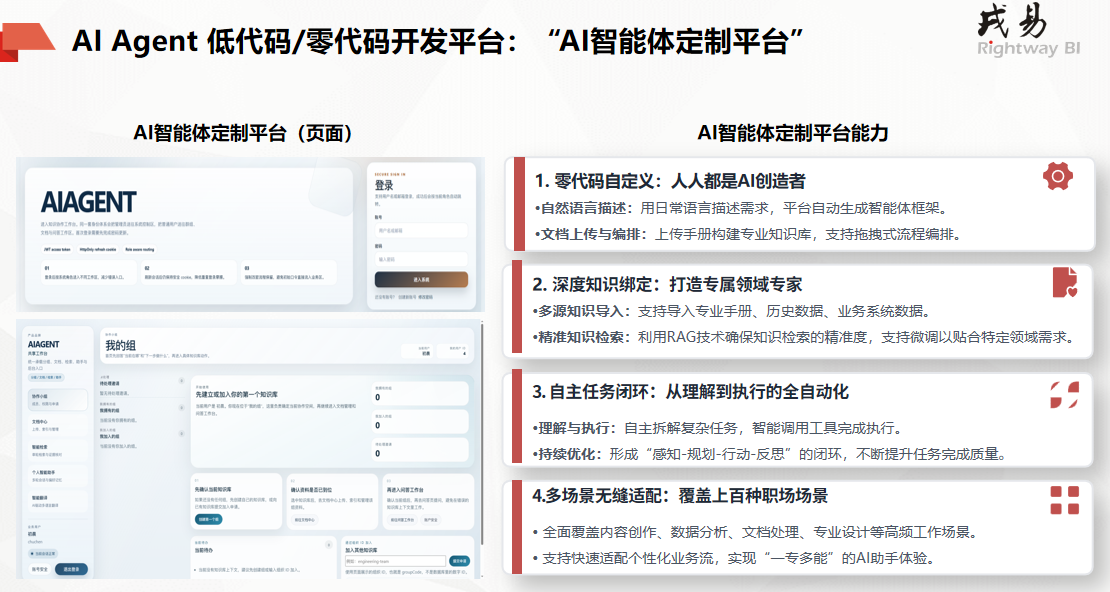
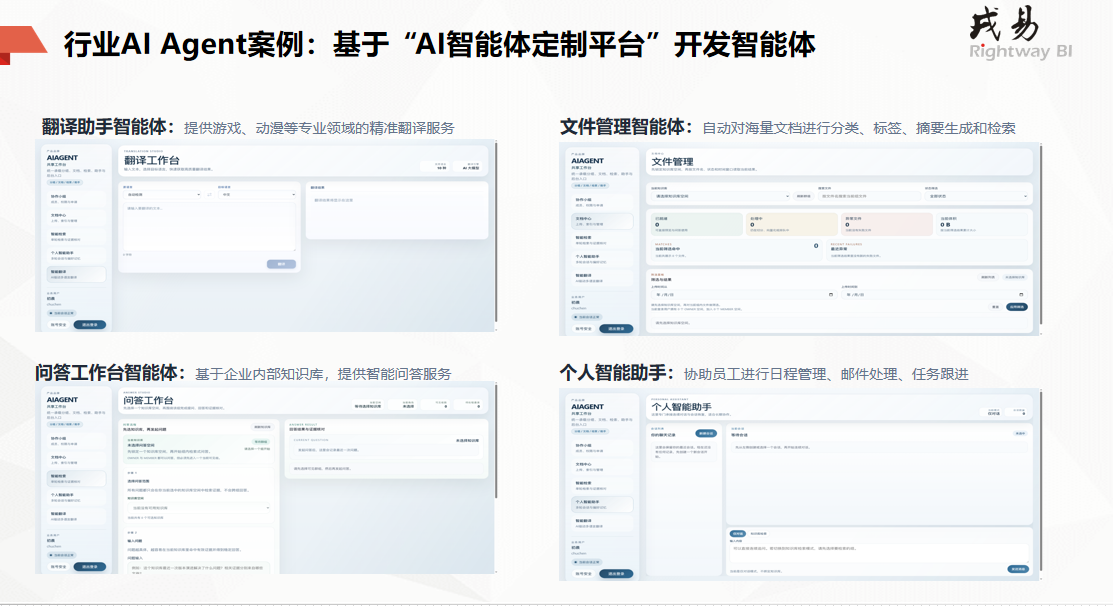
大模型本地化+RAG深度融合:原理、架构与落地实战全解析摘要 :随着大模型行业落地进入深水区,公有云大模型的隐私泄露、网络延迟、定制性差等问题愈发凸显,模型本地化部署成为企业私有化AI落地的核心趋势。但纯本地模型存在知识固化、幻觉严重、领域适配性弱等痛点,而RAG(检索增强生成)技术可完美弥补其短板。本文将深度拆解模型本地化核心理论、RAG技术底层原理,重点剖析二者融合的技术架构、核心优势、落地流程及性能优化方案,帮助开发者快速掌握企业级本地化RAG系统的搭建逻辑与实战要点。
关键词:大模型本地化;RAG;检索增强生成;私有化部署;向量数据库;AI工程化
一、前言:为什么本地化RAG成为企业刚需?
当前大模型应用分为两大流派:云端API调用、本地私有化部署。
云端大模型(GPT、文心一言、通义千问等)开箱即用、能力强大,但在企业落地中存在三大致命问题:
-
数据安全风险:企业内部文档、业务数据需外传调用,极易引发核心数据泄露,无法满足金融、政务、制造等行业的合规要求;
-
使用成本高昂:高并发场景下API调用费用持续累加,长期落地成本远超本地化部署;
-
场景适配性差:模型知识固化于训练数据集,存在知识截止日期,无法适配企业实时业务数据、私有领域知识。
而纯本地化大模型虽解决了数据安全和成本问题,但仍存在核心短板:模型参数固定、无动态知识更新能力、幻觉问题突出、领域问答准确率低。
在此背景下,模型本地化+RAG的融合方案成为企业私有化AI落地的最优解:既保留本地化部署的安全可控、低延迟优势,又通过检索增强技术解决本地模型知识滞后、幻觉频发的痛点,是当前工业界落地率最高的AI应用架构(2026年企业级LLM应用RAG架构渗透率超60%)。
二、核心理论一:大模型本地化部署核心原理
2.1 模型本地化核心定义
大模型本地化是指将开源大模型(Llama、Qwen、ChatGLM、Mistral等)部署在本地服务器、边缘设备或企业私有集群,脱离公网API依赖,实现模型推理、数据处理、业务交互全流程私有化的部署模式。其核心本质是模型权重本地化、推理计算本地化、数据存储本地化。
2.2 本地化核心技术支撑
原生大模型参数庞大、推理算力要求高,无法直接轻量化部署,本地化落地依赖四大核心技术:
-
模型量化技术:通过INT8、INT4、GGUF等量化方式,压缩模型权重体积,降低显存占用,在几乎无损推理效果的前提下,实现端侧、服务器级轻量化部署,是本地模型落地的基础;
-
模型裁剪与蒸馏:裁剪模型冗余参数层,通过大模型蒸馏得到轻量子模型,适配本地算力环境,平衡推理速度与效果;
-
本地推理引擎优化:基于Ollama、llama.cpp、TensorRT等推理框架,优化本地推理调度、显存分配,大幅提升低算力设备的推理速度;
-
私有资源调度:依托企业私有集群、本地GPU算力池,实现模型常驻服务、高并发本地推理,摆脱公网网络限制。
2.3 纯本地化模型的固有痛点
即便经过量化优化,纯本地模型仍无法规避底层缺陷,这也是RAG技术的核心价值所在:
-
知识固化不可逆:模型知识完全锁定在训练权重中,无法自主学习新增业务知识,更新知识需重新微调、部署,成本极高;
-
幻觉问题严重:本地轻量模型参数规模有限,逻辑推理、事实甄别能力弱,易生成虚假、错误的领域信息;
-
领域适配性不足:通用预训练模型无法适配企业细分领域的专业术语、业务流程、私有文档数据。
三、核心理论二:RAG检索增强生成核心机制
3.1 RAG核心定义与核心思想
RAG(Retrieval Augmented Generation,检索增强生成)是一种检索与生成协同的增强式AI架构,核心思想是打破大模型"闭卷答题"的局限,让模型实现"开卷考试"。在模型生成答案前,先从外部私有知识库检索相关事实文本,将检索结果与用户问题拼接,输入模型完成生成,全程无需修改模型权重。
相较于传统微调,RAG无需海量训练数据、无需重新训练模型,具备低成本、可迭代、高可控、零幻觉的核心优势,是动态知识更新的最优工程方案。
3.2 RAG标准双阶段工作流程
完整RAG系统分为离线索引构建 和在线推理生成两大阶段,形成闭环知识服务链路:
阶段1:离线索引构建(一次性构建、可迭代更新)
针对企业私有PDF、Word、数据库、网页文档等原始数据,完成知识库初始化:
-
数据清洗:过滤无效字符、重复内容、格式冗余信息,标准化数据源;
-
智能分块(Chunk):将长文本切割为适配模型上下文窗口的文本块,避免上下文溢出,提升检索精度;
-
向量化处理:通过本地Embedding嵌入模型,将文本块转化为高维语义向量;
-
向量入库:将向量与原始文本对应存储至向量数据库(FAISS、Chroma、Milvus),构建语义索引。
阶段2:在线推理生成(实时响应用户请求)
-
Query向量化:将用户输入的问题通过Embedding模型转为语义向量;
-
语义检索:在向量数据库中匹配相似度最高的文本片段,完成初步召回;
-
重排序优化:通过Rerank模型过滤无效、低相关片段,提纯检索上下文;
-
提示词拼接:将用户问题与提纯后的上下文知识整合为结构化Prompt;
-
模型生成:输入本地大模型,依托外部真实知识生成精准、无幻觉的答案。
四、本地化模型+RAG融合架构:核心优势与整体设计
4.1 融合架构核心优势
模型本地化与RAG属于互补性技术,二者融合可彻底解决纯本地模型、纯云端模型的所有核心痛点:
-
极致安全合规:所有数据、模型、计算均在本地完成,无公网数据传输,完全满足企业数据合规要求;
-
动态知识迭代:无需微调模型,仅更新向量知识库即可实现知识更新,适配企业实时业务变更;
-
彻底弱化幻觉:模型基于检索的真实私有数据生成答案,杜绝凭空捏造内容,大幅提升答案可信度;
-
低成本高可用:规避云端API高额调用成本,本地推理低延迟、高并发,适配企业常态化业务场景;
-
强领域适配性:可精准对接企业私有文档、行业规范、业务流程,实现专属领域智能问答。
4.2 端到端融合架构设计
整套本地化RAG系统分为五层架构,层层解耦、可独立优化,适配工程化落地:
-
数据层:企业私有文档、业务数据库、行业标准、实时业务数据等原始数据源;
-
知识库构建层:完成数据清洗、智能分块、Embedding向量化、向量索引存储,支持知识库增量更新;
-
检索增强层:包含语义检索、关键词检索、Rerank重排序、上下文过滤,保障检索精准度;
-
本地模型推理层:量化部署开源大模型、本地Embedding模型、Rerank模型,依托本地推理引擎优化推理效率;
-
业务服务层:提供API接口、前端交互页面,对接企业业务系统,实现智能问答、文档解析、知识库问答等业务功能。
五、工程化落地:本地化RAG系统实战流程
结合理论原理,整理一套可直接落地的企业级本地化RAG搭建流程,适配中小算力服务器,新手可快速复刻:
5.1 环境与模型选型
-
本地模型:选用Qwen-7B-Chat、ChatGLM3-6B、Mistral-7B等轻量化开源模型,采用INT4量化,兼顾速度与精度;
-
Embedding模型:本地部署bge-small-zh、text2vec-base,保障中文语义检索精度;
-
向量数据库:轻量场景用Chroma/FAISS,企业高并发场景用Milvus/Pinecone本地部署;
-
开发框架:LangChain/LlamaIndex,快速实现RAG链路封装与调度;
-
推理引擎:Ollama,极简实现本地模型部署、调用、负载调度。
5.2 核心落地步骤
-
本地模型部署:通过Ollama拉取量化模型权重,配置本地GPU/CPU推理环境,测试本地单轮、多轮对话推理可用性;
-
私有数据预处理:批量读取企业文档,清洗无效数据,设置512-1024字符分块长度,保留文本语义完整性;
-
本地向量知识库构建:调用本地Embedding模型完成文本向量化,存入向量数据库,构建索引,支持增量添加新文档;
-
检索链路优化:开启语义+关键词混合检索,搭配Rerank模型重排序,过滤冗余、不相关片段,提升检索准确率;
-
Prompt工程适配:设计专属RAG提示词,约束模型仅基于检索上下文作答,无匹配知识时如实回复,杜绝幻觉;
-
服务封装与测试:封装本地API接口,进行问答精度、推理延迟、并发压力测试,完成参数调优后上线。
六、本地化RAG完整实战代码=
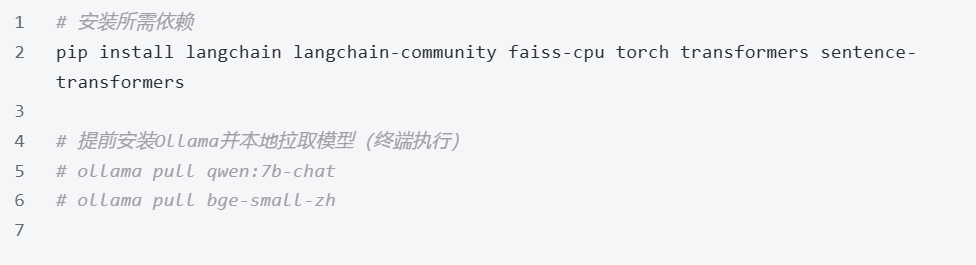
基于前文理论与落地流程,这里给大家提供一套零门槛、可直接运行 的本地化RAG完整代码。基于 Ollama + LangChain + FAISS + 本地BGE嵌入模型 实现,全程离线本地化运行,无需公网、无需API密钥,适配Windows/Linux服务器。
前置依赖安装
6.1 完整工程化代码
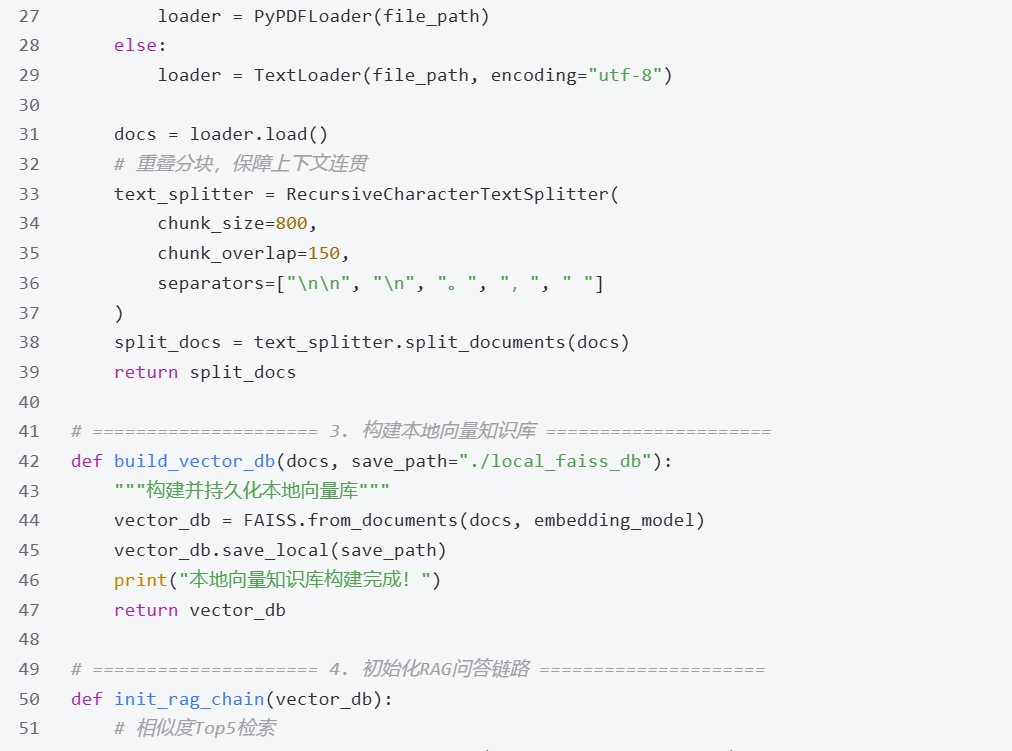


6.2 代码核心说明
-
全链路本地化:嵌入模型、大模型、向量检索均在本地运行,无任何公网数据交互,满足合规要求;
-
优化分块策略:采用递归字符分块+重叠切片,解决长文本语义断裂问题,提升检索精度;
-
抗幻觉配置:温度值设置0.2,限制模型创造性,严格基于检索内容作答;
-
支持多格式文档:原生支持TXT、PDF企业文档,可快速拓展Word、Excel格式;
-
知识库持久化:向量库本地保存,无需每次启动重新构建,支持增量更新。
6.3 知识库增量更新实战代码
原版代码仅支持全量重建知识库,企业实际场景中频繁全量重建会损耗性能、浪费算力。下面新增FAISS向量库增量更新代码,支持新增文档追加入库,无需重建全部索引,适配常态化知识库迭代。
6.4 增量更新核心特性说明
-
低损耗迭代:仅对新增文档做分块、向量化处理,原有知识库数据完全保留,大幅节省算力与时间;
-
无缝兼容:与上文基础RAG代码完全兼容,可直接复用原有模型、分块、检索配置;
-
持久化存储:更新后自动覆盖本地向量库,下次启动项目可直接加载最新知识库;
-
批量拓展:可二次封装循环逻辑,支持批量新增多个文档,适配企业常态化资料更新场景。
6.5 常见运行报错解决
-
Ollama模型找不到:确认本地已执行ollama pull拉取对应模型,且Ollama服务正常启动;
-
GPU显存不足:修改代码中device为cpu,同时使用INT4量化模型降低显存占用;
-
中文乱码:文档加载时统一utf-8编码,避免特殊格式文档解析异常。
七、常见问题与性能优化方案
本地化RAG落地过程中,易出现检索不准、回答卡顿、上下文混乱、幻觉残留等问题,针对性优化方案如下:
-
检索精度低、答非所问:优化分块策略,采用重叠分块保留上下文信息;替换高精度中文Embedding模型;开启Rerank重排序过滤;
-
本地推理速度慢:升级模型量化等级(INT4优先);开启推理引擎GPU加速;限制单轮上下文长度;批量预处理知识库;
-
知识库更新滞后:搭建增量更新链路,新增文档自动分块、向量化、入库,无需重建全量索引;
-
模型依旧产生幻觉:强化Prompt约束,添加"无相关信息则拒绝作答"规则;降低模型创造性温度值(temperature=0.1~0.3);
-
多轮对话上下文丢失:接入对话记忆机制,缓存历史对话上下文,结合实时检索结果完成多轮增强生成。
八、落地总结与行业展望
模型本地化解决了大模型落地的安全、成本、可控性 问题,而RAG技术解决了本地模型知识固化、幻觉频发、领域适配弱的核心痛点,二者融合是当前企业私有化AI落地的最优解,完美适配企业知识库问答、智能客服、文档解析、工业质检、政务咨询等各类私有化场景。
相较于传统模型微调,本地化RAG无需海量标注数据、无需高额训练算力、迭代灵活、落地门槛极低,是中小厂商、传统企业快速实现AI赋能的首选方案。
未来,随着轻量化模型精度持续提升、向量数据库技术迭代、Agent智能体与RAG的深度融合,本地化RAG系统将实现更智能的自主问答、主动检索、多文档联动分析,进一步拓宽企业AI私有化落地的边界。
九、写在最后
本文从底层理论、架构设计、工程落地、性能优化四个维度,完整拆解了本地化模型与RAG的融合体系。相比于单纯的理论学习,工程化落地的核心在于理论适配场景、细节决定效果,分块策略、检索精度、Prompt设计、模型量化的每一个细节,都会直接影响最终问答体验。