大家好 👋,我是 Moment,目前正在使用 Next.js、NestJS、LangChain 开发 DocFlow。这是一个面向 AI 场景的协同文档平台,集成了基于
Tiptap的富文本编辑、NestJS后端服务、实时协作与智能化工作流等核心模块。在这个项目的持续打磨过程中,我积累了不少实战经验,不只是
Tiptap的深度定制、编辑器性能优化和协同方案设计,也包括前端工程化建设、React 源码理解以及复杂项目架构实践。如果你对 AI 全栈开发、文档编辑器、前端工程化或者 React 源码相关内容感兴趣,欢迎添加我的微信
yunmz777一起交流。觉得项目还不错的话,也欢迎给 DocFlow 点个 star ⭐
复杂 Agent 最容易失稳的地方,往往不是后面某个工具没调好,也不是某个模型节点回答得不够漂亮,而是用户输入刚进入系统时,任务就已经被读错了。
在单轮聊天里,理解偏一点,常见后果只是回答不够贴题。但在 Agent 系统里,用户的一句话会继续影响路由、规划、检索、工具选择、风险判断、人工确认、执行节点和评估节点。入口处写进 State 的第一个判断,后面往往会被当成事实继续消费。它一旦错了,系统不是答偏一句,而是整条执行链都会跟着偏。
所以,Agent 的意图识别不能只停留在分类标签上。它真正要做的是把用户输入还原成一份可执行前提:用户最终想要什么、当前处在哪个阶段、哪些上下文可以确认、哪些信息还缺失、是否存在歧义、是否需要工具、风险等级是多少、能不能自动继续执行。
这也是为什么在真实工程里,意图识别不是一个可有可无的小模块,而是 Agent 入口层的第一道闸门。
Agent 接管的是执行链,不是单轮回答
聊天模型面对的是一轮输出。用户问得不清楚,模型可以回答得保守一点,或者让用户补充信息。Agent 不一样,它接管的是一条执行链。
用户输入之后,后面可能接着一串运行时角色:
Router负责选择任务路径Planner负责拆解执行步骤Retriever负责检索资料或上下文Tool Selector负责选择工具Risk Gate负责判断风险等级Confirmation Gate负责判断是否需要人工确认Executor负责执行动作Evaluator负责判断结果是否合格
这些节点消费的不是一句自然语言,而是系统对用户目标和当前阶段的理解。入口处如果把任务读错,后面所有节点都会建立在错误前提上。
比如用户说:
帮我确认一下这封报价邮件能不能发。
如果入口直接判成 send_email,后面可能会进入外发准备、收件人检查和发送确认链路。但用户真实意思也可能只是审阅邮件内容是否合适,这时更应该进入 review_email 或 rewrite_email。第一步错了,后面不是回答偏了,而是执行资源、风险等级和确认流程都会跟着错。
Anthropic 的 Building Effective Agents 把 routing 描述为先对输入分类,再导向专门的后续任务。这个判断放在 Agent 里非常关键:路由不是语义润色,而是在选择一条处理链。
生产级 Agent 还要识别当前处在任务曲线的哪一段。目标可能是发送报价邮件,但当前阶段也许只是收集资料、生成草稿、等待审核或确认发送。LangGraph 强调持久化、interrupt 和 human-in-the-loop,本质上也是在支持这种阶段化执行,而不是假设一次分类就能决定整个任务。
用户输入通常是一份被压缩过的任务包
真实用户很少像填表一样,把目标、约束、阶段、资源和风险都写清楚。更常见的是,一句话里同时塞进主目标、子目标、限制条件和期望输出。
例如:
- 帮我看下这个线上报错,先别动生产,能复现的话给我修复建议
- 帮我查一下这个客户最近情况,再判断要不要继续推进
- 帮我整理这份材料,必要的话生成一版发给领导的摘要
- 帮我把这个功能做出来,但不要影响现在的登录流程
- 按我们之前那个架构继续写,输出一版可以给同事看的方案
这些输入都不是单一意图。
第一句里包含排查、环境限制、复现判断和修复建议。第二句里包含信息检索、业务判断和销售推进。第三句里包含材料整理、摘要生成和面向领导的表达改写。第四句里包含实现意图和风险边界。第五句里包含历史上下文引用、架构延续和输出对象要求。
如果只给它们打一个 debug、research、writing 或 coding 标签,下游会丢失大量关键前提。系统真正需要的是一份可以继续路由、拆解、扇出、聚合的任务结构,而不是一个 winner label。
复杂任务不应该被压扁成单一标签,而应该被展开成一组可执行前提:用户最终想要什么,当前先做哪一步,哪些信息已经确定,哪些信息还缺,是否需要工具,是否允许自动执行,是否需要人工确认。
意图识别本质上是在选择运行模式
很多人把意图识别理解成识别用户想干什么,但在 Agent 系统里,它更重要的职责是选择运行模式。
同一句用户输入,后面可能接上完全不同的执行方式:
- 直接回答
- 检索增强回答
- 单工具调用
- 多工具串行
- 多源并行检索
- 多 Agent 分工
- 先澄清再继续
- 先确认再执行
- 直接拒绝
这些模式的成本、风险和状态流转完全不同。
比如用户说:
帮我整理这个客户的资料,看看要不要继续跟进。
这个任务可能需要先检索 CRM、再查最近沟通记录、再判断商机阶段、最后生成建议。它不是简单的 customer_support,也不是简单的 research。入口处要判断是否需要工具、是否需要多个数据源、是否要进入销售 Agent、是否涉及敏感客户信息、是否需要人工确认后才能更新 CRM 状态。
所以,意图识别更像 mode selection。它不是在给句子取名字,而是在为 Agent Runtime 选择合适的解题框架。
如果用户只是问一个概念,系统直接回答就可以。如果用户要求基于资料判断,系统需要先检索或读取上下文。如果用户要发送邮件、删除数据、发布文章或修改生产配置,系统即使理解得很清楚,也不能自动执行,必须进入确认或审批。
单标签分类会把复杂任务压扁
单标签分类适合简单问答,例如用户问怎么重置密码,系统打上 reset_password 标签就可以进入固定流程。但复杂 Agent 面对的是组合任务、阶段任务和高风险任务,一个标签通常不够用。
比如这句话:
帮我查这家公司最近融资,再判断适不适合合作,再给一版会议提纲。
里面至少有四层任务:
- 资料检索
- 事实核验
- 商业判断
- 写作生成
只打 research 会丢掉判断和写作。只打 business_analysis 又会漏掉前面的检索和核验。只打 writing 更危险,因为它可能直接生成一版看起来完整、但没有事实依据的会议提纲。
它更像一张任务图,而不是一个标签。
单标签分类还有一个更危险的问题:它会把不确定性压扁。生产系统真正怕的不是低置信,而是高置信地走错路。
Rasa 的 fallback 机制 会把低置信或 top 意图分数过近视为触发 fallback 的信号,必要时先让用户确认或重述。这个思想迁移到 Agent 里很重要:如果 review_email 和 send_email 的意图很接近,系统不能硬选一个继续执行。因为在普通聊天里这只是答偏,在 Agent 里可能直接点亮外发链路。
更合理的做法是显式保留候选意图、置信差距、缺失槽位和澄清条件。入口处不能只输出一个标签,而要输出一份可以被下游消费的意图信封。
入口层要先还原主目标,而不是马上选工具
用户输入进入 Agent 后,第一件事不是马上选 Agent,也不是马上调工具,而是先把这句话还原成一个可执行任务。
主意图不是句子里第一个动词,也不是出现最多的动作,而是用户最终想得到的结果。
比如:
帮我查一下这家公司最近融资,再判断适不适合合作,再给一版会议提纲。
这句话的第一个动作是查,但主意图不是查资料,而是判断是否适合合作。查融资只是支撑判断的资料来源,会议提纲只是判断完成后的输出形态。
入口层应该整理成这样的结构:
ts
type ParsedIntent = {
primaryIntent: "business_decision";
subIntents: [
"company_research",
"partnership_evaluation",
"meeting_outline_draft",
];
currentStage: "intake";
expectedOutput: "meeting_outline";
needsRetrieval: true;
needsAnalysis: true;
needsWriting: true;
};这一步的价值在于,后面的 Router 不会只拿到一个模糊标签,而是能知道任务应该先检索,再分析,最后生成文档。
如果入口层把主目标识别错了,后面的所有节点都会合理地做错事。Planner 会拆错步骤,Retriever 会查错资料,Tool Selector 会选错工具,Executor 会执行错动作,Evaluator 还可能用错误标准判断结果合格。
所以,主意图识别要优先问三个问题:
- 用户最终想得到什么结果
- 当前这句话是在推进哪个阶段
- 句子里的其他动作是目标、手段、约束,还是输出格式
这三个问题比单纯分类更重要。
补全上下文不是替用户乱猜,而是把可确认事实装进 State
用户说的很多话都依赖上下文,比如:
按刚才那个方案继续优化一下。 帮我把这个改得更稳一点。 这封邮件能不能直接发? 用我们之前那个架构来写。 还是按上次那个风格来。
这些句子单独看都不完整。系统必须先补上下文,否则主意图很容易识别错。
但上下文补全有一个边界:只能补系统已经可靠知道的信息,不能替用户编事实。
可补的上下文通常来自这些地方:
- 当前对话里的上一轮任务、上一版输出、用户刚上传的文件
- 用户明确选中的文本、图片、邮件、文档或代码片段
- 当前 workspace、项目、仓库、客户、任务状态
- LangGraph checkpoint 里保存的历史阶段、待确认动作、已完成步骤
- 长期记忆里稳定的偏好,例如输出语言、文章风格、技术栈偏好
- 系统工具清单、权限范围、风险规则和当前可访问资源
例如用户说:
帮我把这个发给客户。
如果当前上下文里刚生成了一封客户邮件,系统可以补全这个大概率指的是刚才那封邮件。但这不代表可以直接发送,因为发送邮件是高影响动作,还需要确认收件人、正文、附件和发送意图。
更合理的理解是:
ts
type ContextCompletion = {
resolvedObject: {
type: "email_draft";
source: "previous_turn";
confidence: 0.86;
};
unresolvedFields: ["recipient_confirmation", "final_send_confirmation"];
safeToProceedWithoutQuestion: false;
};补上下文的目标不是让 Agent 显得很聪明,而是让它知道哪些信息已经确定,哪些还不能确定。
这里尤其要注意一个边界:上下文补全不能覆盖用户当前明确表达。
如果历史偏好里用户喜欢详细说明,但这次用户明确说简单点,那就以当前输入为准。如果之前的任务是在写文章,但这次用户上传了代码并说优化一下,就不能继续沿用文章优化路径。
稳定的上下文补全应该遵循这个优先级:
- 当前用户明确输入优先
- 当前选中内容或上传文件优先
- 当前任务状态优先
- 短期对话上下文次之
- 长期记忆只做偏好补充,不能替代当前事实
- 不确定的信息必须标记为
unresolved,不能硬写进事实区
歧义要分类型处理,不能一律追问
用户输入里的歧义并不都一样。有些歧义可以用上下文自动消解,有些歧义必须追问,有些歧义则可以先安全执行一部分。
第一类是对象歧义。用户说这个、那个、刚才那个方案,如果上下文里只有一个候选对象,可以直接绑定。如果有多个候选对象,就需要追问。
例如:
把这个优化一下。
如果当前页面只选中了一段文章,可以直接优化。如果当前对话里同时有文章、代码、图片 prompt 和 PRD,就不能硬猜。
第二类是动作歧义。
例如:
帮我看看这封邮件能不能发。
这里的发可能是发送动作,也可能是审阅语气是否合适。因为发送属于高影响动作,系统应该默认进入审阅,而不是直接进入发送链路。
第三类是阶段歧义。
用户最终目标可能是上线功能,但当前只是想做方案设计。比如:
帮我做一下这个支付功能。
它可能是要写代码,也可能是要先出方案、风险点和接口设计。没有仓库上下文、支付渠道、回调方式、幂等策略和安全边界时,不能直接写生产代码。
第四类是范围歧义。
例如:
优化一下这篇文章。
这可能是只改表达,也可能是重写结构、增加资料、补图、删重复内容。低风险场景可以按用户历史偏好直接执行,但最好保持原结构,不乱扩写。如果用户明确说彻底优化,才进入结构重写。
第五类是权限和风险歧义。
例如:
把这些无用数据删掉。
这里即使对象看起来清楚,也不能直接执行。删除数据、发送邮件、发布内容、修改订单、更新权限、导出敏感信息,都必须进入确认或审批。
所以,歧义处理不是简单判断问不问,而是判断这类不确定性会不会影响执行安全、成本和结果质量。
可以自动消解的歧义,就不要打断用户。会改变执行路径、风险等级或外部副作用的歧义,必须暂停。
多意图并存时,要拆成任务图,而不是硬选一个标签
用户的一句话里经常同时存在多个意图。入口层不能强行 winner-take-all,而要判断这些意图之间是什么关系。
有些是串行关系:先查资料,再分析判断,最后生成提纲。前一步的输出会成为后一步的输入,这种任务必须按顺序执行。
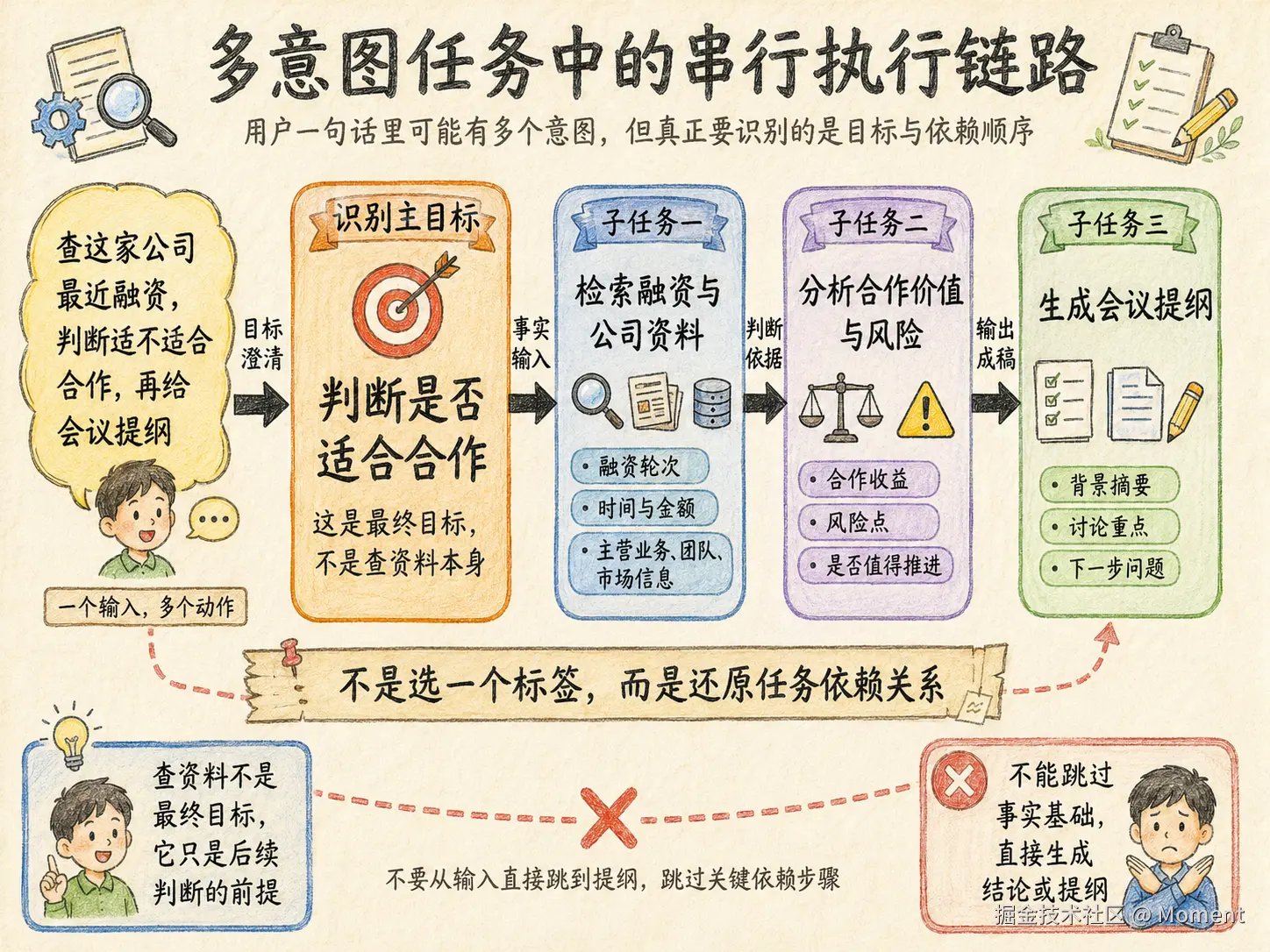
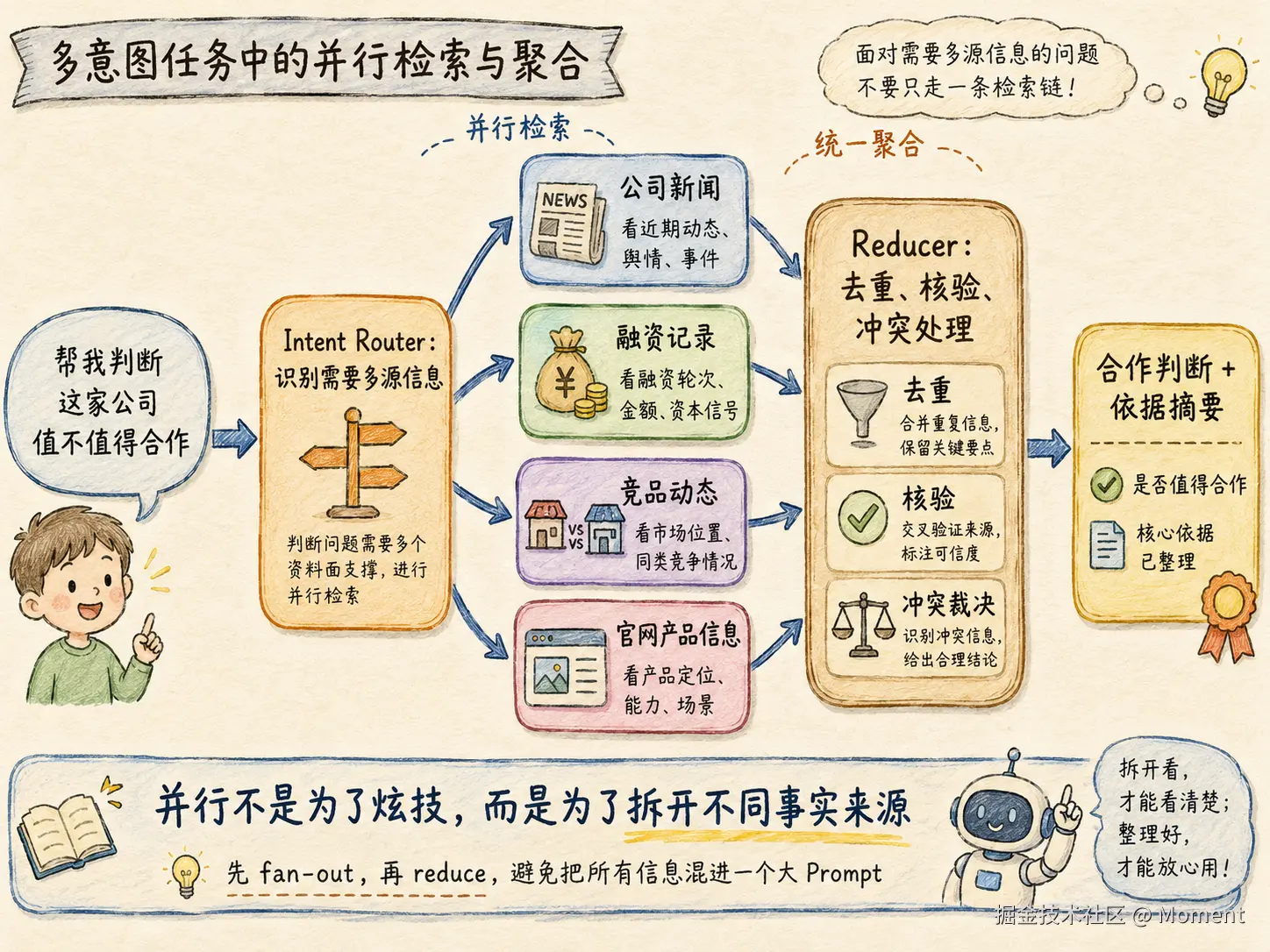
有些是并行关系:同时查公司新闻、融资记录、竞品动态、官网产品信息,最后聚合成判断。它适合 fan-out 并行检索,再由 Reducer 聚合。
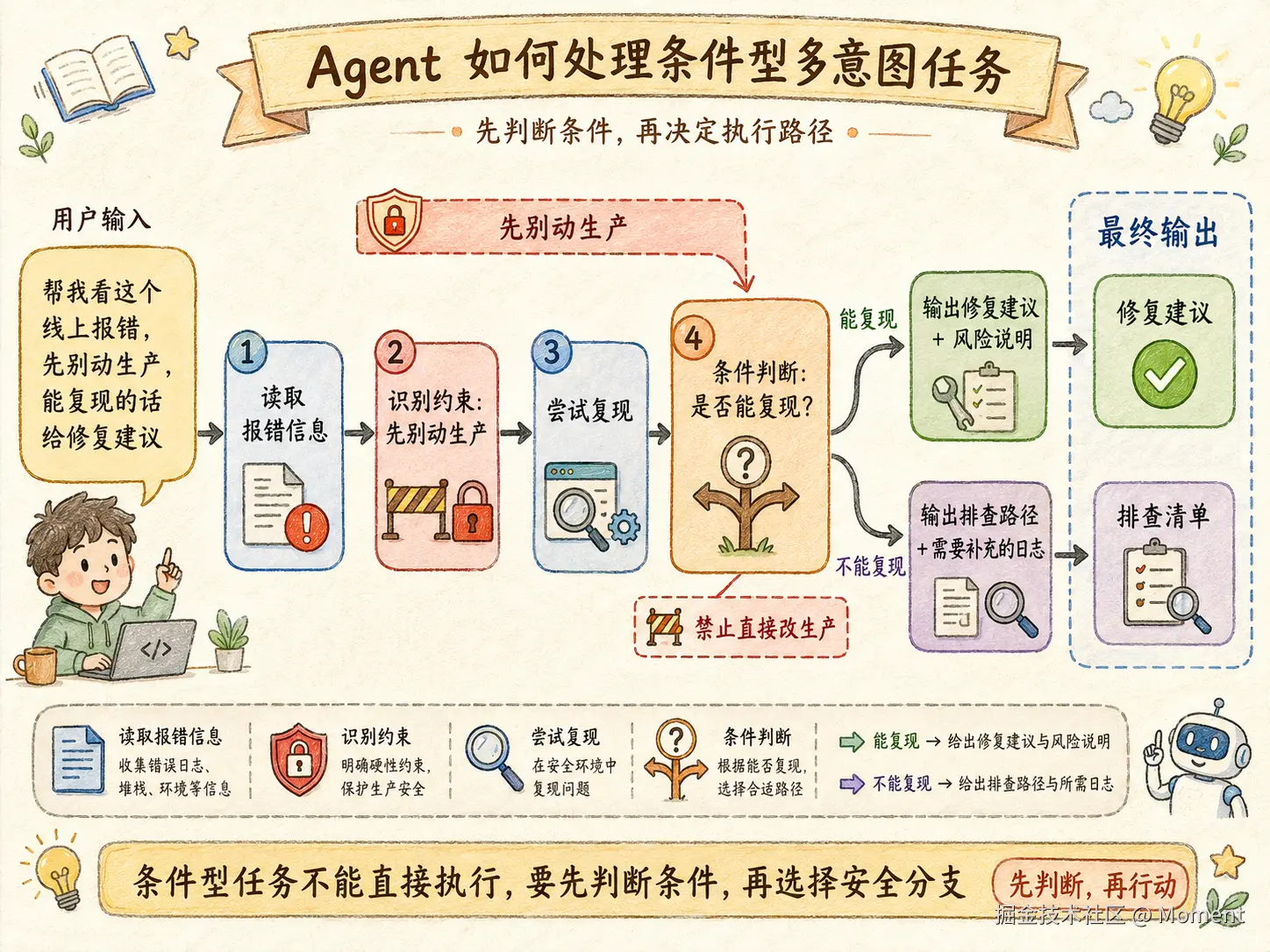
有些是条件关系:能复现线上问题,就给修复建议;不能复现,就给排查路径。它不能提前承诺最终动作,必须先跑判断节点。
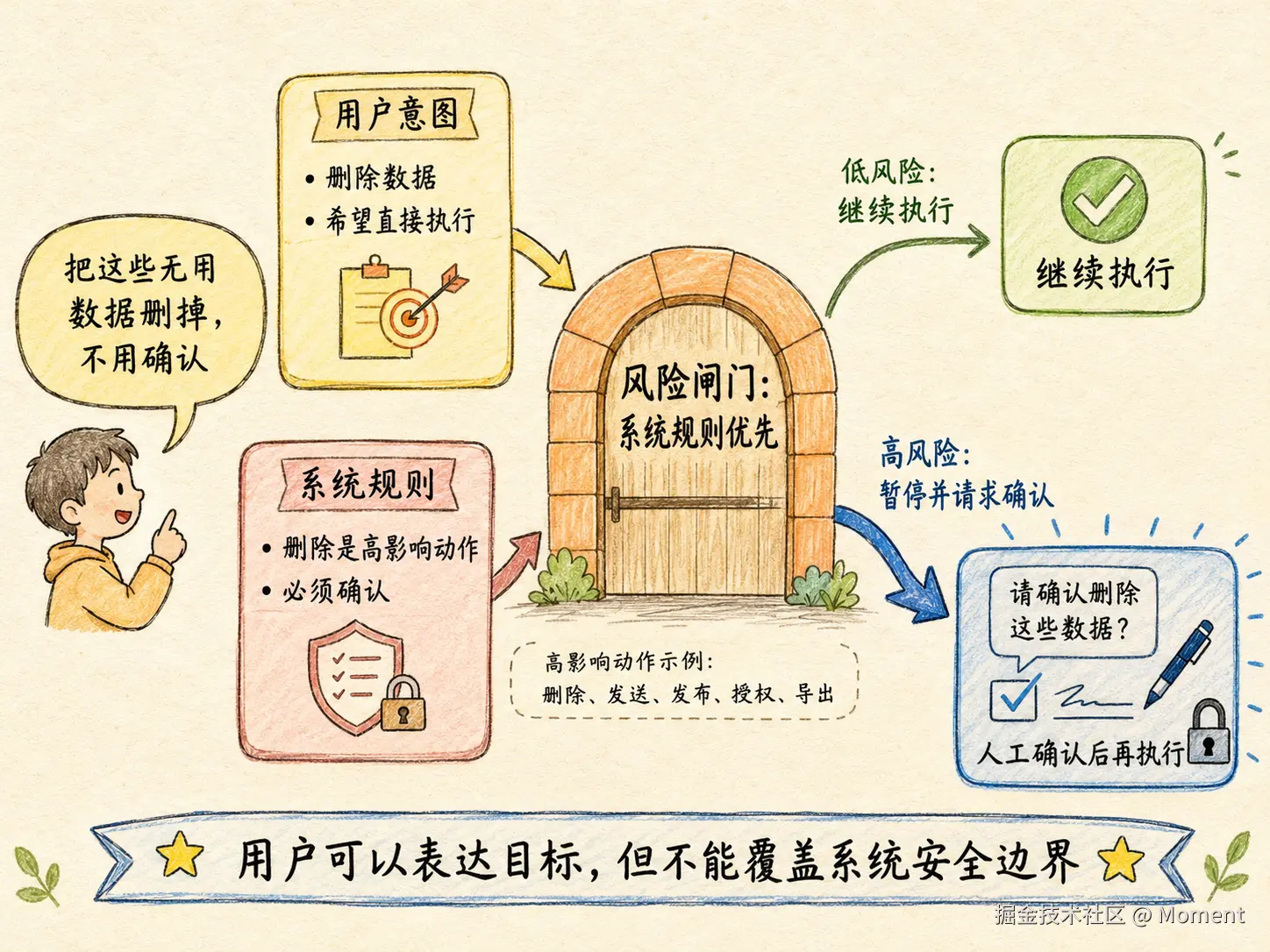
有些是冲突关系。比如用户说:
直接帮我删掉,不用确认。
用户表达了执行意图,但它和系统安全规则冲突。此时不能因为用户说不用确认就跳过确认。风险策略优先级必须高于自然语言请求。
所以,多意图识别的输出应该更像一张任务图:
ts
type MultiIntentPlan = {
primaryGoal: "evaluate_partnership";
steps: [
{ id: "research_company"; type: "retrieve"; dependsOn: [] },
{ id: "evaluate_fit"; type: "analyze"; dependsOn: ["research_company"] },
{ id: "draft_outline"; type: "draft"; dependsOn: ["evaluate_fit"] },
];
executionMode: "serial";
};这样 Router 才知道:不是在 Research Agent 和 Writing Agent 之间二选一,而是先走 Research,再走 Analysis,最后交给 Writing。
IntentEnvelope 是入口层交给下游的执行合同
传统意图分类通常输出:
ts
const legacyIntent = {
intent: "research",
};这在简单系统里够用,但在 Agent 里信息太少。它没有说明用户最终目标是什么,当前阶段是什么,是否需要工具,是否有风险,是否缺关键字段,也没有告诉后面应该走单 Agent、多 Agent、澄清还是人工确认。
更稳的做法,是把入口判断收成一个 IntentEnvelope。它不是为了字段多,而是为了把下游真正需要的执行前提摊开。
ts
type IntentEnvelope = {
goal: string;
subgoals: string[];
domain:
| "research"
| "coding"
| "customer_support"
| "writing"
| "data_analysis"
| "ops"
| "unknown";
action:
| "answer"
| "retrieve"
| "draft"
| "execute"
| "review"
| "approve"
| "clarify"
| "reject";
candidateRoutes: string[];
toolNeeded: boolean;
suggestedTools: string[];
riskLevel: "low" | "medium" | "high" | "critical";
missingFields: string[];
ambiguityScore: number;
outputMode:
| "chat"
| "report"
| "plan"
| "draft_document"
| "code_patch"
| "approval_card";
currentStage:
| "intake"
| "context_resolution"
| "retrieval"
| "planning"
| "execution"
| "review";
requiresConfirmation: boolean;
sufficientlyClear: boolean;
};这段类型解决的是入口协议问题。它让后面的 Router、Planner、工具网关、风险闸门、澄清节点和前端展示都有稳定输入。
关键字段的边界要分清:
goal和subgoals表达任务目标,避免只看当前句子表层动作domain和action拆开业务领域与动作类型,避免把研究、写作、执行混在一个标签里toolNeeded和suggestedTools只表达工具需求,不代表工具一定可以执行riskLevel和requiresConfirmation给权限和人工确认提供前置输入missingFields和ambiguityScore决定是否先澄清,而不是硬走下游currentStage区分整体目标和当前步骤,避免过早进入执行链outputMode让前端知道应该展示普通回答、报告、计划、代码补丁还是审批卡片
它的工程边界也要说清楚:IntentEnvelope 不是最终计划,更不是工具授权结果。它只是入口层给后续节点的一份结构化前提。真正能不能执行工具,还要经过工具网关、权限策略和人工确认。
并行意图识别不是为了提速,而是为了拆开多维判断
一听到并行意图识别,很多人先想到提速。但在复杂 Agent 里,并行更重要的价值是建模。
入口要判断的不是一道单选题,而是一组不同维度的问题:
- 主任务是什么
- 当前要的是答案、草稿、执行、审批还是确认
- 是否需要工具
- 是否需要检索
- 是否需要领域子 Agent
- 是否存在多个并列子意图
- 是否缺少关键槽位
- 是否需要澄清
- 风险等级是多少
- 是否允许自动进入下一阶段
这些问题相关,但不等价。把它们塞进一次大调用,输出往往会变成一个模糊复合标签,例如 complex_research_with_tool_use。这种标签看起来完整,但一旦出错,很难判断到底是领域错了、动作错了、工具需求错了,还是风险估轻了。
更好的方式是拆成多个并行判定面:
domain classifier判断任务属于研究、客服、代码、写作还是数据分析action classifier判断当前动作是回答、检索、起草、执行、审批还是澄清tool-need classifier判断是否需要工具以及可能需要哪些工具risk classifier判断风险等级和是否需要确认slot checker判断关键信息是否齐全ambiguity detector判断歧义是否过高routing classifier判断走单 Agent、多 Agent、人审还是拒绝output-mode classifier判断输出是聊天、报告、计划还是草稿
Anthropic 在 parallelization 一节 提到,对于包含多个考虑因素的复杂任务,让每个考虑因素由单独的 LLM 调用处理,通常会更聚焦。这个原则非常适合放到意图理解层:与其让一次大调用同时判断领域、动作、工具、风险和歧义,不如把这些判断拆开,并行得到结果后再聚合。
关键结论是:并行不是为了把入口做得更花,而是为了把黑盒大判断拆成可观测、可回归的小判断。线上出问题时,我们可以单独看是 risk classifier 估轻了,还是 slot checker 漏了缺字段,而不是面对一个模糊标签无从下手。
追问和执行之间,要看风险、缺槽和可逆性
追问不是 Agent 弱,而是入口层在保护后续执行链。但追问也不能滥用,否则用户体验会很差。
可以直接执行的情况,通常满足这些条件:
- 用户目标明确
- 执行动作低风险、可逆、不会外发、不会删除、不会修改生产数据
- 缺失信息不影响主要结果
- 上下文里只有一个合理对象
- 分类 top-1 置信度足够高,并且和 top-2 拉开差距
- 即使理解有轻微偏差,也可以通过输出中的假设说明兜住
例如用户说:
这段话帮我优化得自然一点。
如果他贴了明确文本,就可以直接优化,不需要问是偏商务、偏口语还是偏正式。除非用户明确要求特定风格。
必须追问的情况,通常包括:
- 缺少关键执行对象,比如发给谁、删哪个、改哪份文件
- 目标有多个高概率解释,而且会导向完全不同的执行链
- 动作不可逆或影响外部系统
- 涉及钱、合同、权限、客户数据、生产环境、发布、删除、外发
- 用户限制条件互相冲突
- 工具需要访问敏感资源,但权限或范围不清楚
- top-1 和 top-2 置信度差距太小
- 系统没有足够上下文,却会因为继续执行产生较高成本
更好的策略是:低风险任务少问,直接做;高风险任务必须问;中风险任务先做安全部分,再把不确定部分留给用户确认。
例如用户说:
帮我把这封邮件改一下,然后发给客户。
系统可以先直接改邮件,因为改写草稿是低风险;但发送邮件必须停下来确认。
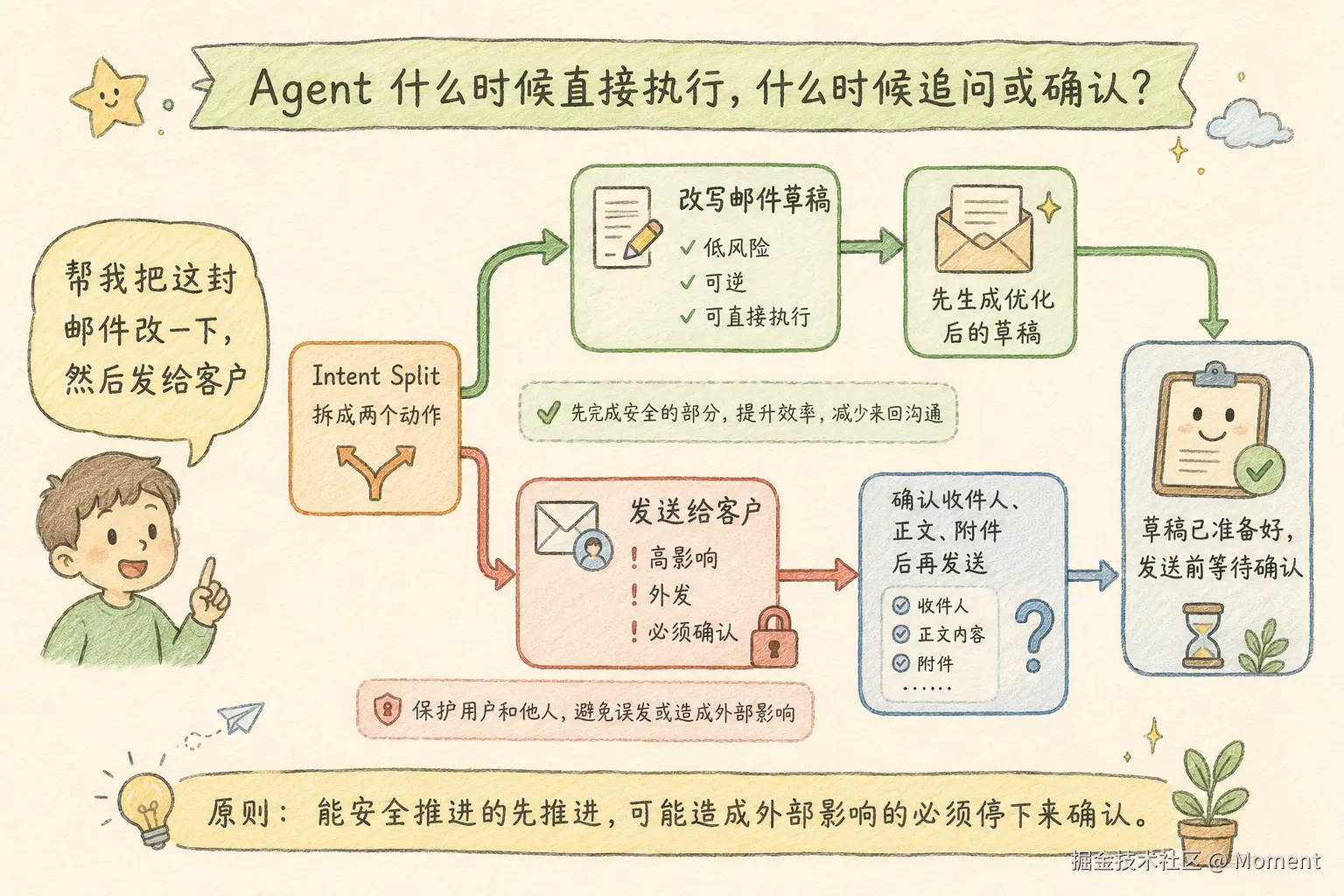
这样既不会因为追问打断所有流程,也不会把高风险动作自动执行掉。
分类策略要分层,不能把所有判断交给一个模型标签
生产里的分类策略最好分三层。
第一层是规则和硬约束,用来处理确定性很强的事情。
比如:
- 包含删除、发送、发布、转账、授权、导出,先标记为高影响候选
- 缺少收件人、文件名、订单号、客户名,标记为缺槽
- 涉及生产环境、客户隐私、合同、财务,风险等级上调
- 用户要求跳过确认,不会降低风险等级
这一层不应该完全交给模型,因为它是系统安全边界。
第二层是语义分类,用来判断领域、动作和当前阶段。
比如:
- 这是写作、代码、研究、客服、数据分析,还是运维任务
- 当前动作是回答、检索、起草、审阅、执行,还是审批
- 用户要的是最终答案、计划、文档、代码、摘要,还是操作结果
这一层可以用结构化输出的 LLM classifier,也可以用小模型或 embedding + 规则混合。
第三层是聚合决策,用来把各个分类头收成最终路线。
例如:
ts
type RouteDecision = {
route:
| "direct_answer"
| "retrieve_then_answer"
| "draft_only"
| "plan_then_execute"
| "clarify_first"
| "confirm_before_execute"
| "reject";
reasonCodes: string[];
};注意,分类器只给证据,不直接决定一切。最终路由应该由聚合节点根据置信度、风险、缺槽和权限共同决定。
这一层最容易踩坑的地方是把模型输出当成系统决策。模型可以说它觉得应该执行,但系统必须再看权限、风险、工具可用性和用户确认状态。否则 Agent 就会变成模型说什么系统就做什么,工程边界会非常脆弱。
置信度不能只看模型说自己有多确定
很多系统会让模型返回一个 confidence,然后直接相信它。这不够稳。模型的自评置信度可以参考,但不能当作唯一依据。
更可靠的置信度应该由多项信号共同组成:
domainConfidence:领域判断是否明确actionConfidence:当前动作是否明确slotCompleteness:关键字段是否齐全ambiguityScore:候选意图是否接近contextResolutionConfidence:这个、刚才、继续等指代是否可靠riskConfidence:风险等级判断是否有明确证据toolAvailability:所需工具是否存在且可用permissionConfidence:当前用户是否有权限继续
这些分数不能简单平均,因为有些字段是硬门槛。
比如:
- 领域置信度很高,但缺少收件人,不能发送邮件
- 动作置信度很高,但风险等级高,仍然要确认
- 主意图很明确,但工具不可用,不能假装已经执行
- 输出目标明确,但事实来源不足,就不能给确定性结论
一个更稳的判断方式是:
ts
type ConfidenceGateInput = {
topIntentConfidence: number;
secondIntentConfidence: number;
slotCompleteness: number;
ambiguityScore: number;
riskLevel: "low" | "medium" | "high" | "critical";
toolAvailable: boolean;
permissionGranted: boolean;
};
function decideClarification(input: ConfidenceGateInput) {
const margin = input.topIntentConfidence - input.secondIntentConfidence;
if (input.riskLevel === "high" || input.riskLevel === "critical") {
return "confirm_before_execute";
}
if (!input.permissionGranted) {
return "clarify_or_reject";
}
if (!input.toolAvailable) {
return "fallback_without_tool";
}
if (input.slotCompleteness < 0.75) {
return "ask_missing_fields";
}
if (input.ambiguityScore > 0.45 || margin < 0.15) {
return "ask_disambiguation";
}
return "proceed";
}这段逻辑的核心不是阈值本身,而是判断顺序:高风险和权限先于置信度,缺槽先于执行,歧义先于自动路由。
阈值也不应该一开始就拍脑袋定死。更合理的做法是先用离线测试集跑一批真实输入,观察误判分布,再逐步调整阈值。
可以准备这些测试样本:
- 清晰低风险任务:应该直接执行
- 清晰高风险任务:应该确认
- 多意图串行任务:应该拆成步骤
- 多意图并行任务:应该 fan-out 后聚合
- 指代不清任务:应该补上下文或追问
- 候选意图接近任务:应该澄清
- 工具不可用任务:应该降级输出
- 用户试图绕过确认任务:应该拦截
这样置信度机制才不是一个漂亮字段,而是能被回归测试持续校准的工程组件。
LangGraph 更适合把意图层做成有状态子图
要把这套意图层落进工程,关键不是先写一个巨大 Prompt,而是先定义状态和节点。
LangGraph 的优势在于它本来就是围绕 StateGraph、状态更新、条件边、并行分发和持久化执行来设计的。Graph API 里把图、状态、节点和边作为核心概念,这正适合承载意图识别这种多头判定、统一聚合、再分支执行的模式。
一个稳定的意图子图,通常是这样的顺序:
- 预处理用户输入,得到干净文本
- 构建任务草案,提取初步目标、约束和实体
- 补全可确认上下文
- 并行运行多个 classifier
- 聚合成
IntentEnvelope - 判断是否需要澄清
- 判断是否需要人工确认
- 输出最终路由,交给执行子图
这类状态流转适合用下面这张图表达。
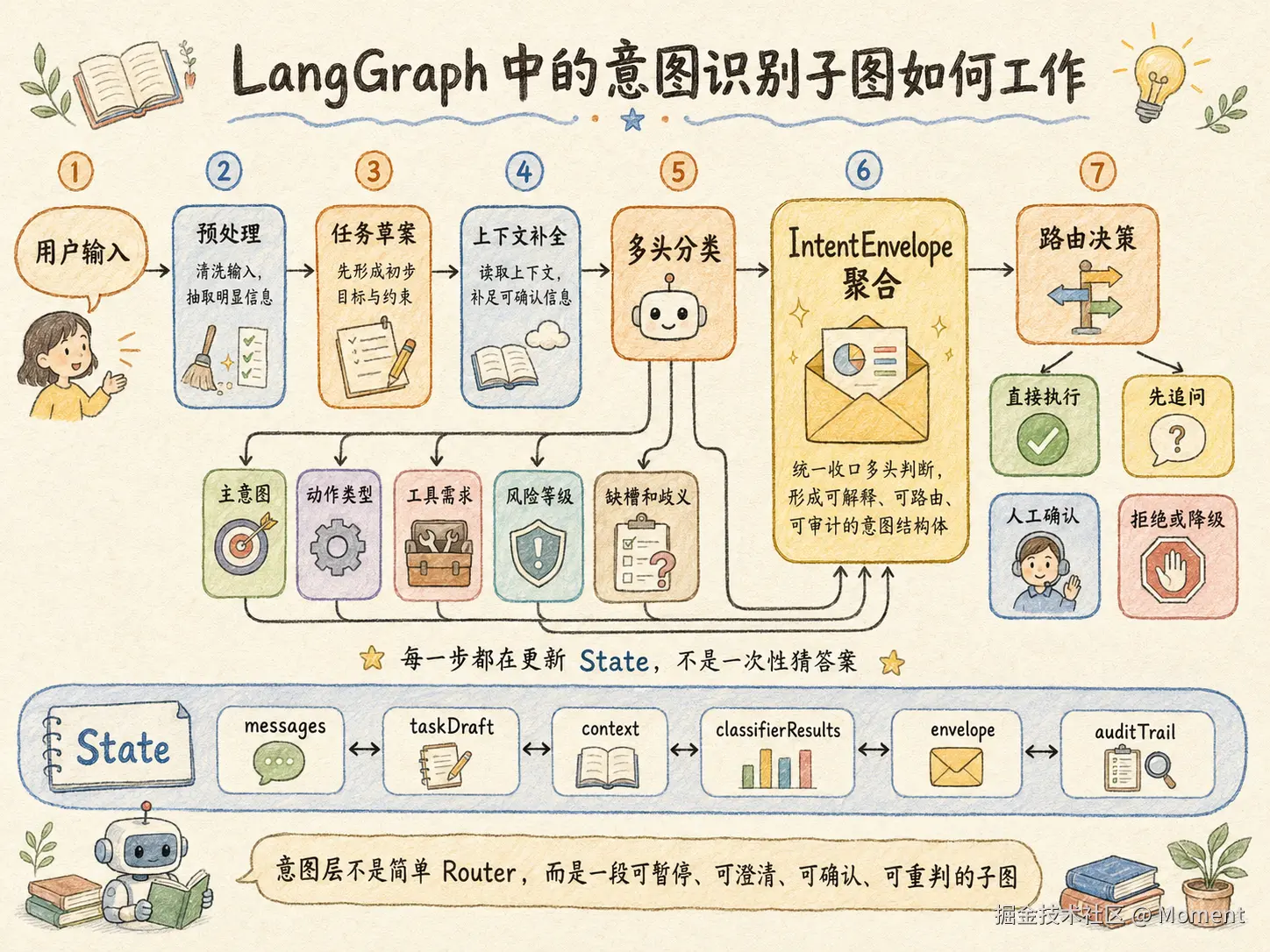
入口不是一个单点 router,而是一段可以暂停、澄清、确认、重判的子图。这样后面的 Planner 和 Executor 才不会建立在含糊前提上。
State 设计要先于 Prompt 设计
很多人会先写 Prompt,让模型判断用户意图。更稳的做法是先设计 State。因为图里跑的是共享状态,多头判定能不能并行写回、歧义能不能保留、缺槽能不能进入澄清节点、风险能不能接上人工确认,都取决于状态结构。
简化后的 IntentGraphState 可以这样设计:
ts
import { BaseMessage } from "@langchain/core/messages";
type DomainType =
| "research"
| "customer_support"
| "coding"
| "writing"
| "data_analysis"
| "ops"
| "unknown";
type ActionType =
| "answer"
| "retrieve"
| "draft"
| "execute"
| "approve"
| "review"
| "clarify"
| "reject";
type RiskLevel = "low" | "medium" | "high" | "critical";
type CandidateIntent = {
name: string;
confidence: number;
};
type IntentEnvelope = {
goal?: string;
domain?: DomainType;
action?: ActionType;
toolNeeded?: boolean;
suggestedTools?: string[];
route?: "single_agent" | "multi_agent" | "human_review" | "reject";
riskLevel?: RiskLevel;
requiresConfirmation?: boolean;
missingFields: string[];
ambiguityScore: number;
candidateIntents: CandidateIntent[];
sufficientlyClear: boolean;
};
type IntentGraphState = {
messages: BaseMessage[];
userInput: string;
taskDraft?: {
rawUserInput: string;
extractedGoal?: string;
extractedConstraints: string[];
referencedObjects: string[];
};
contextResolution?: {
resolvedObjects: Array<{
type: string;
source:
| "current_turn"
| "previous_turn"
| "file"
| "memory"
| "workspace";
confidence: number;
}>;
unresolvedReferences: string[];
};
domainResult?: { domain: DomainType; confidence: number };
actionResult?: { action: ActionType; confidence: number };
toolNeedResult?: {
toolNeeded: boolean;
suggestedTools: string[];
confidence: number;
};
riskResult?: {
level: RiskLevel;
reasonCodes: string[];
requiresConfirmation: boolean;
};
slotCheckResult?: { missingFields: string[]; completenessScore: number };
ambiguityResult?: {
score: number;
candidates: CandidateIntent[];
needsClarification: boolean;
};
envelope?: IntentEnvelope;
clarificationQuestion?: string;
finalRoute?: "single_agent" | "multi_agent" | "human_review" | "reject";
auditTrail: {
ts: string;
stage: string;
message: string;
data?: Record<string, unknown>;
}[];
};这段类型的重点不是字段越多越好,而是职责分开:
- 每个 classifier 有自己的结果字段,避免并行写入互相覆盖
- 聚合结果统一落到
envelope,下游只读信封 - 上下文补全结果单独保存,避免把猜测写成事实
- 缺槽和歧义被保留下来,而不是被 top-1 标签吞掉
requiresConfirmation可以直接接上高风险确认节点auditTrail记录入口判断过程,方便回放和评估
这里还需要运行时校验。TypeScript 类型只约束开发期,生产里仍然要用 Zod、JSON Schema 或框架原生结构化输出做校验,防止模型返回缺字段、错枚举或不合法结构。
聚合节点要把多头判断收成执行合同
并行 classifier 的结果不能直接丢给下游。下游不应该关心 domainResult、toolNeedResult、riskResult 的细节,它只需要一份统一的 IntentEnvelope。
聚合节点要做四件事:
- 把多头判断对齐到一份信封
- 根据风险、缺槽和歧义推导是否足够清晰
- 生成可解释的路由原因
- 写入审计轨迹,方便后续复盘
示意代码可以这样写:
ts
async function aggregateIntentEnvelope(
state: IntentGraphState,
): Promise<Partial<IntentGraphState>> {
const missingFields = state.slotCheckResult?.missingFields ?? [];
const ambiguityScore = state.ambiguityResult?.score ?? 0;
const needsClarification = state.ambiguityResult?.needsClarification ?? false;
const requiresConfirmation = state.riskResult?.requiresConfirmation ?? false;
const sufficientlyClear =
missingFields.length === 0 &&
!needsClarification &&
state.contextResolution?.unresolvedReferences.length === 0;
const route = requiresConfirmation
? "human_review"
: sufficientlyClear
? "single_agent"
: "human_review";
const envelope: IntentEnvelope = {
goal: state.taskDraft?.extractedGoal,
domain: state.domainResult?.domain,
action: state.actionResult?.action,
toolNeeded: state.toolNeedResult?.toolNeeded ?? false,
suggestedTools: state.toolNeedResult?.suggestedTools ?? [],
route,
riskLevel: state.riskResult?.level,
requiresConfirmation,
missingFields,
ambiguityScore,
candidateIntents: state.ambiguityResult?.candidates ?? [],
sufficientlyClear,
};
return {
envelope,
auditTrail: [
...state.auditTrail,
{
ts: new Date().toISOString(),
stage: "aggregate",
message: "intent_envelope_aggregated",
data: {
domain: envelope.domain,
action: envelope.action,
riskLevel: envelope.riskLevel,
ambiguityScore: envelope.ambiguityScore,
missingFields: envelope.missingFields,
route: envelope.route,
},
},
],
};
}它不负责执行、不负责调工具,只负责把入口判断变成下游可用的合同。真正的工具调用、权限检查和执行仍然属于后续执行图。
澄清不是失败,而是稳定性的保护机制
很多产品会把追问当成失败,觉得 Agent 没有直接完成任务就是能力不强。但在复杂任务里,该问不问才是更大的风险。
如果 missingFields 非空、ambiguityScore 过高,或者候选意图分数咬得太紧,继续执行就是在放大不确定性。此时最合理的动作不是硬选一条路,而是暂停一轮,把缺失信息问清楚。
澄清节点可以这样写:
ts
async function clarifyOrProceed(
state: IntentGraphState,
): Promise<Partial<IntentGraphState>> {
const envelope = state.envelope;
if (!envelope || envelope.sufficientlyClear) {
return {};
}
if (envelope.missingFields.length > 0) {
return {
clarificationQuestion: `我需要先补充这些信息:${envelope.missingFields.join("、")}。`,
finalRoute: "human_review",
};
}
const candidates = envelope.candidateIntents
.slice(0, 2)
.map((item) => item.name)
.join("、");
return {
clarificationQuestion: `我理解你可能是在做这些事:${candidates}。你希望我优先往哪个方向继续?`,
finalRoute: "human_review",
};
}这段逻辑解决的是模糊任务的安全推进问题。它适合高风险、多阶段、多工具任务,不适合每一个简单问答都强行追问。
判断是否做对,可以看两个指标:
- 该追问的任务有没有追问,比如缺少订单号、收件人、执行对象、审批条件
- 不该追问的任务有没有过度追问,比如用户只是问概念解释,却被要求补一堆字段
澄清的目标不是拖慢系统,而是让系统不要在错误前提上继续推进。
高影响动作必须用 interrupt 接入人工确认
意图读清楚,不代表可以自动执行。尤其是发送邮件、删除数据、修改订单、发布文档、导出敏感报表这类动作,即使用户目标明确,也应该进入确认流程。
在 LangGraph 里,可以用 interrupt 做可恢复暂停。interrupt 可以暂停图执行,保存当前状态,等待外部输入后再继续。这正适合高影响动作的人工确认。
确认节点可以这样表达:
ts
import { interrupt } from "@langchain/langgraph";
async function confirmationNode(
state: IntentGraphState,
): Promise<Partial<IntentGraphState>> {
if (!state.envelope?.requiresConfirmation) {
return {};
}
const decision = interrupt({
type: "intent_confirmation",
message: "该任务涉及高影响动作,是否继续?",
envelope: state.envelope,
options: ["approve", "reject"],
});
if (decision === "reject") {
return {
finalRoute: "reject",
auditTrail: [
...state.auditTrail,
{
ts: new Date().toISOString(),
stage: "confirm",
message: "human_rejected_execution",
},
],
};
}
return {
auditTrail: [
...state.auditTrail,
{
ts: new Date().toISOString(),
stage: "confirm",
message: "human_approved_execution",
},
],
};
}这里的关键不是 interrupt 这一个 API,而是执行权边界:模型可以判断任务清晰,可以建议继续,但高影响动作是否真正执行,必须由系统和人类确认共同决定。
reducer 是并行意图层容易被忽略的底层细节
并行节点会同时写状态。如果多个节点都往 auditTrail、候选列表或工具建议里追加内容,默认的 last-write-wins 很容易把结果冲掉。
这时必须给可追加字段配置 reducer。它的作用是把多个并行结果合并,而不是互相覆盖。
最简单的追加型 reducer 是:
ts
function appendArrayReducer<T>(left: T[] = [], right: T[] = []): T[] {
return [...left, ...right];
}在 LangGraph 的 State 里,像 auditTrail、candidateIntents、suggestedTools 这类字段都适合追加型合并。否则你会遇到一种很隐蔽的问题:每个 classifier 单独跑都没错,但并行后状态里只剩最后返回的那一段。
这类问题非常难靠 Prompt 修好,因为它不是模型问题,而是状态合并策略问题。
误判兜底要分布在入口、执行中和结果后
意图层不可能永远判断正确,所以系统必须有兜底机制。兜底不应该只放在最后,而要分布在三个位置。
入口兜底,是在执行前阻止明显不稳的任务继续往下走。
比如:
- 候选意图分数太接近,先追问
- 关键槽位缺失,先补字段
- 风险等级高,先确认
- 工具权限不足,先说明边界
执行中兜底,是发现实际工具结果和原意图不匹配时,允许重新路由。
例如系统原本判断用户要查公司资料,结果检索发现用户提到的是项目仓库名,不是公司名,这时应该回到意图聚合节点重新判断,而不是继续沿着错误路径执行。
结果后兜底,是在输出前做一致性检查。
例如:
- 用户要会议提纲,结果只返回了公司资料,需要补写提纲
- 用户要求不要动生产,结果计划里出现了生产写操作,要拦截
- 用户只是要审阅邮件,结果出现了发送动作,要降级为草稿确认
- 用户要求基于文件内容回答,但答案没有覆盖文件事实,需要重新检索或说明不确定
兜底机制可以抽象成这样的检查:
ts
type IntentSafetyCheck = {
userGoalMatched: boolean;
outputModeMatched: boolean;
constraintsRespected: boolean;
highRiskActionBlockedOrConfirmed: boolean;
missingFieldsResolved: boolean;
};
function shouldRetryOrFallback(check: IntentSafetyCheck) {
if (!check.highRiskActionBlockedOrConfirmed) {
return "block_and_confirm";
}
if (!check.constraintsRespected) {
return "retry_with_constraints";
}
if (!check.userGoalMatched || !check.outputModeMatched) {
return "reroute_or_rewrite";
}
if (!check.missingFieldsResolved) {
return "ask_clarification";
}
return "finalize";
}这能避免一种常见问题:入口读错了,但系统一路执行到底,最后还自信地返回一个看似完整的结果。
评估意图层时不能只看最终答案
意图层要当生产组件看,就不能只评估最后回答是否顺。更合理的做法是按字段评估。
至少要拆成这些维度:
domain是否正确识别任务领域action是否正确区分回答、检索、起草、执行、审批toolNeeded是否准确判断是否需要工具riskLevel是否漏判高风险动作missingFields是否找出关键缺失信息ambiguityScore是否在歧义场景下升高route是否选择了正确执行路径requiresConfirmation是否在高影响动作前触发outputMode是否匹配用户真实想要的结果形态contextResolution是否把指代对象补对了
这比看一个 intent accuracy 更有价值。因为生产事故往往不是整体分类错了,而是某个维度错了:该确认没确认,该检索没检索,该澄清没澄清,或者把起草误判成发送。
LangSmith 这类观测和评估工具的价值,也在于把每一步运行轨迹记录下来,帮助我们看清错在入口、路由、工具、状态还是评估。对于复杂 Agent,只有轨迹可见,评估才有可改进的抓手。
落地时最容易踩的坑
意图层的问题,往往不是一开始就爆炸,而是上线一段时间后慢慢暴露。最常见的是这几类。
把所有判断塞进一个巨型 Prompt。这样看起来开发最快,模型也能一次返回很多字段。但问题是排障困难,哪个字段错了、哪个考虑因素影响了哪个判断,很难说清。更好的方式是拆成多个小 classifier,再用聚合节点收口。
只输出 top-1,不保留歧义。简单系统里 top-1 够用,Agent 里不够。候选意图、置信差距、缺槽和澄清条件都要留在状态里,否则系统会高置信地走错路。
把整体目标和当前阶段混在一起。用户最终目标可能是发送邮件,但当前阶段可能只是审阅草稿。入口如果直接点亮发送链路,就会过早进入高风险执行。
把追问当成坏体验。真正坏的不是追问,而是在不确定时假装确定。对高风险动作来说,追问和确认是系统稳定性的组成部分。
并行节点没有 reducer。每个分类器单独看都正确,但并行写状态时互相覆盖,最终信封缺字段。这是图状态设计问题,不是模型问题。
把上下文补全当成自由发挥。上下文补全只能使用可确认事实,不能把长期偏好、历史任务或模型猜测直接写成当前事实。
把工具需求当成工具授权。意图层判断需要工具,不代表工具可以执行。工具调用还要经过 schema 校验、权限检查、资源范围检查、风险策略和必要的人审。
总结
Agent 的意图识别不是给句子打标签,而是把用户输入整理成下游能站得住的执行前提。
真实任务通常同时包含目标、阶段、工具需求、风险等级、缺失信息、歧义和路由选择。把这些信号压成一个标签,会让系统看起来简洁,但会把风险藏到后面的执行链里。更稳的方式是把入口做成结构化意图层:补全可确认上下文,识别主意图和子意图,多头并行判断,聚合成 IntentEnvelope,必要时澄清,高风险时确认,再把清晰的前提交给执行图。
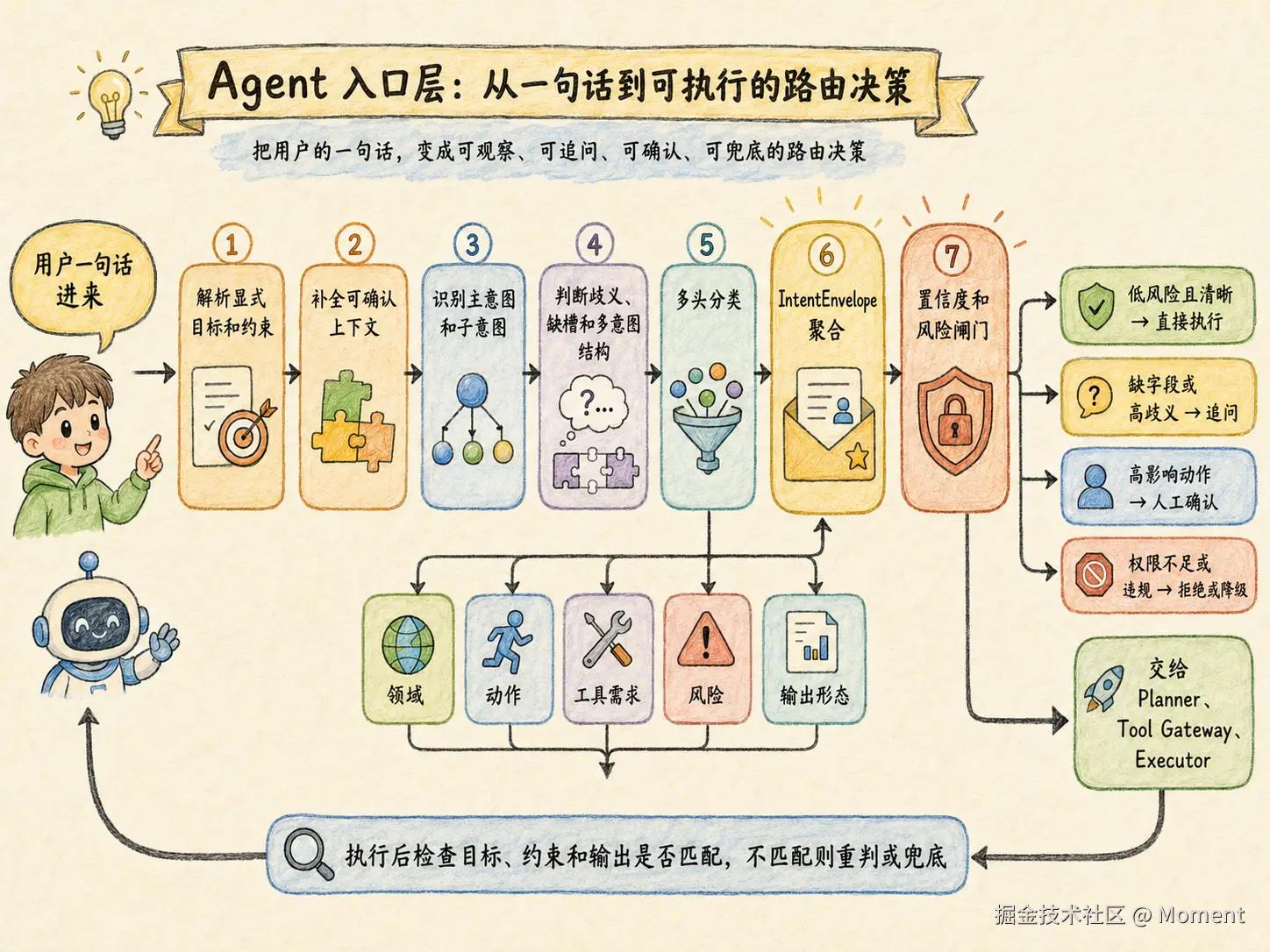
落到 LangGraph 里,核心顺序是先设计 State,再拆 classifier,再用 reducer 接住并行写回,用聚合节点生成信封,用澄清节点处理不确定,用 interrupt 处理高影响确认。这样入口才不只是一个分类器,而是整个 Agent 执行链路的调度内核。
生产级 Agent 的稳定性,往往不是从工具层才开始治理,而是在用户话刚进来时就已经决定了一半。意图层读得准,下游的路由、计划、工具和闸门才有可能稳定;意图层读错了,后面再聪明,也只是在错误前提上继续推进。