给Agent配上解释器
- 原文链接:www.langchain.com/blog/give-y...
- 原文作者:Hunter Lovell

要点摘要
- 解释器介于串行工具调用与完整沙箱之间。 智能体可在受控能力之上做代码级组合,而无需继承一整个运行环境。
- 解释器状态是第三种上下文面。 消息历史承载模型当下要推理的内容;文件系统承载持久化产物;解释器状态承载尚不必进入模型输入的实时工作值。
- 程序化工具调用以中间件形式接入。 白名单内的工具在解释器内出现在
tools命名空间下,可与任意模型配合;早期测试中,部分任务 token 用量最多减少约 35%。
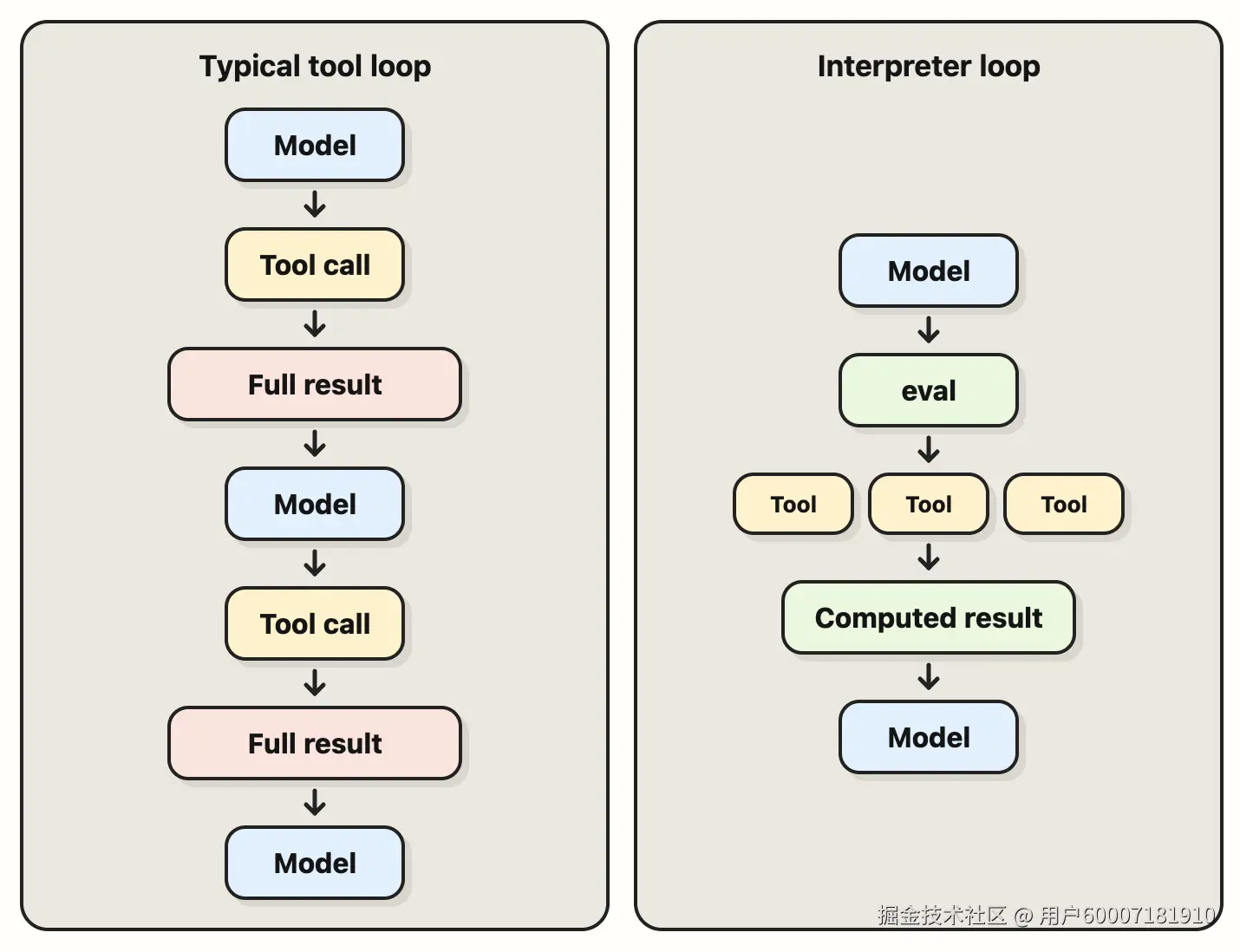
TL;DR 我们正在为 Deep Agents 加入解释器:智能体可在智能体循环内编写并执行代码的小型嵌入式运行时。它在「一次一个工具调用」与「完整沙箱」之间提供中间地带,使智能体能表达多步工作、把中间状态挡在模型上下文之外,并以更可预期的方式执行代码与动作。
什么是解释器?
解释器是一种小型嵌入式运行时,智能体在工作过程中可向其中编写代码。功能上,它像给智能体一个 Python 或 Node REPL:可定义变量、检查值、编写辅助函数,并在多次调用之间复用状态。
如今许多智能体已通过向主机或沙箱环境下发命令来执行代码。当任务是环境级工作------运行命令、安装依赖、操作文件系统------这很合适。解释器针对的是另一层:智能体编写的代码在智能体循环内部运行,用于协调委派、组合工具调用、转换结构化数据,并决定哪些信息应回到模型。
typescript
// 智能体编写的代码大致如下
const rows = [
{ team: "support", tickets: 18 },
{ team: "infra", tickets: 7 },
{ team: "sales", tickets: 11 },
];
const total = rows.reduce((sum, row) => sum + row.tickets, 0);
const busiest = rows.sort((a, b) => b.tickets - a.tickets)[0];
`${busiest.team} has the most tickets. ${total} tickets total.`;这为智能体提供了新场所,用于表达难以干净地塞进一连串工具调用的行为。智能体获得多步逻辑的工作区,同时 Harness 仍控制该工作区能触及什么。解释器可保存临时状态,并只把重要部分返回。
解释器所处的位置
谈到智能体时,人们通常会先想到为它挂载各类工具。
在最简单的智能体形态里,智能体在循环中使用这些工具:模型调用一个工具、查看 observation,再决定下一步。这种一步一步的方式便于调试与评估,许多工作流也确实需要对即时 observation 进行推理。
沙箱在此基础上为智能体提供 bash 工具,针对环境运行命令、安装依赖、处理文件。
但两端都有缺点:沙箱可以处理本地过程(因为它也能写代码去做),但可能更难供给与扩展;而纯串行工具循环在中间步骤大多只为下一步服务时,会显得别扭。
部分智能体工作落在这两个极端之间,解释器正好嵌入其中。它们让智能体在受控能力之上做代码级组合,而不必获得完整环境。模型可写一小段程序,在既有能力上表达控制流,而 Harness 通过主机决定哪些能力可用。
有意做得更受限
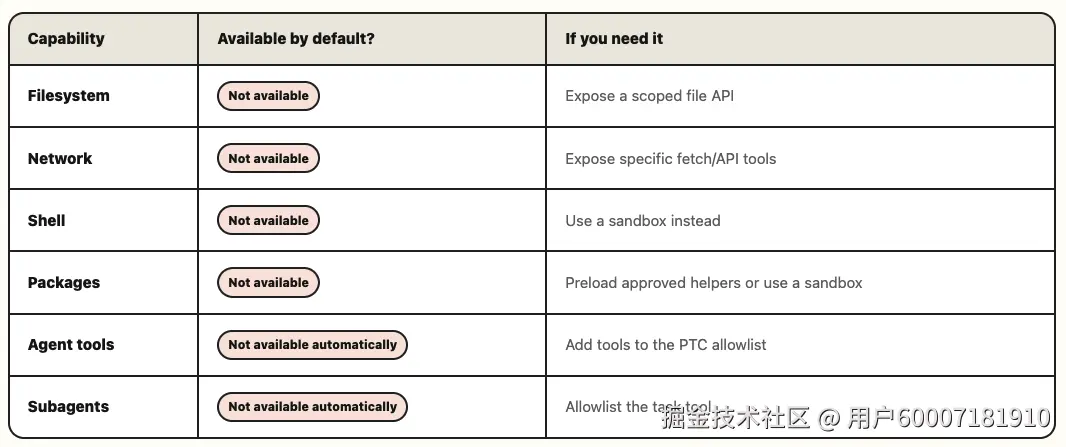
我们称之为解释器,而不只是代码运行时,因为解释器是有意受限的。默认情况下,它没有你在正常编程环境里会期望的那些 API:没有文件系统、没有网络、没有 shell、没有包安装、也没有墙钟时间访问。智能体从基本控制流与对象操作起步:对象、数组、map、JSON,以及小型语言运行时的其余部分。
这些能力通过指向主机运行时的显式桥接暴露。若智能体需要调用工具、从受控文件系统 API 读取、抓取 URL,或委派给子智能体,Harness 必须刻意暴露该能力。例如,下面这段脚本只有在我们把 fetch、read_file 和 task 工具显式桥接到解释器时才能工作:
typescript
// 调用 `fetch` 工具发起网络请求
const response = tools.fetch("https://docs.langchain.com");
// 调用 `readFile` 工具从智能体文件系统读取文件
const file = tools.readFile("SPEC.md");
// 调用 `task` 工具生成子智能体
const subagentOutput = tools.task({
description: "Do you know the muffin man?"
});主机运行时(与运行 Harness 的是同一个)包含智能体借助解释器可执行的全部动作,并显式决定解释器代码能调用其中哪些。解释器是智能体在该边界上的可编程一侧。
默认情况下,解释器只有语言特性,不会像沙箱那样给予泛化的主机访问。任何触及外部世界的行为都必须经过你指定的显式桥接。
我们有意把解释器设计得更受限,主要有以下几方面原因:
- 更小的动作面: 使用 bash 或沙箱时,起点很宽:智能体拥有类似计算机的东西,你再从中限制它能做什么。使用解释器时,起点很窄:智能体只有语言运行时,能力再被刻意加回。当你的威胁模型需要进程或 VM 隔离时,这并不能替代沙箱;但它意味着智能体默认不会继承宽泛的主机访问。
- 可预期性: 小而固定的运行时使智能体行为更易预判与评估。若解释器拥有宽泛的主机访问或丰富的库面,同一目标可通过许多不同策略达成,输出会更不一致、更难测试。保持默认环境最小,并迫使额外能力穿过显式桥接,可收窄智能体的动作空间、让失败模式更清晰、让结果更可重复。
你在 Figma、Shopify、AWS 等系统的架构中能看到相同形状:一侧运行受约束的代码,主机在另一侧暴露受控 API 边界。
解释器能解锁什么
近期若干系统收敛到类似模式:给模型一个小型、受控的运行时,让它写一点代码来管理控制流与中间状态。Cloudflare 的 Code Mode、Anthropic 的 Programmatic Tool Calling(PTC),以及 RLM 风格工作流,从不同角度指向同一想法。在 Deep Agents 中,解释器是以与模型无关的方式获得该模式的途径。以下是几处已证明有用的场景:
解释器状态作为上下文面
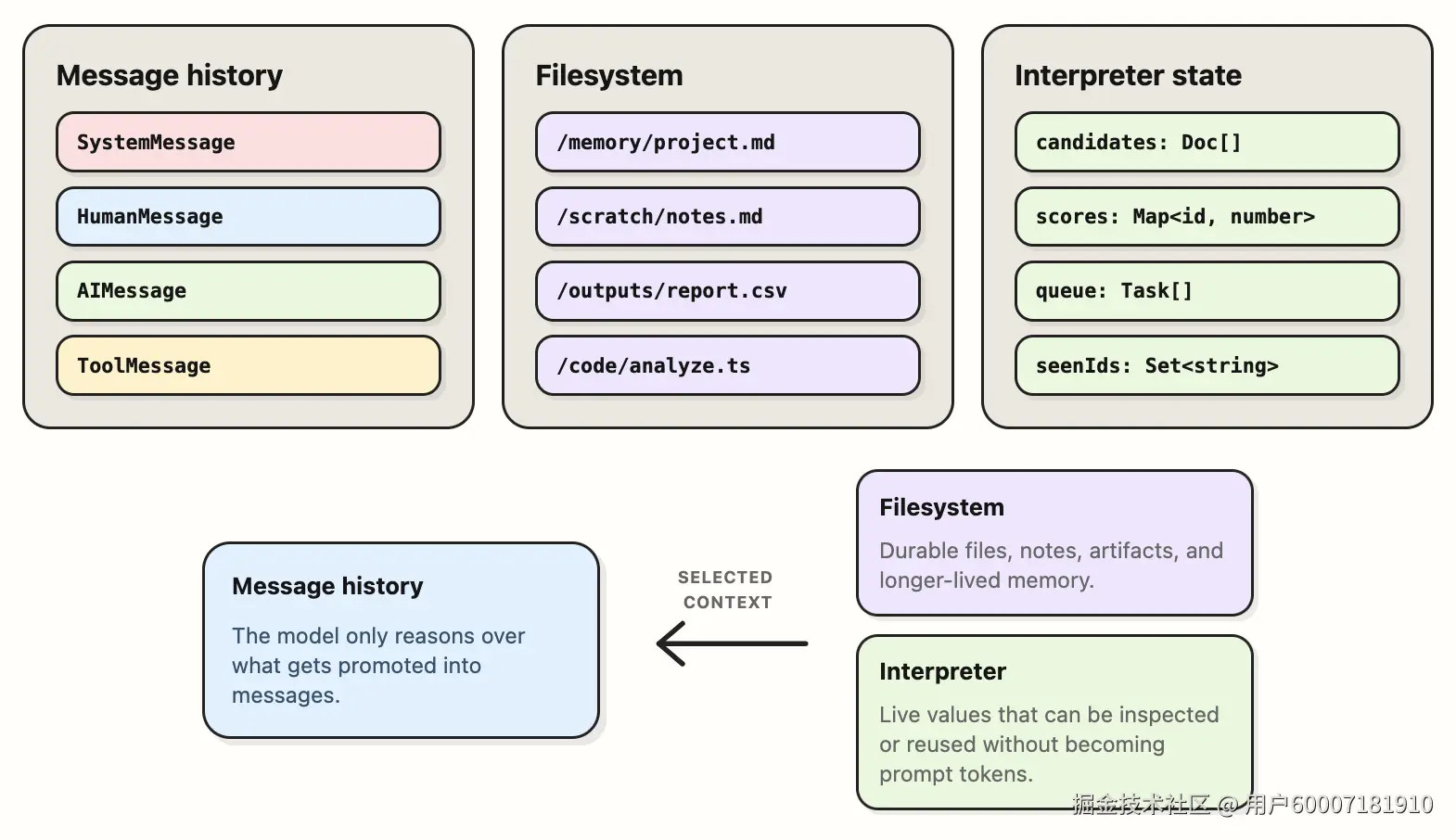
智能体 Harness 已在若干面上组织上下文:
-
消息历史是模型立即可用的上下文。
- 它昂贵且受注意力约束:模型能接受一百万 token,并不意味着会对每个 token 同等充分地推理。(例如 context rot)
-
文件系统为智能体提供存放持久化产物、笔记、中间文件与更长寿命工作记忆的场所。
- 它持久且灵活,但迫使智能体把工作状态序列化进文件,之后再重建。
- Harness 的工作之一,是控制文件系统与消息历史之间的上下文流动。
解释器状态给智能体多一个选项。值可留在运行时里,作为数组、对象、map、计数器、队列与辅助函数。模型不必把每个中间值都变成 prompt 文本,但仍可让解释器稍后检查或复用这些值。
这与 REPL 和一次性命令为何感受不同类似。若在 REPL 里定义变量,你提交下一条命令时它仍在。你不必把它变成 stdout、写入文件,或在继续下一步之前重建。当智能体多次调用解释器时同样适用:它可以直接复用上一次调用留下的值。
这使解释器对智能体循环内的状态很有用。消息历史承载模型现在需要推理的内容;文件系统承载持久化产物与环境级工作;解释器状态承载可能稍后有用、但尚不必成为模型输入的实时工作值。
程序化工具调用
Anthropic 的 Programmatic Tool Calling(PTC) 是该模式的另一版本:工具调用发生在智能体编写的代码内部,而不是作为一连串由模型中介的动作。
若模型调用工具、收到完整结果、对其推理、再调用下一个工具,每个小步骤都会变成又一次模型往返。若智能体能编写直接调用工具的代码,它可把中间输出留在运行时里,只返回最终结果或精选证据。
在 Deep Agents 中,PTC 以中间件实现,而非模型提供方行为。开发者传入白名单,白名单内的工具出现在全局 tools 命名空间下,每个工具作为解释器可用 await 调用的 async 函数暴露。这意味着你可以为任意模型(包括开源模型)启用 PTC。
typescript
const topics = ["retrieval", "memory", "evaluation"];
const reports = await Promise.all(
topics.map((topic) =>
tools.task({
description: `Research ${topic} in Deep Agents and return three concise findings.`,
subagent_type: "general-purpose",
}),
),
);
reports.join("\\n\\n");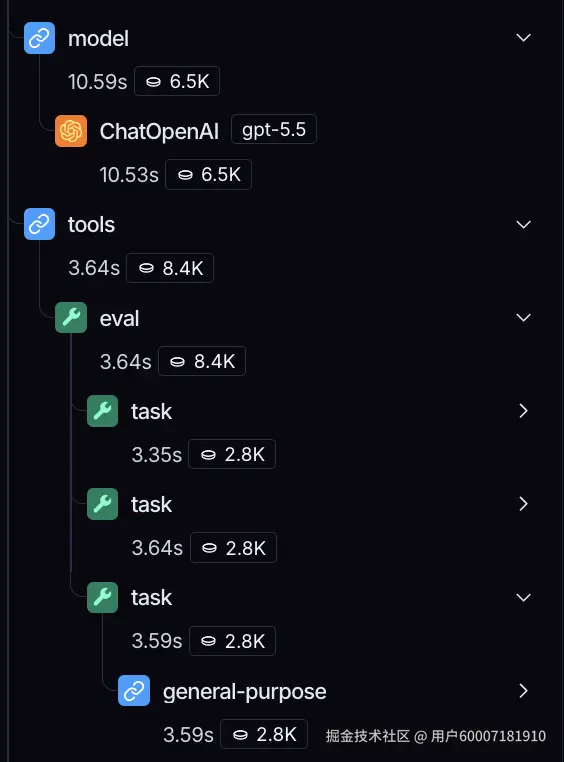
在我们的一些早期测试中,这种工具调用方式在部分任务上最多少用约 35% 的 token。(我们在来自 OOLONG trec-coarse 数据集的一组任务上做了评估。)
处理大规模数据集
以文档密集型任务为例:智能体需要对 10,000 份文档进行分类、抽取或综合信息。
对标准工具调用智能体,自然形态是一长串由模型中介的动作。模型搜索、把结果拿回上下文、决定下一步检查什么、再调用工具、再拿回更多结果,如此重复。对小任务,该循环足够。但在规模上开始崩坏:
- 很难验证智能体是否真的按预期程序执行。
- 过多中间上下文被路由回模型。
- 很容易撞上延迟、上下文或工具调用上限。
- 模型被迫通过历史管理过多工作状态时,回答质量会下降。
解释器形态则不同。模型可编写代码,在运行时里保留文档与搜索状态,以程序方式批量迭代、打分或过滤候选,并仅对选定切片调用子智能体。解释器不把每个中间结果都返回给模型,而是返回紧凑的证据集:匹配的文档、已抽取的字段、未决案例,或少数值得推理的摘要。
解释器并不会神奇地推理全部 10,000 份文档。它给智能体更好的方式去控制搜索空间,并决定什么应进入模型上下文。
typescript
const candidates = documents
.map((doc) => ({ doc, score: scoreDocument(doc, query) }))
.filter(({ score }) => score > 0.75)
.sort((a, b) => b.score - a.score)
.slice(0, 10);
const reports = await Promise.all(
candidates.map(({ doc }) =>
tools.task({
description: `Extract evidence from ${doc.id} for: ${query}`,
subagent_type: "general-purpose",
}),
),
);
reports.join("\n\n");递归编排
另一个相关想法是 Recursive Language Models(RLM)。RLM 把长 prompt 视为外部 REPL 环境的一部分,再让模型编写代码去检查、分解,并对选定片段递归调用模型。
Deep Agents 的解释器并未在模型层实现 RLM,但在 Harness 层仍有相关联系:代码可在模型上下文之外保存工作状态,选取其中一片,并只把该片传入下一次模型或子智能体调用。
在 Deep Agents 中,tools.task 是这里的桥接。解释器代码可选定一片工作、把该片委派给子智能体、把结果与既有运行时状态合并,并只把综合输出返回给主模型。
在 Deep Agents 中如何工作
在 Harness 层,解释器是智能体循环与小型运行时之间的中间件。该中间件会:
- 为智能体增加
eval工具 - 创建并维护 QuickJS 上下文
- 执行智能体的 TypeScript 代码
- 在配置时捕获
console.log输出 - 将最终表达式送回模型上下文
eval 工具不是「在主机上运行任意代码」。代码在解释器上下文内运行。若需与外部世界通信,须通过主机运行时暴露的桥接进行。
程序化工具调用是其中一种主机桥接。开发者传入 ptc 白名单,白名单内的工具在解释器内出现在 tools 命名空间下(例如 tools.getWeather(...)),每个工具作为解释器可用 await 调用的 async 函数暴露。真实工具调用仍由主机运行时执行。
从模型到解释器再回到模型的整体流程大致如下:
- 模型编写代码并调用
eval - QuickJS 在解释器上下文内求值代码
- 解释器代码可选调用白名单内的工具
- 主机运行时执行真实工具调用
- 结果回到解释器
- 最终表达式回到模型上下文
同一次运行中的多次 eval 可共享同一活跃解释器上下文,这正是值能像 REPL 状态一样行为的原因。对话轮次之间也可做快照,但应把它视为保存可序列化工作数据的方式,而非保存活跃句柄或主机资源。
内存、超时等运行时控制同样位于主机与解释器之间的这一边界上:
- 内存上限
- 每次
eval超时 - 程序化工具调用次数上限
- 结果大小上限
- 控制台捕获
- 轮次间快照

在 Deep Agents 中如何使用
可用 create_deep_agent 安装解释器并添加中间件:
bash
uv add "deepagents[quickjs]"
python
from deepagents import create_deep_agent
from langchain_quickjs import CodeInterpreterMiddleware
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware()],
)(以下为 TypeScript 侧的同等安装与接入方式。)
bash
pnpm install deepagents @langchain/quickjs
typescript
import { createDeepAgent } from "deepagents";
import { createCodeInterpreterMiddleware } from "@langchain/quickjs";
const agent = createDeepAgent({
model: "openai:gpt-5.5",
middleware: [createCodeInterpreterMiddleware()],
});若要让解释器代码调用智能体工具,请用白名单启用程序化工具调用。工具不会自动暴露给解释器代码;你必须选择哪些工具可以穿过主机运行时桥接。
python
agent = create_deep_agent(
model="openai:gpt-5.5",
middleware=[CodeInterpreterMiddleware(ptc=["task"])],
)
typescript
const agent = createDeepAgent({
model: "openai:gpt-5.5",
middleware: [createCodeInterpreterMiddleware({ ptc: ["task"] })],
});启用 PTC 后,白名单内的工具出现在全局 tools 命名空间下。每个工具都是 async 函数,模型收到的是解释器最终输出,而不是每一次中间工具结果。
Deep Agents 提供 Python 与 TypeScript 版本。文档中有更多关于解释器的信息,以及完整的中间件选项与运行时控制说明。