摘要
自回归(Autoregressive, AR)模型在自然语言处理领域取得了巨大成功,但其在计算机视觉领域的潜力却长期受限于传统的"下一词元(next-token)"预测范式。本文介绍的视觉自回归建模(Visual AutoRegressive modeling, VAR) 提出了一种全新的生成范式,将图像的自回归学习重新定义为从粗到细的"下一尺度预测(next-scale prediction)"。这一直观且符合人类视觉感知规律的方法,使得GPT风格的AR模型在图像生成任务中首次 超越了扩散模型(Diffusion Transformers, DiT)。在ImageNet 256×256基准测试中,VAR将FID从18.65大幅降至1.73,推理速度提升了20倍。更为重要的是,VAR展现出了类似于大语言模型(LLMs)的幂律缩放定律(Scaling Laws)与零样本泛化能力 ,为视觉生成与统一学习开辟了新的路径。

引言
近年来,以GPT系列为代表的大语言模型(LLMs)通过"预测下一个词元"的自监督学习策略,展现出了卓越的通用性与智能。其成功的两大核心基石在于缩放定律(Scaling Laws)与零样本泛化能力(Zero-shot generalization)。受此启发,计算机视觉领域一直致力于开发大型视觉自回归模型或世界模型。
然而,现有的视觉AR模型(如VQGAN、DALL-E等)通常将2D图像展平为1D序列(如光栅扫描顺序)进行生成。这种处理方式存在显著的理论与实践缺陷:
- 违背数学前提:图像特征具有双向相关性,强行展平并应用单向依赖假设会导致信息建模的冲突。
- 破坏空间局部性:展平操作破坏了相邻像素/特征之间的空间拓扑结构。
- 计算效率低下 :生成包含 n2n^2n2 个词元的图像需要 O(n2)O(n^2)O(n2) 步自回归迭代,总计算复杂度高达 O(n6)O(n^6)O(n6),导致其性能与推理速度显著落后于扩散模型(Diffusion Models)。
人类在感知和创作图像时,通常遵循"先全局结构,后局部细节"的层次化过程。基于此,VAR摒弃了传统的"下一词元预测",提出以"尺度(分辨率)"为自回归单元,从低分辨率到高分辨率逐步生成图像。这一范式不仅在理论上解决了传统AR模型的缺陷,更在实证中打破了AR模型在视觉领域的性能瓶颈。
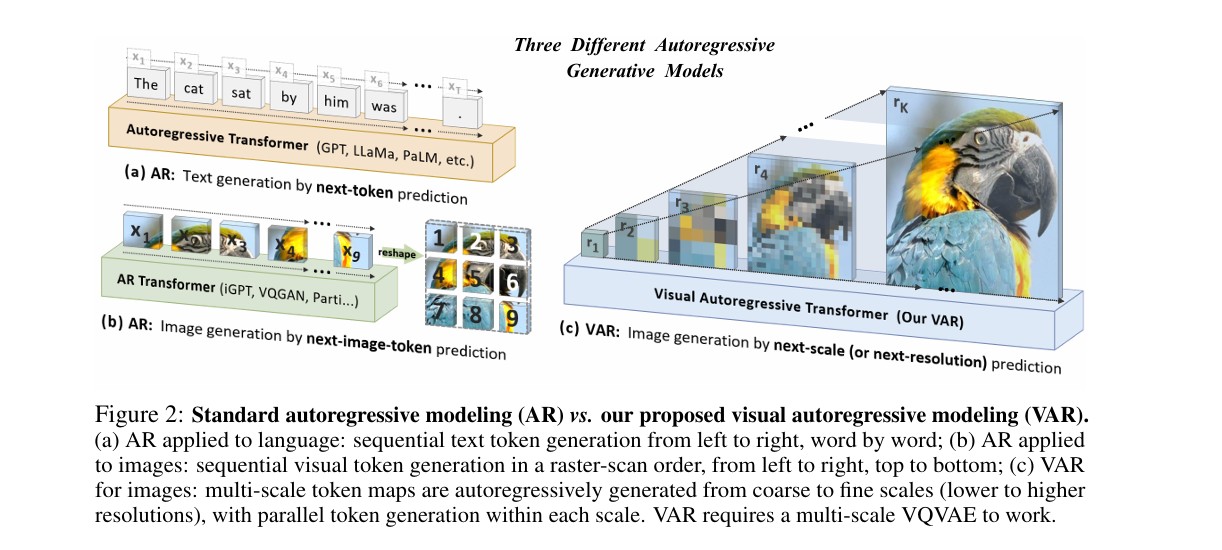
模型架构
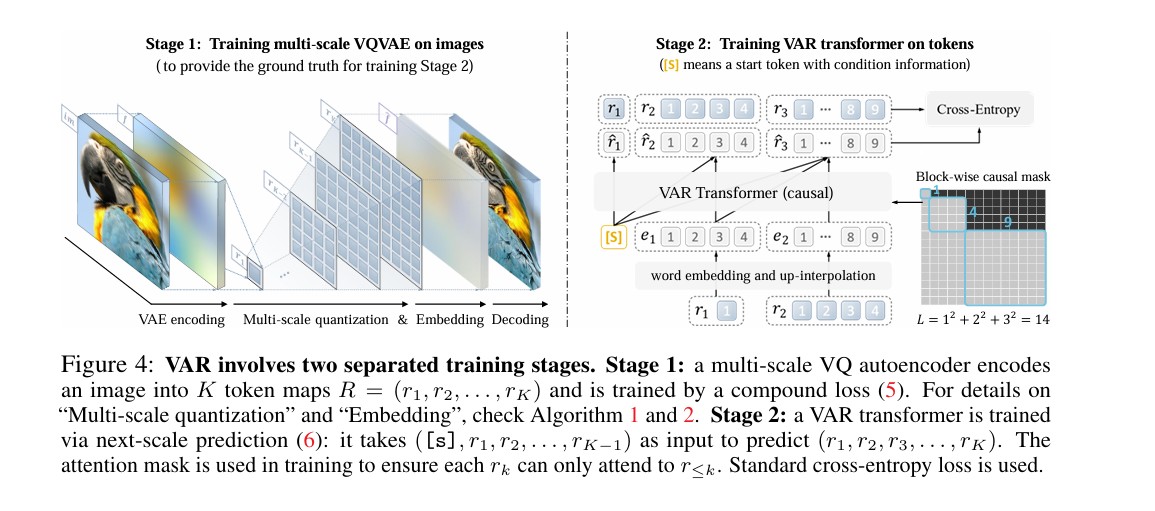
VAR框架的核心在于将自回归单元从"单个离散词元"升维至"整个词元映射图(Token Map)"。其架构主要包含两个训练阶段:多尺度VQVAE的构建与VAR Transformer的训练。
1. 下一尺度预测(Next-Scale Prediction)
假设图像被量化为 KKK 个不同分辨率的离散词元图 R=(r1,r2,...,rK)R = (r_1, r_2, ..., r_K)R=(r1,r2,...,rK),其中分辨率逐层递增。VAR的自回归似然函数被重新定义为:
p(r1,r2,...,rK)=∏k=1Kp(rk∣r1,r2,...,rk−1) p(r_1, r_2, ..., r_K) = \prod_{k=1}^K p(r_k | r_1, r_2, ..., r_{k-1}) p(r1,r2,...,rK)=k=1∏Kp(rk∣r1,r2,...,rk−1)
在第 kkk 步自回归生成中,模型基于前 k−1k-1k−1 个尺度的条件,并行 预测当前尺度 rkr_krk 中的所有 hk×wkh_k \times w_khk×wk 个词元。这种设计完美保留了图像的空间局部性,并将生成复杂度从 O(n6)O(n^6)O(n6) 大幅降至 O(n4)O(n^4)O(n4)。
2. 多尺度VQVAE(Tokenization)
为了提供多尺度的 ground-truth,VAR设计了一种带有残差结构的多尺度量化自编码器。该编码器使用共享的码本(Codebook),将图像特征从粗到细逐层量化。在解码阶段,通过将各尺度的特征上采样并叠加,实现图像的高保真重建。
3. VAR Transformer
VAR直接采用了类似GPT-2的Decoder-only Transformer架构,并结合了自适应层归一化(AdaLN)以融入类别条件信息。在训练时,模型采用块级因果掩码(Block-wise causal mask) ,确保每个尺度 rkr_krk 只能关注到其前缀尺度 r≤kr_{\le k}r≤k;而在推理阶段,借助KV-Caching技术,模型可实现极高效的并行生成。
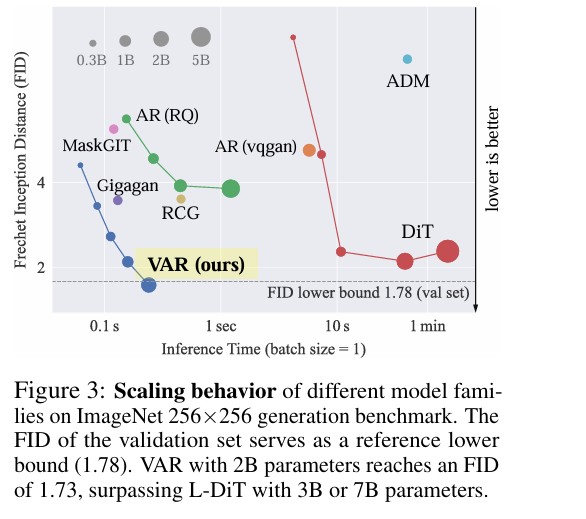
实验结果和分析
论文在ImageNet条件生成基准上进行了详尽的实验,从生成质量、缩放定律及泛化能力三个维度验证了VAR的有效性。
1. 突破SOTA的图像生成质量与效率
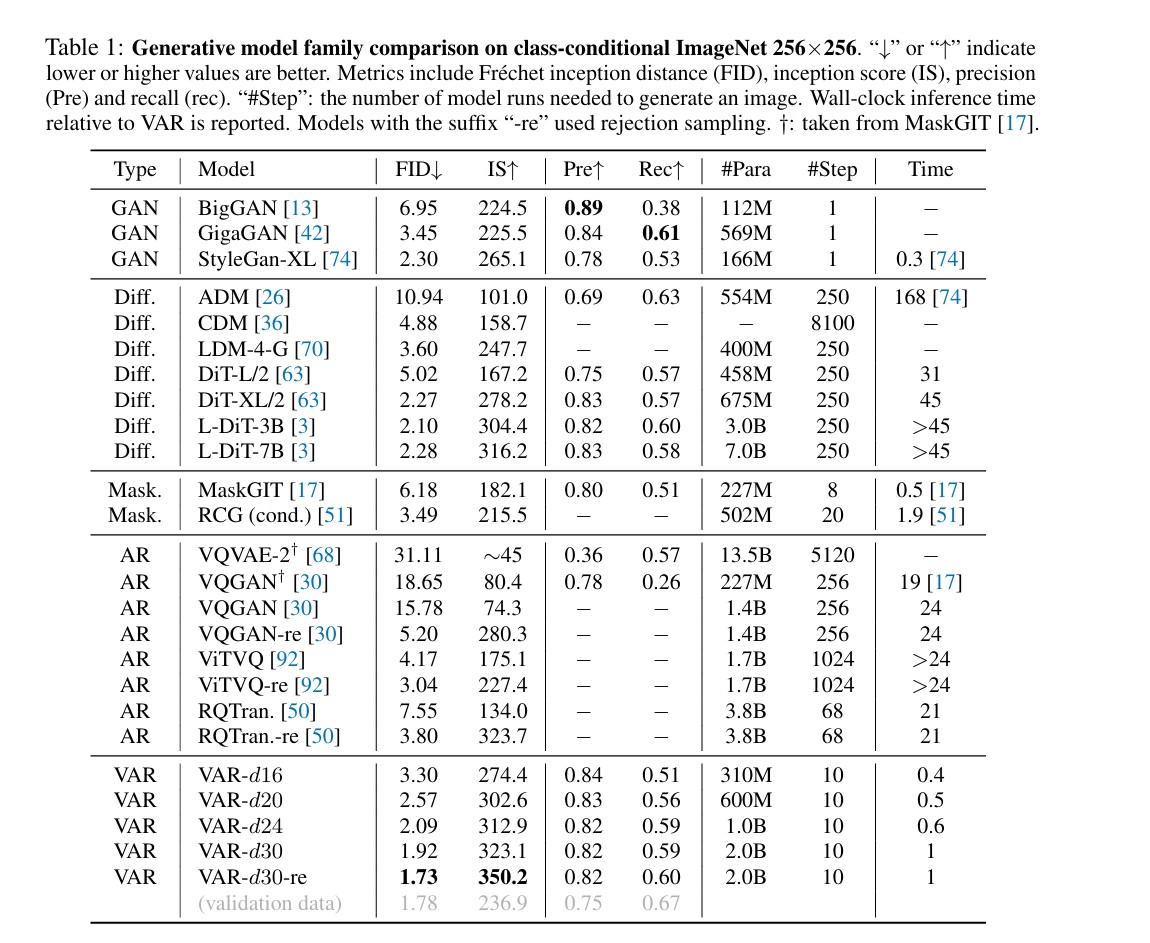
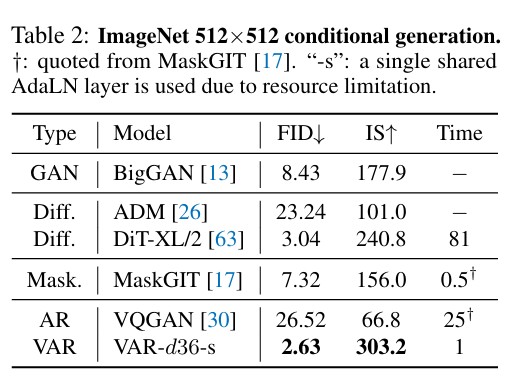
在ImageNet 256×256基准上,拥有2B参数的VAR-d30模型取得了 FID 1.73 和 IS 350.2 的卓越成绩。这不仅显著优于传统的AR基线(如VQGAN),更全面超越了当前主流的扩散模型(如DiT-XL/2、L-DiT-7B)。此外,得益于并行生成机制,VAR的推理速度比传统AR模型快约20倍,比DiT快数十倍,达到了媲美GAN的实时生成效率。在512×512分辨率下,VAR同样保持了压倒性的优势。
2. 视觉领域的幂律缩放定律(Scaling Laws)
缩放定律是LLM成功的标志。研究团队训练了12种不同规模(18M至2B参数)的VAR模型,实证发现了VAR的测试损失(Test Loss)和词元错误率(Token Error Rate)与模型参数 NNN 及最优训练计算量 CminC_{min}Cmin 之间存在高度拟合的幂律关系(Power-law) 。其对数坐标下的皮尔逊相关系数接近 -0.998。这一发现证明了VAR具备极强的可扩展性,且更大的模型在计算上更具效率。
3. 零样本任务泛化(Zero-shot Generalization)
未经任何特定任务微调,VAR仅通过改变推理时的掩码或条件注入,便成功实现了图像修复(In-painting) 、图像外扩(Out-painting)以及类别条件图像编辑 。这证明VAR确实学习到了鲁棒的视觉数据分布,具备了类似基础模型(Foundation Models)的上下文泛化能力。
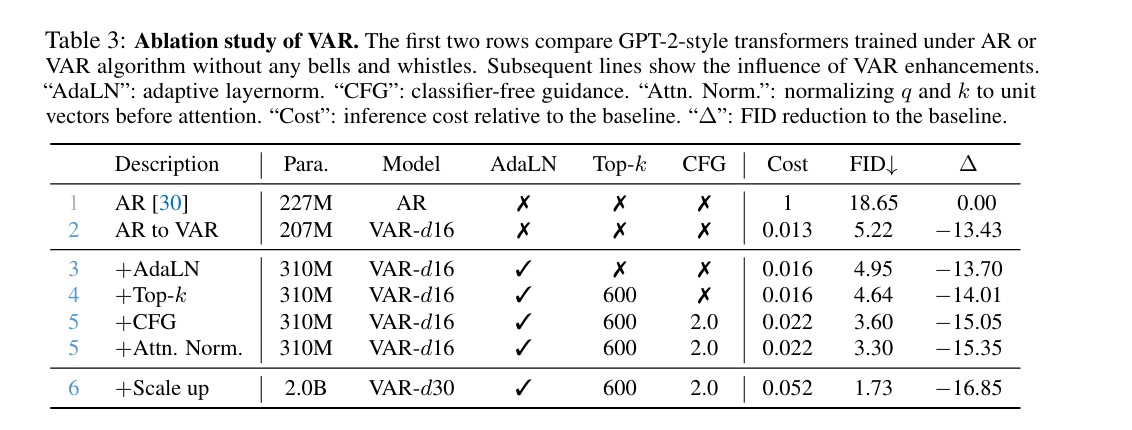
总结与展望
本文提出的视觉自回归建模(VAR)通过创新的"下一尺度预测"范式,从理论上修正了传统图像AR模型的缺陷,并在实践中历史性地使GPT风格的自回归模型在图像质量、多样性、数据效率与推理速度上全面超越了强大的扩散模型(DiT)。VAR在视觉领域成功复现了LLM的"缩放定律"与"零样本泛化"两大核心属性,为构建统一的视觉-语言多模态大模型奠定了坚实基础。
未来展望:
- Tokenizer的演进:当前的VAR主要聚焦于学习范式的创新,未来结合更先进的VQVAE/Tokenizer技术(如有限标量量化等),有望进一步提升生成上限。
- 文本到图像生成(Text-to-Image):鉴于VAR与LLM在架构上的高度同源性,未来可通过编码器-解码器或上下文学习(In-context learning)的方式,无缝接入文本提示,实现强大的文生图能力。
- 视频生成(Video Generation):传统AR模型因计算复杂度过高而难以处理高分辨率视频。VAR可自然扩展至"3D下一尺度预测(时空金字塔)",在保持时序一致性的同时大幅降低计算成本,这使其在未来的视频生成领域(如对标SORA)具备巨大的竞争潜力。
注:本博客内容基于论文《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》(arXiv:2404.02905v2) 整理撰写。相关代码与模型已开源至 GitHub: FoundationVision/VAR。