嗨~大家好,这里是春栀怡铃声的博客~
"做你害怕的事,然后发现,不过如此~"
目录
[一、 删除单个元素](#一、 删除单个元素)
[二、 删除指定区间](#二、 删除指定区间)
list
带头双向链表(有哨兵位)
构建链表方式
cpp
list<int>l(10, 2);
list<int>l2(l);
list<int>l3(l2.begin(), l2.end()); //vector等的迭代器也可以传给list进行构造sort
std::sort 这种通用的排序算法,底层主要依赖的是类似 快排 的逻辑。这种算法有一个硬性要求:它需要频繁且瞬间地在数据中"大跨步跳跃"。也就是随机访问
比如,它经常需要做这样的操作:瞬间找到数据的正中间位置。这就要求容器必须支持随机访问 (比如直接通过 begin() + 5 跳到第 6 个元素)。vector 在内存中是连续排列的,就像一排连续编号的储物柜,所以它可以瞬间完成这种跳跃计算。
结合 list 的底层结构(内存中分散的节点,仅靠前后的指针像锁链一样相连),在list不能使用 标准库中的sort,如果需要在list 中进行排序,需要自己实现sort 函数
迭代器
C++ 的 std::list 是一个底层实现为双向链表的容器。与 std::vector 的随机访问迭代器不同,std::list 的迭代器是双向迭代器(Bidirectional Iterator) 。这意味着你可以使用 ++ 向前移动,或使用 -- 向后移动,但不能 直接跨越访问**(例如 it + 3 是非法的)。**
end() 和 cend() 指向的是最后一个元素的下一个位置 (越界位置),而 rend() 和 crend() 指向的是第一个元素的前一个位置。它们通常作为循环结束的标志。
| 迭代器类型 | 获取方法 | 遍历方向 | 读写权限 |
|---|---|---|---|
| iterator | begin(), end() |
正向 | 读 / 写 |
| const_iterator | cbegin(), cend() |
正向 | 仅读 |
| reverse_iterator | rbegin(), rend() |
反向 | 读 / 写 |
| const_reverse_iterator | crbegin(), crend() |
反向 | 仅读 |
正向读写:iterator
这是最常用的迭代器。你可以用它来遍历并修改链表中的元素。
cpp
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
++it;
}
cout << endl;正向只读:const_iterator
当你只需要读取数据而不需要修改时,使用 const_iterator 可以提供更好的安全性和性能意图表达。
cpp
list<int>::const_iterator cit = lt.cbegin();
while (it != lt.cend())
{
cout << *cit << " ";
++cit;
}
cout << endl;反向读写:reverse_iterator
当你需要从尾部向头部遍历时,反向迭代器非常方便。
cpp
list<int>::reverse_iterator rit = lt.rbegin();
while (it != lt.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;insert
在指定位置插入数据,注意指定位置的参数 只能传迭代器!
由于直接用迭代器进行++是非法的,在使用 insert 向指定位置插入数据时,需要借用while 循环使得begin()迭代器进行++,从而到达指定位置
但不能 直接跨越访问**(例如
it + 3是非法的)。**
代码如下:
cpp
auto it = lt.begin();
int k = 3;
while (k--)
{
++it;
}
lt.insert(it, 30);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;范围for
cpp
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;push_back
向链表末尾插入数据
cpp
list<int>lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);unique
链表必须有序才可以进行去重
cpp
lt.unique();//前提必须有序才能去重
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;splice
想象一下,你有两列火车(代表两个 std::list)。如果你想把第二列火车的所有车厢移到第一列火车的车头,你不需要把里面的乘客(也就是数据)挨个请出来,再塞进新的车厢里。你只需要解开连接处的挂钩,重新挂载一下就可以了。
这就是 splice 的工作原理:它可以把一个list中的节点 转移 到另一个 list 的指定位置中。因为底层只是修改了几个指针的指向,所以这个过程不发生任何数据的拷贝,也不需要重新分配内存。这在处理包含复杂数据(比如大型结构体或类)的链表时,效率高得惊人。
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
int x = 0;
cin >> x;
it = find(lt.begin(), lt.end(), x);
if (it != lt.end())
{
//lt.splice(lt.begin(), lt, it);
lt.splice(lt.begin(), lt, it, lt.end());//剪切粘贴
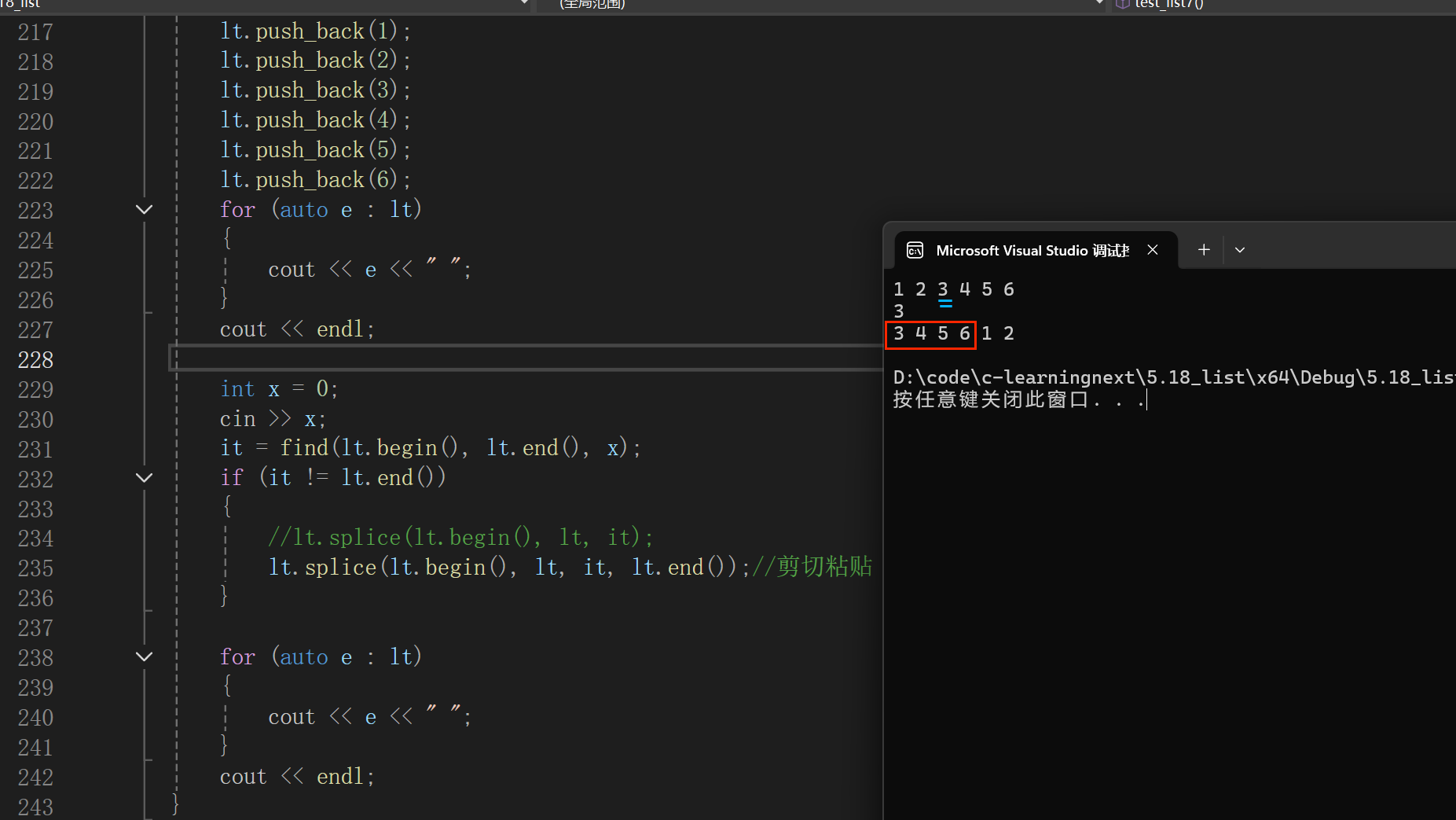
}建立一个list ,里面存放着1-6,
我们输入一个x,在链表中查找 x ,
找到x,it 指向x
a.使用 splice 将 it 到链表末尾的数据 ( lt.end() ) 剪切粘贴到链表最前方
lt.splice(lt.begin(), lt, it, lt.end());
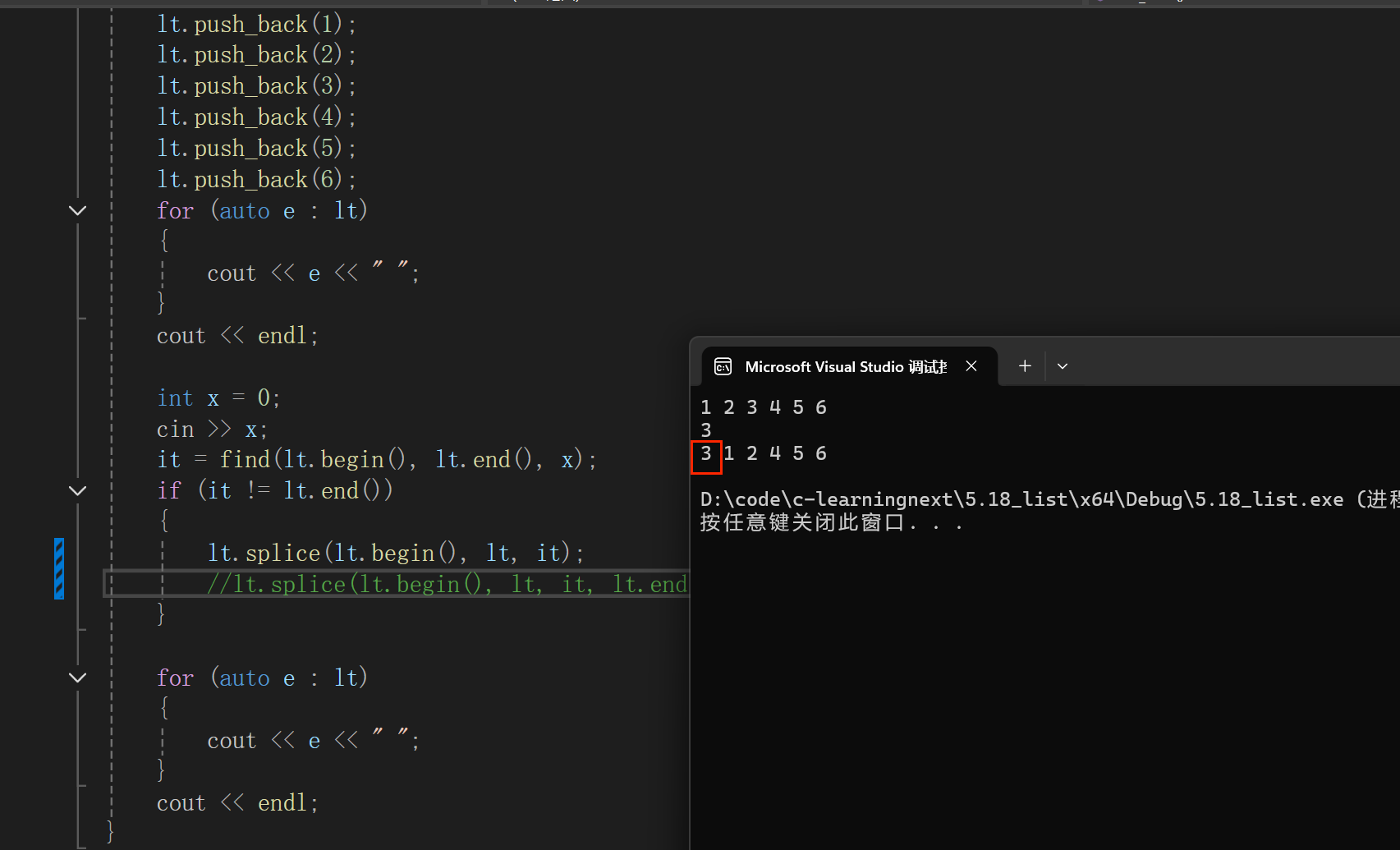
b.使用splice 将 it 指向的x 剪切粘贴到链表最前方
lt.splice(lt.begin(), lt, it);
merge
核心作用是将两个已经排好序 的 list 合并成一个包含所有元素、且依然有序的新 list 。
就像我们在讲 splice 时提到的"指针魔法"一样,merge 的底层也是单纯通过重新打断、连接节点的指针来实现的 。因此,它不需要创建任何新节点,也不需要拷贝数据,效率极高。
我们可以通过下面这段代码来看看它是怎么工作的:
cpp
#include <iostream>
#include <list>
int main() {
std::list<int> list1 = {1, 3, 5, 7};
std::list<int> list2 = {2, 4, 6};
// 将 list2 合并到 list1 中
list1.merge(list2);
// 此时 list1 变成了 {1, 2, 3, 4, 5, 6, 7}
// list2 因为节点都被转移走了,变成了空链表 {}
return 0;
}可以把这个过程想象成合并两叠已经按学号排好的试卷:你只需要每次对比两叠试卷最上面(也就是链表当前的头部节点)的那一张,哪张学号小,就把它抽出来放到最终的一叠里。因为不需要像 std::vector 那样移动后续元素腾出空间,整个合并过程非常丝滑。
emplace_back
你可以把它和我们常用的 push_back 放在一起比较。它们的目的都是在链表的尾部添加一个新元素,但它们底层处理数据的方式有很大的不同。
打个直观的比方: 假设你要往房间(list)里放一把复杂的新椅子(比如一个包含多个属性的类对象)。
-
push_back的做法是:你在工厂(当前代码作用域)先完整组装好 这把椅子,然后再把它搬运(拷贝或移动)进房间里。这个过程产生了一把"临时椅子"。 -
emplace_back的做法是:你直接把一堆木头和钉子(构造函数所需的参数)带进房间,在房间预留的位置上直接现场组装。
因为省去了"先在外面建好临时对象,再拷贝/移动进来,最后销毁临时对象"的过程,emplace_back 在处理复杂数据类型时,性能表现更好。
我们来看一个具体的代码例子,对比它们的用法:
cpp
#include <iostream>
#include <list>
struct A
{
public:
A(int a1 = 1, int a2 = 1)
:_a1(a1)
, _a2(a2)
{
cout << "A(int a1=1,int a2=1)" << endl;
}
A(const A& aa)
:_a1(aa._a1)
,_a2(aa._a2)
{
cout << "A(const A& aa)" << endl;
}
int _a1;
int _a2;
};
void test_list3()
{
list<A> lt;
A aa1(1, 1);
lt.push_back(aa1);
lt.push_back(A(2, 2));
lt.emplace_back(aa1);
lt.emplace_back(A(3, 3));
cout << endl;
lt.emplace_back(3, 3);
}在使用 emplace_back 时,你不需要写出类名 直接把参数( 3,3 ) 扔给它,list 的底层会自动抓取这些参数去调用 A 的构造函数,直接在链表节点里把对象建好。
lt.emplace_back(3, 3);
上面的这句代码就不能使用 push_back 实现
erase
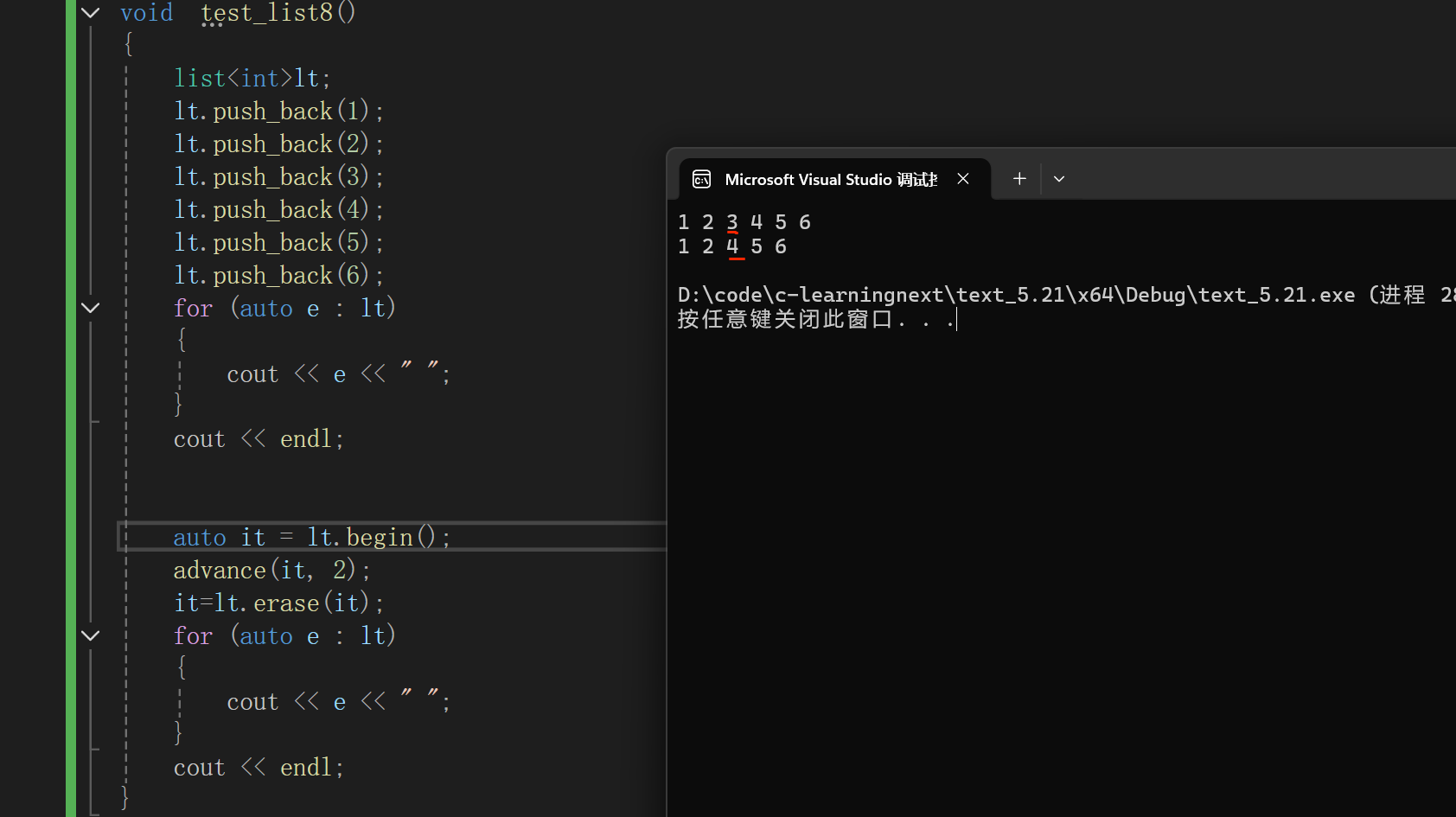
一、 删除单个元素
如果你只需要删除特定位置的元素,传入指向该位置的迭代器即可。
cpp
#include<iostream>
#include<list>
using namespace std;
void test_list8()
{
list<int>lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
auto it = lt.begin();
advance(it, 2);
it=lt.erase(it);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test_list8();
return 0;
}
二、 删除指定区间
如果你想一次性删除一段连续的元素,可以传入两个迭代器:first 和 last。 注意: 删除的区间是左闭右开的 [first, last),也就是说,last 指向的元素不会被删除。
cpp
std::list<int> myList = {1, 2, 3, 4, 5, 6, 7};
auto it_start = myList.begin();
std::advance(it_start, 1); // 指向 2
auto it_end = myList.begin();
std::advance(it_end, 5); // 指向 6
// 删除区间 [2, 6),也就是删除 2, 3, 4, 5
// 返回的迭代器将指向 6
auto next_it = myList.erase(it_start, it_end);
// 此时 myList 变为: {1, 6, 7}