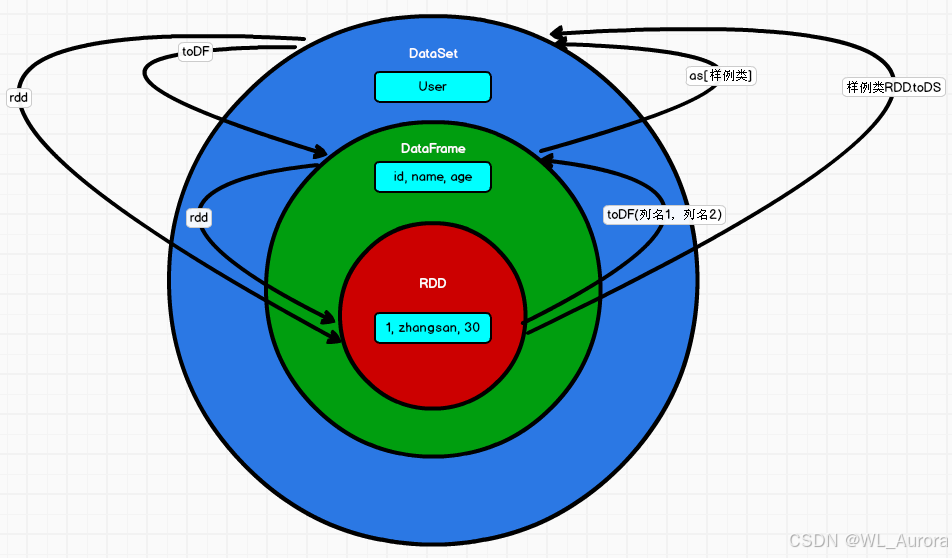
scala
// RDD -> DataFrame
val df = rdd.toDF("name", "age")
// RDD -> DataSet
case class User(name: String, age: Int)
val ds = rdd.map(t => User(t._1, t._2)).toDS
// DataFrame -> RDD
val rdd = df.rdd // RDD[Row]
// DataFrame -> DataSet
val ds = df.as[User]
// DataSet -> RDD
val rdd = ds.rdd // RDD[User]
// DataSet -> DataFrame
val df = ds.toDF三、Spark SQL 核心编程
3.1 新的起点:SparkSession
Spark Core 中需要构建 SparkContext,而 Spark SQL 提供了更高级的入口:SparkSession。
SparkSession 实质上是 SQLContext 和 HiveContext 的组合,内部封装了 SparkContext。
scala
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession
.builder()
.appName("SparkSQLDemo")
.master("local[*]")
.getOrCreate()
// Spark 2.x+ 中,spark-shell 会自动创建名为 spark 的 SparkSession启动 spark-shell 后,你会看到:
Spark session available as 'spark'.3.2 创建 DataFrame
有三种方式:
3.2.1 从 Spark 数据源创建
scala
// 查看支持的数据源格式
spark.read.
// csv format jdbc json load option options orc parquet schema table text textFile
// 读取 JSON 文件
val df = spark.read.json("data/user.json")
df.show()注意 :从文件中读取的数字,不能确定是什么类型,所以用 bigint 接收。
3.2.2 从 RDD 转换
scala
// 方式1:通过样例类转换
case class User(name: String, age: Int)
val rdd = sc.makeRDD(List(("zhangsan", 30), ("lisi", 40)))
val df = rdd.map(t => User(t._1, t._2)).toDF
// 方式2:指定 Schema 转换
import org.apache.spark.sql.types._
val schema = StructType(Array(
StructField("name", StringType),
StructField("age", IntegerType)
))
val rowRDD = rdd.map(t => Row(t._1, t._2))
val df = spark.createDataFrame(rowRDD, schema)3.2.3 从 Hive Table 查询
scala
// 需要配置 Hive 支持
val spark = SparkSession.builder()
.appName("HiveDemo")
.config("spark.sql.warehouse.dir", "/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
spark.sql("SELECT * FROM default.user_table").show()3.3 SQL 语法风格
scala
// 1. 创建 DataFrame
val df = spark.read.json("data/user.json")
// 2. 创建临时视图(Session 级别)
df.createOrReplaceTempView("people")
// 3. 使用 SQL 查询
val sqlDF = spark.sql("SELECT * FROM people WHERE age > 20")
sqlDF.show()
// 4. 创建全局临时视图(应用级别)
df.createGlobalTempView("people_global")
spark.sql("SELECT * FROM global_temp.people_global").show()3.4 DSL 语法风格
DataFrame 提供了一套领域特定语言(DSL),无需创建临时视图。
scala
val df = spark.read.json("data/user.json")
// 查看 Schema
df.printSchema()
// 选择列
df.select("username").show()
// 选择列并计算
df.select($"username", $"age" + 1 as "newage").show()
// 过滤
df.filter($"age" > 30).show()
// 分组聚合
df.groupBy("age").count().show()3.5 DataFrame 与 RDD 互转
scala
// DataFrame -> RDD
val df = sc.makeRDD(List(("zhangsan", 30), ("lisi", 40)))
.map(t => User(t._1, t._2)).toDF
val rdd = df.rdd // RDD[Row]
val array = rdd.collect
// array: Array[Row] = Array([zhangsan,30], [lisi,40])
// 获取字段值
array(0).getAs[String]("name") // zhangsan
array(0)(0) // zhangsan3.6 DataSet 编程
3.6.1 创建 DataSet
scala
// 方式1:使用样例类序列
case class Person(name: String, age: Long)
val caseClassDS = Seq(Person("zhangsan", 2)).toDS()
// 方式2:使用基本类型序列
val ds = Seq(1, 2, 3, 4, 5).toDS
// 方式3:从 RDD 转换
val ds = sc.makeRDD(List(("zhangsan", 30), ("lisi", 49)))
.map(t => User(t._1, t._2)).toDS3.6.2 DataSet -> RDD
scala
val rdd = ds.rdd // RDD[User]
rdd.collect // Array[User] = Array(User(zhangsan,30), User(lisi,49))四、用户自定义函数(UDF/UDAF)
4.1 UDF(用户自定义函数)
scala
// 1. 创建 DataFrame
val df = spark.read.json("data/user.json")
// 2. 注册 UDF
spark.udf.register("addName", (x: String) => "Name: " + x)
// 3. 创建临时表
df.createOrReplaceTempView("people")
// 4. 应用 UDF
spark.sql("SELECT addName(name), age FROM people").show()4.2 UDAF(用户自定义聚合函数)
Spark 3.0 后,推荐使用 Aggregator 强类型方式:
scala
// 输入数据类型
case class User01(username: String, age: Long)
// 缓存类型
case class AgeBuffer(var sum: Long, var count: Long)
// 定义聚合函数
class MyAverageUDAF extends Aggregator[User01, AgeBuffer, Double] {
override def zero: AgeBuffer = AgeBuffer(0L, 0L)
override def reduce(b: AgeBuffer, a: User01): AgeBuffer = {
b.sum += a.age
b.count += 1
b
}
override def merge(b1: AgeBuffer, b2: AgeBuffer): AgeBuffer = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
override def finish(reduction: AgeBuffer): Double = {
reduction.sum.toDouble / reduction.count
}
override def bufferEncoder: Encoder[AgeBuffer] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
// 使用
val ds = spark.read.json("data/user.json").as[User01]
val myAvg = new MyAverageUDAF
val col = myAvg.toColumn
ds.select(col).show()五、数据加载与保存
5.1 通用方式
scala
// 加载数据
val df = spark.read.format("json").load("data/user.json")
// 保存数据
df.write.format("parquet").save("output/")
// SaveMode 选项
df.write.mode(SaveMode.Append).save("output/")
// ErrorIfExists(default) / Append / Overwrite / Ignore5.2 常用数据源
| 格式 | 读取 | 保存 | 说明 |
|---|---|---|---|
| Parquet | spark.read.load() |
df.write.save() |
默认格式,列式存储 |
| JSON | spark.read.json() |
df.write.json() |
每行一个 JSON 对象 |
| CSV | spark.read.format("csv").option("header", "true") |
df.write.csv() |
需指定分隔符、表头 |
| JDBC | spark.read.jdbc(url, table, props) |
df.write.jdbc(url, table, props) |
需 JDBC 驱动 |
5.3 MySQL 读写示例
scala
import java.util.Properties
// 读取
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
val df = spark.read.jdbc("jdbc:mysql://localhost:3306/spark-sql", "user", props)
// 写入
val rdd = spark.sparkContext.makeRDD(List(User2("lisi", 20), User2("zs", 30)))
val ds = rdd.toDS
ds.write.mode(SaveMode.Append)
.jdbc("jdbc:mysql://localhost:3306/spark-sql", "user", props)5.4 Hive 集成
scala
// 1. 添加依赖
// spark-hive_2.12, hive-exec, mysql-connector-java
// 2. 拷贝 hive-site.xml 到 resources
// 3. 代码实现
val spark = SparkSession.builder()
.appName("HiveDemo")
.config("spark.sql.warehouse.dir", "hdfs://localhost:8020/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
// 执行 Hive SQL
spark.sql("SHOW TABLES").show()
spark.sql("CREATE TABLE aa (id INT)")
spark.sql("LOAD DATA LOCAL INPATH 'input/ids.txt' INTO TABLE aa")
spark.sql("SELECT * FROM aa").show()六、实战项目:各区域热门商品 Top3
6.1 数据准备
sql
-- 用户行为表
CREATE TABLE user_visit_action(
`date` STRING,
user_id BIGINT,
session_id STRING,
page_id BIGINT,
action_time STRING,
search_keyword STRING,
click_category_id BIGINT,
click_product_id BIGINT,
order_category_ids STRING,
order_product_ids STRING,
pay_category_ids STRING,
pay_product_ids STRING,
city_id BIGINT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 产品表
CREATE TABLE product_info(
product_id BIGINT,
product_name STRING,
extend_info STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 城市表
CREATE TABLE city_info(
city_id BIGINT,
city_name STRING,
area STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';6.2 需求分析
计算各个区域前三大热门商品(按点击量),并备注每个商品在主要城市中的分布比例。
输出示例:
| 地区 | 商品名称 | 点击次数 | 城市备注 |
|---|---|---|---|
| 华北 | 商品A | 100000 | 北京21.2%,天津13.2%,其他65.6% |
| 华北 | 商品P | 80200 | 北京63.0%,太原10%,其他27.0% |
6.3 实现思路
- 连接三张表,获取完整数据(仅点击记录)
- 按地区和商品名称分组,统计点击次数
- 每个地区内按点击次数降序排列,取 Top3
- 自定义 UDAF 函数实现城市备注
scala
// 核心 SQL 逻辑
spark.sql("SELECT area, product_name, click_count, city_remark(city_name) as city_remark FROM (SELECT area, product_name, count(*) as click_count, collect_list(city_name) as city_list, ROW_NUMBER() OVER (PARTITION BY area ORDER BY count(*) DESC) as rk FROM user_visit_action t1 JOIN city_info t2 ON t1.city_id = t2.city_id JOIN product_info t3 ON t1.click_product_id = t3.product_id WHERE click_product_id IS NOT NULL GROUP BY area, product_name) t WHERE rk <= 3").show()七、总结
| 特性 | 说明 |
|---|---|
| 核心优势 | Catalyst 优化器、Tungsten 执行引擎、统一数据访问 |
| 编程抽象 | DataFrame(弱类型)、DataSet(强类型) |
| 入口对象 | SparkSession(封装了 SparkContext) |
| 查询方式 | SQL 语法、DSL 语法 |
| 扩展能力 | UDF、UDAF(Aggregator) |
| 数据源 | JSON、Parquet、CSV、JDBC、Hive 等 |
Spark SQL 极大地简化了大数据处理的开发复杂度,同时通过底层优化保证了执行效率。在实际工作中,DataSet/DataFrame 已基本取代 RDD 成为首选 API,掌握 Spark SQL 是每一位大数据工程师的必修课。
参考文档:Apache Spark 官方文档、尚硅谷大数据技术之 SparkSQL V3.0
Spark 版本:3.0+
推荐环境:Scala 2.12 / Java 8+