公司正在持续深化 AI 在研发流程中的使用,其中一个很重要的方向,是在需求阶段使用 AI 生成原型,逐步替代过去通过 Axure、墨刀等工具手工拖拽页面的方式。
这个方向的价值很明确:需求人员只要描述业务场景、页面字段和交互规则,AI 就可以快速生成可评审的原型页面,大幅降低原型制作成本,也能让需求沟通更快进入具体页面和流程。
但真正落地后会发现,如果不对 AI 加约束,生成出来的原型往往五花八门,几乎不可直接使用。有的页面像后台系统,有的像官网落地页;同样的按钮、表格、弹窗,在不同页面里的样式和结构也不一致。更麻烦的是,当用户提供截图或旧系统页面作为参考时,AI 很容易把截图里的颜色、圆角、阴影和布局都照搬过来,导致页面偏离项目既定规范。
为了解决这个问题,我研发了一个 zhp-html-prototype skill。它的目标不是让 AI "自由发挥得更好",而是让 AI 在明确的原型规范、目录结构和校验机制下,稳定生成可用于需求评审和方案沟通的静态 HTML 原型。
一、为什么要做这个 Skill
原型页面生成看起来是一个简单任务:给 AI 一段业务描述,让它生成一个 HTML 文件即可。
但在实际研发、评审和沟通场景里,我们需要的不只是"能打开的页面",而是可持续维护、风格一致、便于多人协作的原型体系。
我最初遇到的问题主要有几类:
-
页面风格不稳定
同样是后台管理页面,不同 AI 会话生成出来的视觉风格、间距、字号、按钮样式和表格结构差异很大。单页看可能还可以,但多个页面放在一起就会显得割裂。
-
原型文件结构混乱
如果没有约束,AI 可能把 HTML、CSS、JS 随意写在不同位置。后续新增页面、修改菜单、维护入口页时,成本会越来越高。
-
截图参考容易带偏
业务方经常会提供截图、旧系统页面或其他产品页面作为参考。AI 默认倾向于"复刻视觉",但我们真正需要的是提取业务信息,例如字段、筛选条件、表格列、按钮、状态和流程,而不是复制对方的视觉风格。
-
缺少完成后的校验机制
页面生成完成后,资源引用是否正确、入口页是否更新、菜单是否同步、浏览器能否正常打开,这些都需要检查。只靠提示词提醒,稳定性并不高。
所以,这个 skill 的核心目标可以概括为一句话:
让 AI 按团队约定的原型体系生成页面,而不是每次重新发明一套页面风格。
二、Skill 的定位
zhp-html-prototype 是一个用于生成静态 HTML 原型的 skill,主要服务于需求评审、方案沟通、草稿确认等阶段。
它支持根据以下输入生成原型页面:
- 业务描述
- 字段清单
- 页面功能说明
- 截图
- 已有页面代码
- 外部页面参考
生成结果会落在统一的 prototypes/ 目录中,并复用内置的模板、公共 CSS、设计令牌和共享菜单。
一个典型的生成结果大致如下:
text
prototypes/
├── assets/
│ ├── design-tokens.json
│ └── prototype.css
├── index.html
├── grid-model-archives.html
└── shared/
├── app-shell.js
└── menu-config.js这个结构看起来不复杂,但它解决了一个关键问题:原型不再是零散文件,而是一个可以持续扩展的小型静态站点。
三、设计思路:把"偏好"沉淀到 Skill 里
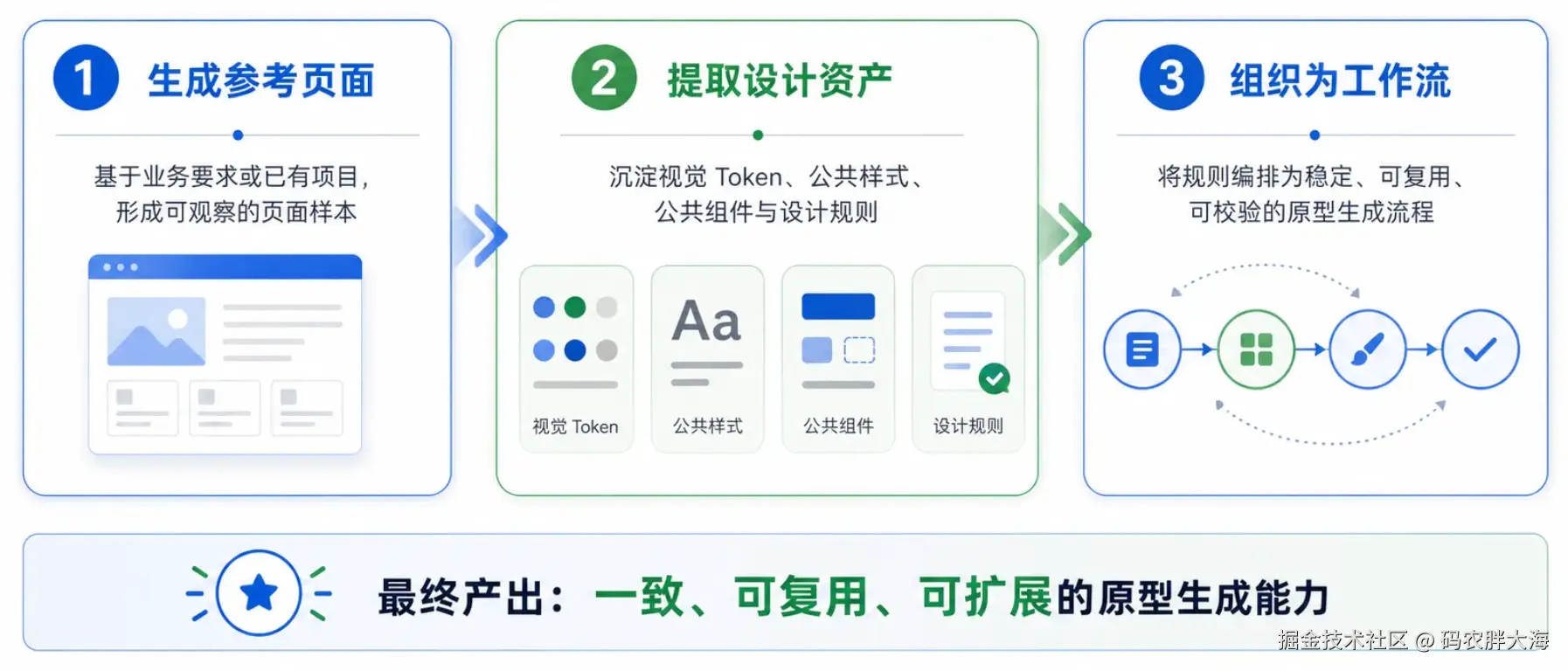
写这个 skill 时,我没有把它设计成一个巨大的提示词集合,而是把它拆成几类稳定资产。
1. 工作流入口:SKILL.md
SKILL.md 负责告诉 AI:
- 什么时候应该触发这个 skill
- 生成原型时应该遵循什么流程
- 哪些资源需要读取
- 完成后需要做哪些检查
这里最重要的经验是:description 字段应该写给模型看,而不是写给人看。
也就是说,它不应该只是"这是一个生成 HTML 原型的工具"这种功能说明,而应该包含触发条件,例如"生成原型页面""静态页面""根据业务描述生成页面""维护原型目录"等。这样模型在用户提出相关任务时,才能更稳定地自动使用这个 skill。
2. 设计令牌:design-tokens.json
为了避免 AI 每次自己决定颜色、字体、间距和圆角,我把这些基础规范沉淀成 design-tokens.json。
它承担的是"设计约束"的角色。AI 在生成页面时,不需要重新判断主色是什么、边框半径是多少、内容区间距多大,而是直接复用已有 token。
这一步的价值非常明显:页面生成的随机性会明显下降。
3. 公共样式:prototype.css
prototype.css 封装了页面骨架、布局、表单、表格、按钮、弹窗、状态标签等公共样式。
对 AI 来说,最容易失控的地方往往不是业务内容,而是 UI 细节。公共样式的作用就是把这部分"容易飘"的内容固定下来。
这样,AI 的主要任务就从"设计一个页面"变成了"用现有组件结构组织业务信息"。
4. 页面模板:template.html
模板负责提供业务页面的基本 HTML 骨架。新增页面时,AI 不需要从零开始写结构,而是在模板基础上填充页面标题、查询区、操作区、表格、弹窗和脚本逻辑。
模板的意义不是减少几行代码,而是保证页面结构稳定。
5. 共享外壳与菜单配置
原型页面通常不是单页使用,而是多个页面一起评审。为此,skill 内置了共享外壳和菜单配置:
app-shell-template.jsmenu-config-template.jsindex.html
每新增一个页面,AI 需要同步维护菜单和入口页,确保用户可以从统一入口访问所有原型。
这让原型从"一堆 HTML 文件"变成了"可浏览的原型集合"。
6. 校验脚本:validate_prototype.py
最后,我把一些稳定、明确、可自动化的检查封装成脚本。
例如:
prototypes/目录结构是否存在- 公共资源是否齐全
- 页面资源引用是否正确
- 菜单配置是否可用
- 入口页是否同步
这体现了一个很重要的原则:能用代码检查的事情,不要只写在提示词里。
提示词可以指导 AI,但脚本可以给出确定性反馈。对于 skill 来说,脚本比更多文字说明更可靠。
四、处理截图参考:只提取业务信息,不复刻视觉
这个 skill 里我特别强调了一条规则:当用户提供截图或外部页面时,AI 应该先提取业务信息,再使用项目统一模板和样式生成页面。
也就是说,截图可以作为信息源,但不能作为视觉规范源。
从截图中可以提取:
- 页面模块
- 查询条件
- 表格字段
- 按钮和操作
- 状态枚举
- 弹窗字段
- 业务流程
- 页面层级关系
但不应该直接照搬:
- 颜色
- 字体
- 圆角
- 阴影
- 间距
- 布局风格
这个规则解决了一个非常实际的问题:业务方给参考图只是为了表达功能,并不意味着我们要复制参考图的设计体系。
如果不在 skill 里显式约束,AI 很容易误解这一点。
五、从"提示词"到"工程化资产"
这个 skill 的研发过程让我更清楚地认识到:skill 的价值不在于写一大段万能提示词,而在于把团队的上下文、偏好和可复用能力工程化。
我总结了几条编写原则。
1. Skill 应该补充模型默认不知道的东西
通用的 HTML、CSS、JavaScript 写法,模型本来就知道,不需要在 skill 里重复解释。
真正应该写进 skill 的,是团队自己的规则:
- 原型目录应该放在哪里
- 页面应该长什么样
- 菜单如何维护
- 截图参考如何处理
- 完成后如何校验
- 哪些风格不能使用
这些才是模型默认不知道、但对交付质量影响很大的信息。
2. 约束目标,而不是写死路径
如果把 skill 写成非常死板的步骤清单,AI 在遇到稍微不同的任务时就容易卡住。
更好的方式是约束目标和边界:
- 页面必须复用公共样式
- 新增页面必须同步菜单
- 截图只用于提取业务信息
- 完成后必须运行校验
至于具体如何组织某个页面、弹窗字段怎么排布、交互脚本如何写,可以保留一定灵活性。
3. 稳定能力要沉淀成脚本
校验、初始化、复制模板、同步目录这类事情,如果只靠 AI 每次手工执行,很难保证稳定。
因此,我更倾向于把稳定能力封装成脚本和模板,让 skill 负责组织流程,让脚本负责确定性操作。
这也是我认为 skill 和普通提示词最大的差异之一。
4. 遵循渐进披露
skill 不应该在一开始就把所有文档全部塞给模型。
更合理的做法是:
SKILL.md只保留核心流程- 布局规则放到
references/layouts.md - 交互模式放到
references/interactions.md - 初始化步骤放到
references/prototype-init.md - 视觉参考页面放到
prototype-component-demo.html
模型在需要时再读取对应资料,这样可以减少上下文浪费,也能降低 token 消耗。
六、如何定制这个 Skill
各项目的页面风格不同,所以这个 skill 也预留了定制方式。
最简单的方式是在项目根目录添加 AGENTS.md 或 CLAUDE.md,覆盖局部规则。例如:
md
# Project Rules
- 新生成的原型页面放置在 `prototypes/second-version` 目录下。如果需要更深层的定制,可以直接修改 skill 文件本身。
比如要把整体风格改成 Ant Design 风格,可以先让 AI 重新生成公共控件参考页:
text
修改 prototype-component-demo.html 为 Ant Design 风格然后再让 AI 根据参考页面更新公共样式和规则:
text
根据 prototype-component-demo.html,修改公共样式及相关规则文件这个过程本质上是在重建一套项目级原型设计系统。
七、一次典型使用流程
使用时,用户可以直接提出页面需求:
text
新建一个"采集终端管理"原型页面。
页面包含:
1. 查询条件:终端编号、终端名称、所属区域、在线状态。
2. 表格列:终端编号、终端名称、通信地址、所属区域、在线状态、最后在线时间、操作。
3. 操作:新增、编辑、删除、查看详情、启用、停用。
4. 弹窗:新增和编辑终端信息。AI 触发 skill 后,会完成以下工作:
- 检查并初始化
prototypes/目录 - 复制或复用公共样式、设计令牌和共享脚本
- 基于模板生成业务页面
- 补齐查询区、表格、操作按钮和弹窗
- 更新菜单配置和入口页
- 运行校验脚本
- 提示用户打开 HTML 页面查看效果
这套流程跑通后,后续新增页面的成本会明显降低。更重要的是,生成结果会保持在同一套规范里。
八、后续规划
当前版本主要解决的是静态 HTML 原型生成问题。后续我计划从三个方向继续扩展。
第一是支持更多外观风格。
例如不同项目主题、不同产品线视觉规范、不同终端形态的页面风格等。不同项目可以在初次使用时选择风格,并记录到配置文件中。
第二是支持更多业务场景。
目前主要面向后台管理类页面,后续可以扩展到数据大屏、移动端 H5、流程配置页面等。
第三是支持更多技术栈。
静态 HTML 适合快速评审,但在某些场景下,团队可能希望直接生成 Vue、uni-app 或其他前端技术栈代码。后续可以在 skill 中加入技术栈选择,让原型从"可看"进一步走向"可复用"。
九、总结
这次实践给我最大的启发是:AI 生成能力本身已经足够强,但如果缺少上下文和约束,它就很容易变成一次性的自由创作。
而 skill 的价值,是把团队经验、项目规范、目录结构、视觉偏好和校验机制沉淀下来,让 AI 在一个稳定的边界内工作。
对于原型页面生成这个场景来说,真正重要的不是让 AI 写出某一个漂亮页面,而是让它持续、稳定、低成本地生成一组风格一致、结构清晰、便于评审和维护的原型页面。
这也是我研发 zhp-html-prototype skill 的核心目标:让 AI 从"会写页面",进化到"按规范交付原型"。