文档转换器与字符分割器组件的使用
DocumentTransformer 组件
在 LangChain 中,使用 文档加载器 加载得到的文档一般来说存在着几个问题:原始文档太大、原始文档的数据格式不符合需求(需要英文但是只有中文)、原始文档的信息没有经过提炼等问题。
如果将这类数据直接转换成向量并存储到数据库中,会导致在执行相似性搜索和 RAG 的过程中,错误率大大提升。所以在 LLM 应用开发中,在加载完数据后,一般会执行多一步 转换 的过程,即将加载得到的 文档列表 进行转换,得到符合需求的 文档列表 。
转换涵盖的操作就非常多,例如:文档切割、文档属性提取、文档翻译、HTML 转文本、重排、元数据标记等都属于转换。
在前面的聊天机器人架构中添加上转换步骤,更新后的 聊天机器人架构/运行流程 如下所示:
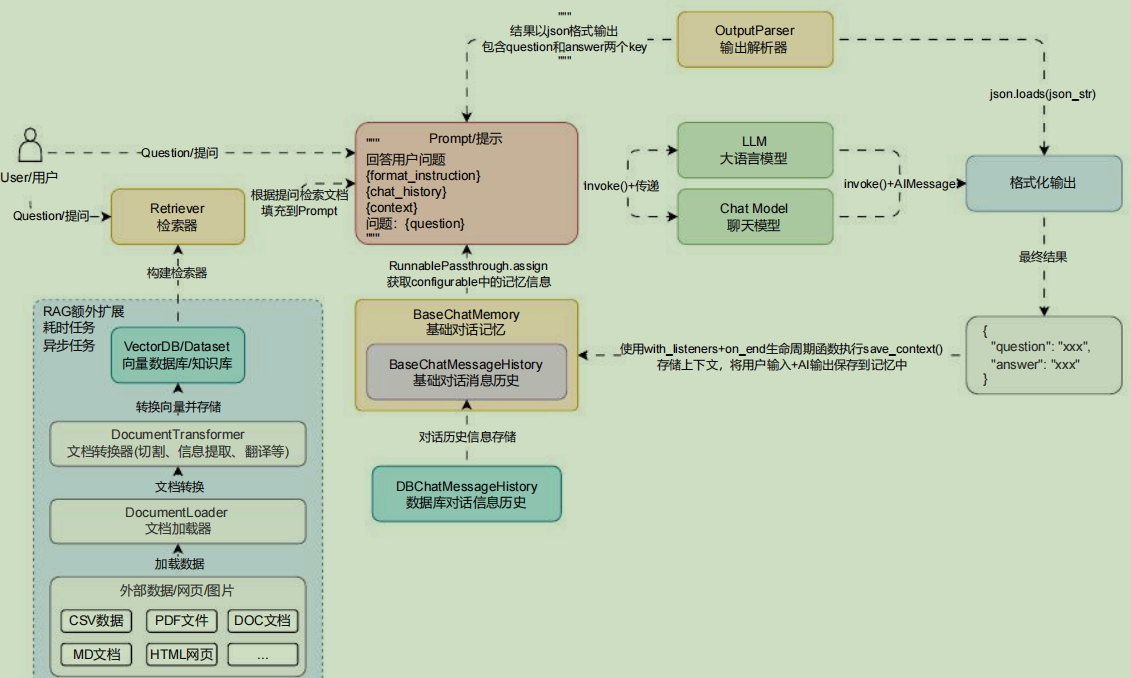
在 LangChain 中针对文档的转换也统一封装了一个基类 BaseDocumentTransformer ,所有涉及到文档的转换的类均是该类的子类,将大块文档切割成 chunk 分块的文档分割器也是BaseDocumentTransformer 的子类实现。
BaseDocumentTransformer 基类封装了两个方法:
- transform_documents() :抽象方法,传递文档列表,返回转换后的文档列表。
- atransform_documents() :转换文档列表函数的异步实现,如果没有实现,则会委托transform_documents() 函数实现。
在 LangChain 中,文档转换组件分成了两类: 文档分割器(使用频率高) 、 文档处理转换器(使用频率低,老版本写法) 。
并且目前 LangChain 团队已经将 文档分割器 这个高频使用的部分单独拆分成一个 Python 包,哪怕不使用 LangChain 框架本身进行开发,也可以使用其文本分割包,快速分割数据,在使用前必须执行以下命令安装:
bash
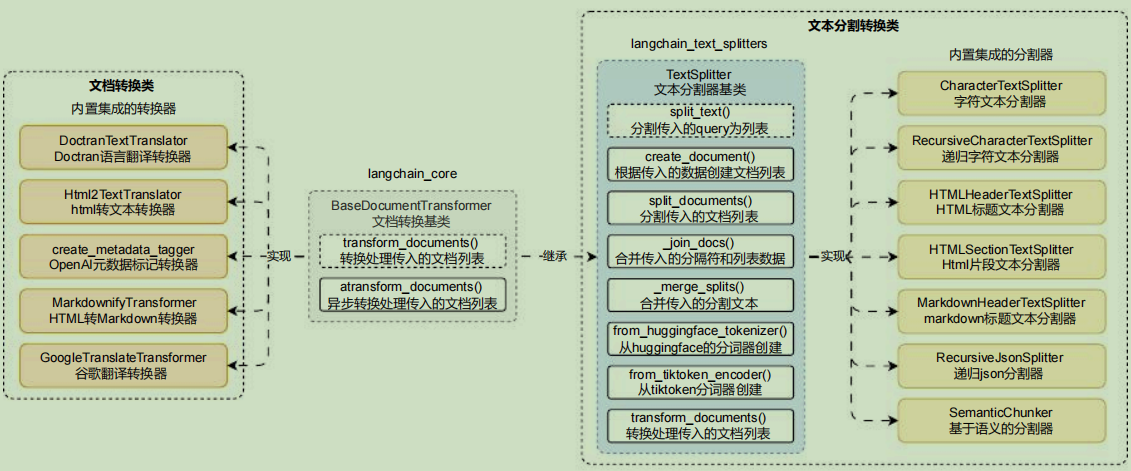
pip install -qU langchain-text-splitters对于文本分割器来说,除了继承 BaseDocumentTransformer ,还单独设置了文本分割器基类TextSplitter ,从而去实现更加丰富的功能, BaseDocumentTransformer 衍生出来的类图:
字符分割器基础使用技巧
在文档分割器中,最简单的分割器就是------字符串分割器,这个组件会基于给定的字符串进行分割,默认为 \n\n ,并且在分割时会尽可能保证数据的连续性。分割出来每一块的长度是通过字符数来衡量的,使用起来也非常简单,实例化 CharacterTextSplitter 需传递多个参数,信息如下:
- separator :分隔符,默认为 \n\n 。
- is_separator_regex :是否正则表达式,默认为 False 。
- chunk_size :每块文档的内容大小,默认为 4000 。
- chunk_overlap :块与块之间重叠的内容大小,默认为 200 。
- length_function :计算文本长度的函数,默认为 len 。
- keep_separator :是否将分隔符保留到分割的块中,默认为 False 。
- add_start_index :是否添加开始索引,默认为 False ,如果是的话会在元数据中添加该切块的
起点。 - strip_whitespace :是否删除文档头尾的空白,默认为 True 。
如果想将文档切割为不超过 500 字符,并且每块之间文本重叠 50 个字符,可以使用CharacterTextSplitter 来实现,代码如下:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 1. 加载对应的文档
loader = UnstructuredMarkdownLoader("./项目API资料.md")
documents = loader.load()
# 2.创建文本分割器
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=50,
)
# 3. 分割文本
chunks = text_splitter.split_documents(documents)
for chunk in chunks:
print(f"快大小:{len(chunk.page_content)}")输出内容:
python
Created a chunk of size 771, which is longer than the specified 500
Created a chunk of size 980, which is longer than the specified 500
Created a chunk of size 542, which is longer than the specified 500
Created a chunk of size 835, which is longer than the specified 500
块内容大小:251,元数据:{'source': './项目API文档.md', 'start_index': 0}
块内容大小:451,元数据:{'source': './项目API文档.md', 'start_index': 246}
块内容大小:771,元数据:{'source': './项目API文档.md', 'start_index': 699}
块内容大小:435,元数据:{'source': './项目API文档.md', 'start_index': 1472}
块内容大小:497,元数据:{'source': './项目API文档.md', 'start_index': 1859}
块内容大小:237,元数据:{'source': './项目API文档.md', 'start_index': 2359}
块内容大小:980,元数据:{'source': './项目API文档.md', 'start_index': 2598}
块内容大小:438,元数据:{'source': './项目API文档.md', 'start_index': 3580}
块内容大小:293,元数据:{'source': './项目API文档.md', 'start_index': 4013}
块内容大小:498,元数据:{'source': './项目API文档.md', 'start_index': 4261}
块内容大小:463,元数据:{'source': './项目API文档.md', 'start_index': 4712}
块内容大小:438,元数据:{'source': './项目API文档.md', 'start_index': 5129}
块内容大小:542,元数据:{'source': './项目API文档.md', 'start_index': 5569}
块内容大小:464,元数据:{'source': './项目API文档.md', 'start_index': 6113}
块内容大小:835,元数据:{'source': './项目API文档.md', 'start_index': 6579}
块内容大小:489,元数据:{'source': './项目API文档.md', 'start_index': 7416}使用 CharacterTextSplitter 进行分割时,虽然传递了 chunk_size 为 500,但是仍然没法确保分割出来的文档一直保持在这个范围内,这是因为在底层 CharacterTextSplitter 是先按照分割符号拆分整个文档,然后循环遍历拆分得到的列表,将每个列表逐个相加,直到最接近 chunk_size 窗口大小时则完成一个 Document 的组装。
但是如果基于分割符号得到的文本,本身长度已经超过了 chunk_size ,则会直接进行警告,并且将对应的文本单独变成一个块。
核心代码如下:
python
# langchain_text_splitters/character->CharacterTextSplitter::split_text
def split_text(self, text: str) -> List[str]:
"""Split incoming text and return chunks."""
# First we naively split the large input into a bunch of smaller ones.
separator = (
self._separator if self._is_separator_regex else re.escape(self._separator)
)
splits = _split_text_with_regex(text, separator, self._keep_separator)
_separator = "" if self._keep_separator else self._separator
return self._merge_splits(splits, _separator)
def _split_text_with_regex(
text: str, separator: str, keep_separator: bool
) -> List[str]:
# Now that we have the separator, split the text
if separator:
if keep_separator:
# The parentheses in the pattern keep the delimiters in the result.
_splits = re.split(f"({separator})", text)
splits = [_splits[i] + _splits[i + 1] for i in range(1, len(_splits),2)]
if len(_splits) % 2 == 0:
splits += _splits[-1:]
splits = [_splits[0]] + splits
else:
splits = re.split(separator, text)
else:
splits = list(text)
return [s for s in splits if s != ""]递归字符文本分割器
递归字符文本分割器
普通的字符文本分割器只能使用单个分隔符对文本内容进行划分,在划分的过程中,可能会出现文档块过小 或者 过大 的情况,这会让 RAG 变得不可控,例如:
- 文档块可能会变得非常大,极端的情况下某个块的内容长度可能就超过了 LLM 的上下文长度限制,这样这个文本块永远不会被引用到,相当于存储了数据,但是数据又丢失了。
- 文档块可能会远远小于窗口大小,导致文档块的信息密度太低,块内容即使填充到 Prompt 中,LLM 也无法提取出有用的信息。
那么有没有一种分割方案,可以解决这个问题呢?按照 分隔符 初次分割的时候,去检测块内容,如果太大就按照提供的 备选分隔符 二次分割,如果太小则合并前后的块,最后让所有的块内容长度都控制在指定的大小并尽可能接近呢?
在 LangChain 中就为这种方案提供了一个分割器组件------ RecursiveCharacterTextSplitter ,即递归字符串分割,这个分割器可以传递 一组分隔符 和 设定块内容大小 ,根据分隔符的优先顺序对文本进行预分割,然后将小块进行合并,将大块进行递归分割,直到获得所需块的大小,最终这些文档块的大小并不能完全相同,但是仍然会逼近指定长度。
RecursiveCharacterTextSplitter 的分隔符参数默认为 "\\n\\n", "\\n", " ", "" ,即优先使用换两行的数据进行分割,然后在使用单个换行符,如果块内容还是太大,则使用空格,最后再拆分成单个字符。
所以如果使用默认参数,这个字符文本分割器最后得到的文档块长度一定不会超过预设的大小,但是仍然会有小概率出现远小于的情况(目前也没有很好的解决方案)。例如使用递归字符文本分割器修改上节课的需求,示例代码如下:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = UnstructuredMarkdownLoader("./项目API文档.md")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
add_start_index=True,
)
chunks = text_splitter.split_documents(documents)
for chunk in chunks:
print(f"块大小:{len(chunk.page_content)}, 块元数据:{chunk.metadata}")输出内容:
python
块大小:251, 块元数据:{'source': './项目API文档.md', 'start_index': 0}
块大小:451, 块元数据:{'source': './项目API文档.md', 'start_index': 246}
块大小:490, 块元数据:{'source': './项目API文档.md', 'start_index': 699}
块大小:305, 块元数据:{'source': './项目API文档.md', 'start_index': 1165}
块大小:435, 块元数据:{'source': './项目API文档.md', 'start_index': 1472}
块大小:497, 块元数据:{'source': './项目API文档.md', 'start_index': 1859}
块大小:237, 块元数据:{'source': './项目API文档.md', 'start_index': 2359}
块大小:483, 块元数据:{'source': './项目API文档.md', 'start_index': 2598}
块大小:486, 块元数据:{'source': './项目API文档.md', 'start_index': 3092}
块大小:438, 块元数据:{'source': './项目API文档.md', 'start_index': 3580}
块大小:293, 块元数据:{'source': './项目API文档.md', 'start_index': 4013}
块大小:498, 块元数据:{'source': './项目API文档.md', 'start_index': 4261}
块大小:463, 块元数据:{'source': './项目API文档.md', 'start_index': 4712}
块大小:438, 块元数据:{'source': './项目API文档.md', 'start_index': 5129}
块大小:474, 块元数据:{'source': './项目API文档.md', 'start_index': 5569}
块大小:93, 块元数据:{'source': './项目API文档.md', 'start_index': 6018}
块大小:464, 块元数据:{'source': './项目API文档.md', 'start_index': 6113}
块大小:478, 块元数据:{'source': './项目API文档.md', 'start_index': 6579}
块大小:379, 块元数据:{'source': './项目API文档.md', 'start_index': 7035}
块大小:489, 块元数据:{'source': './项目API文档.md', 'start_index': 7416}RecursiveCharacterTextSplitter 底层的运行流程其实也非常简单,可以拆分成 预分割 、 大文档块递归分割 、 小文档块合并 。运行流程图如下(需掌握,目前 LLM 应用开发中高频提问到的一个问题):
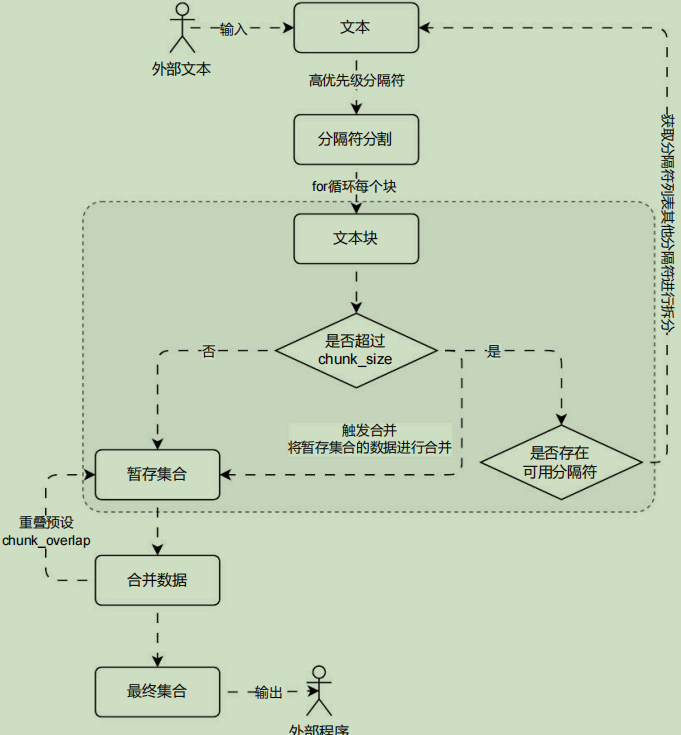
对比普通的字符文本分割器, 递归字符文本分割器可以传递多个分隔符,并且根据不同分隔符的优先级来执行相应的分割。在 LangChain 中通过 RecursiveCharacterTextSplitter 类实现对文本的递归字符串分割
衍生代码分割器
递归字符文本分割器的核心部分在于传递不同的分割符列表,通过不同的优先级的列表,可以实现一些复杂文件的拆分,例如在该分割器内部预先构建了大量的的分割列表,用于在特定的编程语言中拆分文本。
支持的编程语言类型存储在 langchain_text_splitters.Language 枚举中,涵盖如下:
python
class Language(str, Enum):
"""Enum of the programming languages."""
CPP = "cpp"
GO = "go"
JAVA = "java"
KOTLIN = "kotlin"
JS = "js"
TS = "ts"
PHP = "php"
PROTO = "proto"
PYTHON = "python"
RST = "rst"
RUBY = "ruby"
RUST = "rust"
SCALA = "scala"
SWIFT = "swift"
MARKDOWN = "markdown"
LATEX = "latex"
HTML = "html"
SOL = "sol"
CSHARP = "csharp"
COBOL = "cobol"
C = "c"
LUA = "lua"
PERL = "perl"
HASKELL = "haskell"要想查看给定语言的分隔符,可以使用RecursiveCharacterTextSplitter.get_separators_for_language() 函数获取,例如查看 Python 语言的分隔符,如下:
python
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
separators = RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)
print(separators)
# 输出
['\nclass ', '\ndef ', '\n\tdef ', '\n\n', '\n', ' ', '']可以从分隔符列表中看到 Python 文件的分割逻辑,优先将所有类都分割出来,然后分割函数,接下来分割类方法、模块语句等内容。
要想使用这些 编程语言分隔符 其实非常简单,在构造分割器的时候传递即可,或者使用from_language() 并传递编程语言枚举数据也可以实现,示例如下:
python
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
loader = UnstructuredFileLoader("./demo.py")
text_splitter = RecursiveCharacterTextSplitter.from_language(
Language.PYTHON,
chunk_size=500,
chunk_overlap=50,
)
documents = loader.load()
chunks = text_splitter.split_documents(documents)
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据:{chunk.metadata}")输出内容:
python
块大小: 151, 元数据:{'source': './demo.py'}
块大小: 335, 元数据:{'source': './demo.py'}
块大小: 439, 元数据:{'source': './demo.py'}
块大小: 499, 元数据:{'source': './demo.py'}
块大小: 108, 元数据:{'source': './demo.py'}
块大小: 187, 元数据:{'source': './demo.py'}
块大小: 352, 元数据:{'source': './demo.py'}
块大小: 450, 元数据:{'source': './demo.py'}
块大小: 446, 元数据:{'source': './demo.py'}
块大小: 431, 元数据:{'source': './demo.py'}
块大小: 347, 元数据:{'source': './demo.py'}
块大小: 492, 元数据:{'source': './demo.py'}
块大小: 491, 元数据:{'source': './demo.py'}
块大小: 471, 元数据:{'source': './demo.py'}
块大小: 489, 元数据:{'source': './demo.py'}
块大小: 474, 元数据:{'source': './demo.py'}
块大小: 476, 元数据:{'source': './demo.py'}
块大小: 492, 元数据:{'source': './demo.py'}
块大小: 472, 元数据:{'source': './demo.py'}
块大小: 490, 元数据:{'source': './demo.py'}
块大小: 469, 元数据:{'source': './demo.py'}
块大小: 452, 元数据:{'source': './demo.py'}
块大小: 490, 元数据:{'source': './demo.py'}
块大小: 497, 元数据:{'source': './demo.py'}
块大小: 492, 元数据:{'source': './demo.py'}
块大小: 496, 元数据:{'source': './demo.py'}
块大小: 497, 元数据:{'source': './demo.py'}
块大小: 498, 元数据:{'source': './demo.py'}
块大小: 491, 元数据:{'source': './demo.py'}
块大小: 466, 元数据:{'source': './demo.py'}
块大小: 348, 元数据:{'source': './demo.py'}递归分割会尽可能从大分块上保证数据的连续性,打印其中一个分块,示例如下:
python
print(chunks[2].page_content)输出内容:
python
def split_text(self, text: str) -> List[str]:
"""Split incoming text and return chunks."""
# First we naively split the large input into a bunch of smaller ones.
separator = (
self._separator if self._is_separator_regex else re.escape(self._separator)
)
splits = _split_text_with_regex(text, separator, self._keep_separator)
_separator = "" if self._keep_separator else self._separator
return self._merge_splits(splits, _separator)中文场景下的递归分割
RecursiveCharacterTextSplitter 默认配置的分隔符均是英文场合下的,在中文场合下,除了换行/空格,一般还有更加复杂的语句结束判断标识,例如: 。 、 ! 、 ? 等标识符,如果想更好去切割 中英文文档 ,可以考虑重设分隔符列表(或者继承该类进行重写)。
不同符号的优先级如下:
- \n\n :换行两次优先级最高。
- \n :普通换行符优先级其次,一般切断后都不会导致上下文语义丢失。
- 。|!|? :中文中句号、感叹号、问号一般都表示句子结束,也可以尝试切割。
- .\s|!\s|?\s :对应到英文中就是点、感叹号、问号,并且标准的英文写法在这些符号后通常需要添加空格。
- ;|;\s :其次就是中英文的分段,在英文分段后一般会添加空格;
- ,|,\s :接下来优先级是中英文中的逗号,逗号一般都表示句子语义还未结束,所以一般不切割,除非文本块仍然超过大小。
- :空格和空字符串是优先级最低的切割符号之一,特别是在英文场合中,有时候两个词才有意义,切割出来意义就不大,而空字符串则是优先级最低的切割符,空字符串会把中文切割成单个汉字,在英文场合下切割成单个字母,几乎完全丢失语义。
更改后的示例如下:
python
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.创建加载器和文本分割器
loader = UnstructuredMarkdownLoader("./项目API文档.md")
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
"。|!|?",
"\.\s|\!\s|\?\s", # 英文标点符号后面通常需要加空格
";|;\s",
",|,\s",
" ",
""
],
is_separator_regex=True,
chunk_size=500,
chunk_overlap=50,
add_start_index=True,
)
# 2.加载文档与分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
# 3.输出信息
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据: {chunk.metadata}")
输出示例:
python
块大小: 251, 元数据: {'source': './项目API文档.md', 'start_index': 0}
块大小: 451, 元数据: {'source': './项目API文档.md', 'start_index': 246}
块大小: 490, 元数据: {'source': './项目API文档.md', 'start_index': 699}
块大小: 305, 元数据: {'source': './项目API文档.md', 'start_index': 1165}
块大小: 435, 元数据: {'source': './项目API文档.md', 'start_index': 1472}
块大小: 497, 元数据: {'source': './项目API文档.md', 'start_index': 1859}
块大小: 237, 元数据: {'source': './项目API文档.md', 'start_index': 2359}
块大小: 483, 元数据: {'source': './项目API文档.md', 'start_index': 2598}
块大小: 486, 元数据: {'source': './项目API文档.md', 'start_index': 3092}
块大小: 438, 元数据: {'source': './项目API文档.md', 'start_index': 3580}
块大小: 293, 元数据: {'source': './项目API文档.md', 'start_index': 4013}
块大小: 498, 元数据: {'source': './项目API文档.md', 'start_index': 4261}
块大小: 463, 元数据: {'source': './项目API文档.md', 'start_index': 4712}
块大小: 438, 元数据: {'source': './项目API文档.md', 'start_index': 5129}
块大小: 474, 元数据: {'source': './项目API文档.md', 'start_index': 5569}
块大小: 93, 元数据: {'source': './项目API文档.md', 'start_index': 6018}
块大小: 464, 元数据: {'source': './项目API文档.md', 'start_index': 6113}
块大小: 478, 元数据: {'source': './项目API文档.md', 'start_index': 6579}
块大小: 379, 元数据: {'source': './项目API文档.md', 'start_index': 7035}
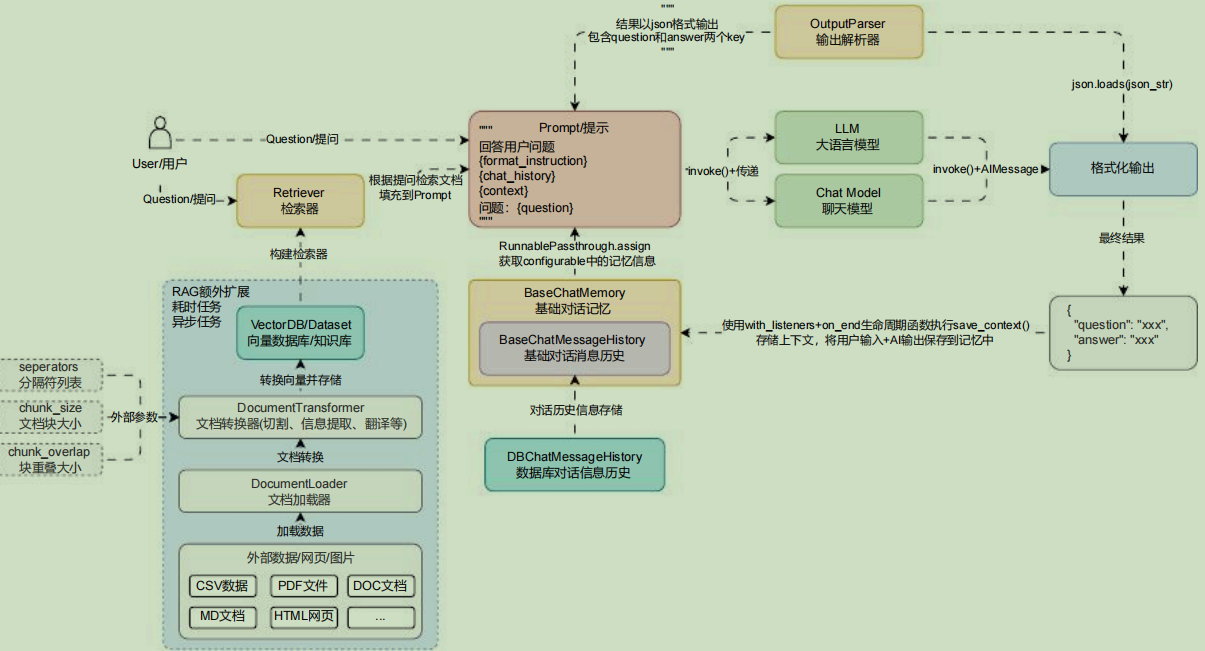
块大小: 489, 元数据: {'source': './项目API文档.md', 'start_index': 7416}在 LLMOps 项目中,具体的文本分割逻辑由创建知识库的用户决定,所以 分隔符 、 文档块大小 和 块重叠大小 均是通过外部传递,然后再生成 RecursiveCharacterTextSplitter 分割器,而文档加载器使用 扩展名 + 通用非结构化文件加载器 来实现,更新后的聊天机器人的架构运行流程如下:
语义文档分割器与其他内容分割器的使用
语义文档分割器的使用与背景
在前面课时中使用的文档分割器都是使用 特定字符 对文本进行拆分,这种拆分模式虽然考虑了文档中的上下文切断的问题,但是并没有考虑句子之间的语义相似性,如果有一篇长文本,需要将其分割成语义相关的块,以便更好地理解和处理,这个时候可以使用 LangChain 中的 语义相似性分割器(SemanticChunker) 来实现这个任务。
语义相似性分割器 目前仍处于实验性,这个类目前位于 langchain_experimental 包中(这个包中的类与方法未来极大概率会发生变更,需要谨慎使用),安装命令:
php
pip install -Uqq langchain_experimentalSemanticChunker 在使用上和其他的文档分割器存在一些差异,并且该类并没有继承TextSplitter ,实例化参数含义如下:
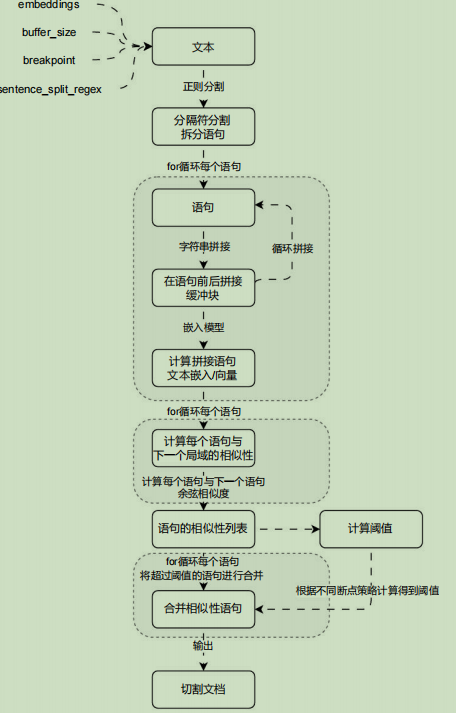
- embeddings :文本嵌入模型,在该分类器底层使用向量的 余弦相似度 来识别语句之间的相似性。
- buffer_size :文本缓冲区大小,默认为 1,即在计算相似性时,该文本会叠加前后各 1 条文本,如果不够则不叠加(例如第 1 条和最后 1 条)。
- add_start_index :是否添加起点索引,默认为 False。
- breakpoint_threshold_type :断点阈值类型,默认为 percentile 即百分位
- breakpoint_threshold_amount :端点阈值金额/得分。
- number_of_chunks :分割后的文档块个数,默认为 None。
- sentence_split_regex :句子切割正则,默认为 (?<=.?!)\s+,即以英文的点、问号、感叹号切割语句,不同的文档需要传递不同的切割正则表达式。
例如想要将 科幻短篇.txt 按照语义切割成 10 个文档,可以使用如下代码示例:
python
import dotenv
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
# 1.构建加载器和文本分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = SemanticChunker(
embeddings=OpenAIEmbeddings(model="text-embedding-3-small"),
sentence_split_regex=r"(?<=[。?!])",
number_of_chunks=10,
)
# 2.加载文本与分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据: {chunk.metadata}")输出内容:
python
块大小: 201, 元数据: {'source': './科幻短篇.txt'}
块大小: 25, 元数据: {'source': './科幻短篇.txt'}
块大小: 31, 元数据: {'source': './科幻短篇.txt'}
块大小: 46, 元数据: {'source': './科幻短篇.txt'}
块大小: 203, 元数据: {'source': './科幻短篇.txt'}
块大小: 19, 元数据: {'source': './科幻短篇.txt'}
块大小: 91, 元数据: {'source': './科幻短篇.txt'}
块大小: 466, 元数据: {'source': './科幻短篇.txt'}
块大小: 116, 元数据: {'source': './科幻短篇.txt'}
块大小: 0, 元数据: {'source': './科幻短篇.txt'}SemanticChunker 的原理其实非常简单,核心思想是将文档拆分成独立的每一句,接下来根据传递的缓冲大小前后拼接字符串,然后计算拼接后的新字符串的文本嵌入/向量,然后计算这些文本的相似度,并根据传入的分块数+断点类型计算得到一个阈值,最后将相似度超过某个阈值的合并到一起,从而实现相似度分割。
目前在 SemanticChunker 底层检测相似度阈值的方法有 4 种: 百分位数(默认) 、 标准差 、 四分位数 、梯度 。
其他文档分割器的使用
除了上述的文档分割器,在 LangChain 中还封装了一些其他场合下的分割器(使用频率不高),涵盖了:基于 HTML 标题/段的分割器、Markdown 标题分割器、递归 JSON 分割器、基于 Token 计数的分割器等,使用起来和字符文本分割器非常接近。
LangChain 文档分割器翻译文档:https://imooc-langchain.shortvar.com/docs/how_to/#检索器
HTML/Markdown 标题/段分割器
在 LangChain 中设计了针对 HTML 类型文档的分割器------ HTMLHeaderTextSplitter 与HTMLSectionSplitter ,分割器的作用如下:
- HTMLHeaderTextSplitter :在 HTML 文档中按照元素级别进行分割,查找出每一块文本的内容与其所有关联的标题,并为每个相关的标题块提供元数据(顺序往上逐层查找,直到找到所有嵌套层级的标题)。
- HTMLSectionSplitter :在 HTML 文档中按照元素级别进行分割,查找出每一块文本的内容及其副标题(顺序往上查找,找到最近的副标题则停止)。
理解起来其实也非常简单,层级关系并不是嵌套,而是看目录导航,例如在课件的左侧可以看到对应的导航,分别是一级标题、二级标题和三级标题,这块内容在哪个标题内下使用,就可以看成是被嵌套到哪个标题下,和实际的 HTML 层级没有任何关系。
如下,红圈的部分被嵌套的 语义文档分割器与其他文档分割器的使用 - 02. 其他文档分割器的使用 - 2.1HTML/Markdown 标题/段分割器 下。

使用示例:
python
from langchain_text_splitters import HTMLHeaderTextSplitter
html_string = """
<!DOCTYPE html>
<html>
<body>
<div>
<h1>标题1</h1>
<p>关于标题1的一些介绍文本。</p>
<div>
<h2>子标题1</h2>
<p>关于子标题1的一些介绍文本。</p>
<h3>子子标题1</h3>
<p>关于子子标题1的一些文本。</p>
<h3>子子标题2</h3>
<p>关于子子标题2的一些文本。</p>
</div>
<div>
<h3>子标题2</h2>
<p>关于子标题2的一些文本。</p>
</div>
<br>
<p>关于标题1的一些结束文本。</p>
</div>
</body>
</html>
"""
headers_to_split_on = [
("h1", "一级标题"),
("h2", "二级标题"),
("h3", "三级标题"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits)输出内容:
python
[
Document(page_content='标题1'),
Document(metadata={'一级标题': '标题1'}, page_content='关于标题1的一些介绍文本。 \n子标
题1 子子标题1 子子标题2'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1'}, page_content='关于子标
题1的一些介绍文本。'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1', '三级标题': '子子标题1'},
page_content='关于子子标题1的一些文本。'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1', '三级标题': '子子标题2'},
page_content='关于子子标题2的一些文本。'),
Document(metadata={'一级标题': '标题1'}, page_content='子标题2'),
Document(metadata={'一级标题': '标题1', '三级标题': '子标题2'}, page_content='关于子标
题2的一些文本。'),
Document(metadata={'一级标题': '标题1'}, page_content='关于标题1的一些结束文本。')
]另外在 LangChain 中除了 HTML 类型的文档可以使用这套分割规则,Markdown 类的文件也有类似的分割规则,可以使用 Markdown 标题分割器------ MarkdownHeaderTextSplitter 完成同样的文档分割。
详细文档:https://imooc-langchain.shortvar.com/docs/how_to/markdown_header_metadata_splitter/
递归 JSON 分割器
对于 JSON 类的数据,在 LangChain 中也封装了一个递归 JSON 分割器------RecursiveJsonSplitter ,这个分割器会按照深度优先的方式遍历 JSON 数据,并构建较小的 JSON 块,而且尽可能保持嵌套 JSON 对象完整,但如果需要保持文档块大小在最小块大小和最大块大小之间,则会将它们拆分。
在 JSON 数据中,如果值不是嵌套的 JSON,而是一个非常大的字典,则不会对该字符串进行拆分,可以配合 递归字符文本分割器 强制性拆分字符串,确保块大小在限制的范围内。
RecursiveJsonSplitter 的参数非常简单,只需传递 max_chunk_size 和 min_chunk_size(可选)即可。
例如这里有一个很大的 json 文本(https://api.smith.langchain.com/openapi.json),使用递归 JSON 分割器对其进行拆分,如下:
python
import requests
from langchain_text_splitters import RecursiveJsonSplitter
# 1.获取并加载json
url = "https://api.smith.langchain.com/openapi.json"
json_data = requests.get(url).json()
# 2.递归JSON分割器
text_splitter = RecursiveJsonSplitter(max_chunk_size=300)
# 3.分割json数据并创建文档
json_chunks = text_splitter.split_json(json_data=json_data)
chunks = text_splitter.create_documents(json_chunks)
for chunk in chunks[:3]:
print(chunk)输出内容:
python
page_content='{"openapi": "3.1.0", "info": {"title": "LangSmith", "version":
"0.1.0"}, "paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracersessions"], "summary": "Read Tracer Session", "description": "Get a specific
session."}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"operationId":
"read_tracer_session_api_v1_sessions__session_id__get", "security": [{"API Key":
[]}, {"Tenant ID": []}, {"Bearer Auth": []}]}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"parameters":
[{"name": "session_id", "in": "path", "required": true, "schema": {"type":
"string", "format": "uuid", "title": "Session Id"}}, {"name": "include_stats",
"in": "query", "required": false, "schema": {"type": "boolean", "default": false,
"title": "Include Stats"}}, {"name": "accept", "in": "header", "required": false,
"schema": {"anyOf": [{"type": "string"}, {"type": "null"}], "title":
"Accept"}}]}}}}'RecursiveJsonSplitter 分割器的运行流程其实也非常简单,这个分割器会按照 深度优先 的方式遍历整个 JSON,即一层一层往下读取数据,然后将对应的数据提取生成一个新的 JSON,直到数据大小接近块大小(极端情况下还是会超过预设的块大小,例如 JSON 数据中的 Key 很长,亦或者 Value 很长,甚至出现单条数据就超过了预设大小)。
所以如果要使用该分割器,一般会结合 RecursiveCharacterTextSplitter 降低单条数据超过预设大小的风险,思路就是将递归 JSON 分割器生成的文档列表进行二次分割。
基于标记的分割器
对于大语言模型来说,上下文的长度计算应该通过 token 进行计算,而不是通过字符长度 len() 函数,在 OpenAI 的 GPT 模型中,一个汉字大约等于 1.5 个 Token,一个单词为 1 个 Token,所以使用len() 函数可能会导致很大的误差。
在 LLM 应用开发中,不同的模型对于 Token 的计算并不相同,但是可以使用 tiktoken 这个包来大致计算文本的 token 数,误差也相对较小,首先安装 tiktoken 包,命令如下:
python
pip install -U tiktoken接下来定义一个基于 tiktoken 的长度计算函数,如下:
python
def calculate_token_count(query: str) -> int:
"""计算传入文本的token数"""
encoding = tiktoken.encoding_for_model("text-embedding-3-large")
return len(encoding.encode(query))然后将该函数传递给分割器的 length_function ,例如前几节课时的案例,修改优化后,代码如下:
python
import tiktoken
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.定义加载器和文本分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
"。|!|?",
"\.\s|\!\s|\?\s", # 英文标点符号后面通常需要加空格
";|;\s",
",|,\s",
" ",
""
],
is_separator_regex=True,
chunk_size=500,
chunk_overlap=50,
length_function=calculate_token_count,
)
# 2.加载文档并执行分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
# 3.循环打印分块内容
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据: {chunk.metadata}")输出内容:
python
块大小: 334, 元数据: {'source': './科幻短篇.txt'}
块大小: 409, 元数据: {'source': './科幻短篇.txt'}
块大小: 372, 元数据: {'source': './科幻短篇.txt'}
块大小: 95, 元数据: {'source': './科幻短篇.txt'}在 LangChain 中,除了传递 length_function 方法,还可以直接调用分割器的类方法from_tiktoken_encoder() 来快速创建基于 tiktoken 分词器的文本分割器(确保分词器使用的模型和开发的 LLM 保持一致即可),例如:
python
RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=500,
chunk_overlap=50,
separators=[
"\n\n",
"\n",
"。|!|?",
"\.\s|\!\s|\?\s", # 英文标点符号后面通常需要加空格
";|;\s",
",|,\s",
" ",
""
],
is_separator_regex=True,
)自定义 LangChain 文档分割器技巧
自定义文档分割器
在 LangChain 中,如果内置的文档分割器均没办法完成需求,还可以根据特定的需求实现自定义文档分割器(一般极少),实现的方法也非常简单,继承文本分割器基类 TextSplitter ,在构造函数中传递相关参数,然后实现 split_text() 方法即可。
例如,实现一个根据传递的分隔符实现对文档进行片段划分,并且将分割出来的文档片段转换成 N 个关键词的分割器,代码示例:
python
from typing import List
import jieba.analyse
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_text_splitters import TextSplitter
class CustomTextSplitter(TextSplitter):
"""自定义文本分割器"""
def __init__(self, seperator: str, top_k: int = 10, **kwargs) -> None:
super().__init__(**kwargs)
self._seperator = seperator
self._top_k = top_k
def split_text(self, text: str) -> List[str]:
"""分割传入的文本为字符串列表"""
split_texts = text.split(self._seperator)
text_keywords = []
for split_text in split_texts:
text_keywords.append(
jieba.analyse.extract_tags(split_text, self._top_k)
)
return [",".join(keywords) for keywords in text_keywords]
# 1.创建加载器与分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = CustomTextSplitter("\n\n")
# 2.加载文档并分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
# 3.循环遍历文档信息
for chunk in chunks:
print(f"文档库块内容:{chunk.page_content}")生成内容:
python
文档库块内容:星际,穿越,标题
文档库块内容:概要
文档库块内容:星系,李昂,文明,这个,高度发达,宇航员,星际,灭绝,一个,穿越
文档库块内容:迷航,星际,第一章
文档库块内容:飞船,李昂,观察窗,浩瀚,星空,宇航员,经验丰富,星系,与众不同,穿越
文档库块内容:李昂,星空,睁开眼,眩晕,飞船,星系,扭曲,闪过,发现自己,陌生
文档库块内容:异星,第二章,文明
文档库块内容:李昂,文明,行星,一颗,高度发达,小行星,星球,灭绝,星系,这颗
文档库块内容:赛跑,第三章,时间
文档库块内容:寻找,李昂,科技知识,小行星,飞船,星系,撞击,紧迫,自己,阻止
文档库块内容:火花,第四章,智慧
文档库块内容:能量,李昂,场来,计划,小行星,解决方案,撞击,这个,轨道,科学家
文档库块内容:第五章,危机,希望
文档库块内容:星球,矿物,能量,李昂,夜以继日,小行星,蕴藏,罕见,深处,科学家
文档库块内容:第六章,星际,救援
文档库块内容:小行星,成功,矿物,能量,李昂,撞击,带回,采集,勇敢,实验室
文档库块内容:归途,第七章
文档库块内容:李昂,遗迹,热烈欢迎,星系,隐藏,感激,解除,通往,这个,探索
文档库块内容:第八章,重逢,星际
文档库块内容:李昂,归属感,归途,星系,穿越,踏上,冒险,告别,前所未有,平静
文档库块内容:第九章,开始
文档库块内容:李昂,星球,星际,之间,一个,开启,激励,全新,无数,英雄
文档库块内容:第十章,星际,使者
文档库块内容:文明,李昂,旅程,使者,美好,宇宙,探索,交流,挑战,面对
文档库块内容:慕课
文档库块内容:梦工厂,程序员RAG 文档分割/分块总结
在前面的课时中,我们学习过 字符文本分割器 、 递归字符文本分割器 、 Html标题/段分割器 、 语义分割器等多种文本分割器类型,这也是目前 RAG 分块 Chunk 的 4 种策略:
- 固定大小分块 :这是最常见的分块方法,通过设定块的大小和是否有重叠来决定分块。这种方法简单直接,不需要使用任何NLP库,因此计算成本低且易于使用,例如 CharacterTextSplitter ,亦或者直接循环遍历固定大小拆分。
- 基于结构的分块 :常见的 HTML、MARKDOWN 格式,或者其他可以有明确结构格式的文档。这种可以借助"结构感知"对文档分块,充分利用文档文本意外的信息,类似 LangChain 中的HTMLHeaderTextSplitter 等。
- 基于语义的分块 :这种策略旨在确保每个分块包含尽可能多的语义独立信息。可以采用不同的方法,如标点符号、自然段落、或者NLTK、Spicy 等工具包来实现语义分块,或者 Embeddingbased 方法,例如 LangChain 中的 SemanticChunker 等。
- 递归分块 :递归分块使用一组分隔符,以分层和迭代的方式将输入文本划分为更小的块。如果最初分割文本没有产生所需大小或结构的块,则该方法会继续递归地分割直到满足条件,例如LangChain 中的 RecursiveCharacterTextSplitter 等。
这些策略各有优势和适用场景,选择合适的分块策略取决于具体的应用需求和数据特性。很遗憾,到目前为止还没有什么是最优的策略,但这也是很难有一个产品一统天下的原因。同时策略可以组合使用,并不是一类文档只能用一种策略。
对于一个 RAG 场景,分成四个主要阶段: 预检索 、 检索 、 后检索 和 生成 ,其中 分块 是 预检索阶段的策略,如果在 分块 阶段尝试了上述 4 种策略均没有很好的效果,或许就不应该采用 RAG 的策略,而是使用 微调 的方式,让这部分知识成为模型永久的记忆,效果可能会更好!
非分割类型的文档转换器使用技巧
DocumentTransformer 组件
在 LangChain 中,另一种非分割类型的文档转换器,这类转换器也是传递 文档列表 并返回 文档列表 ,一般是将某种文档按照需求转换成另外一种格式(例如:翻译文档、文档重排、HTML 转文本、文档元数据提取、文档转问答等)。
这类文档转换器由于接收 文档列表 ,返回的也是 文档列表 ,所以可以在 LLM 应用中任何存在 文档列表的地方使用,例如下方的 LLM 应用架构流程图中的 文档加载 、 文档切割 、 检索器检索 的环节交互数据都是 文档列表 ,所以这几个环节都可以添加文档转换器组件。
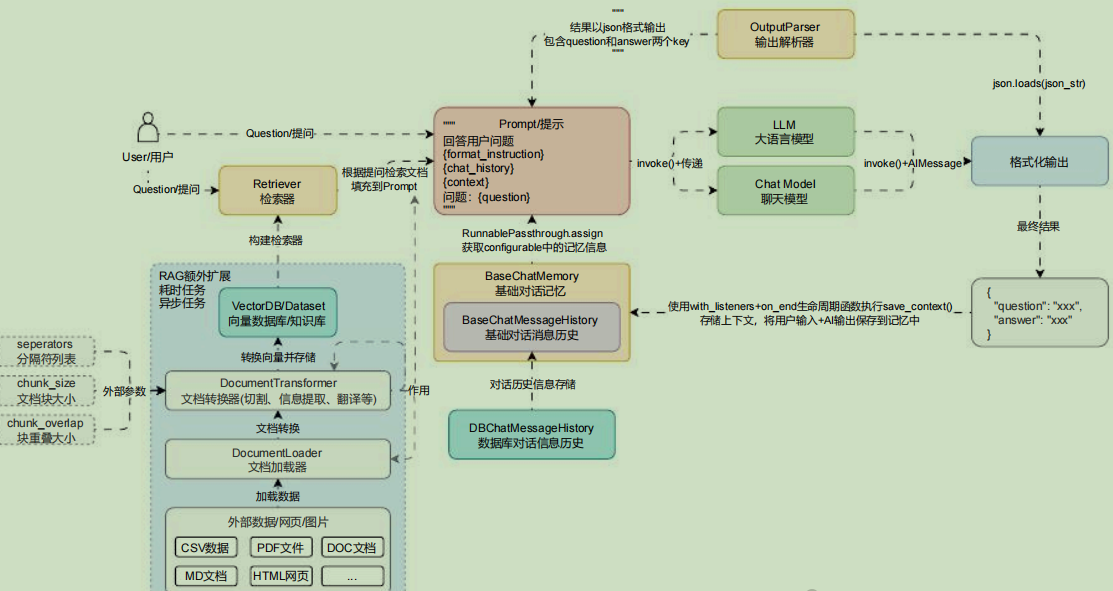
在 LangChain 中,使用文档转换器技巧非常简单,按照对应组件的构造函数进行传参,然后调用transformer_documents 函数即可完成对文档的快速转换(每个转换器生成的格式不一样,需查看文档了解生成内容详情)。
LangChain 封装的文档转换器组件:https://imooc-langchain.shortvar.com/docs/integrations/document_transformers/。
问答转换器
在 RAG 的外挂知识库中,向量存储知识库中使用的文档通常以叙述或对话格式存储。但是,绝大部分用户的查询都是问题格式,所以如果我们在对文档进行向量化之前先将其转换为 问答格式 ,可以在一定程度上增加检索相关文档的可能性,降低检索不相关文档的可能性。
这个技巧也是 RAG 应用开发中常见的一种优化策略,即将原始数据转换成 QA 数据后进行存储,除此之外,对于绝大部分 LLM 的微调,使用的也是 QA问答数据 也可以考虑使用该问答转换器进行转换。
在 LangChain 中封装了 Doctran 库并实现了 DoctranQATransformer 类可以快捷实现该功能,这个库底层使用 OpenAI 的函数回调来实现对问答数据的提取,首先安装该库:
python
pip install -U doctran假设有一段如下的文本,需要转换成 QA数据 :

使用示例:
python
import dotenv
from langchain_community.document_transformers import DoctranQATransformer
from langchain_core.documents import Document
dotenv.load_dotenv()
# 1.构建文档列表
page_content = """..."""
documents = [Document(page_content=page_content)]
# 2.构建问答转换器并转换
qa_transformer = DoctranQATransformer(openai_api_model="gpt-3.5-turbo-16k")
transformer_documents = qa_transformer.transform_documents(documents)
# 3.输出内容
for qa in transformer_documents[0].metadata.get("questions_and_answers"):
print(qa)输出内容:
python
{'question': '文件日期是什么?', 'answer': '2023年7月1日'}
{'question': '文件主题是什么?', 'answer': '各种话题的更新和讨论'}
{'question': '谁是IT部门的网络安全负责人?', 'answer': 'John Doe(电子邮件:
john.doe@example.com)'}
{'question': '如果发现安全风险或事件,应该向谁报告?', 'answer': '专门的团队,联系邮箱为
security@example.com'}
{'question': '谁在客户服务方面表现出色?', 'answer': 'Jane Smith(社保号:049-45-
5928)'}
{'question': '员工福利计划的开放报名期是什么时候?', 'answer': '即将到来'}
{'question': '人力资源代表的联系信息是什么?', 'answer': 'Michael Johnson(电话:418-
492-3850,电子邮件:michael.johnson@example.com)'}
{'question': '谁在管理社交媒体平台方面做出了杰出努力?', 'answer': 'Sarah Thompson(电
话:415-555-1234)'}
{'question': '产品发布活动的日期是什么时候?', 'answer': '7月15日'}
{'question': '谁在研发部门担任项目负责人角色?', 'answer': 'David Rodriguez(电子邮件:
david.rodriguez@example.com)'}
{'question': '研发头脑风暴会议的日期是什么时候?', 'answer': '7月10日'}翻译转换器
在 RAG 应用开发中,将文档通过嵌入/向量的方式进行比较的好处在于能跨语言工作,例如: 你好,世界! 、 Hello, World! 和 こんにちは、世界! 分别是 中英日 三国的语言,但是因为语义相近,所以在向量空间中的位置也是非常接近的。
当一个 RAG 应用需要跨语言工作时,一般有两种策略:
- 在将文档切块并嵌入存储到向量数据库时,同时将文档翻译成多国语言并进行相同的操作。
- 在进行检索操作时,将检索出来的文档执行翻译功能,然后使用翻译后的文档。
这两种策略都涉及到一个功能,就是 文档的翻译 ,或者是说将 文档 转换成另外一种形式的 文档 ,这类操作其实和 文档转换器 的作用一模一样,所以可以考虑使用该组件来实现这个功能,LangChain 中针对翻译的转换器就提供了不少,例如 Doctran 。
首先执行命令安装 doctran ,这是一个文本翻译库,底层使用 OpenAI 的函数调用功能来在不同语言之间实现翻译:
python
pip install -U doctran接下来就可以使用 DoctranTextTranslator 组件来实现对文档的快速中英文转换,示例如下:
python
import dotenv
from langchain_community.document_transformers import DoctranTextTranslator
from langchain_core.documents import Document
dotenv.load_dotenv()
# 1.构建文档列表
page_content = """..."""
documents = [Document(page_content=page_content)]
# 2.构建翻译转换器并翻译
text_translator = DoctranTextTranslator(openai_api_model="gpt-3.5-turbo-16k")
translator_documents = text_translator.transform_documents(documents)
# 3.输出翻译内容
print(translator_documents[0].page_content)