一、概念辨析:字符串、字节与十六进制表示
1. 字符串的本质
C# 中的 string 是 Unicode 字符序列,每个字符占 2 字节(UTF-16 编码)。字符串 "A" 在内存中并非直接存储为 0x41,而是 0x41 0x00(小端序)。这是初学者最容易混淆的起点------字符串不是字节数组,两者之间存在编码转换层。
2. 字节数组的本质
byte\[\] 是原始二进制数据的容器,每个元素取值范围 0-255。它本身没有"文本含义",仅表示数值。
3. 十六进制表示的本质
十六进制是一种人类可读的数值表示法。0xFF、255、11111111b 在数值上完全等价,只是书写形式不同。所谓"十六进制字符串"(如 "FF03A7")是将字节值以十六进制基数编码后的文本形式。
4. 三者关系图谱
字符串 "A" ──UTF-16 编码──→ 字节数组 0x41, 0x00
字符串 "41" ──ASCII 编码──→ 字节数组 0x34, 0x31
字节 0x41 ──十六进制格式化──→ 字符串 "41"
字节 0x41 ──ASCII 解码──→ 字符串 "A"
"字符串字节转十六进制字节数组"这一描述,实际指向的是将表示十六进制数值的字符串,解析还原为对应的字节数组。例如将 "FF03" 转换为 0xFF, 0x03。
二、输入字符串的多种形态
真实场景中,待解析的字符串并非整齐划一,工程实现必须考虑输入的多样性。
1. 紧凑连续型
"AABBCCDD1122" ------ 无分隔符,纯十六进制字符连续排列。这是网络抓包、日志输出的常见格式,解析时按每两个字符一组切分。
2. 空格分隔型
"AA BB CC DD 11 22" ------ 以空格作为字节边界。人工阅读友好,但存在单空格与多空格、Tab 与空格混用等变体。
3. 符号分隔型
"AA:BB:CC:DD:11:22" ------ MAC 地址标准格式,冒号分隔。
"AA-BB-CC-DD-11-22" ------ UUID 片段常见格式,连字符分隔。
"AA,BB,CC,DD,11,22" ------ 配置文件或 CSV 场景,逗号分隔。
4. 前缀标记型
"0xAA 0xBB 0xCC" ------ 带 0x 前缀,常见于 C 语言代码片段或调试输出。
"#AABBCC" ------ 颜色值表示,井号前缀。
"%AA%BB" ------ URL 编码风格,百分号前缀。
5. 混合污染型
"0xAA, 0xBB,\n0xCC\r\n" ------ 包含前缀、逗号、换行符的复杂输入。生产环境中的数据往往如此"脏乱",健壮的解析器必须具备容错能力。
三、解析过程的核心挑战
1. 字符到数值的映射
每个十六进制字符(0-9、A-F、a-f)需映射为对应的 4 位二进制值。A 和 a 等价,代表数值 10;F 和 f 代表数值 15。大小写不敏感是基本要求。
2. 长度奇偶性处理
十六进制字符串长度为偶数时,可完美两两分组;长度为奇数时,最高位字节缺失前导零。例如 "ABC" 应理解为 0x0A 0xBC 还是 0xAB 0xC0?策略选择直接影响结果:
- 前置补零:"ABC" → 0x0A, 0xBC,适用于固定宽度字段
- 后置补零:"ABC" → 0xAB, 0xC0,较少使用
- 严格校验:奇数长度直接报错,强制输入方保证格式正确
3. 非法字符的处置策略
输入中混入非十六进制字符时,不同场景要求不同:
- 严格模式:遇非法字符立即终止并抛出异常,适用于安全敏感场景
- 过滤模式:静默跳过空格、换行、分隔符等,仅提取有效字符,适用于日志清洗
- 替换模式:将非法字符替换为特定值(如 0x00),适用于容错性要求高的嵌入式通信
4. 字节序问题
多字节数据解析时,字符串中字节的排列顺序与目标数值的字节序必须一致:
- 大端序(Big-Endian):字符串 "1234" 解析为字节数组 0x12, 0x34,高位在前。网络协议、Modbus、Java 平台默认采用。
- 小端序(Little-Endian):字符串 "1234" 解析为字节数组 0x34, 0x12,低位在前。x86/x64 处理器、C# 内存布局默认采用。
若混淆字节序,0x1234(十进制 4660)会被误解析为 0x3412(十进制 13330),数值完全错误。
四、解析流程的抽象模型
无论具体实现如何变化,解析过程遵循统一的逻辑框架:
1. 预处理阶段
- 空值校验:输入为空或仅含空白字符时,返回空数组或抛出异常
- 清洗过滤:根据策略移除或替换非法字符、分隔符、前缀标记
- 长度校验:清洗后长度为奇数时,按既定策略处理或报错
- 大小写统一:转为大写或小写,简化后续映射逻辑
2. 转换阶段
- 双字符分组:将清洗后的字符串按每两个字符切分为若干组
- 数值映射:每组字符通过查表或计算转换为 0-255 的整数值
- 字节组装:将数值存入字节数组的对应位置
3. 后处理阶段
- 字节序调整:若目标平台与解析字节序不一致,执行翻转
- 范围校验:确保每个字节值在有效范围内(0-255)
- 结果封装:返回字节数组或包装为只读结构(ReadOnlyMemory)
五、代码实现
csharp
public static byte[] ConvertStringToBytes(String str)
{
List<byte> listBytes = new List<byte>();
string[] hexValuesSplit = str.Trim().Split(' ');
foreach (string hex in hexValuesSplit)
{
listBytes.Add(Convert.ToByte(hex, 16));
}
return listBytes.ToArray();
}六、性能优化的技术维度
1. 内存分配策略
字符串操作在 .NET 中易产生大量临时对象。高性能解析应避免:
- 避免中间字符串创建:不通过 Substring 反复切割,而是直接索引原字符串的字符位置
- 预分配目标数组:根据源字符串长度计算目标字节数组大小,一次性分配
- 栈上缓冲区:小数据量(如小于 1KB)使用 Span 在栈上分配,零堆压力
2. 查表法 vs. 计算法
查表法:预建 256 长度的映射表('0'→0, '9'→9, 'A'→10, 'a'→10, ...),转换时直接索引。优点是指令数少、分支预测友好;缺点是占用少量内存(可忽略)。
计算法:通过条件判断和算术运算映射字符(如 c >= '0' && c <= '9' ? c - '0' : c - 'A' + 10)。优点是无额外内存;缺点是分支多、CPU 流水线易中断。
现代处理器上,查表法通常更快,因其将分支判断转化为确定性的内存访问。
3. 向量化与 SIMD
.NET 6+ 引入的 Vector128 / Vector256 允许单条指令并行处理多个字符。理论上,AVX2 可同时处理 32 字节(16 组十六进制字符),吞吐量提升一个数量级。但实现复杂度高,需处理非对齐内存、剩余字符等边界情况,仅在超高频场景(如网络协议解析网关)值得投入。
七、工程实践中的典型场景
场景一:解析设备上报的 Hex 报文
工业传感器常以 ASCII 编码的十六进制字符串形式上报数据,如 "680400000068"。解析流程:
- 接收串口/网络数据,得到字符串
- 清洗可能的回车换行符
- 校验长度是否符合协议帧结构(如 Modbus RTU 要求特定长度)
- 解析为字节数组后,按协议定义提取帧头、功能码、数据域、CRC 校验
场景二:处理配置文件中的密钥或 ID
配置文件存储设备序列号 "A1B2C3D4E5F6",需转换为字节数组写入硬件寄存器。注意:
- 确认配置文件的编码(UTF-8、GB2312)不影响十六进制字符的解析
- 确认目标硬件要求的字节序
- 校验转换后的长度是否与寄存器宽度匹配
场景三:URL 参数或表单中的 Hex 数据
前端通过 URL 传递十六进制数据(如 ?data=%3A%FF),后端接收后:
- URL 解码(%3A → :,%FF 保持)
- 提取有效十六进制字符
- 解析为字节数组供业务逻辑使用
场景四:日志与调试输出中的数据还原
系统日志记录 "Sent: AA BB CC DD",故障排查时需还原原始字节。解析器需识别方括号、空格等装饰性字符,提取核心数据。
八、健壮性设计原则
1. 防御式编程
- 输入假设最小化:不假定输入总是偶数长度、总是合法字符、总是正确分隔
- 失败快速传播:在预处理阶段即发现并报告错误,避免携带脏数据进入业务逻辑
- 边界条件全覆盖:空字符串、单字符、极大长度、全非法字符等极端情况均需定义行为
2. 可观测性
- 记录原始输入:转换失败时,日志应包含原始字符串(注意脱敏敏感数据)
- 记录处理阶段:标识错误发生在清洗、分组、映射还是校验阶段
- 提供诊断信息:如"位置 7 发现非法字符 'G'",而非笼统的"格式错误"
3. 版本兼容性
协议演进可能导致十六进制字符串格式变化(如新增前缀、变更分隔符)。解析器应:
- 支持配置化分隔符集合,而非硬编码
- 提供 TryParse 模式,允许调用方优雅降级
- 文档化支持的格式版本与废弃计划
九、调试与验证方法论
1. 正向验证
给定已知输入,验证输出是否符合预期:
- "00" → 0x00
- "FF" → 0xFF
- "A1B2" → 0xA1, 0xB2(大端序)
2. 反向验证
将解析结果重新序列化为十六进制字符串,应与原始输入等价(忽略大小写和分隔符差异)。这是检验解析器正确性的黄金标准。
3. 边界测试矩阵
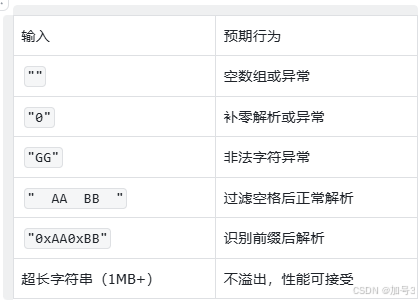
十、结语
"字符串字节转十六进制字节数组"是 C# 开发中看似平凡却暗藏深意的操作。从字符映射的数学本质,到输入清洗的工程实践,再到内存布局的性能博弈,每一个环节都考验着开发者对底层机制的理解深度。在物联网、工业自动化、网络安全等领域,这一基础能力的扎实程度,往往决定了系统在面对真实世界"脏乱"数据时的健壮性。技术之美,常在于对简单问题的深刻洞察。