🎯 杂乱文件堆里的重复噩梦
日常办公或资料整理时,你是否总被大量 "同名不同版""相似名重复内容" 的文件困扰?下载的教程、备份的文档、收集的素材,日积月累后不仅占用大量磁盘空间,找文件时翻来翻去分不清版本,手动删除又怕误删重要文件 ------ 这是多数人文件管理的高频痛点。
我们团队深耕文件管理工具开发,基于 Python+Tkinter 打造的同名文件去重工具,从底层逻辑出发解决这些问题,让文件整理从 "耗时耗力" 变成 "一键高效"。
.
步里软件【编号2453】文件批量去重工具操作演示视频
🧩 核心逻辑:文件去重的底层代码设计
一款好用的去重工具,核心在于 "精准识别" 和 "安全处理",我们的代码架构围绕这两个核心展开。首先是文件名的规范化处理,这是识别重复的基础 ------ 通过正则过滤特殊字符,再剔除自定义过滤词,让相似文件名的比对更精准:
def normalize_filename(filename, filter_words=None):
name_without_ext = os.path.splitext(filename)[0]
result = name_without_ext
if filter_words:
for word in filter_words:
if word:
result = result.replace(word, '')
return NORMALIZE_PATTERN.sub('', result)这段代码的设计逻辑是:先剥离文件扩展名,再批量移除干扰性的过滤词(比如 "作者""完结" 等),最后用正则清除所有非文字 / 非中文的符号,让文件名回归 "核心标识",避免因符号、冗余词汇导致的重复漏判。
其次是相似度计算逻辑,我们采用 Python 内置的 SequenceMatcher 算法,而非简单的 "完全匹配",这让工具能识别 "近似名" 的重复文件:
def similarity(s1, s2):
if not s1 and not s2:
return 1.0
if not s1 or not s2:
return 0.0
return SequenceMatcher(None, s1, s2).ratio()这个算法会逐字符比对两个规范化后的文件名,输出 0-1 的相似度值,比如 "教程 - Python 基础" 和 "Python 基础教程" 的相似度接近 1.0,能被精准识别,这也是工具比手动筛选更智能的核心原因。
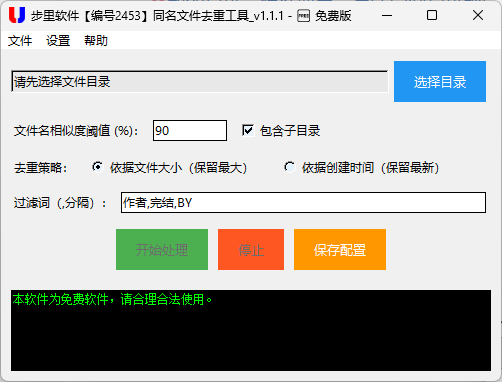
📂 核心功能 1:智能目录扫描,不放过任何重复痕迹
解决重复文件问题的第一步,是完整且精准地扫描目标目录。我们的扫描功能设计兼顾 "全面性" 和 "灵活性",代码底层采用 os.walk 实现递归扫描,同时支持 "包含 / 不包含子目录" 的自定义选择:
def scan_directory(root_dir, log_callback=None, filter_words=None, include_subdirs=True):
files = []
file_count = 0
if log_callback:
if include_subdirs:
log_callback(f"开始递归扫描目录: {root_dir}")
else:
log_callback(f"开始扫描目录(不包含子目录): {root_dir}")实际使用中,用户可以选择扫描单个文件夹,也可以覆盖所有子文件夹;扫描过程中会实时输出日志,显示每个文件的名称、规范化结果、扩展名、大小等信息,既让用户看到扫描进度,也方便核对扫描范围。哪怕是隐藏文件、不同扩展名的同名文件(比如 "笔记.txt" 和 "笔记.docx"),也能被完整抓取,避免漏扫导致的重复残留。
同时,扫描时支持自定义过滤词(比如 "备份""副本""BY" 等),这些词汇会被自动剔除后再做比对 ------ 比如 "Python 教程_备份.txt" 和 "Python 教程.txt",过滤 "备份" 后会被识别为同一文件,解决了 "加后缀导致重复识别失败" 的问题。
🎨 核心功能 2:灵活的相似度匹配,精准识别重复文件
扫描完成后,工具会基于 "相似度阈值" 筛选重复文件,用户可自定义阈值(默认 90%),比如设置 80% 阈值时,相似度≥80% 的文件会被判定为重复。这个设计兼顾了 "精准度" 和 "灵活性":对要求严格的用户,可将阈值设为 100%(仅完全同名文件判定为重复);对需要模糊匹配的用户,降低阈值即可识别近似名文件。
比如整理下载的网课资料时,"01-Python 入门.mp4" 和 "Python 入门 - 01.mp4" 的规范化名称高度相似,设置 90% 阈值就能被识别;而如果是完全不相关的文件,哪怕有个别字符相同,也会因相似度不足被排除,避免误判。
⚖️ 核心功能 3:自定义去重策略,保留最有价值的文件
识别出重复文件后,工具的核心价值在于 "安全去重"------ 我们提供两种核心策略,用户可按需选择:一是 "按文件大小保留(保留最大)",适合资料、视频、压缩包等文件,确保保留内容最完整的版本;二是 "按创建时间保留(保留最新)",适合文档、笔记等经常更新的文件,确保保留最新编辑的版本。
这个策略的底层逻辑是:对每组重复文件,工具会提取文件的大小 / 创建时间属性,排序后保留最优项,其余文件标记为待删除;删除前会弹出确认提示,避免误操作。同时,整个处理过程会被完整记录在日志面板中,用户可随时查看哪些文件被处理、哪些被保留,做到 "可追溯、可核对"。
🛠️ 人性化设计:让文件整理更省心
除了核心的去重功能,工具在交互和使用体验上做了大量细节优化:
-
配置保存功能:用户设置的相似度阈值、过滤词、扫描范围、去重策略等,均可一键保存,下次打开自动加载,无需重复设置:
def save_config(self):
config = {
'threshold': self.threshold_var.get(),
'strategy': self.strategy_var.get(),
'filter_words': self.filter_var.get(),
'last_dir': self.root_dir if self.root_dir else '',
'include_subdirs': self.include_subdirs_var.get()
} -
可视化日志面板:所有操作(扫描、比对、删除)的日志实时输出,字体和颜色区分(黑底绿字),清晰易读;
-
友好的 UI 交互:自定义的美观按钮(hover / 点击状态变色)、滚动提示栏、简洁的参数设置区,哪怕是电脑基础薄弱的用户,也能快速上手;
-
紧急停止功能:处理过程中若发现异常,可点击 "停止" 按钮中止操作,避免批量删除风险。
✨ 总结:让文件管理回归简单
这款同名文件去重工具,从底层代码逻辑到上层交互设计,始终围绕 "解决重复文件痛点" 展开:通过规范化文件名解决 "识别不准",通过灵活扫描解决 "漏扫",通过自定义策略解决 "误删",通过可视化日志解决 "不可控"。无论是职场人士整理办公文件、学生整理学习资料,还是个人用户清理硬盘备份,都能通过这款工具高效完成文件去重,释放磁盘空间,让文件管理更有序。
.✨ 程序源码及成品软件下载
https://pan.quark.cn/s/56ea761c14d3
https://pan.baidu.com/s/5WF5UUr03w50hKFDyksIrOg
关键词:同名文件去重工具,文件去重软件,重复文件识别,目录扫描去重,文件名相似度匹配,自定义去重策略,文件整理工具,Python 文件去重,批量删除重复文件