Floating-point Support
目前Arm architecture支持的floating-point extension版本是FPv5。FPv5提供了以下功能:
- 单精度算术运算;
- 可选的双精度算术运算;
- 整数、双精度、单精度、和半精度格式之间的转换;
- 用于浮点处理的寄存器:S0-S31或D0-D15;
- 在Arm通用寄存器(GPR)和FPv5 extension寄存器S0-S31或D0-D15之间进行单精度或双精度值的数据传输;
- 软件可以启用或禁用的"Flush-to-zero"模式;
- IEEE 754-2008的半精度格式和alternative半精度格式,通过FPSCR.AHP指示选择哪一种;
FPv5也增加了以下系统寄存器:
- 在CP10和CP11系统寄存器空间的FPSCR;
- SCB里的FPCAR, FPCCR, FPDSCR, MVFR0, MVFR1和MVFR2;
从Armv8.1-M开始,FPv5提供半精度算术运算。
当floating-pointer extension实现时,软件可以查询MVFR0, MVFR1和MVFR2来查看所实现的浮点特性有哪些。另外执行产生floating-point exception的floating-point指令会更新FPSCR的一些状态字段。
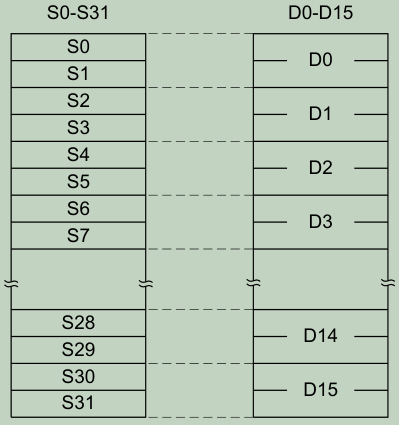
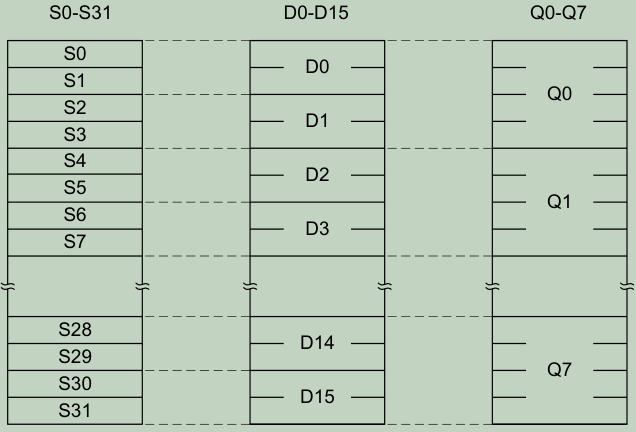
FPv5为浮点处理添加的寄存器如下所示:
- 32单精度寄存器,S0-S31;
- 16双精度寄存器,D0-D15;
这些寄存器映射关系如下:
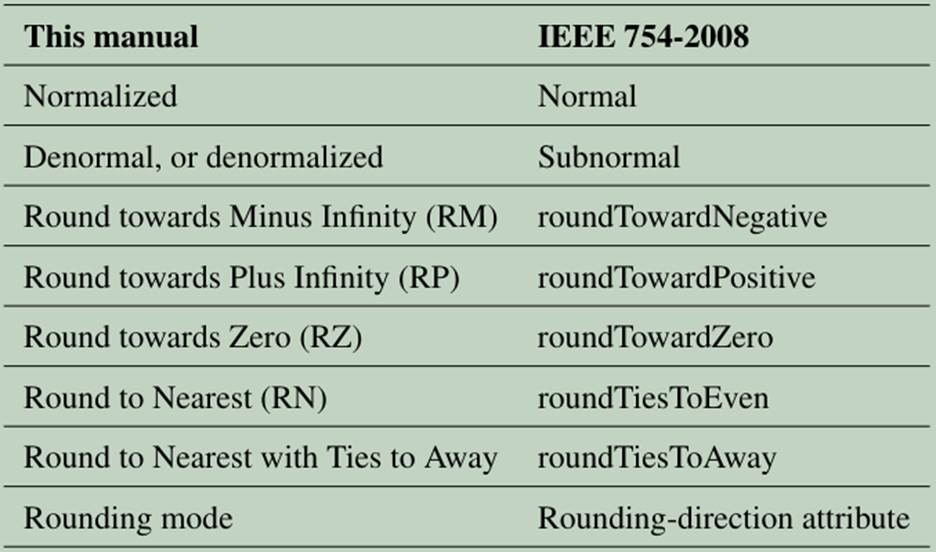
Arm手册使用的浮点术语与IEEE 754-2008中使用的术语不同如下:
Arm支持的标准浮点运算有IEEE 754-2008再加上以下配置:
-
- Flush-to-zero mode enabled.
- Default NaN mode enabled.
- Round to Nearest mode selected.
- Alternative half-precision interpretation not selected.
根据IEEE 754的定义,FPv5支持以下浮点数据:
- Normalized numbers.
- Denormalized numbers.
- Zeros, +0 and -0.
- Infinities, +∞ and −∞.
- NaNs, signaling NaNs and quiet NaN.
另外Denormalized的数字可以使用Flush-to-zero模式刷新为0。
IEEE 754 Floating-point exception有:
- Invalid Operation
- Division by zero
- Overflow
- Underflow
- Inexact
这些IEEE 754浮点exception对应的状态标志是FPSCR.{IOC, DZC, OFC, UFC,
IXC}
Flush-to-zero mode
当Flush-to-zero mode开启时,所有floating-point操作的single-precision denormalized输入、double-precision denormalized输入或half-precision denormalized输入都会被视为0,也就是说,它们的值被刷新为0了。
当floating-point操作的输入被刷新为0时,PE生成一个输入denormal exception。而且输入denormal exception也只有在Flush-to-zero mode下才会产生的。
当floating-point操作的结果刷新为零时,PE生成一个Underflow exception。
当floating-point数字被刷新为0时,符号将被保留。也就是说,0的符号位与被刷新为0的数字的符号位相匹配。
NaN
NaN是Not a Number的缩写。当数值和无穷大都不合适时可以使用的NaN浮点值。NaN可以是quiet NaN(通过大多数浮点操作传输),也可以是signaling NaN(在使用时导致Invalid Operation floating-point exception)。
当启用Default NaN模式时,Default NaN是以下两种情况的结果:
- 所有产生untrapped Invalid Operation exception的浮点操作。
- 所有输入至少包含一个queit NaN但不包含signaling NaN的浮点运算。
Vector Extension
Vector指令对固定的128-bit矢量宽度进行操作。MVE-I可以操作32-bit,16-bit和8-bit数据类型。MVE-F也可以对half-precision和single-precision floating-point值进行操作。Vector操作分为两种正交的方式:
- Lanes
- Beats
每个beat可以执行多个lanes,Element表示放入每个beat的一个lane中的数据。每个vector指令有4个beats。Vector指令的伪代码是按一个beat来写的,因此需要执行4次才是一个vector指令的真正功能。GetCurInstrBeat()函数返回当前节beat数和predication细节。它们决定了在当前执行代码期间对哪些lanes进行操作。
Lanes
正被执行的指令决定了操作的lane宽度。每一个beat允许的lane宽度和lane操作有:
- For a 64-bit lane size, a beat performs half of the lane operation.
- For a 32-bit lane size, a beat performs a one lane operation.
- For a 16-bit lane size, a beat performs a two lane operations.
- For an 8-bit lane size, a beat performs a four lane operations.
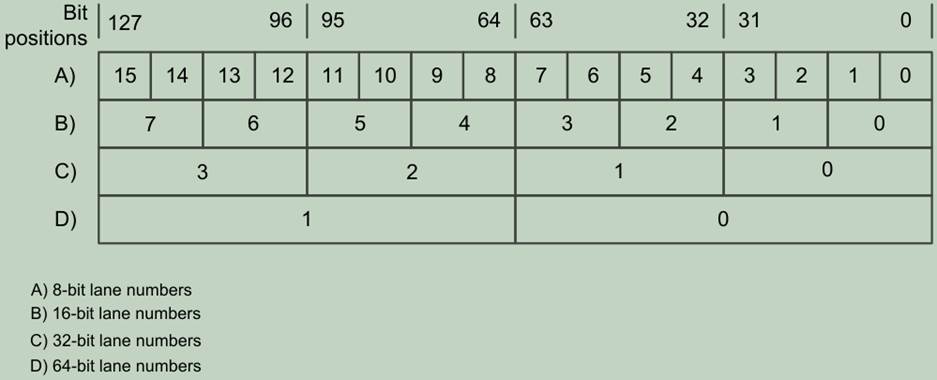
Beats
vector指令按顺序执行beat,从节拍0-3开始。

在一般情况下,每个tick的beat数目描述了在每个architecture tick下更新了多少architectural state。在一个简单的实现中,一个architecture tick可能是一个时钟周期:
- In a single-beat system, one beat might occur for each tick.
- In a dual-beat system, two beats might occur for each tick.
- In a quad-beat system, four beats might complete for each tick.
每个architecture tick执行多少beats是IMPLEMENTATION DEFINED的。每个tick的beat数可能在运行时改变,不需要保持恒定。
在一个architecture tick内可能出现多个faults。在这种情况下,只有一个fault会raise起来,被raise情况的fault按以下优先级确定:
- 来自最早指令的fault优先;
- 如果多个fault与最早的fault指令相关联,则按编码按最低beat产生的fault优先;
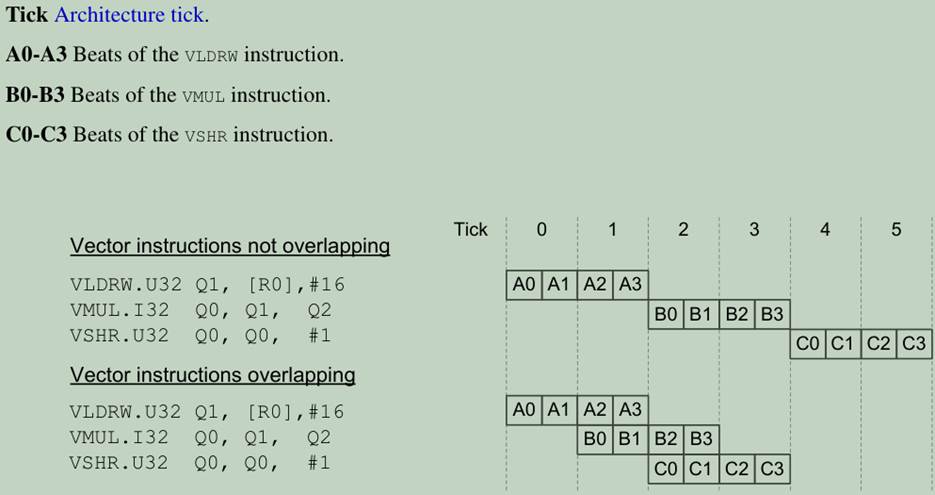
在dual-beat overlap系统中,vector指令的最后两个beat和下一条vector指令的前两个beat可以重叠处理。下面是一个dual-beat系统的例子,其中每个architecture tick可以处理两个beat。如图:
PE可以从任何有效的ECI值恢复exception continuable instruction的执行,即使PE不能生成所有的ECI值。
对于vector指令来说,只有当该条的所有beats都完成后,PC才会更新。
由于Vector的load和store会产生多笔memory访问,Arm规定了由同一Observers对同一vector store指令生成的多个elements写入可以按任何顺序被观察到,但不同elements对同一位置的写入是按vector element number递增的顺序被观察的。
如果CCR.BFHFNMIGN为1,如果请求为负priority且执行一条指令产生多个load或store访问时,生成了BusFault,该 BusFault可能会影响该指令生成的所有访问,而不仅仅是生成BusFault的访问。
Vector register file
MVE定义了8个向量寄存器,Q<n>,它们复用Floating-point Extension的寄存器实体。
Q0127:96 = S3, Q095:64 = S2, Q063:32 = S1, Q031:0 = S0
Q1127:96 = S7, Q195:64 = S6, Q163:32 = S5, Q131:0 = S4
...
Q7127:96 = S31, Q795:64 = S30, Q763:32 = S29, Q731:0 = S28
这些寄存器映射如下:
为了减少对vector register的压力,许多vector指令可以使用GPR作为参数。
Predication/conditional execution
MVE包括predication机制,可以在vector操作中对每个lane进行独立屏蔽。它支持以下predication机制:
- Loop tail predication(循环尾部预测):它消除了如果要处理的elements数量不是vector中element数量的倍数,那么在循环之后需要特殊的vector尾部代码处理的需求。
- VPT predication:这使得基于数据值比较的数据相关条件能够单独屏蔽每个向量lane。
Loop tail predication和VPT predication是分开操作的。每个机制产生的predication标记加在一起。因此,只有当loop tail predication和VPT predication的条件都为真时,vector操作的一个lane才会处于active状态。
MVE interleaving/de-interleaving loads and stores
对于包含MVE的实现,可以使用VLD2/VLD4和VST2/VST4以步长2/步长4进行interleave和de-interleave处理数据流。Interleaving和de-interleaving指令每次总是对128-bit数据进行操作。
当使用VLD4时,4条VLD4指令中每一条都读取128-bit数据,并部分更新四个目的vector寄存器。要访问的memory地址偏移量和目的寄存器部分安排如下:

