目录
[一、400 tokens/s 到底有多快?](#一、400 tokens/s 到底有多快?)
[三、 为什么速度这么重要?](#三、 为什么速度这么重要?)
[五、结语:AI 正在从"工具"变成"实时伙伴"](#五、结语:AI 正在从“工具”变成“实时伙伴”)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 GLM-5.1高速版
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
平时用大模型的时候,你有没有过这种感觉:AI 确实挺聪明的,但就是有点"慢性子"。
尤其是当你让它写一段长代码,或者帮你分析一份长文档时,看着屏幕上的字一个一个往外蹦,急性子的人恨不得帮它敲键盘。
在日常闲聊时,等个几秒钟无所谓;但在真正干活的生产环境里,这种等待就是对工作效率的消耗。
最近,智谱发布了 GLM-5.1 高速版(GLM-5.1-highspeed),直接把大模型的输出速度飙到了 400 tokens/s。这个速度不仅刷新了目前的行业认知,更重要的是,它可能会彻底改变我们和 AI 协同工作的方式。

一、400 tokens/s 到底有多快?
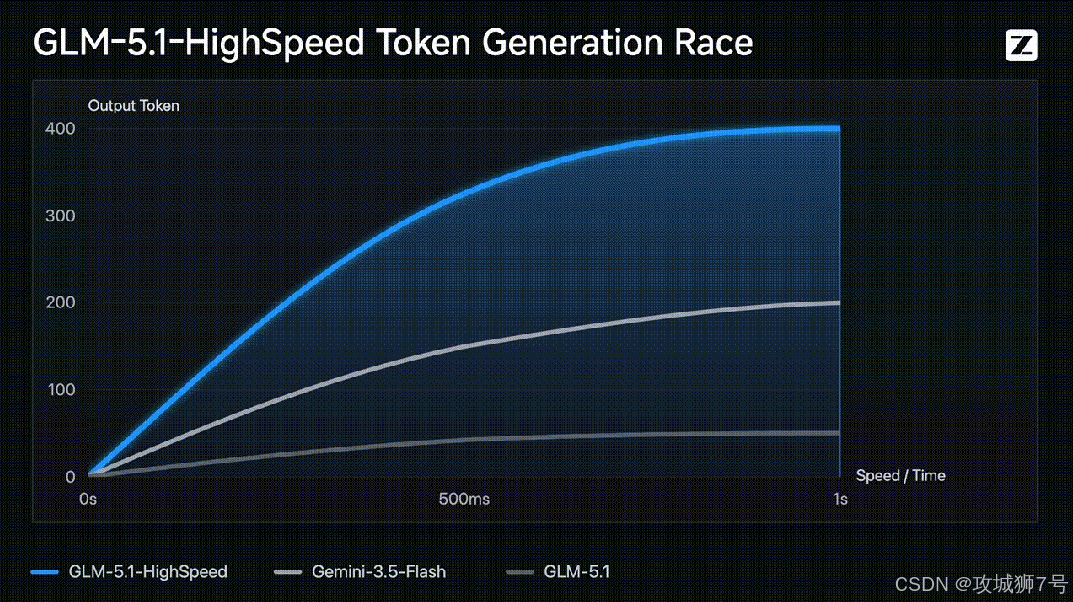
简单科普一下,大模型里的"token"可以理解为字或者词的片段。400 tokens/s,大约相当于一秒钟能输出 600 到 800 个汉字。
这是什么概念呢?
正常人类说话的语速大概是一秒钟 4 到 5 个字;人类阅读的极限速度,一秒钟也就看几十个字。
也就是说,GLM-5.1 高速版输出内容的速度,已经远远超过了你眼睛阅读的速度。
对比一下现在的行业水平:目前市面上主流的顶尖大模型(比如 GPT-4o 或者 Claude 3.5),速度普遍在 80 到 130 tokens/s 之间。智谱这次直接把速度上限拉高了 3 到 5 倍。
以前让 AI 写一篇 1500 字的文章,你可能得去倒杯水,等个两三分钟;现在,30 秒左右就能搞定。
二、鱼和熊掌兼得:打破"快就是笨"的行业魔咒
其实,在 AI 圈子里,想把模型做快并不难,最简单的办法就是"把模型做小"。
过去行业里有个默认的规矩:你要想聪明,就得用参数量极大的旗舰模型,代价就是慢;你要想快,就只能用轻量级的小模型,代价就是容易"降智",处理复杂问题时容易胡说八道。
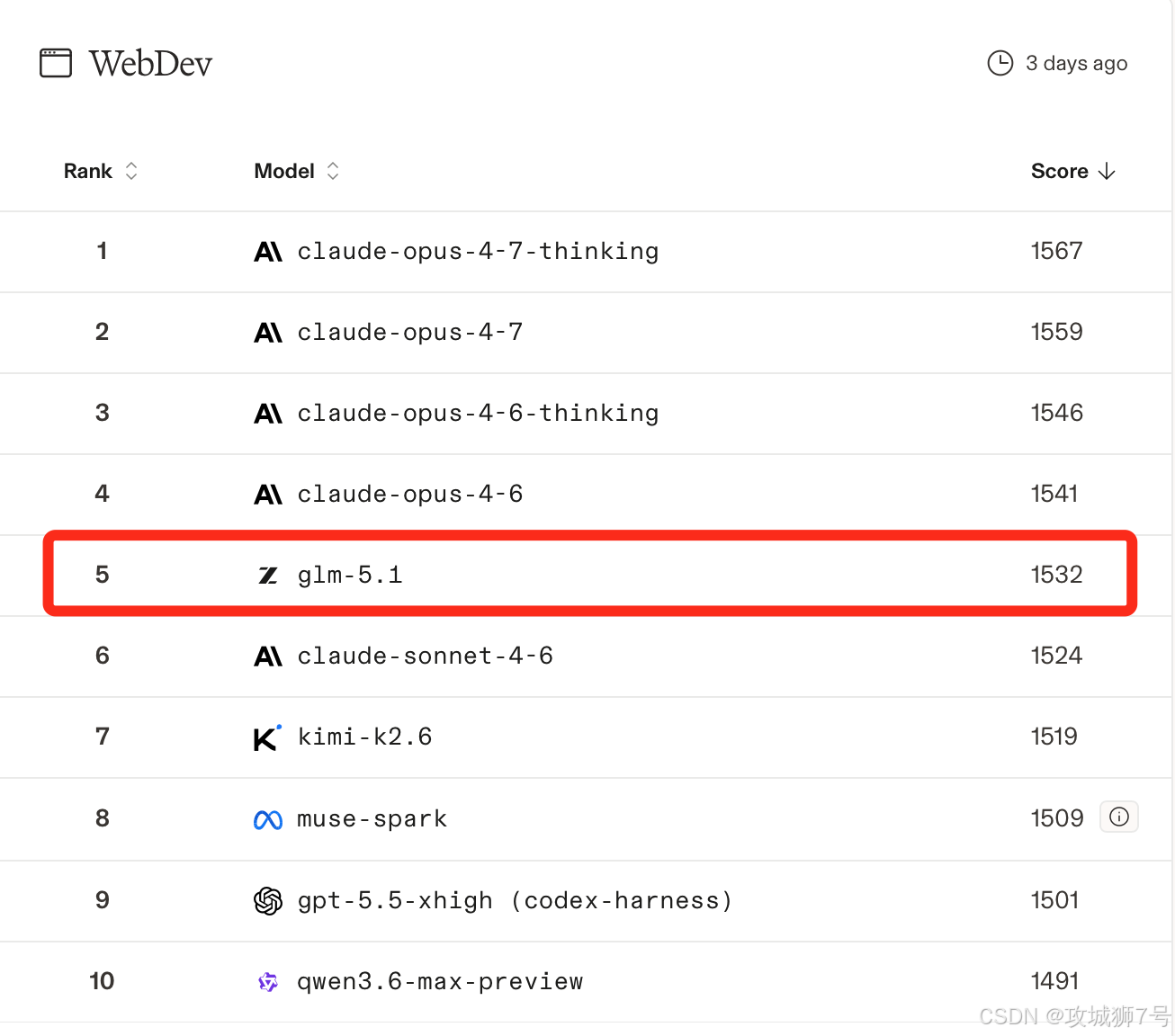
GLM-5.1 高速版最核心的突破,不在于它有多快,而在于它在保持这么快的同时,依然保留了 GLM-5.1 旗舰模型的完整能力。
这就好比给一辆重型卡车装上了跑车的发动机,既能拉重货(处理复杂逻辑),又能跑得飞快。在实测中,无论是让它写复杂的 3D 游戏代码,还是处理长篇的商业文档,它交付的质量甚至比一些慢吞吞的国际顶尖模型还要好。
三、 为什么速度这么重要?
你可能会问,AI 稍微慢一点又怎样,只要结果对不就行了?
如果只是偶尔问个问题,确实没关系。但在很多真实的业务场景里,速度就是生命线。
(1)最典型的例子就是 AI 编程(Coding Agent)。
现在的 AI 写代码,早就不是"你提需求,它写代码"这么简单的一锤子买卖了。一个成熟的 AI 程序员,需要先读取你的项目文件,分析代码依赖,制定修改计划,写代码,跑测试,如果报错了还得自己去排查修改。
**这中间可能需要 AI 在后台自己跟自己对话十几次。**如果 AI 每次思考和输出都要花 10 秒,10 轮下来就是一两分钟的纯等待时间。如果是大型项目,这种等待会把工程师的思路完全打断。
有了 400 tokens/s 的速度,原本需要一两个小时才能跑完的复杂重构任务,现在十几分钟就能搞定。AI 不再是一个需要你耐心等待的"外包工具",而变成了一个能跟上你手速的"结对编程伙伴"。
(2)另一个场景是语音助手。
现在的很多语音助手,你跟它说完话,它总要停顿个两三秒才回答,体验非常生硬。如果底层的模型足够快,AI 就能像真人一样,在你话音刚落的瞬间给出回应,这种交互体验是颠覆性的。
四、速度翻倍的秘密:把算力从"搬砖"中解放出来
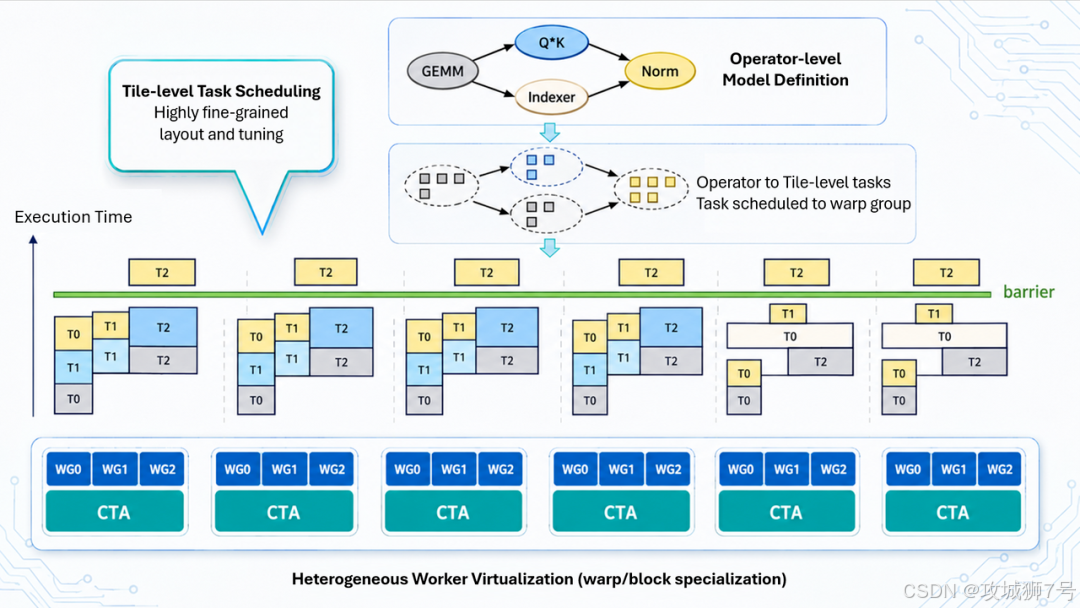
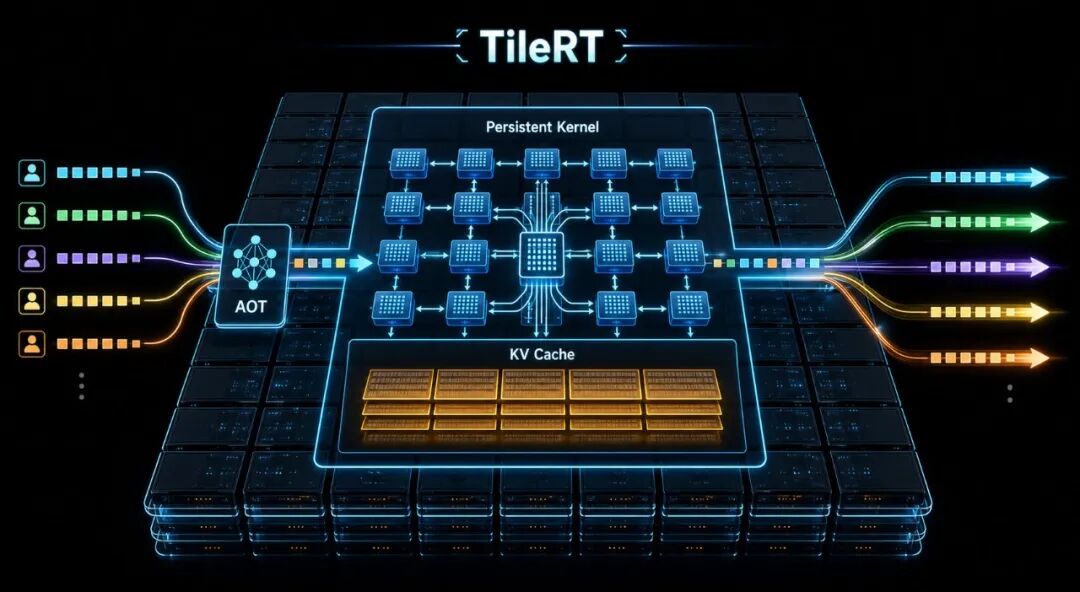
为什么 GLM-5.1 能跑这么快?这就得提到它背后的 TileRT 推理引擎。
结合计算机科学的基础知识来说,现在限制大模型速度的,往往不是 GPU 的算力不够,而是"内存墙"问题。
大模型在推理时,需要频繁地把庞大的参数从显存里搬到计算单元,算完了再搬回去。传统的推理框架,调度方式比较死板。每算一步,都要经历"启动、读数据、计算、写回数据"的完整流程。当任务被切得很碎的时候,GPU 大部分时间其实都在等数据搬运,算力被白白浪费了。
TileRT 引擎的做法非常硬核:它抛弃了传统那种走一步看一步的动态调度,直接在底层把计算任务静态编排好。
打个通俗的比方:
以前的厨房(传统框架),厨师(GPU)每切一盘菜,都要跑到远处的冷库(全局显存)去拿食材,切完再放回去,大部分时间都花在走路上了。
现在的厨房(TileRT),直接把食材提前放在了厨师手边的案板和保鲜柜里(寄存器和高速缓存)。厨师不用来回跑,中间切好的配菜也直接顺手递给下一个环节,效率自然呈指数级上升。
五、结语:AI 正在从"工具"变成"实时伙伴"
GLM-5.1 高速版的出现,释放了一个非常明确的信号:大模型下半场的竞争,已经不仅仅是拼谁更聪明,还要拼谁能把这种聪明以最低的延迟交付给用户。
当 AI 的响应速度超越了人类的感知阈值,量变就会引起质变。
未来,我们使用 AI 的方式将不再是"提交任务 -> 等待结果",而是无缝的实时协作。无论是在代码编辑器里实时补全逻辑,还是在游戏里和 NPC 进行毫无延迟的开放对话,极致的速度都将是这一切的基础。
AI,正在真正成为跟得上你节奏的得力助手。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!