一、什么是分段(Epoching)?
1.1 通俗理解
到目前为止,我们处理的是连续的脑电数据(一整段录音)。
但脑电分析通常关注的是刺激出现前后的大脑反应:
连续数据:
├─────────────────────────────────────────────┤
0秒 100秒 200秒 300秒
↑ 刺激1 ↑ 刺激2 ↑ 刺激3
分段 = 把每个刺激前后的一小段时间"切"出来:
刺激1周围: [刺激前0.2秒]──[刺激]──[刺激后0.5秒]
刺激2周围: [刺激前0.2秒]──[刺激]──[刺激后0.5秒]
刺激3周围: [刺激前0.2秒]──[刺激]──[刺激后0.5秒]1.2 形象比喻
你正在录一整天的声音:
"......早上好......吃了吗......再见......"
分段就是:
把每个"早上好"出现的前后各 1 秒切出来
然后你就能分析:
- "早上好"这个声音的平均波形是什么?
- 每次说"早上好"有什么变化?1.3 Epochs 数据结构
Epochs 对象 = 三维数组
维度1:事件数量(比如 72 个听觉刺激 × 4 种条件 = 288 个分段)
维度2:通道数量(60 个 EEG 通道)
维度3:时间点数(比如 -0.2s 到 0.5s,共 421 个采样点)
形状:(288, 60, 421)
↑ ↑ ↑
事件 通道 时间二、环境准备与数据加载
2.1 导入库和基础设置
python
# ========== 环境设置 ==========
# matplotlib.use('TkAgg') 的作用:
# 指定 matplotlib 的渲染后端
# TkAgg 是 Windows 系统自带的 Tkinter 后端
# 必须在 import pyplot 之前设置,否则可能会报错
# 常见后端对比:
# TkAgg:Windows 自带,无需额外安装
# Qt5Agg:功能更丰富,需要安装 PyQt5
# Agg:不需要显示窗口,只保存图片(适合服务器)
import matplotlib
matplotlib.use('TkAgg')
# pyplot:matplotlib 的主要绘图接口
# 提供类似 MATLAB 的绘图函数(plot, subplot, title 等)
# plt 是约定俗成的简写
import matplotlib.pyplot as plt
# mne:脑电分析核心库
# 包含了数据加载、预处理、分析、可视化的所有功能
import mne
# numpy:数值计算库
# np 是约定俗成的简写
# 提供高效的数组操作、数学运算
import numpy as np
# os:操作系统路径处理模块
# 用于安全地拼接文件路径
import os
# Counter:统计工具
# 可以快速统计列表中各元素出现的次数
# 例如 Counter(['a','a','b']) → {'a':2, 'b':1}
from collections import Counter
# warnings:控制警告信息的显示
import warnings
# filterwarnings('ignore'):
# 忽略所有警告信息,让输出更干净
# 之前遇到的 Blowfish 警告、event missing 警告都会被隐藏
warnings.filterwarnings('ignore')
# ========== 中文字体设置 ==========
# rcParams 是 matplotlib 的全局配置字典
# 类似于软件的"设置"或"偏好设置"菜单
# 'font.sans-serif':设置无衬线字体列表
# matplotlib 会按列表顺序尝试,使用第一个可用的字体
# 'Microsoft YaHei' = 微软雅黑(Windows 常见,美观)
# 'SimHei' = 黑体(Windows 自带,备用方案)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
# 'axes.unicode_minus':控制负号的显示方式
# True(默认):使用 Unicode 减号 "−"(更美观)
# False:使用 ASCII 连字符 "-"
# 为什么设为 False?
# 有些中文字体不支持 Unicode 减号
# 设为 False 可以避免负号显示为方块 □
plt.rcParams['axes.unicode_minus'] = False
# 打印标题分隔线
# "="*60 表示将 "=" 重复 60 次
print("="*60)
print("MNE-Python 第6天:分段(Epoching)与基线校正")
print("="*60)2.2 加载原始数据
python
# ---------- 1. 加载数据 ----------
# mne.datasets.sample.data_path() 的作用:
# 返回 MNE 示例数据集的存储路径
# 第一次运行时:
# 1. 自动从网上下载数据集(约 2GB)
# 2. 保存到 ~/mne_data/ 目录
# 之后运行时:直接返回本地路径,不会重新下载
sample_data_folder = mne.datasets.sample.data_path()
# os.path.join():安全地拼接文件路径
# 为什么不用 + 号直接拼接?
# Windows 用反斜杠 \,Linux/Mac 用正斜杠 /
# os.path.join() 会自动使用正确的分隔符
# 例如:
# Windows: "MEG\sample\file.fif"
# Linux: "MEG/sample/file.fif"
raw_fname = os.path.join(
sample_data_folder, # 数据集根目录
'MEG', # MEG 子目录
'sample', # sample 子目录
'sample_audvis_raw.fif' # 原始数据文件名
)
# mne.io.read_raw_fif():读取 .fif 格式的原始脑电数据
# .fif = Functional Image File,MNE 的原生数据格式
#
# preload=False 的含义:
# 数据暂存在硬盘上,不加载到内存(RAM)
# 优点:节省内存,适合大文件
# 缺点:操作时需要从硬盘读取,速度慢
#
# preload=True 的含义:
# 数据立即加载到内存
# 优点:操作速度快
# 缺点:占用内存(但这个数据集不大,可以接受)
raw = mne.io.read_raw_fif(raw_fname, preload=False)
print("✅ 原始数据加载完成").fif 文件内部结构:
python
.fif 文件就像一个"大箱子",里面装有:
┌─────────────────────────────┐
│ 📊 信号数据 │
│ - 每个通道每个时间点的数值 │
│ │
│ 📋 通道信息 │
│ - 通道名称(EEG 001 等) │
│ - 通道类型(eeg/eog/stim) │
│ - 电极位置 │
│ │
│ ⚙️ 元数据 │
│ - 采样率(600.61 Hz) │
│ - 采集日期 │
│ - 设备信息 │
└─────────────────────────────┘三、数据预处理
3.1 提取通道
python
# ---------- 2. 快速预处理 ----------
print("\n快速预处理...")
# raw.copy():创建数据的独立副本
# 为什么要 copy?
# 保持原始 raw 对象不变
# 这样如果后续操作出错,可以回到原始状态重新开始
# 类似于"另存为"而不是"保存"
# pick_types():根据通道类型筛选通道
# eeg=True → 保留 EEG(脑电)通道
# eog=True → 保留 EOG(眼电)通道,后续 ICA 需要
# stim=True → 保留 STIM(刺激标记)通道,提取事件需要
#
# 注意:这里没有 ecg=True,因为这个数据集没有 ECG 通道
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, stim=True)
print(f" 提取了 {len(raw_eeg.ch_names)} 个通道")通道类型说明:

3.2 重命名通道并设置 Montage
python
# 找出所有以 'EEG' 开头的通道名称
# 列表推导式的语法:[表达式 for 变量 in 列表 if 条件]
# 遍历 raw_eeg.ch_names 中的每个通道名
# 只保留以 'EEG' 开头的
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
print(f" EEG 通道数: {len(eeg_names)}")
print(f" EEG 通道示例: {eeg_names[:3]}") # 前3个,如 ['EEG 001', 'EEG 002', 'EEG 003']
# 创建标准 10-20 系统的蒙太奇(第2天学的内容)
# make_standard_montage() 返回一个 Montage 对象
# 包含 94 个标准电极的 3D 坐标
montage = mne.channels.make_standard_montage('standard_1020')
# 从标准蒙太奇中取相同数量的电极名称
# montage.ch_names 包含所有标准电极名(如 'Fz', 'Cz', 'Pz', ...)
# [:len(eeg_names)] 取前 N 个(N = EEG 通道数量)
standard_names = montage.ch_names[:len(eeg_names)]
print(f" 标准名称示例: {standard_names[:3]}") # 如 ['Fz', 'Cz', 'Pz']
# dict(zip(A, B)) 详解:
# 步骤1:zip(eeg_names, standard_names)
# 将两个列表逐对配对,生成迭代器
# → [('EEG 001', 'Fz'), ('EEG 002', 'Cz'), ('EEG 003', 'Pz'), ...]
#
# 步骤2:dict(...)
# 将配对列表转换为字典
# → {'EEG 001': 'Fz', 'EEG 002': 'Cz', 'EEG 003': 'Pz', ...}
#
# 这个字典就是"重命名映射表"
rename_dict = dict(zip(eeg_names, standard_names))
# rename_channels():根据字典批量重命名通道
# 旧名称(键) → 新名称(值)
raw_eeg.rename_channels(rename_dict)
print(f" 重命名后通道示例: {raw_eeg.ch_names[:3]}") # ['Fz', 'Cz', 'Pz']
# set_montage():设置电极在头皮上的位置
# MNE 会根据通道名称在 montage 中查找对应的 3D 坐标
# 这样才能画地形图
raw_eeg.set_montage(montage)
print(" 通道重命名和蒙太奇设置完成")3.3 🔑 关键步骤:先加载数据,再滤波
python
# ⚠️ 重要:滤波等操作必须在数据加载到内存之后!
# load_data() 的作用:
# 将数据从硬盘文件读到计算机的内存(RAM)中
# 内存中的读写速度比硬盘快几百倍
#
# 为什么不能在 preload=False 时做滤波?
# 滤波需要对每个数据点做数学运算
# 如果数据在硬盘上,每次读取都非常慢
# MNE 为了防止这种情况,直接报错提醒你
print(" 加载数据到内存...")
raw_eeg.load_data()
print(" ✅ 数据已加载到内存")preload 与 load_data 的关系:
python
# 方式1:加载时直接预加载
raw = mne.io.read_raw_fif('file.fif', preload=True)
# 此时数据已在内存中
# 方式2:先不加载,需要时再加载(本次的方式)
raw = mne.io.read_raw_fif('file.fif', preload=False)
# ... 做一些不需要内存的操作 ...
raw.load_data() # 现在加载到内存
# ... 做需要内存的操作(滤波等)...3.4 陷波滤波
python
# notch_filter():陷波滤波器
#
# 陷波滤波器在特定频率"挖一个非常窄的坑"
# 只去除这一个频率,不影响其他频率
#
# 50Hz(中国/欧洲)或 60Hz(美国)是交流电的频率
# 电线、电器产生的电磁场会被电极拾取
# 在脑电信号中表现为持续的嗡嗡声
print(" 陷波滤波(去除 60Hz)...")
raw_eeg.notch_filter(
freqs=60, # 要去除的频率
picks='eeg', # 只对 EEG 通道滤波
verbose=False # 不打印详细信息
)
print(" ✅ 去除了 60Hz 工频干扰")陷波滤波原理图:
python
信号幅度
│
│ ┌─┐
│ │ │ ← 60Hz 的尖峰(工频干扰)
│ ╱ ╲
│ ╱ ╲___ ← 正常的脑电信号
│ ╱
└────────────────────→ 频率
↑
60Hz被"挖掉"3.5 带通滤波
python
# filter():带通滤波器
#
# 带通滤波 = 高通滤波 + 低通滤波
# 高通部分:去除低于 l_freq 的频率
# 低通部分:去除高于 h_freq 的频率
#
# 本次的设置:
# l_freq=1:去除 <1Hz 的缓慢漂移(出汗、电极移动)
# h_freq=40:去除 >40Hz 的高频噪声(肌肉活动、电磁干扰)
# 保留 1-40Hz:包含了脑电的主要频段
print(" 带通滤波(1-40 Hz)...")
raw_eeg.filter(
l_freq=1, # 低截止频率(高通部分)
h_freq=40, # 高截止频率(低通部分)
picks='eeg', # 只对 EEG 通道滤波
verbose=False
)
print(" ✅ 保留了 1-40 Hz 的信号")脑电频段与滤波的关系:
python
频段 频率范围 本次是否保留
─────────────────────────────────────
Delta δ 0.5-4 Hz ✅ 保留(>1Hz 部分)
Theta θ 4-8 Hz ✅ 保留
Alpha α 8-13 Hz ✅ 保留
Beta β 13-30 Hz ✅ 保留
Gamma γ 30-100 Hz ⚠️ 部分保留(30-40Hz)
高频噪声 >40 Hz ❌ 去除
基线漂移 <1 Hz ❌ 去除3.6 重参考
python
# set_eeg_reference():设置 EEG 参考
#
# 脑电测量的是"电位差":
# 记录值 = 电极电位 - 参考电位
#
# 采集时可能以 Cz(头顶)或耳垂为参考
# 但这些位置本身也有脑电活动,不是"中性"的
#
# 平均参考('average'):
# 新参考 = 所有 EEG 通道的平均值
# 每个通道的新值 = 原值 - 所有通道的平均值
# 假设:全头平均电位 ≈ 0
# 优点:标准、可重复、适合高密度电极
print(" 重参考(平均参考)...")
raw_eeg.set_eeg_reference(
'average', # 参考类型:所有通道的平均值
verbose=False
)
print(" ✅ 重参考完成(平均参考)")重参考的数学原理:
python
# 假设有 3 个通道
ch1 = 10 # μV
ch2 = 20 # μV
ch3 = -5 # μV
# 平均参考
average = (10 + 20 + (-5)) / 3 = 8.33 μV
# 新的值
ch1_new = 10 - 8.33 = 1.67 μV
ch2_new = 20 - 8.33 = 11.67 μV
ch3_new = -5 - 8.33 = -13.33 μV
# 验证:新值的平均值 = 0
(1.67 + 11.67 + (-13.33)) / 3 ≈ 0 ✅四、提取事件
4.1 从刺激通道提取事件
python
# ---------- 3. 提取事件 ----------
print("\n提取事件...")
# find_events():从刺激通道自动检测事件
#
# 工作原理:
# 1. 监控刺激通道(STI 014)的值
# 2. 平时值是 0,刺激出现时值变为非 0
# 3. 检测到变化时,记录为事件
#
# 返回值:events 数组
# 形状:(N, 3)
# N = 事件总数
# 每行 = [采样点编号, 持续采样点数, 事件编号]
events = mne.find_events(
raw_eeg, # 包含刺激通道的数据
stim_channel='STI 014' # 刺激通道的名称
)
print(f" 提取到 {len(events)} 个事件")
# 查看事件数组的前5行
print(f"\n 前5个事件:")
print(f" 采样点 持续时间 事件编号")
for i in range(min(5, len(events))):
sample = events[i, 0] # 第0列:采样点位置
duration = events[i, 1] # 第1列:持续时间
event_code = events[i, 2] # 第2列:事件编号
time_sec = sample / raw_eeg.info['sfreq'] # 转换为秒
print(f" {sample:6d} {duration:4d} {event_code} (={time_sec:.1f}秒)")事件数组的结构:
python
# events 是一个 N×3 的二维数组
# 可以理解为一张表格:
# ┌─────────┬─────────┬─────────┐
# │ 采样点 │ 持续时间│ 事件编号│
# ├─────────┼─────────┼─────────┤
# │ 15000 │ 0 │ 1 │ ← 第1个事件:编号1,瞬时
# │ 23000 │ 0 │ 2 │ ← 第2个事件:编号2,瞬时
# │ 31000 │ 0 │ 1 │ ← 第3个事件:编号1,瞬时
# │ ... │ ... │ ... │
# └─────────┴─────────┴─────────┘4.2 创建事件 ID 字典
python
# event_id 字典:将数字编号映射为有意义的事件名称
# 键 = 条件名称(字符串)
# 值 = 事件编号(整数)
event_id = {
'听觉/左耳': 1, # 编号 1 = 左耳听到纯音
'听觉/右耳': 2, # 编号 2 = 右耳听到纯音
'视觉/左眼': 3, # 编号 3 = 左眼看到棋盘格
'视觉/右眼': 4 # 编号 4 = 右眼看到棋盘格
}
# 统计每种事件的次数
print("\n事件统计:")
for event_name, event_code in event_id.items():
# .items() 返回 (键, 值) 对
# np.sum(events[:, 2] == event_code)
# 统计第2列中等于 event_code 的行数
count = np.sum(events[:, 2] == event_code)
print(f" {event_name} (编号{event_code}): {count} 次")五、创建 Epochs(分段)
5.1 理解时间窗口
python
print("""
分段的时间窗口设计:
刺激前(基线期) 刺激点 刺激后(反应期)
←──────────|──────────★──────────|──────────→
-0.2秒 0秒 0.5秒
tmin = -0.2:从刺激前 0.2 秒开始
tmax = 0.5:到刺激后 0.5 秒结束
为什么这样设置?
- 基线期(-0.2 ~ 0秒):观察刺激前的大脑状态
- 反应期(0 ~ 0.5秒):观察刺激引起的大脑反应
- 总长 0.7 秒:足够看到早期和中期脑电成分
""")5.2 定义拒绝标准
python
# reject 参数:定义"坏段"的判断标准
#
# 什么是"坏段"?
# 幅度异常大的分段,通常是由残留伪迹引起的:
# - 被试突然咳嗽
# - 电极瞬间接触不良
# - 眨眼没有被 ICA 完全去除
#
# reject_criteria 是一个字典
# 键 = 通道类型
# 值 = 幅度阈值(单位:伏特)
#
# 150e-6 的含义:
# 150 × 10⁻⁶ = 0.000150 伏特 = 150 微伏
# 如果分段中任何 EEG 通道的幅度超过 ±150μV
# 这个分段就会被丢弃
reject_criteria = dict(
eeg=150e-6 # 150 微伏
)
print(f" 拒绝标准: 幅度超过 {reject_criteria['eeg']*1e6:.0f} 微伏的分段将被丢弃")不同伪迹的幅度参考:

5.3 创建 Epochs 对象
python
# ---------- 4. 创建 Epochs ----------
print("\n创建 Epochs...")
# mne.Epochs():从连续数据创建分段
epochs = mne.Epochs(
# ── 数据源 ──
raw_eeg, # 连续 EEG 数据
events, # 事件数组(告诉 MNE 在哪切)
event_id=event_id, # 事件 ID 字典(告诉 MNE 每个编号叫什么)
# ── 时间窗口 ──
tmin=-0.2, # 分段起始时间(刺激前 0.2 秒)
tmax=0.5, # 分段结束时间(刺激后 0.5 秒)
# 总时长 = tmax - tmin = 0.5 - (-0.2) = 0.7 秒
# ── 基线校正 ──
baseline=(-0.2, 0), # 用刺激前 0.2 秒做基线
# 原理:每个分段减去基线期的平均值
# 效果:让所有分段从同一"起跑线"开始
# ── 质量控制 ──
reject=reject_criteria, # 拒绝幅度异常的分段
# ── 内存管理 ──
preload=True, # 加载到内存,加速后续操作
# ── 输出控制 ──
verbose=False # 不打印详细信息
)
# 输出统计信息
print(f"✅ Epochs 创建完成")
print(f" 总事件数: {len(events)}")
print(f" 保留分段: {len(epochs)} ({len(epochs)/len(events)*100:.1f}%)")
print(f" 丢弃分段: {len(events) - len(epochs)} ({(len(events)-len(epochs))/len(events)*100:.1f}%)")
# 查看各条件的分段数
print(f"\n各条件分段统计:")
for cond_name in event_id.keys():
n_epochs = len(epochs[cond_name])
n_events = np.sum(events[:, 2] == event_id[cond_name])
print(f" {cond_name}: {n_epochs}/{n_events} 个 (保留率 {n_epochs/n_events*100:.1f}%)")Epochs 参数详解表:
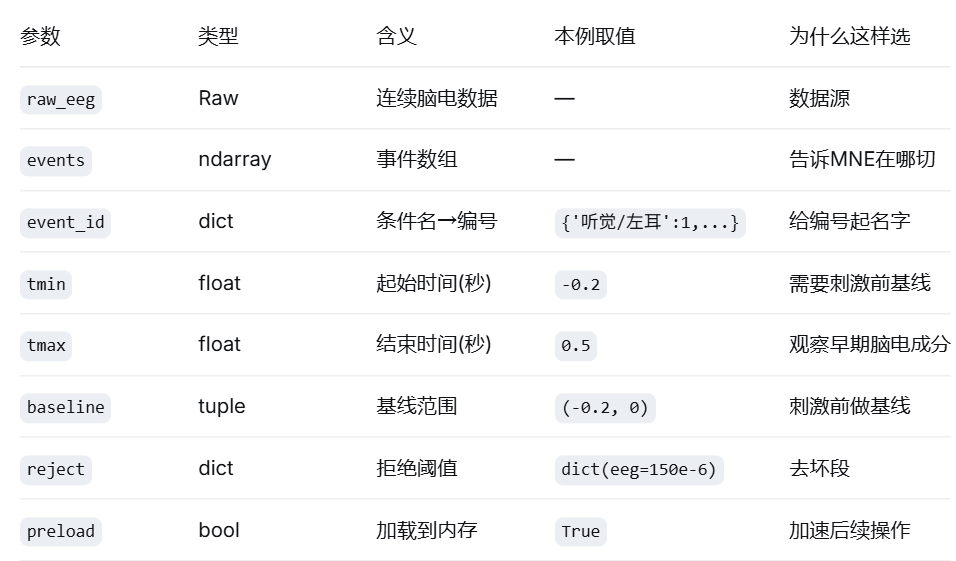
六、基线校正详解
6.1 为什么需要基线校正?
python
问题:不同分段可能在不同的"高度"
分段1: ~~~~~/‾‾‾‾‾~~~~ ← 整体偏上(+20 μV 偏移)
分段2: ___/‾‾‾‾‾‾___ ← 整体偏下(-10 μV 偏移)
分段3: ~~~~~/‾‾‾‾‾~~~~ ← 整体居中(0 μV)
如果不校正,叠加平均会被偏移污染
就好像把不同亮度的照片叠在一起,结果一片模糊
基线校正后:
分段1: ___/‾‾‾‾‾‾___ ← 都从 0 开始
分段2: ___/‾‾‾‾‾‾___ ← 都从 0 开始
分段3: ___/‾‾‾‾‾‾___ ← 都从 0 开始
现在可以公平地比较和叠加了!6.2 基线校正的数学原理
python
# 基线校正的数学过程:
# 对于每个分段、每个通道:
# 1. 找到基线期的时间范围(-0.2 到 0 秒)
# 2. 计算基线期内的平均值
# baseline_mean = mean(data[基线期内])
# 3. 用整个分段减去这个平均值
# data_corrected = data - baseline_mean
# 4. 结果:基线期的平均值为 0
# 简单例子:
原始分段 = [2.1, 2.2, 2.0, 2.5, 2.8, 3.1, 3.5]
# ↑── 基线期 ──↑ ↑── 反应期 ──↑
基线均值 = (2.1 + 2.2 + 2.0) / 3 = 2.1
校正后 = [-0.0, 0.1, -0.1, 0.4, 0.7, 1.0, 1.4]
# ↑── 基线期 ≈ 0 ──↑七、Epochs 可视化
7.1 蝴蝶图
python
# ---------- 5. 可视化 ----------
print("\n可视化...")
# epochs.plot():绘制分段的"蝴蝶图"
#
# 为什么叫蝴蝶图?
# 所有分段画在同一张图上
# 像蝴蝶翅膀一样展开
#
# 怎么看?
# 每条半透明的线 = 一个分段
# 线条的分布 = 不同分段之间的差异
# 线条密集处 = 稳定的脑电反应
# 线条离散处 = 变化较大的脑电反应
print("1. 绘制前 20 个分段的蝴蝶图...")
epochs[:20].plot(
n_epochs=20, # 显示的分段数量
n_channels=10, # 显示的通道数量
scalings='auto', # 自动调整纵轴比例
show=True # 显示图形
)
plt.suptitle('前 20 个分段(蝴蝶图)', fontsize=14, fontweight='bold')
plt.show(block=True) # block=True:保持窗口打开蝴蝶图解读指南:
python
振幅
↑
│ ╱‾‾╲ ← 所有分段在刺激后的反应
│ ╱ ╲___
│╱ ╲___
────┼──────────────→ 时间
│ ↑
│ 刺激点(0秒)
看什么?
1. 基线期(-0.2~0秒)应该接近 0
2. 刺激后各分段的变化方向是否一致
3. 有没有特别离谱的分离(可能是坏段)7.2 丢弃日志
python
# plot_drop_log():绘制分段丢弃日志
#
# 这个图显示:
# - 每个条件有多少分段被丢弃
# - 丢弃的原因是什么
# - 被丢弃分段之间的关联
print("\n2. 绘制分段丢弃日志...")
fig = epochs.plot_drop_log(show=False)
plt.suptitle('分段丢弃日志', fontsize=14, fontweight='bold')
plt.show(block=True)八、保存结果
python
# ---------- 6. 保存 ----------
# save():将 Epochs 对象保存为 .fif 文件
# 保存了什么?
# - 所有分段的数据
# - 通道信息
# - 事件信息
# - 时间信息
# 下次可以直接加载,无需重新预处理和分段
epochs.save('day6_epochs.fif', overwrite=True)
print("\n✅ 数据已保存为 day6_epochs.fif")
print("\n" + "="*60)
print("第6天学习完成!")
print("="*60)九、第6天完整代码
python
# ========== 环境设置 ==========
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import mne
import numpy as np
import os
from collections import Counter
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第6天:分段(Epoching)与基线校正")
print("="*60)
# ---------- 1. 加载数据 ----------
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
print("✅ 原始数据加载完成")
# ---------- 2. 快速预处理 ----------
print("\n快速预处理...")
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, stim=True)
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
montage = mne.channels.make_standard_montage('standard_1020')
standard_names = montage.ch_names[:len(eeg_names)]
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
raw_eeg.set_montage(montage)
print(" 加载数据到内存...")
raw_eeg.load_data()
print(" 陷波滤波(去除 60Hz)...")
raw_eeg.notch_filter(freqs=60, picks='eeg', verbose=False)
print(" 带通滤波(1-40 Hz)...")
raw_eeg.filter(l_freq=1, h_freq=40, picks='eeg', verbose=False)
print(" 重参考(平均参考)...")
raw_eeg.set_eeg_reference('average', verbose=False)
print("✅ 快速预处理完成")
# ---------- 3. 提取事件 ----------
print("\n提取事件...")
events = mne.find_events(raw_eeg, stim_channel='STI 014')
print(f" 提取到 {len(events)} 个事件")
event_id = {
'听觉/左耳': 1,
'听觉/右耳': 2,
'视觉/左眼': 3,
'视觉/右眼': 4
}
for event_name, event_code in event_id.items():
count = np.sum(events[:, 2] == event_code)
print(f" {event_name}: {count} 次")
# ---------- 4. 创建 Epochs ----------
print("\n创建 Epochs...")
reject_criteria = dict(eeg=150e-6)
epochs = mne.Epochs(
raw_eeg, events, event_id=event_id,
tmin=-0.2, tmax=0.5,
baseline=(-0.2, 0),
reject=reject_criteria,
preload=True,
verbose=False
)
print(f"✅ Epochs 创建完成")
print(f" 总事件: {len(events)}, 保留: {len(epochs)}, 丢弃: {len(events)-len(epochs)}")
# ---------- 5. 可视化 ----------
print("\n可视化...")
epochs[:20].plot(n_epochs=20, n_channels=10, scalings='auto', show=True)
plt.suptitle('前 20 个分段(蝴蝶图)', fontsize=14)
plt.show(block=True)
fig = epochs.plot_drop_log(show=False)
plt.suptitle('分段丢弃日志', fontsize=14)
plt.show(block=True)
# ---------- 6. 保存 ----------
epochs.save('day6_epochs.fif', overwrite=True)
print("\n✅ 数据已保存为 day6_epochs.fif")
print("\n" + "="*60)
print("第6天学习完成!")
print("="*60)十、今日总结
📝 核心概念

🛠️ 掌握的技能

🔑 操作顺序铁律
python
1. 提取通道 pick_types()
2. 重命名通道 rename_channels()
3. 设置蒙太奇 set_montage()
4. 加载到内存 load_data() ← 关键!必须在这之后
5. 陷波滤波 notch_filter()
6. 带通滤波 filter()
7. 重参考 set_eeg_reference()
8. 提取事件 find_events()
9. 创建分段 mne.Epochs()