
一次基于真实开源代码的源码级拆解:Hermes Agent v0.11.x(发版时最新v0.14.0,部分功能已优化)与 OpenClaw self-improving-agent v3.0.21(ClawdHub)。
TL;DR
- 真正的"自我进化"不是工具调用、不是上下文学习,而是跨会话的持久化学习------记忆 + 程序性知识两条线一起做才完整。
- Hermes 用"内禀机制":硬编码计数器 + fork 静音子 agent + 自然语言 review prompt + 原子写盘 + 缓存失效,五步闭环全自动。
- OpenClaw 用"外挂 hook":UserPromptSubmit 注入 reminder + 结构化 Markdown 日志 + 量化 Recurrence-Count + 渐进 promote,五步闭环纸上完整。
- 两者共同的最大空白是"质量反馈回路":新版 Hermes 已补上使用频次追踪,但 skill 被使用后任务是成功还是失败,仍无任何机制回写------这是当前所有"自我进化 Agent"共同的最大缺口(详见 §7.1)。
一、引子:一个常见的现象
上周我用某 AI Agent 帮忙在 Aone 上 Debug 一个容器构建失败的问题。问题最终定位到一个非常隐晦的坑:内网构建不能直接 wget github.com,必须走 ghproxy secret 代理。我们一来一回试了七八次,前面调了 retry,调了 DNS,调了 certs,最后才在某条日志里发现是网络出口的限制。
过了两天,另一个仓库出现了类似的问题------同一个 Agent,提示了我同样的错误现象,然后它又走了一遍 retry → DNS → certs 的完整试错路径。完全不记得上次怎么解决的。
这就是无状态 Agent 的困境。这个 Agent 有工具调用、有上下文学习、有联网搜索,看起来什么都不缺;但它没有"经验"。每一次 session 都是它的"第一次"。
那么问题来了:真正能"越用越好"的 Agent,背后的机制究竟是什么?
恰好最近在调研 Agent 框架,把 Hermes Agent 和 OpenClaw 两个仓库的相关代码逐行扒了一遍。两套系统选择了完全不同的工程哲学,但解决的是同一个问题。本文是源码层面的拆解笔记。
二、先搞清楚:什么叫"自我进化"
很多文章把"自我进化"和"工具调用"、"上下文学习"混在一起谈,但它们不是一回事。
| 概念 | 含义 | 例子 |
|---|---|---|
| 自我进化 | Agent 改变自己未来的行为 | 记住"内网构建要走 ghproxy" → 下次直接跳过 retry/DNS 排查 |
| 工具调用 | Agent 使用外部能力 | 调 terminal 执行命令 |
| 上下文学习 | Agent 在当前对话中适应 | 用户说"简短点"→ 本轮简短回答 |
判别标准很简单:关掉这一轮对话,下一轮还在不在? 在,是自我进化;不在,是上下文学习。
所以自我进化 = 跨会话的持久化学习------这是核心。(注:本文的"自我进化"与《Agent 自我迭代机制深度解析》中的"自我迭代"指代同一类机制,下文统一用"自我进化"。)
剩下的所有讨论都围绕这一个定义展开:知识从哪里来?怎么落地?落地后怎么注入下次会话?落地后用得好不好怎么回收?
三、两种实现哲学:从开源代码说起
把上面四个问题一个个回答清楚,就构成了一个完整的"自进化系统"。两个开源代表实现做了完全不同的取舍:
- Hermes Agent:内禀机制,深度集成在 agent 内核(
run_agent.py、prompt_builder.py、skill_manager_tool.py等核心文件)。 - OpenClaw self-improving-agent:外挂 hook 插件(
activator.sh、error-detector.sh、handler.ts),框架无关。
打个比方:Hermes 是一个主动自省的进化型生物------它体内自带"反思中枢",会按节拍强迫自己复盘;OpenClaw 是一个需要被提醒记笔记的勤奋学生------你贴一张便利贴在它显示器上"别忘了写日志",它就乖乖照做。
哪种更好?这要看具体的工程约束。下面拆开看。
四、深度拆解:Hermes 的七层自我迭代体系
先给出全景图。Hermes 不是单一机制,是七个子系统协同工作:
下面挑最关键、最有"工程含量"的四块展开:Skill 自进化闭环(核心)、Memory、Curator、Cron。
4.1 核心:Skill 自进化闭环(5 步)
整个自进化机制的精髓可以用一句话概括:让 Agent 像一个有代码洁癖的工程师一样,一边干活一边整理自己的工具箱。
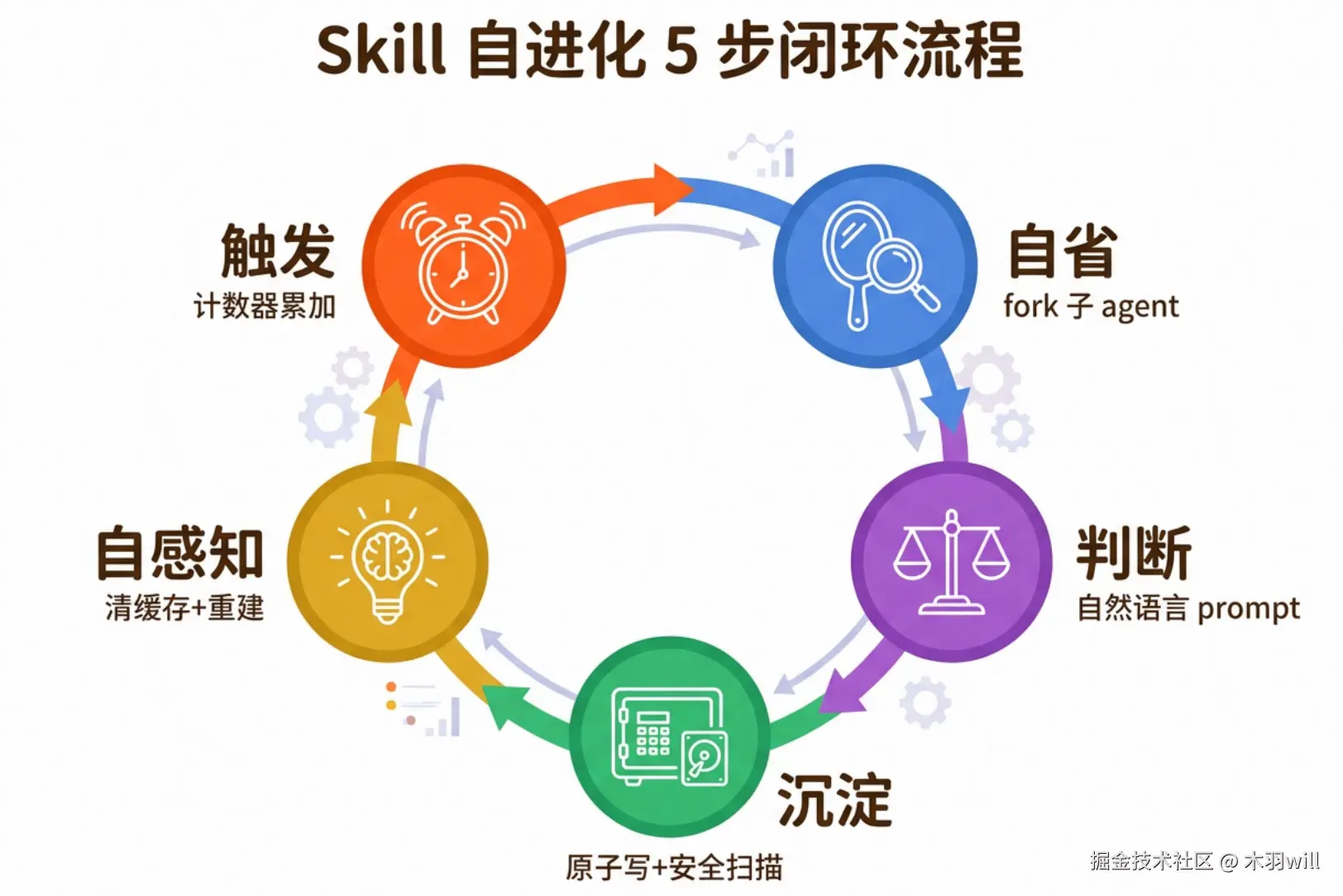
步骤 1 --- 触发:有意识改进 + 无意识积累
Hermes 设计了两条互补的触发路径,本质上对应工程团队里两种完全不同的知识沉淀方式:
- 路径 A:主动触发 --- Agent 在执行中意识到"这值得记下来",直接调用
skill_manage。类似工程师写完一段精彩的 debug 后主动提 PR 到团队 wiki。 - 路径 B:计数器强制触发 --- 每累积 N 次 LLM 推理(默认 10 次)且 turn 结束时,系统自动派一个后台 agent 复盘。类似团队设定的"每两周必须做一次 retro"。
两者的互补逻辑很简单:
if agent 主动调了 skill_manage → 计数器归零,跳过强制复盘
if 计数器攒满且 agent 没主动调过 → 强制复盘兜底阈值设定是个有意思的 trade-off:设太低(比如 3 轮),每次简单问答都触发复盘,浪费算力产出一堆"Nothing to save";设太高(比如 50 轮),真正有价值的模式早被后续对话冲刷掉了。默认 10 是个经验值------大概是"一次有意义的任务的平均思考深度"。
一个值得注意的设计细节:计数单位是 LLM API 调用次数而非 tool calls 数量。一次推理里并行调 5 个工具也只算 1 次。这意味着系统度量的是"思考了几轮"而非"动手做了几步"------毕竟知识沉淀需要的是深度思考,不是机械操作。
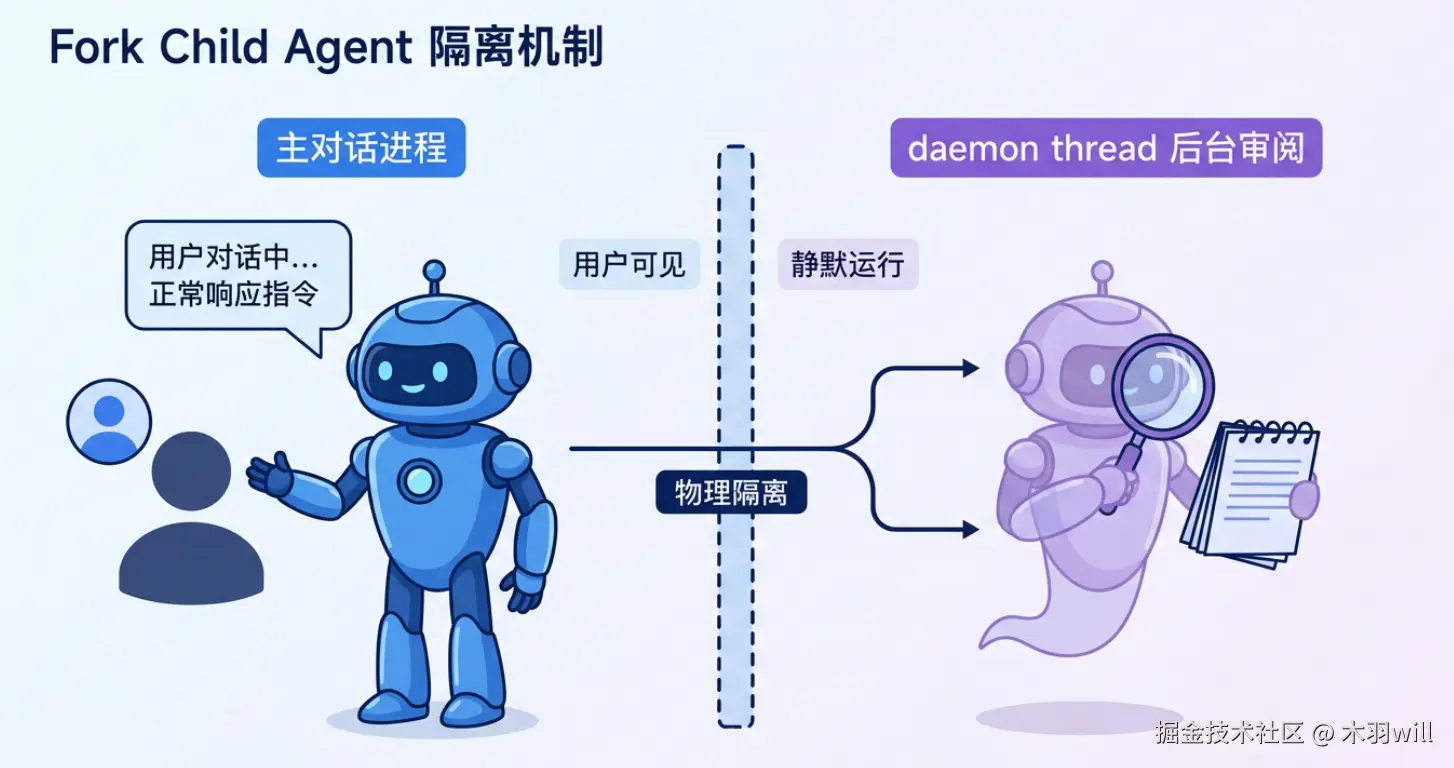
步骤 2 --- 自省:他审而非自审
这一步的核心设计决策是:复盘绝不由主 Agent 自己做。Hermes fork 一个独立子 agent,在后台 daemon thread 里静默完成审阅。
为什么?道理和 code review 一样------你不应该审自己的代码。具体来说有三重工程考量:
- 注意力隔离 --- 主 Agent 刚回完用户,context window 里装满了任务细节。这时候再塞入"你刚才做的值不值得存",会挤掉真正有用的上下文。
- 失败解耦 --- 子 agent 跑在 daemon thread 里(
daemon=True),即使 review 过程崩了,用户侧无感知、主流程不受影响。 - 递归截断 --- 子 agent 直接把
_skill_nudge_interval设为 0,从根源上杜绝"复盘触发复盘"的无限递归。
这个方案本身也经历了进化。早期版本(v0.3.x)用的是 inline nudge------达到阈值后直接在主对话里插一条 system message 催促主 Agent 自省。效果可想而知:主 Agent 被打断、对话历史被污染、用户体验割裂。v0.4.0 起改为 background fork,把"反思过程"与"工作过程"做了物理隔离。自进化机制本身也在进化------这本身就很 meta。
步骤 3 --- 判断:用自然语言代替 if-else
子 agent 醒来后面对完整对话快照,靠什么判断"值不值得沉淀"?Hermes 的答案出人意料:零行规则代码,全靠一段 prompt。
这段 review prompt 的判断维度大致包括:
- 过程中是否使用了 non-trivial 的方法(试错、调整思路、与直觉不符的发现)
- 如果已有同类 skill,是否需要更新
- 如果是新模式且可复用,是否值得新建
- 如果没什么新东西------显式允许说"没什么值得存的"然后停止
最后这条是最妙的设计。它给了 LLM 一个正当的"否决权出口",避免了用 LLM 做判定时最常见的陷阱:模型为了展示自己"有用"而强行生产垃圾输出。
为什么不用 if-else 规则?因为 "non-trivial" 这个判定本质上是语义级的------10 轮 tool call 可能全在反复改 typo(噪声),5 轮也可能藏着一次精彩的 debug 突破(真金)。规则永远追不上上下文的多样性。而改 prompt 不需要改代码、不需要发版,符合"知识可演化"的核心设计目标。
步骤 4 --- 沉淀:先写后验 + 回滚兜底
子 agent 决定写盘后,执行流走的是经典的"write-ahead + safety scan"模式:先把 skill 落盘,再做安全扫描,不过关就整目录回滚。
写入采用原子操作(先写临时文件再 os.replace 原子 rename),确保并发场景下不会出现半写状态。
落盘之后是三层安全决策链:
- 层 1 --- 威胁扫描:结构检查 + 正则模式匹配(100 条威胁模式覆盖数据外泄、注入、破坏性操作等)+ 不可见 unicode 检测,输出 safe / caution / dangerous 判定
- 层 2 --- 来源策略矩阵:根据 skill 来源(builtin / trusted / community / agent-created)× 威胁等级,查表决定 allow / block / ask
- 层 3 --- 行为翻译:把策略决定翻译成实际动作------allow 就保留,其余情况整目录回滚
一个有趣的发现:agent-created × dangerous 对应的策略是 ask(询问用户),但在自进化场景中 agent 是在后台 daemon 里跑的,根本没有用户可以问------这实质上是一段永远走不到的路径。不过作为防御性设计,保留它的合理性在于:万一将来有前台 agent 在用户面前触发 skill_manage,这条路径就活过来了。
为什么扫描必须在写盘之后?因为安全检查需要看整个 skill 目录的最终形态(包括可能新增的脚本、配置文件等),只有完整写出来才能做全面评估。代价是必须有完整的回滚能力------这也解释了为什么原子写是前置硬性要求。
步骤 5 --- 自感知:让新 skill 被 LLM "看见"
写盘成功后,系统清除两层缓存:进程内 LRU cache + 磁盘快照文件。下次 system prompt 重建时,会重新扫描 skills 目录,新 skill 的描述就出现在 <available_skills> 中了。
但这里有个刻意的 trade-off:当前 turn 不会主动刷新 system prompt。原因是 prefix cache------如果每次写 skill 都刷 system prompt,之前缓存的 KV cache 全部失效,要重新走一遍数万 token 的 prefill。所以新 skill 通常要等到下一次 context compression 或下一个 session 才正式生效。这是"即时感知"与"推理效率"之间的务实折中。
文件级 SSOT 带来的隐形红利:所有入口(CLI / WebUI / Cron / Telegram)共用同一个 ~/.hermes/skills/ 目录,周一在 CLI 里积累的 skill,周二用 Telegram 时自动可用,跨 surface 零成本共享。
4.2 Memory 系统:用户画像的持久化
如果说 Skill 是"菜谱"------记录做事的方法论,那 Memory 就是"食客口味"------记录用户是谁、喜欢什么、有什么习惯。两者分工明确,存储路径也物理隔离:
javascript
~/.hermes/memories/
├── MEMORY.md (≤ 2200 字符,Agent 笔记:环境事实、项目约定)
└── USER.md (≤ 1375 字符,用户画像:人设、偏好、工作风格)Memory 的触发和审阅机制与 Skill 高度对称,但在几个关键维度上做了差异化设计:
| 维度 | Memory | Skill |
|---|---|---|
| 计数单位 | 对话轮次(turns) | LLM 推理次数(iterations) |
| 注入方式 | 全文塞进 system prompt | 仅 60 字描述进 prompt,全文按需加载 |
| 粒度 | 一句话级别 | 一篇 Markdown |
| 生效时机 | 下个 session 启动时快照加载 | 下次 prompt 重建时扫描加载 |
这里有个精巧的设计叫 frozen snapshot:Memory 在 session 启动时一次性加载到 system prompt,此后整个 session 内不再变化。写入的新 memory 只影响下一个 session。这既保护了 prefix cache 命中率,又保证了跨 session 的持久化承诺。
为什么 Memory 按 turn 计而 Skill 按 iteration 计?因为两者的知识形态不同:了解一个人靠"聊了多少次"------三轮寒暄可能比五十轮 debug 更能暴露偏好;积累一个方法论靠"思考了多深"------LLM 真正调了多少轮工具、做了多少推理才代表在执行有实质深度的任务。不同的知识类型配不同的度量尺子。
4.3 Curator:系统唯一的负熵机制
自进化系统有个天然问题:skill 只增不减,时间一长就变成垃圾场。Curator 就是 Hermes 对这个"熵增问题"的回应------它是整个系统里唯一在做"减法"的组件。
触发条件:Agent 空闲 + 距上次运行超过设定间隔(默认 7 天)。核心职责四项:
| 职责 | 设计意图 |
|---|---|
| 生命周期迁移 | 长期未用的 skill 标记 stale → archive,降低 prompt 噪声 |
| 同类合并(UMBRELLA-BUILDING) | 多个狭窄 skill 合并为一个更通用的 skill,对抗碎片化 |
| 过时修补 | fork Agent 审阅老 skill,可调 skill_manage(patch) 就地修复 |
| 绝不删除 | 只归档不删除,归档可恢复;被 pin 的 skill 跳过所有自动操作 |
"绝不删除"这条设计原则值得特别说。它体现了一种工程上的克制:自动化系统做加法容错空间大(多一条 skill 最多浪费点 token),做减法的风险却高得多(删错一条可能让用户精心积累的工作流失效)。所以 Curator 选择了最保守的策略------只降级不删除。
每次运行产出完整审计日志(~/.hermes/logs/curator/ 下按时间戳目录存放),确保所有自动化操作可追溯。
版本演进注:v0.11.x 中 Curator 的生命周期判定只能依赖 last_patched_at 等有限时间戳,做纯时间维度的退化决策。新版本(截至本文撰写时的最新代码)已通过 tools/skill_usage.py 补上了 use_count / view_count / last_used_at / last_viewed_at 等完整使用计数,Curator 消费这些数据做 stale→archive 决策------这是一个典型的"框架自身也在迭代"的例子。但即使如此,Curator 仍只有"使用频次/最近一次活动"可用,还没有"使用之后是否成功"这一更高阶的质量信号(详见 7.1)。
4.4 Cron 自迭代:无人值守的渐进完善
Cron 把 Skill 自进化从"被动积累"推到了"主动打磨"------通过反复执行暴露问题,再由 Agent 自主修复:
ini
Cron 触发
↓
构建 job prompt(skill_view 加载关联 Skill 拼入上下文)
↓
创建独立 AIAgent(配备 skill_manage + terminal + read_file 等完整工具链)
↓
执行任务
├─ 成功 → 记录 last_status=success
└─ 失败 → Agent 看到错误上下文 → 自主调 skill_manage(patch) 修复 Skill
↓
下次触发 → skill_view 无缓存重新读盘 → 使用修复后的版本执行
↓
渐进收敛:Skill 在反复执行中越磨越锋利这里的关键设计是 skill_view 每次都从磁盘冷读、不做缓存。这保证了 patch 写入后下次执行立即生效------如果有缓存,patch 和生效之间就会出现不确定的延迟窗口。Cron 提供重复试错的"磨刀石",Skill 提供可演化的"刀",Agent 提供自主修复的"手"------三者构成一个无人值守的渐进收敛环,让 skill 从静态文档变成活的、会自我修复的知识载体。
五、另一种思路:OpenClaw 的轻量 Hook 方案
OpenClaw 的设计哲学是"最小侵入 + 最大可移植"------纯 hook + Markdown 实现,框架无关。整个闭环 5 阶段:
scss
[1] DETECT Hook 注入 <self-improvement-reminder> (activator.sh)
↓
[2] CAPTURE 结构化 Markdown 三文件 (.learnings/)
↓
[3] REVIEW Pattern-Key 去重 + Recurrence-Count 追踪
↓
[4] PROMOTE 达到量化阈值后 → CLAUDE.md / SOUL.md
↓
[5] EXTRACT 提取为独立 Skill (extract-skill.sh)核心机制 1:activator.sh(每次 prompt 注入提醒)
objectivec
# scripts/activator.sh
cat << 'EOF'
<self-improvement-reminder>
After completing this task, evaluate if extractable knowledge emerged:
- Non-obvious solution discovered through investigation?
- Workaround for unexpected behavior?
- Project-specific pattern learned?
- Error required debugging to resolve?
If yes: Log to .learnings/ using the self-improvement skill format.
</self-improvement-reminder>
EOF每次 UserPromptSubmit 注入 ~50-100 token,覆盖率 100%(不像 Hermes 要等 10 轮 iteration 才触发一次)。代价是常驻 token 开销,且 LLM 可能对重复提醒"疲劳"。
核心机制 2:Recurrence-Count 量化门槛
OpenClaw 最值得称道的设计是量化的 promote 决策:
promote 条件:
Recurrence-Count ≥ 3 AND 出现于 ≥ 2 个不同任务 AND 30 天窗口内每个 learning 条目带 Pattern-Key(一个语义指纹),新条目通过 grep Pattern-Key 检查是否已有同类条目;命中则增 Recurrence-Count,未命中新建。这是一个非常工程化的"知识升级"决策依据------不是"看起来重要就 promote",而是"反复出现才 promote"。
核心机制 3:4 层渐进蒸馏
scss
raw learning (.learnings/LEARNINGS.md)
↓ Recurrence ≥ 3
project rule (CLAUDE.md / AGENTS.md)
↓ broadly applicable
workspace rule (.github/copilot-instructions.md)
↓ See Also ≥ 2
skill (independent skill via extract-skill.sh)降低了"一上来就写 skill"的风险。Hermes 是直接从对话写 skill,OpenClaw 在中间加了两层缓冲。
六、两者的互补与对比
| 环节 | Hermes | OpenClaw | 谁更优 |
|---|---|---|---|
| 感知(发现值得记的经验) | 双路径:LLM 自主 + 系统强制 fork | 单路径:Hook 提醒 + LLM 自主 | Hermes |
| 判断(决定是否沉淀) | 独立子 agent 第三方视角 | 主 agent 自审,有偏差风险 | Hermes |
| 沉淀(写入存储) | 原子写 + 3 层安全扫描 + 回滚 | 简单 append,无安全保障 | Hermes |
| 加载(下次使用) | 自动注入 system prompt | 需手动 promote 才进 context | Hermes |
| 反馈(使用效果回路) | v0.11.x 无 → 新版补上 use_count / last_used_at(Curator 消费),但仍缺质量信号 |
Status + Recurrence-Count,但缺成功/失败信号 | 各有一半 |
| 淘汰(清理无用知识) | Curator 时间退化 | Status 流转 + Recurrence | OpenClaw |
| 跨平台 | 文件 SSOT,CLI/cron/WebUI 共享 | 项目局部 .learnings/ |
各有所长 |
| 框架耦合 | 深耦合 Hermes 内核 | 零耦合,纯 hook | OpenClaw |
核心矛盾:
- Hermes 是"产出强、治理弱":感知 → 沉淀 → 加载 全自动,工程上极其健壮(fork 隔离 + 安全扫描 + 原子写);但治理链路(追踪 → 淘汰 → 去重 → 合并)只有 Curator 一个有限的兜底。
- OpenClaw 是"规则清晰、执行力弱":Status 流转 / Pattern-Key / Recurrence-Count / Promote 路由设计得非常完善;但没有任何代码强制执行这些制度。Promote 条件只是写在 SKILL.md 里的自然语言指令,没有脚本定期扫描
.learnings/检查哪些条目达到阈值。
一个像"写进化机器",一个像"制度齐全但无人督查"。
七、真实缺陷:不要被优雅的设计掩盖
读源码的一个收获是:知道哪些是设计漂亮的实现,也知道哪些是设计漂亮但实际跑不到的死代码。下面是基于 grep / 缺失证据找出的三个最关键断点。
7.1 质量反馈缺失(Hermes 最大盲区)
版本演进注:v0.11.x 中此处确实是完整的断环------没有任何使用追踪模块,Curator 只能基于时间做退化(原始分析正确)。新版本已通过 tools/skill_usage.py 模块(约 610 行)补上了使用计数追踪,Curator 消费这些数据做 stale→archive 决策。这是"做自我进化的框架,自身也在迭代进化"的一个典型例证。但即使新版也仍然缺少质量信号------这才是真正的断点所在。
新版本的 tools/skill_usage.py 实现了完整的使用计数:
python
# tools/skill_usage.py:304-317 每条 skill 的使用记录(新版本新增)
def _empty_record() -> Dict[str, Any]:
return {
"created_by": None,
"use_count": 0,
"view_count": 0,
"last_used_at": None,
"last_viewed_at": None,
"patch_count": 0,
"last_patched_at": None,
"created_at": _now_iso(),
"state": STATE_ACTIVE,
"pinned": False,
"archived_at": None,
}这些计数器在以下位置被主动维护:
skill_view工具每次调用都会先后触发bump_view()+bump_use()(tools/skills_tool.py:1549-1554);skill_manage(patch)触发bump_patch()(tools/skill_manager_tool.py:778-784);- Cron 在
_build_job_prompt加载关联 skill 时调用bump_use()(cron/scheduler.py:956-970); - 计数与时间戳通过 fcntl 文件锁 + 临时文件 +
os.replace原子写入~/.hermes/skills/.usage.json,并发安全。
新版本的 Curator 也确实在消费这些数据------agent/curator.py 调用 skill_usage.agent_created_report(),按 last_activity_at(即 last_used_at / last_viewed_at / last_patched_at 三者中的最新值)判断 stale → archive 转移:
ini
# agent/curator.py:264-278(节选)
stale_cutoff = now - timedelta(days=get_stale_after_days())
archive_cutoff = now - timedelta(days=get_archive_after_days())
last_activity = _parse_iso(row.get("last_activity_at"))
anchor = last_activity or _parse_iso(row.get("created_at")) or now所以"使用计数"这一环新版本已经闭合(v0.11.x 没有,Hermes 团队意识到断点后主动修补)。真正的断点不在这里。
真正的断点是"质量反馈"------新旧版本一样缺:skill 被 view / use 之后,主 agent 用它去做任务------任务最终是成功还是失败?这条信号没有任何机制回写到 skill 元数据。系统记下了"这条 skill 被看了 5 次、用了 3 次",但记不下"这 3 次里有 2 次任务失败了"。
Grep 验证(在整个 main/hermes-agent-main/ 仓库中搜索质量信号关键词):
success_rate------ 仅在trajectory_compressor.py中出现,是"轨迹压缩成功率",与 skill 无关;task_outcome------ 零命中;skill_effectiveness------ 零命中;skill_usage.py的 record schema(上方代码)里没有任何success_count/failure_count/last_outcome字段;- Curator 的判定也只用时间窗口(
stale_after_days/archive_after_days),没有任何基于成功率的淘汰路径。
含义:
- 烂 skill 只要还在被打开看,就永远不会被识别为烂------它不"过期",但它"误事"。
- Curator 的 stale → archive 是"长期没人看就归档",不是"经常被用但经常导致失败就归档"。
- review prompt 让子 agent "判断是否已有相关 skill",子 agent 现在能拿到的最强信号是
last_used_at,但拿不到"用了之后效果如何"。
这是 Hermes 当前最值得继续往前推的一公里。自进化机制已经闭合到"写"和"用频次",但没有闭合到"用得对不对"------使用计数有了,使用效果评估还没有。
7.2 执行力缺失(OpenClaw 最大盲区)
断点:Recurrence-Count ≥ 3 + 2 个任务 + 30 天的 promote 条件,没有任何代码强制执行。
Grep 验证:
- 整个 OpenClaw self-improving-agent 仓库没有一个定时任务/cron/scheduler扫描
.learnings/检查哪些条目达到阈值; - Recurrence-Count 字段在条目里,但没有任何代码做计数器维护------全靠 LLM 在 review 时自己 grep + 手动 +1;
- Promote 路由(CLAUDE.md / AGENTS.md / SOUL.md)也是 SKILL.md 里的指令,LLM 决定是否执行。
含义:好制度,但完全靠 LLM 的"自觉"维持------和 Hermes 用硬编码计数器强制触发 review 形成鲜明对比。设计上漂亮,工程上脆弱。
7.3 ask 决策被静默吞掉(Hermes 策略矩阵的死代码)
断点:INSTALL_POLICY["agent-created"][2] = "ask" 设计意图是 dangerous 时让用户决策;但代码里 allowed is None 被直接当 False 处理,悄悄回滚。
代码出处对照:
vbnet
# tools/skills_guard.py:642 策略矩阵
INSTALL_POLICY = {
"agent-created": ("allow", "allow", "ask"), # 第 3 格本意是"问用户"
}
# tools/skill_manager_tool.py:64-71 manager 层包装
# allowed is True → 返回 None (放行)
# allowed is False → 返回 error string (回滚)
# allowed is None → 也返回 error string ← 这里!本应"问用户",被当成 False实际行为:agent-created × dangerous = silent block。
- LLM 收到
{"success": False},以为 skill 没过安检; - 用户屏幕上什么都不显示,根本不知道有过一次"ask 机会";
- 矩阵里专门为 agent-created 设计的第 3 格
ask,在自进化路径上永远走不到。
这是非常典型的"策略矩阵和 manager 实现存在断层"的死代码------设计文档完全没问题,代码却悄悄把 ask 退化成了 block。只有把矩阵和实现两边都读一遍才能发现这个坑。
7.4 其他次要缺陷(一笔带过)
- 频次硬阈值(
run_agent.py:1404 + 11627):_skill_nudge_interval = 10是常量,不区分任务类型,不学习用户偏好。长任务(20 轮)会触发两次 review 可能存出两条相似 skill;短任务(5 轮)永远不触发。 - 相关性发现成本高(
tools/skill_manager_tool.py:325):_find_skill只按 name 精确查,没有 fuzzy / embedding / tag 倒排。子 agent 的 8 轮预算一半得花在 skill 发现上,更倾向 "create new" 而非 "update existing"。 - review 是 best-effort(
run_agent.py:11652-11653):except Exception: pass吞掉所有异常,失败的 review 不留痕迹也不重试。网络抖动一次本可沉淀的经验就消失了。
八、对我们的启发:如何设计一个"真正会进化"的 Agent
把上面的分析提炼成几条可操作的设计原则:
- 感知必须有保底机制------不能只靠 LLM 自觉。Hermes 双路径 + 计数器是被验证过的工程实践,OpenClaw 的"全靠 LLM 记住"在实际跑起来后会出问题。
- 自省要隔离,不要污染主对话------fork 子 agent 是正确的工程选择。它解决了注意力争抢、context 污染、递归风险、失败隔离四个问题。这条经验从 Hermes 的 inline nudge → background review (PR #2235) 演化路径里能直接读出来。
- 沉淀要原子性 + 安全扫描------LLM 写文件是高风险操作(注入、prompt injection、逃逸路径)。原子写不是可选项,是必须项。
- "质量反馈"是最难的,也是最重要的------使用计数这一层 Hermes 新版本已经补上(
tools/skill_usage.py的use_count/last_used_at+ Curator 消费,v0.11.x 中尚无),正是框架自身迭代进化的体现。真正还没人解决好的是质量信号回写:skill 被使用之后,关联任务的最终结果(成功 / 失败 / 用户是否回头修改了 skill)没有任何机制写回到元数据。补上这一环------比如给 turn 结束加一个success/failure信号、给 cron job 完成时把last_outcome写回引用过的 skill------改动其实不大,但能让所有下游治理决策(基于成功率的淘汰、合并、冲突检测)真正有数据可用。 - 治理与产出要同步建设------只建产出通道(Hermes 早期)或只建治理制度(OpenClaw)都不够。知识库最终会腐化或瘫痪。
如果要从零设计一个理想的"Agent 自进化系统",理想管道设计大概是:
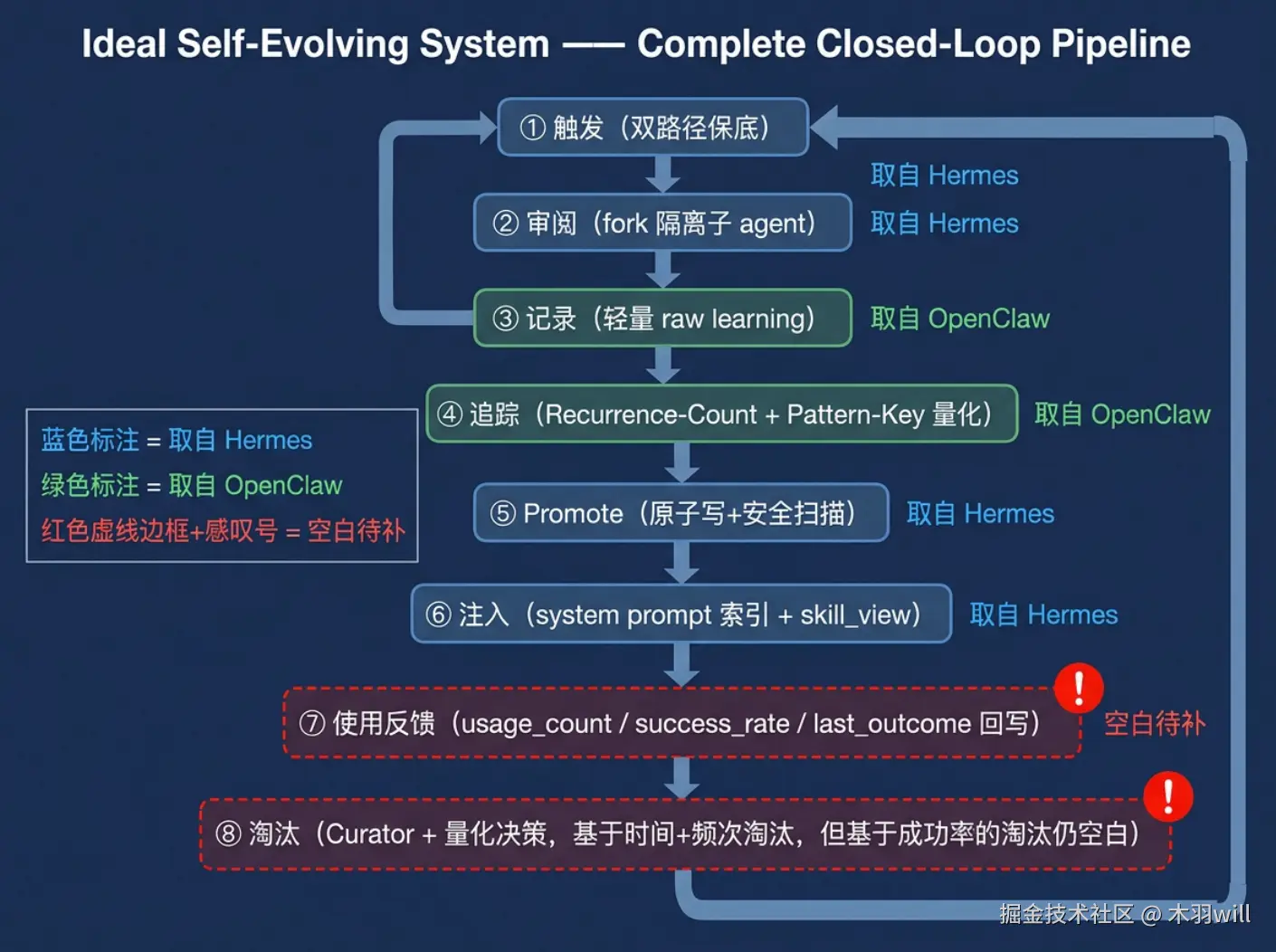
九、小结
不存在"完美的自我进化方案"。Hermes 和 OpenClaw 不是替代关系,是互补关系------Hermes 解决"怎么自动产出知识",OpenClaw 解决"怎么管理知识质量"。
但更重要的,是从源码分析里提炼出的Agent 自我进化的设计模式:
- 双路径触发(主动 + 保底)解决"LLM 会忘"
- fork 隔离解决"自省污染主对话"
- 自然语言判定解决"什么值得沉淀是终极语义判断"
- 原子写 + 安全扫描解决"LLM 写文件高风险"
- 缓存失效中继解决"写完到生效的传导"
- 量化阈值 + 渐进蒸馏解决"垃圾知识进库"
- 使用计数回写------v0.11.x 还没有,但新版 Hermes 已补上(
skill_usage.py的use_count/last_used_at+ Curator 消费)------框架自身也在进化 - 质量信号回写------使用之后效果好不好(任务成功 / 失败)这一条新旧版本都没解决,是下一站
回到开头那个被同一个坑卡住两次的 Agent。它缺的不是更好的模型、不是更多的工具,是一套能让"踩过的坑"留下来的机制。这套机制不是玄学,是可以从源码里一行一行读出来、再一行一行写出来的工程实践。
最后一个值得品味的发现:我们在 v0.11.x 分析中指出的"使用反馈断环",Hermes 团队在后续版本中确实补上了(tools/skill_usage.py)。这本身就验证了文章的核心论点------真正好的自我进化系统,连自身的缺陷也会被识别并修补。 做自我进化的框架,自身也在迭代进化。而"质量信号"这个仍然空白的环节,或许就是下一次迭代的目标。
Agent 不是工具,是一个会自我学习的程序生物------前提是我们真的把这套机制做完整。