内核代差揭秘:从 DISTINCT 优化实测看国产数据库的逻辑推理深度
近几年,随着底层基础软件国产化替代的浪潮,许多研发团队都面临着数据库迁移与选型的挑战。作为一名在一线摸爬滚打的后端开发者,我参与了公司核心业务系统的数据库选型评估工作。
在早期的横向对比中,我们往往把注意力集中在"SQL 语法兼容性"和"高并发下的吞吐量"上。但随着底层压测的深入,我们逐渐发现了一个更加硬核、也更容易被忽视的考量维度:数据库优化器(Optimizer)的逻辑推理深度。
今天,我就以日常开发中最常见的去重查询为例,结合我们在测试环境中的详细实操步骤和执行计划,来和大家硬核探讨一下:同样是面对一条冗余的去重 SQL,为什么有的数据库只能"大力出奇迹",而有的数据库却能通过"逻辑降维"实现毫秒级短路?
@toc
一、 实操环境准备:一个"看似愚蠢"却普遍的 SQL
在复杂的企业级业务中,由于多层架构的嵌套或者防御性编程的习惯,开发人员经常会写出带有明确过滤条件,同时又要求结果去重的 SQL 语句。
为了直观对比各大数据库对这类语句的处理能力,我们在测试库中构造了一个极简但数据量庞大的测试场景:
步骤 1:构建测试表并灌入冗余数据
sql
-- 1. 构建一张测试日志表 s1
CREATE TABLE s1 (
id BIGINT PRIMARY KEY,
a INT, -- 模拟业务系统编码
b INT, -- 模拟模块编码
payload VARCHAR(128)
);
-- 2. 模拟灌入海量数据
-- 我们故意制造大量 a=1 且 b=1 的冗余数据,以放大去重时的性能损耗
INSERT INTO s1 (id, a, b, payload)
SELECT generate_series(1, 1000000), 1, 1, 'test_data';
-- 3. 收集统计信息,确保代价优化器能做出准确判断
ANALYZE s1;业务端发起了一个探针查询,目的是确认系统 1 是否调用过模块 1,要求去重返回:
sql
-- 测试用例 SQL
SELECT DISTINCT a, b FROM s1 WHERE a=1 AND b=1;这条 SQL 的特殊之处在于:它的查询目标列(a 和 b)在 WHERE 条件中已经被常量(1 和 1)完全固定了。
二、 物理层面优化的局限:传统 CBO 的"死磕"
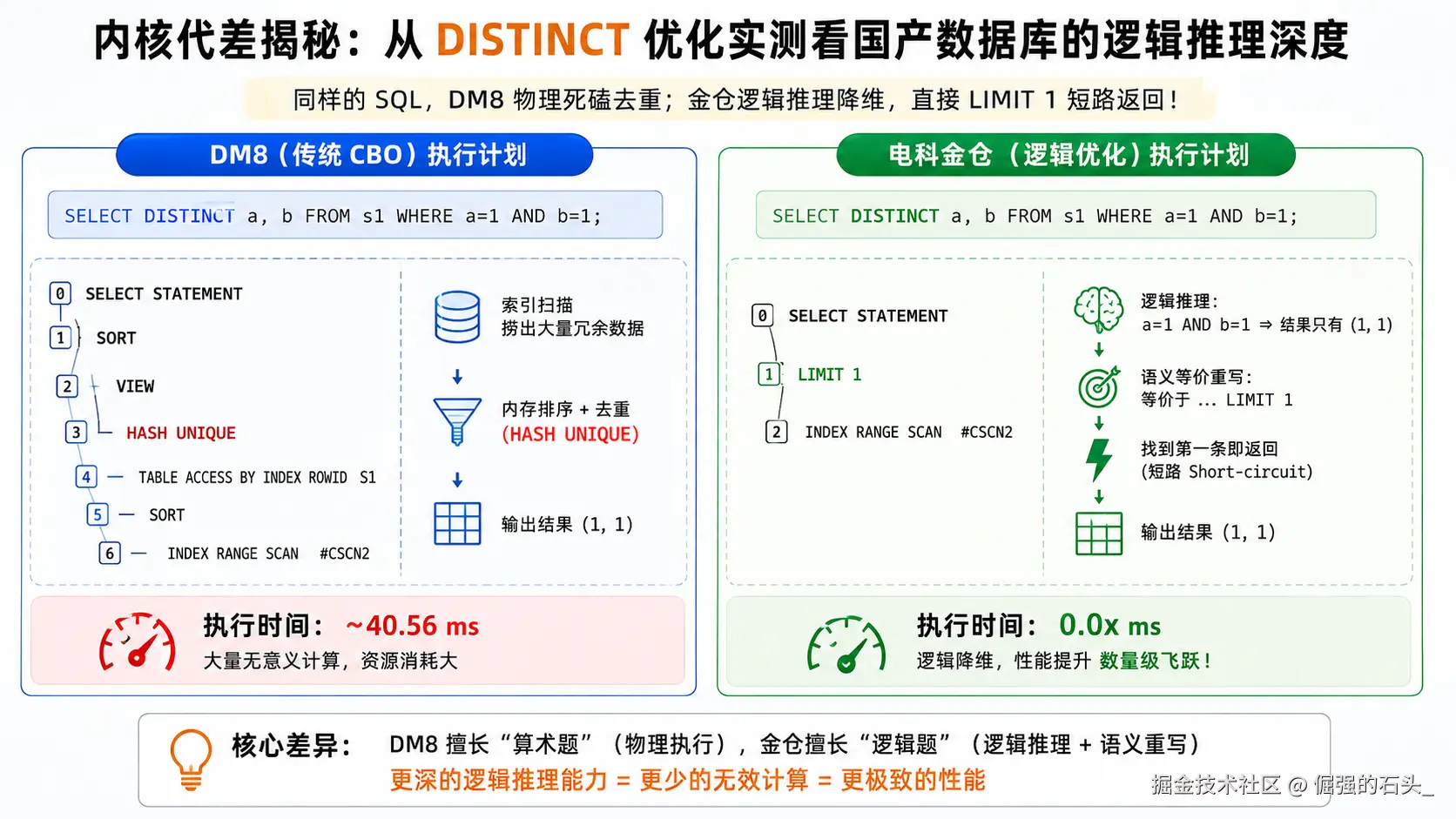
在我们的横向对比测试中,我们首先在国内市场占有率很高的一款数据库,以 DM8 为例上运行了这条语句。
作为一款成熟的商业数据库,其核心优化器是基于代价(CBO)的。当我们执行 EXPLAIN 查看其生成的执行计划时,其底层处理逻辑清晰地展现在我们面前:
步骤 2:在DM8上的执行计划

瓶颈分析: 从这份真实的执行计划中,我们可以看出传统 CBO 的工作模式:
- 它准确地评估了通过索引扫描(第 7 行
#CSCN2)找数据是最便宜的物理路径。 - 随后,它非常"老实"地把满足条件的冗余数据捞出来。
- 最致命的是,它依然在内存中启动了标准的去重算子(第 3 和第 5 行的
#DISTINCT),对这些长得一模一样的数据(全都是1, 1)进行死板的比对去重。
CBO 擅长做"算术题",但缺乏"逻辑思考"。它不会去质问:既然条件里已经锁死了查询结果必然是 (1, 1),我还有必要去硬盘里捞出成千上万条数据来做去重吗? 这种物理层面的"死磕",在数据量爆炸时,会导致系统资源被大量无意义的计算白白消耗。
三、 逻辑推理的降维打击:电科金仓实测
随后,我们将完全相同的表结构和测试 SQL,放在了电科金仓数据库上进行实测。这一次,执行引擎给出了令人惊艳的答案。
步骤 3:在金仓数据库上的实测验证
在金仓数据库中,这项深度逻辑改写能力可能受内核参数控制。我们开启相关特性后执行查询:

在电科金仓的执行计划中,原本沉重无比的分组去重操作彻底消失了,取而代之的是一个轻巧的 LIMIT 1 算子。执行时间从传统的几十毫秒,断崖式降维到了 0.0x 毫秒级别!
四、 底层技术解码:什么是逻辑优化?
为什么电科金仓能给出完全不同的执行路径?这是因为其现代高级优化器在 CBO 介入之前,增加了一层深度的逻辑推理与抽象语法树(AST)重写 引擎。 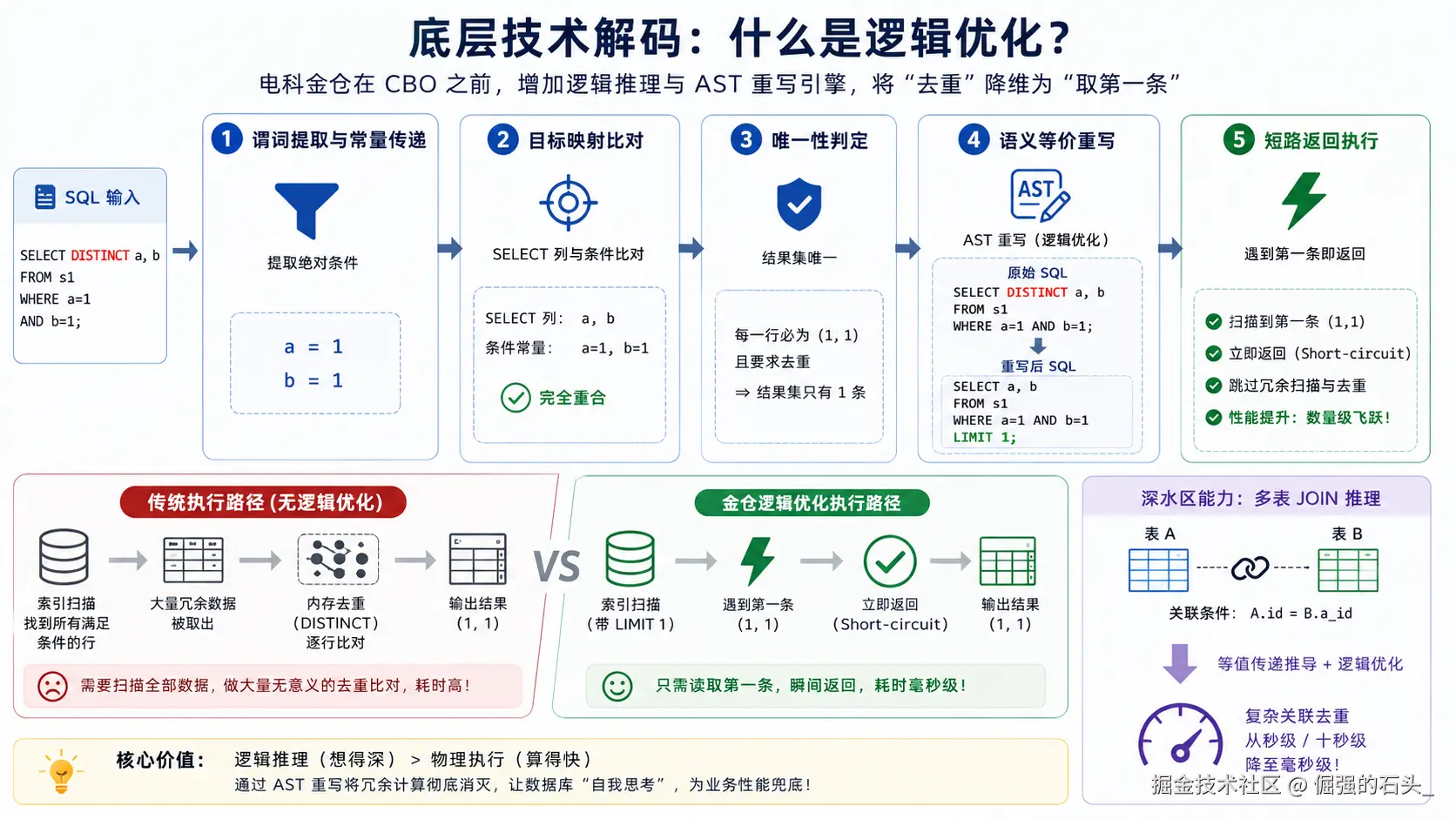
当内核解析器接收到这条 SQL 时,它执行了以下逻辑推导:
- 谓词提取与常量传递 :提取到绝对条件
a=1和b=1。 - 目标映射比对 :发现
SELECT子句要求的返回列,与上述常量条件完全重合。 - 唯一性判定:既然最终输出的每一行必然是固定的常量组合,且业务明确要求去重,那么结果集绝对只有一条。
- 语义等价重写 :优化器直接在内核层面,将原始 SQL 篡改(重写)为
SELECT a, b FROM s1 WHERE a=1 AND b=1 LIMIT 1;。
这个小小的 LIMIT 1 带来了核弹级的性能提升。底层的扫描器在海量数据中,只要碰到第一条符合要求的数据,立刻触发短路返回(Short-circuit)。完美绕过了所有的冗余扫描和内存比对。
值得一提的是,金仓的这种推理能力在深水区的多表 JOIN 关联查询中依然有效,它能通过关联条件进行跨表的"等值传递"推导,将原本可能需要几秒甚至几十秒的关联去重,瞬间截断为毫秒级。
五、 总结与开发者启示
其实咱们团队这几天反反复复测了好几轮。测完之后呢,大家基本都得出一个比较一致的结论。也就是说:我们在看一个数据库底层的能力到底行不行的情况,真的不能光盯着它"算数据的速度快不快",其实更应该去看看它在执行前"考虑问题的逻辑深不深"。
先拿达梦来说吧,它其实就属于那种传统的按部就班去执行底层指令的情况。也就是说,你给它规划好一条执行的路线,接着它就老老实实顺着给你跑完。但是电科金仓数据库在这点上就不太一样了。这个东西的底层逻辑明显要聪明不少。那它是怎么做的呢?其实就是在还没真正去查数据的编译阶段,它自己就在后台把那些常量给传导下去了,顺便还做了一堆逻辑上的推理。这样的话,那些本来根本就没必要去算的重复步骤,它在真正动手去执行之前就已经顺手给清理掉了。
那么,既然底层引擎之间有这么大的差别,这事儿对咱们平时写代码的开发人员来说的话,确实是需要去好好弄明白的:
- 不要迷信全量扫描:通常来说,咱们平时在写 SQL 语句的情况,你一定要尽量把那些用来过滤的条件写得确切一点。为什么要费这个劲呢?原因在于,现在这些写得比较好的数据库底层内核,它是会顺着你给的这些过滤条件去干活的。它们往往会自己去推导出很多咱们写代码时根本没想到的优化逻辑。
- 审视基础软件的进化:其实现在国内这些数据库系统之间的竞争,早就不是随便搞搞就能应付过去的了。现在拼的都是些很深的底层逻辑。你比如说像什么逻辑改写啊,还有那种谓词下推或者传递这种技术(其实就是提前把过滤条件丢给最下层去过滤,好尽早减少需要处理的数据量)。这些玩意儿真的是特别考验写内核代码那些兄弟的技术功底的。往往仅仅只是这些底层细节,现在反而成了各个数据库之间性能差距拉开的关键点。也就是说,如果我们项目里能挑一个这种底层会"自己去动脑子思考"的数据库系统,那么以后咱们自己的业务系统在性能和稳定性方面,基本上就算是稳了,真能帮咱们省下不少排查问题的精力。