从 Figma 走查到 AI 可验证产物:我们如何重构客户端 UI 交付链路
大家好,我是小林。
过去这段时间,我做了一件有点"反直觉"的事:
首先背景是团队内部开始弃用Figma这类的设计稿,而是用了一个原型平台来驱动客户端开发。
当然这件事情到底是不是我们在 "自掘坟墓 "不太重要,因为领导已经决定并开始推广的时候,就已经是板上钉钉了...
话说回来从原型平台(vue3)到客户端(flutter),也是有很大的壁垒和坑点,具体我不展开细嗦,最后经过多次踩坑,我才明确下来思路。
我不是直接让 AI 写 Flutter 页面,也不是做一个所谓的 Vue 转 Dart 编译器,而是先给 AI 做一座桥。
这座桥叫 ProtoBridge。
它要解决的问题很具体:当产品、UI、客户端研发开始用 AI 协作以后,为什么 UI 页面还是经常还原不准?为什么你把 PRD、Figma、截图、甚至原型页面都丢给 AI,它还是会在组件、状态、间距、主题、路由、文案和文件结构上疯狂"脑补"?
后来我慢慢意识到,问题不一定出在 AI 不会写代码。
很多时候,是我给 AI 的上下文本来就不够工程化。
AI 写 UI 最大的问题:它总是在猜
传统客户端 UI 交付链路,大概长这样:
text
产品输出 PRD
-> UI 在 Figma 出静态设计稿
-> 客户端按自己的理解实现
-> 联调
-> UI 走查
-> 返工修正这条链路跑了很多年,大家都很熟。它不是完全不可用,甚至在很多团队里已经形成了稳定协作方式。
但它有一个天然问题:设计交付物里的信息,会在每一次交接中变薄。
PRD 负责说明业务目标和规则,Figma 负责表达视觉稿,客户端负责把它变成真实 App。每个环节都合理,但中间有大量信息并不会自动传递。
尤其是 Figma。
Figma 非常适合表达静态视觉,但真实 App 是动态的。静态稿很难完整表达这些东西:
- tab 切换后的状态
- 列表 loading、empty、error
- 弹窗、筛选、bottom sheet
- 滚动区域和吸顶行为
- 动态文案和格式化规则
- 组件复用边界
- 客户端工程里的主题、国际化、路由和状态管理模式
以前这些缺口靠人补。
产品解释一遍,UI 解释一遍,客户端自己再理解一遍。最后 UI 走查再兜底一遍。
UI 走查本质上是在事后补偿前面交付证据不足的问题。
它不是没有价值,恰恰相反,它很重要。但如果一次页面实现里大部分问题都要靠走查阶段发现,就说明更早的工程输入不够明确。
当我们引入 AI coding agent 以后,这套链路的问题会被放大。
因为 AI 很擅长"根据已有信息生成一个看起来合理的东西"。但如果证据边界不清楚,它也会很自然地把不存在的字段补出来,把目标工程没有的架构模式引进来,或者根据截图猜一个 Flutter widget tree。
所以我想做的不是再写一段更长的 prompt,而是把 UI 交付中的关键信息变成一组可采集、可追溯、可审查、可验证的工程产物。
这就是 ProtoBridge 的出发点。
我想把 UI 交付链路升级成什么样
理想的链路不是"AI 看图写代码",而是:
text
产品 / UI / AI 生成交互原型
-> 原型平台沉淀组件、主题、布局、状态和交互
-> ProtoBridge 采集源码证据、运行时证据、截图证据和目标工程规范
-> 生成可审查的实现契约
-> AI agent 或开发者按契约实现
-> 实现后验证目标变更这件事的关键变化是:UI 交付物不再只有"图"和"描述",而是变成了一组 agent 能理解的证据。
ProtoBridge 在这里的位置很明确:
它不是生产代码生成器。
它是一个 原型平台和目标客户端工程之间的上下文桥接层。
先看成果:不是概念稿,示例工程已经跑通
为了避免这篇文章变成"架构 PPT",我先把成果放前面。
目前仓库里已经准备了一个完整示例:
text
examples/vue3-to-flutter/
├── source-vue3/ # Vue3 + Vite + Vue Router + Pinia 原型工程
├── target-flutter/ # Flutter target 工程
├── agent-output/ # 保存过的一次 agent 输出
├── output/ # 运行示例后生成的 ProtoBridge 产物
├── screenshots/ # 原型和 Flutter 还原截图
└── proto-bridge.config.json示例覆盖两个页面:
| Case | Vue route | Flutter route | 覆盖点 |
|---|---|---|---|
| simple | /prototype/asset/holding-list |
/account/holding-list |
标题、摘要、筛选、列表、loading/empty |
| complex | /prototype/asset/pnl-analysis |
/account/pnl-analysis |
tab、筛选、指标卡、趋势图、交易列表、bottom sheet |
运行:
bash
pnpm run example
pnpm run example:dev会生成:
text
output/<case>/
├── page-canonical.json # 证据原档
├── page-debug-index.json # 调试索引
├── ui-build-plan.json # 实现蓝图
├── ui-build-review.md # 中文审查视图
└── screenshots/full-page.png同时示例里保存了一次 agent 根据这些产物实现出来的 Flutter 输出,放在:
text
examples/vue3-to-flutter/agent-output/flutter-proto-files/*.dart.txt也就是说,ProtoBridge 本身不直接产 Dart 文件;它生成的是页面上下文和实现契约。真正的 Flutter 页面,是 agent 读取这些契约以后实现出来的。
下面是示例工程里的公开截图对照。
| Vue3 原型 | Flutter 还原页 |
|---|---|
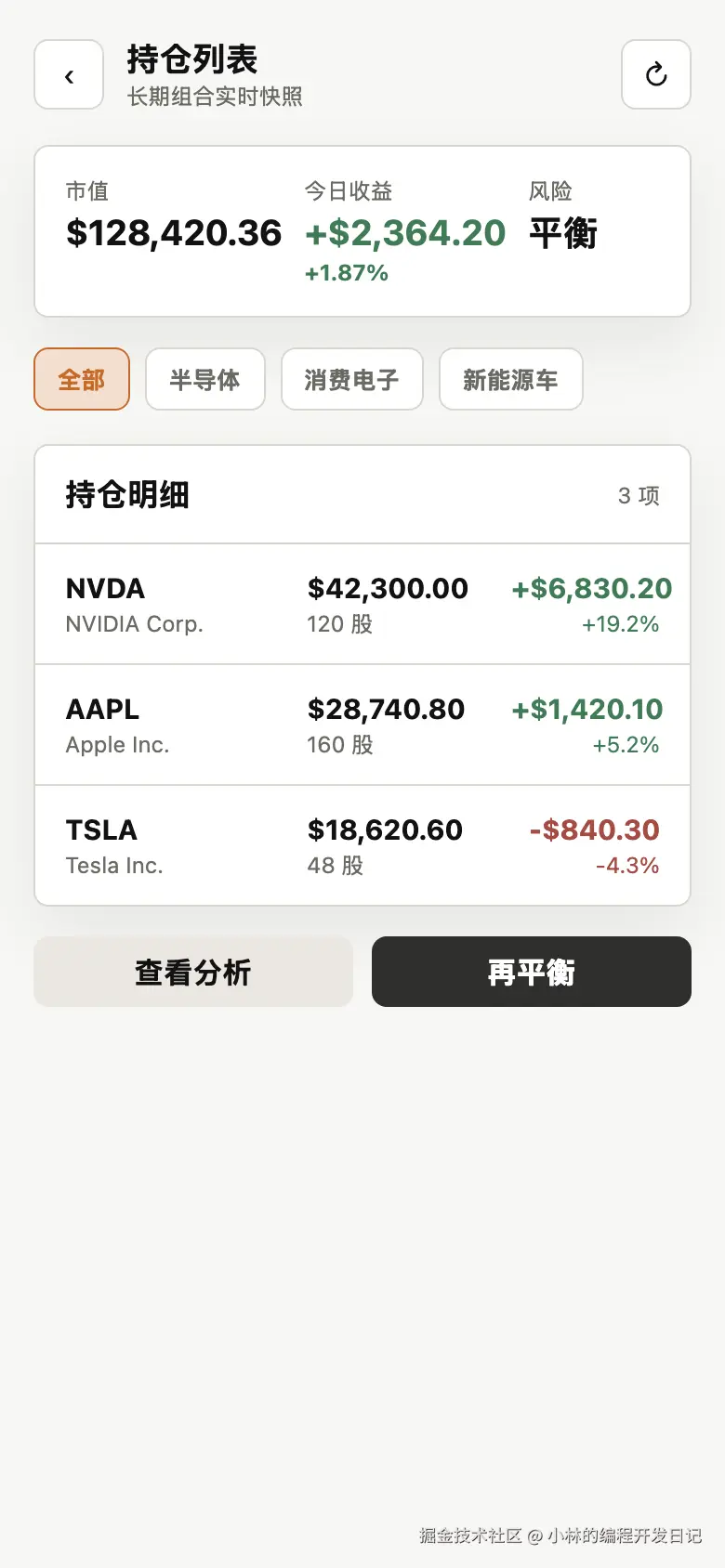 |
 |
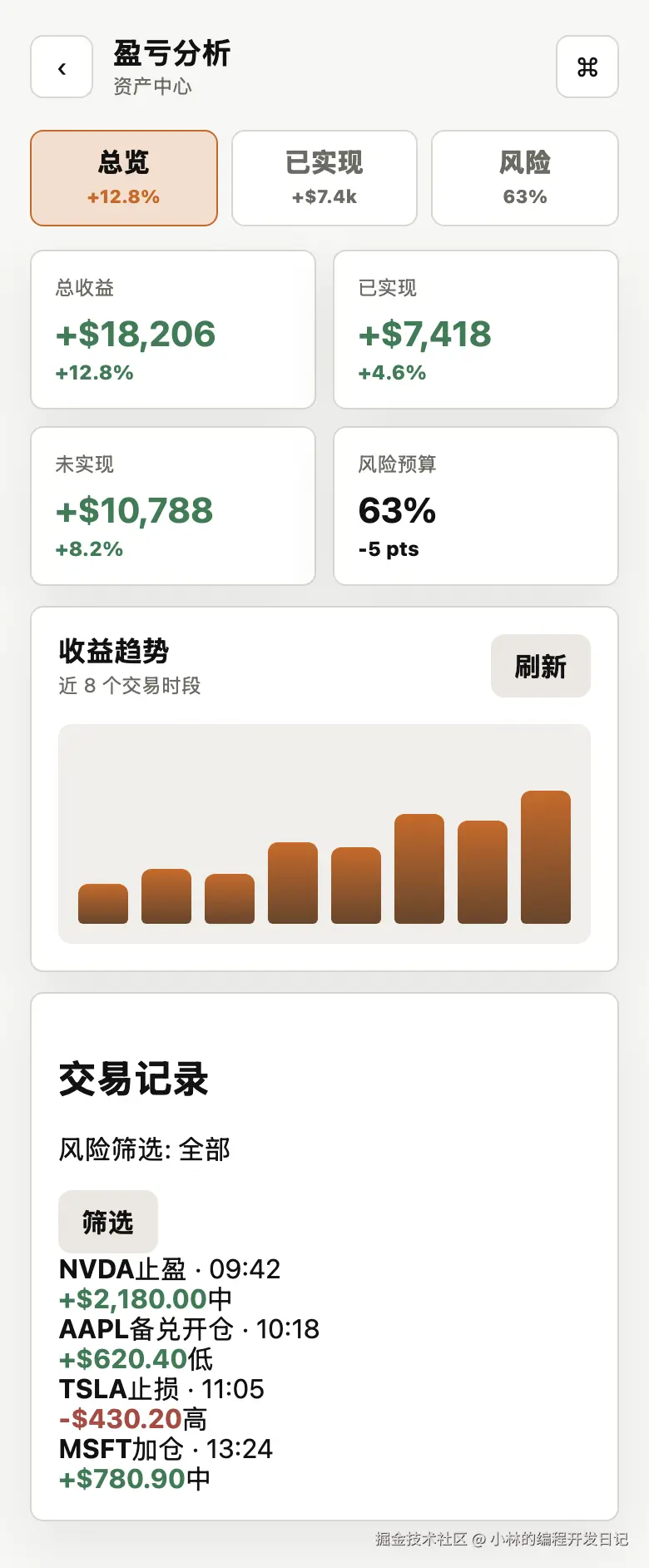 |
 |
在真实业务页面中这套链路在真实复杂页面上的效果会更明显:当页面有大量状态、筛选、列表、弹层和目标工程规范时,只靠截图或 PRD 让 AI 写代码,很容易开始猜;有了结构化证据以后,agent 的实现稳定性会高很多。
ProtoBridge 到底是什么
一句话:
ProtoBridge 是把交互原型、运行时页面、截图证据和目标 Flutter 工程规范,整理成页面级实现契约的工具。
它的输入可以是:
- prototype source:交互原型源码,用来分析页面结构、业务区块、状态空间、交互意图、资源和样式 token 意图。
- running URL:正在运行的原型页面地址,用来采集真实渲染后的文本、节点位置、计算样式、截图和当前激活状态。
- screenshot / OCR:截图和 OCR 文本,用来补充视觉对照和文字证据,尤其适合没有运行态页面时做辅助校验。
- target Flutter repository:目标 Flutter 工程,用来扫描目标项目真实使用的路由、状态管理、主题、国际化、公共组件和文件组织方式。
它的输出是一组产物:
text
page-canonical.json
证据原档。记录证据从哪里来,源码、运行时、截图和目标工程各自提供了什么,
用于追溯来源、排查冲突和补查细节。
page-debug-index.json
调试索引。方便从截图区域、文本锚点、节点 id、样式或资源快速定位回证据。
ui-build-plan.json
实现蓝图。它是 agent 默认执行的主文档,描述目标工程规范、文件边界、
Widget 拆分、视觉还原依据、动态文案和验证提示。
ui-build-review.md
审查视图。从实现蓝图渲染出的中文版本,方便人快速阅读和确认。
screenshots/full-page.png
视觉对照截图。用于实现前理解页面,也用于实现后排查视觉偏差。其中最重要的是 ui-build-plan.json。
它不是给人看的长文档,而是给 AI agent、验证器和开发者消费的机器契约。
ui-build-review.md 则是从实现蓝图渲染出来的中文审查视图,方便人快速 review。
ProtoBridge 不做这些事:
- 不把 Vue、HTML、DOM 直接翻译成 Dart
- 不自己生成生产 Flutter 页面
- 不替代目标应用的架构决策
- 不在没有证据时编造 API、权限、埋点、风控和业务规则
- 不把截图伪造成完整 DOM 或完整业务模型
它做的是:把 AI 原本要猜的部分,尽量变成证据。
它不是凭空来的:figma-mcp 和 Flutter GenUI 给我的启发
ProtoBridge 不是我拍脑袋凭空设计出来的。
在做这个工具之前,我重点参考过两个方向:一个是 Figma MCP,另一个是 Flutter 官方的 GenUI。
Figma MCP 给我的启发是:设计上下文不应该只以图片或人工描述的方式进入 agent,而应该变成 agent 可以读取的结构化上下文。
Figma 的 MCP 思路,本质上是在把设计稿里的节点、布局、样式和组件信息,通过工具接口带进 AI coding workflow。这样 agent 拿到的不是一张孤立截图,而是更接近设计源数据的上下文。
这对我很重要。因为 UI 还原的问题,很多时候不是"AI 看不懂图",而是它缺少图背后的结构、组件、约束和设计意图。
Flutter 官方的 GenUI 给我的启发更直接。
它的定位是 Flutter 的 Generative UI SDK,核心思路不是让 AI 随便吐一段不可控的 UI 代码,而是用 JSON-based UI format 描述界面,并且基于已有的 widget catalog 组合运行时 UI。它还明确支持 A2UI,也就是 agent-to-user-interface:agent 可以在 App 运行过程中生成或调整 UI;开发者则维护可用的组件库、数据绑定和状态反馈机制。
我从 GenUI 里学到的一点是:AI 生成 UI 不应该绕开客户端工程,而应该被约束在客户端已经认可的组件、协议和运行时边界里。
这和我的业务场景非常贴近。
但 ProtoBridge 要解决的问题又不完全一样。
我面对的不是"让 App 在运行时动态生成一个控件"这么单一的问题,而是一个更长的交付链路:
rust
交互原型
-> 运行时页面
-> 截图证据
-> 目标 Flutter 工程规范
-> AI agent 实现
-> 实现后验证所以 ProtoBridge 最后取了两边的启发:
- 从 Figma MCP 那里,我借鉴了"把设计/原型上下文结构化给 agent"的方向。
- 从 Flutter GenUI 那里,我借鉴了"AI UI 应该围绕组件库、协议和运行时边界工作"的方向。
- 再结合自己的业务,把重点放到了"交互原型到目标 Flutter 工程"的上下文桥接和可验证产物上。
这也是为什么 ProtoBridge 没有选择直接生成生产 Dart 页面。
它更像是把设计上下文、运行时事实和目标工程规范整理好,让 agent 在一个更可靠的上下文里工作。
核心设计:证据分工,而不是截图统治一切
我在设计 ProtoBridge 时,最重要的一个原则是:不同证据源各司其职。
不要让截图决定架构,也不要让源码决定视觉,更不要让工具自带某个 Flutter 架构偏好。
简单说:
| 证据来源 | 负责什么 | 不负责什么 |
|---|---|---|
| 源码语义 | 页面结构、业务区块、状态空间、交互意图、资源和样式 token 意图 | 不决定目标 Flutter 工程用 GetX、Bloc 还是 Riverpod |
| 运行时 / 截图证据 | 当前可见文本、位置、计算样式、截图、OCR 和视觉对照 | 不决定文件拆分、状态 owner 和架构边界 |
| 目标工程规范 | 目标工程真实使用的路由、状态、主题、国际化、组件和文件组织 | 不补造源码中没有的业务语义 |
这个分工非常关键。
举个例子,一个原型页面里有 tab、筛选、列表和 bottom sheet。源码语义能告诉我们这些状态空间和交互意图;运行时证据能告诉我们当前哪个 tab 激活、哪些文本可见、节点位置是多少;目标工程规范能告诉我们当前 Flutter 工程到底用什么路由注册方式、有没有公共 AppBar、theme token 怎么取。
最后这些信息都会进入 ui-build-plan.json,但各自落在不同区域。
架构实现:能力优先,而不是入口优先
ProtoBridge 采用的是 capability-first 架构,也可以理解成"能力优先"。
CLI、MCP、Core API 都只是不同入口,真正的产品逻辑沉在一组可复用能力里。
核心编排逻辑可以用伪代码理解成下面这样:
ts
async function reconstructPageContext(input) {
// 1. 根据本次输入选择证据来源,不强求 source 和 URL 同时存在
const sourceEvidence = input.source
? await analyzePrototypeSource(input.source)
: undefined;
const runtimeEvidence = input.url && input.capture
? await captureRunningPage(input.url)
: undefined;
const screenshotEvidence = input.screenshot || input.ocr
? await attachScreenshotEvidence(input)
: undefined;
const targetProfile = input.targetRepo
? await inspectFlutterTarget(input.targetRepo)
: undefined;
// 2. 合并成页面级证据原档,记录来源、冲突和待确认问题
const canonicalPage = await mergeEvidence({
sourceEvidence,
runtimeEvidence,
screenshotEvidence,
targetProfile,
});
// 3. 目标工程存在时,生成 agent 默认执行的实现蓝图
const buildPlan = targetProfile
? await createUiBuildPlan(canonicalPage, targetProfile)
: undefined;
// 4. 再把机器蓝图投影成中文审查视图,方便人 review
const review = buildPlan
? await renderHumanReview(buildPlan)
: undefined;
return { canonicalPage, buildPlan, review };
}这也是为什么 ProtoBridge 不要求你每次必须同时提供 source 和 URL。
它支持多种输入组合:
| 输入 | 可用模式 | 特点 |
|---|---|---|
| 原型源码 + 目标工程 | 源码优先 | 结构、状态、交互意图强,但没有截图证据 |
| 页面 URL + 目标工程 | 运行时优先 | 当前视觉事实强,但源码意图弱 |
| 原型源码 + 页面 URL + 目标工程 | 混合模式 | 最完整,推荐用于页面重建 |
| 截图 / OCR + 目标工程 | 补充证据 | 可补充视觉和文字,但不能替代 DOM 或源码 |
| 已实现的目标工程变更 | 实现后验证 | 检查变更范围、硬编码、架构偏离和契约风险 |
这套设计的好处是:入口可以很多,但核心能力只有一套。
CLI 用的是它,MCP server 用的是它,未来如果要嵌到其他 Node.js 工具里,也还是复用这一套能力。
产物权威链:agent 到底应该读谁
有了多个产物以后,最容易出现的问题是:agent 到底应该先看哪个?
ProtoBridge 的规则很明确:
page-canonical.json 是证据原档。
它回答的是:
- 证据来自哪里?
- 源码、运行时、截图和目标工程各提供了什么?
- 哪些字段采用什么优先级?
- 哪些地方存在 mismatch?
- 哪些问题需要人工确认?
page-debug-index.json 是调试索引。
当截图某块区域不对时,可以从文本、section、node id、bbox、style、asset refs 快速定位回 canonical。
ui-build-plan.json 是实现蓝图。
这是 agent 默认应该执行的主文档。
ui-build-review.md 是人类审查视图。
它可以折叠重复节点、简化噪音,但不拥有独立裁判权。review 和 plan 理解不一致时,以 plan 为准。
所以阅读优先级可以简单记成:
text
实现时:ui-build-plan.json 优先
人工快速 review:ui-build-review.md 优先
排查视觉偏差:page-debug-index.json + screenshots 优先
追溯证据来源或冲突:page-canonical.json 优先ui-build-plan.json 里面有什么
把 ui-build-plan.json 理解成四类信息:
| 中文分区 | 解决的问题 |
|---|---|
| 目标工程画像 | 当前 Flutter 工程实际使用什么状态管理、路由、主题、国际化、公共组件和目录组织 |
| 实现契约 | 这个页面应该落到哪些文件,拆成哪些 Widget,状态归谁管,子 Widget 通过什么参数和回调协作 |
| 视觉还原计划 | 当前页面有哪些可见区域、重复卡片/列表项/按钮怎么排布,哪些文本是动态值,哪些字段不能自行补 |
| 映射与验证提示 | source token 如何映射到 target theme,哪些组件可以复用,哪些风险需要实现后检查 |
也就是说,ui-build-plan.json 不是"把页面截图描述一遍",而是把实现前最容易遗漏的信息整理成 agent 可执行的契约。
其中我认为最有价值的是下面四块。
1. 目标工程画像:目标工程到底长什么样
这部分来自目标 Flutter repo 扫描。
它会尽量识别:
- 状态管理模式
- 路由注册和跳转方式
- 国际化调用方式
- 主题和文本样式 token
- 可复用公共组件
- 文件和模块组织方式
比如 GetX、flutter_bloc、Riverpod、Provider、Navigator、go_router、context.t、AppLocalizations、CommonAppBar、themeService,都不是 ProtoBridge 的默认偏好。
只有 target repo 里真的扫描到证据,它们才会影响 plan。
这点很重要。
因为 AI 写代码最容易犯的错误之一,就是把自己熟悉的架构模式带进目标项目。比如目标项目明明用 Bloc,它写一套 GetX;目标项目明明有公共 AppBar,它又手写一个新的;目标项目有 theme token,它直接写死颜色和字号。
ProtoBridge 的原则是:工程表达必须来自目标工程证据。
2. 实现契约:哪些文件和 Widget 应该怎么拆
这部分回答:
- 预期改哪些文件?
- 页面拆成哪些 Widget?
- 状态 owner 在哪里?
- 子 Widget 通过什么参数接收数据?
- 哪些地方需要 callback?
- 哪些地方不能直接读整页 controller?
也就是说,它不是把 DOM section 机械翻译成 Flutter 文件。
运行时证据只负责视觉事实,不决定架构拆分。
真正的文件和 Widget 边界,来自源码语义和目标工程规范的结合。
3. 节点级审查:重复 UI 单元不能靠猜
这是我重点补强的一块。
因为列表项、卡片、tab、chip、按钮、appbar action、bottom action 这类重复 UI 单元,是 AI 还原偏差最高发的地方。
如果只给一个 section summary,agent 很容易漏字段、加字段,或者把文本和 icon 顺序搞错。
所以实现蓝图会把代表性节点的细节提升出来:
- 容器 padding / margin / gap
- radius / border / background
- 按 y 分组的行结构
- 文本和 icon 顺序
- 控件 padding / height / radius
- 资源引用
- 缺失提示
- 不要自行补字段的负向约束
这里的"缺失提示"很有意思。
它不是告诉 agent "这里有什么",而是告诉 agent "这里没有什么"。
比如原型首个卡片里没有 Avail. 字段,agent 就不能为了业务完整性自己补一个 Avail.。这类负向契约,对控制 AI 脑补非常有用。
4. 动态文案提示:动态值不能写死到翻译 key
很多 UI 文案看起来像普通文本,但其实是动态值:
- 列表数量
- 金额
- 百分比
- 日期
- 风险等级
如果不显式标出来,agent 可能会把 +12.8%、8 个交易时段、+$7.4k 当成固定文案或 translation key。
实现蓝图会把这些内容标成动态值,并同步到国际化计划里。
实现时,稳定标签进 i18n,动态值来自 UI model / controller / formatter。
这就是契约的价值:不是让 AI 少写代码,而是让 AI 少猜边界。
示例工程闭环
示例工程的闭环可以这样理解:
这里有一个细节我觉得值得强调:示例里的原型模块是 asset,目标 Flutter 模块是 account。
这不是 bug,而是特意保留下来的风险展示。
当原型模块和目标模块不一致时,ProtoBridge 不应该假装自己知道业务归属,而是把它显式暴露为确认项。因为在真实项目里,模块归属、路由落点、状态 owner 这些问题,经常不是工具能单方面决定的。
工具最应该做的不是替你拍脑袋,而是把不确定性标出来。
MCP:让 agent 直接使用这套能力
ProtoBridge 支持 CLI、MCP 和 core library 三种接入方式。
对 AI coding agent 来说,MCP 是最自然的入口。你可以把 MCP 理解成一组可被 agent 调用的工具接口:agent 不需要手动复制文件、猜路径,而是直接调用工具生成页面上下文、读取目标工程规范、查找相似示例、验证实现结果。
MCP server 暴露了几个工具,职责很直观:
text
reconstruct_page_context 重建页面上下文,生成实现蓝图和审查视图
read_target_conventions 读取目标 Flutter 工程规范
find_target_examples 查找目标工程里的相似页面和组件示例
validate_ui_build 实现后验证目标工程变更一次典型调用是:
json
{
"name": "reconstruct_page_context",
"arguments": {
"route": "/prototype/asset/pnl-analysis",
"url": "http://localhost:5173/#/prototype/asset/pnl-analysis?is_mobile=1",
"capture": true,
"trace": true
}
}生成产物后,agent 的工作流程应该是:
- 先读
ui-build-plan.json - 再用
ui-build-review.md做中文核对 - 目标工程模式不明确时调用
read_target_conventions或find_target_examples - 在目标 Flutter 工程中实现
- 运行 format、analyze、tests
- 调用
validate_ui_build - 汇报变更文件、风险警告和仍需人工确认的问题
这里的关键不是"把 AI 接进来",而是把 AI 接进一个有边界、有证据、有验证的流程里。
实现后验证:它不是视觉百分百证明
validate_ui_build 不是视觉百分百证明。
它更像一个工程 review 辅助器,会检查:
- 变更了哪些文件
- 是否超出允许变更范围
- 实现蓝图预期的文件是否缺失
- 占位文案和 TODO
- 硬编码颜色
- 硬编码字号
- 局部阴影
- 网络图片
- 导航风险标记
- 是否引入目标工程规范没有证据支持的新状态管理 / 路由 / 国际化 / 主题模式
- 子 Widget 是否违反实现契约,例如不该直接读取整页状态却直接依赖 controller
也就是说,它主要防的是工程层面的跑偏。
真正的视觉效果,仍然需要结合截图、运行预览和人工确认。
但即便如此,它也已经比"实现完以后纯靠人肉走查"更进一步:至少变更范围、架构偏离、硬编码风险和契约缺失能先被自动扫一轮。
为什么不直接做 Vue 转 Flutter 编译器
这个问题我自己也想过。
看起来,如果原型是 Vue,目标是 Flutter,那是不是可以直接做一个 Vue SFC 到 Dart Widget 的转换器?
后来我放弃了这个方向。
原因很简单:真实项目里,最难的不是把 div 变成 Container,也不是把 button 变成 TextButton。
难的是:
- 这个页面应该落在哪个 module?
- 目标工程有没有现成公共组件?
- 当前项目用 GetX、Bloc、Riverpod 还是别的?
- 文案应该怎么走 i18n?
- theme token 怎么映射?
- 哪些值是 mock,哪些是动态模型?
- 哪些交互已经由原型证明,哪些仍需人工确认?
- 哪些文件是允许修改的,哪些不应该碰?
这些问题都不是代码翻译能解决的。
如果硬做一对一翻译,很容易得到一个"看起来能跑,但不像目标项目代码"的页面。
所以 ProtoBridge 选择的是另一条路:
不做确定性翻译。
先做证据归一和契约生成。
让 agent 在目标工程里,按目标工程自己的方式实现。
这套设计给我的几个启发
第一,AI 时代的工程效率,不只取决于模型能力,也取决于上下文质量。
很多时候我们觉得 AI 不稳定,其实是输入本身没有边界。PRD 是自然语言,Figma 是静态图,截图是视觉结果,代码仓库是工程现实。它们都重要,但它们不能混成一团丢给 AI。
第二,越是复杂页面,越需要契约。
简单页面靠截图和 prompt 可能也能凑出来。但只要页面开始出现 tab、筛选、弹层、列表、状态机、主题 token、i18n、公共组件复用,靠猜就会变得很危险。
第三,验证不是最后一步才有的事。
如果一开始就知道允许改哪些文件、预期生成哪些 Widget、哪些动态值不能写死、哪些架构模式不能引入,那么验证就可以从"事后挑毛病"变成"契约闭环"的一部分。
第四,工具不要假装自己知道所有业务答案。
缺证据就标出来,冲突就写进 manual confirmation。比起编一个看似完整的答案,明确"不确定"在工程协作里更有价值。
总结
ProtoBridge 做的事情,可以总结成一句话:
把 UI 交付中原本靠人解释、靠 AI 猜测、靠走查兜底的信息,变成可追溯、可审查、可验证的工程契约。
它不是想替代客户端开发者,也不是想把原型页面机械翻译成生产 Flutter 代码。
它更像是 AI coding agent 的"上下文编译层":
- source 负责表达结构、状态和交互意图
- runtime 和 screenshot 负责表达当前视觉事实
- target repo 负责表达工程规范
- plan 负责把这些证据变成实现契约
- review 负责让人能快速读懂
- validation 负责实现后扫一轮工程风险
未来我希望 UI 走查不再是大规模事后兜底,而是变成少量异常确认。
因为大部分应该被解释、被传递、被检查的信息,都已经提前进入了工程产物。
这可能才是 AI 参与客户端研发时,最值得投入的方向:
不是写更玄学的提示词,而是给 AI 更可靠的上下文。