1.核心组件 - 消息(Messages)
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出,以及可能与对话关联的任何其它的上下文或元数据。
1.1. LLM消息结构
每条消息都有一个角色和内容,以及因LLM 的不同而不同的附加元数据。
- 消息角色(Role):用来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。
|-----------------|----------------------------------------------|
| 角色 | 描述 |
| system(系统⻆⾊) | 用于告诉聊天模型如何行为并提供额外的上下文。并非所有聊天模型提供商都支持 |
| user(用户角色) | 表示用户与模型交互的输入,通常以文本或其他交互式输入的形式 |
| assistant(助理角色) | 表示来自模型的响应,其中可以包括文本或调用工具的请求。 |
| tool(工具角色) | 用于在检索外部数据或将工具调用的结果传递回模型的消息。与支持工具调用的聊天模型一起使用。 |
-
消息内容(Content):表示多模态数据(例如,图像、音频、视频)的消息文本或字典列表的内容。内容的具体格式可能因底层不同的LLM 而异。目前,大多数模型都支持文本作为主要内容类型,对多模态数据的支持仍然有限。
-
消息其他元数据(Additional metadata) :
|------------|--------------------------------|
| 元数据 | 描述 |
| ID | 消息描述符 |
| Name | 名称允许区分具有相同角色的不同实体。并非所有型号都支持此功能 |
| Metadata | 有关消息的其他信息,例如时间戳、令牌使用情况等。 |
| Tool Calls | 模型发出的一个或多个工具的调用请求 |下面展示一个OpenAI的格式消息列表:
python
[
{
"role": "user",
"content": "Hello , how are you?",
},
{
"role": "assistant",
"content": "I 'm doing well , thank you for asking .",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]LangChain接受下面的格式作为聊天模型的输入:
python
chat_model.invoke(
[
{"role":"user", "content":"Hello, how are you?",},
{"role":"assistantr", "content":"I 'm doing well , thank you for asking."},
{"role":"user", "content":"Can you tell me a joke?",},
]
)1.2. LangChain消息
LangChain提供了一种同一的消息格式,可以快聊天模型使用,允许用户使用不同的聊天模型,而无需担心每个模型提供商使用的消息格式的具体细节。例如:
python
openai_model = init_chat_model("gpt-4o-mini", model_provider="")
anthropic_model = init_chat_model("claude-3-5-sonnet-latest", model_provider="")
deepseek_model = init_chat_model("deepseek-chat", model_provider=" ")
google_genai_model = init_chat_model("gemini-2.5-flash", model_provider="")
model = init_chat_model(...)这些模型提供商不同,但对于其输入和输出,统一使用LangChain 的消息格式。LangChain 消息格式主要分为五种,分别是:
|---------------|------------------|-----------------------------------------------------------------|
| 消息类型 | 对应角色 | 描述 |
| SystemMessage | 对应system 系统角色 | 用于启动AI 模型的行为并提供额外的上下文,例如指示模型采用特定角色或设定对话的基调(例如,"你是一个后端开发的专家")。 |
| HumanMessage | 对应user 用户角色 | 人类消息表示用户与模型交互的输入。 大多数聊天模型都希望用户输入采用文本形式。 |
| AIMessage | 对应assistant 助理角色 | 这是来自模型的响应,其中可以包括文本或调用工具的请求。它还可能包括其他媒体类型,如图像、音频或视频---尽管这目前仍然不常见。 |
| ToolMessage | 对应tool 工具角色 | 这表示一条角色为"tool"的消息,其中包含调用工具的结果 |
这几个消息类型,我们已经全部见过!它们都是LangChain BaseMessage 的子类,全部是作为 LangChain 聊天模型的输入和输出!!
1.2.1. BaseMessages抽象消息类
class langchain_core.messages.base.BaseMessage是作为LangChain聊天模型的输入和输出.
参数如下:
- content:消息的字符串内容。
- additional_kwargs:与消息关联的其他有效负载数据。对于来自AI 的消息,可能包括模型提供程序编码的工具调用。
- reseponse_metadata:响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
- type:消息的类型。必须是消息类型唯一的字符串。此字段的目的是在对消息进行反序列化时方便地识别消息类型。
- name:消息名称,为消息提供一个人类可读的名称。该字段的使用是可选的,是否使用它取决于模型实现。
- id:消息的可选唯一标识符。理想情况下,这应该由创建消息的提供者/模型提供。
python
content='我是DeepSeek,由深度求索公司创造的AI助手,乐于解答你的问题!'
additional_kwargs={'refusal': None}
response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 8, 'total_tokens': 27, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 8}, 'model_provider': 'openai', 'model_name': 'deepseek-v4-flash', 'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402',
'id': '52b1cbe2-bbe2-4f1d-a01d-2123f84fd193', 'finish_reason': 'stop', 'logprobs': None} id='lc_run--019e3f4f-ff24-7b61-8065-5f002b83c54f-0' tool_calls=[] invalid_tool_calls=[]
usage_metadata={'input_tokens': 8, 'output_tokens': 19, 'total_tokens': 27, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}内置方法:
- pretty_print() -> None:打印消息的漂亮表示
- pretty_repr(html: bool = False)- >str: 获取消息的漂亮表示。
- text() - > str: 获取消息的文本内容
1.2.2. 对话模式
大多数对话都以设置对话上下文的系统消息开始。接下来是包含用户输入的用户消息,然后是包含模型响应的助手消息。
1.3. 缓存历史消息
1.3.1. 多轮对话
在与大型语言模型交互的过程中,我们常常体验到与智能助手进行连贯多轮对话的便利性。但目前我们的系统还不支持此功能,代码如下:
python
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat")
print(model.invoke("你好,我叫李华!"))
print(model.invoke("我叫什么名字?"))运行结果:
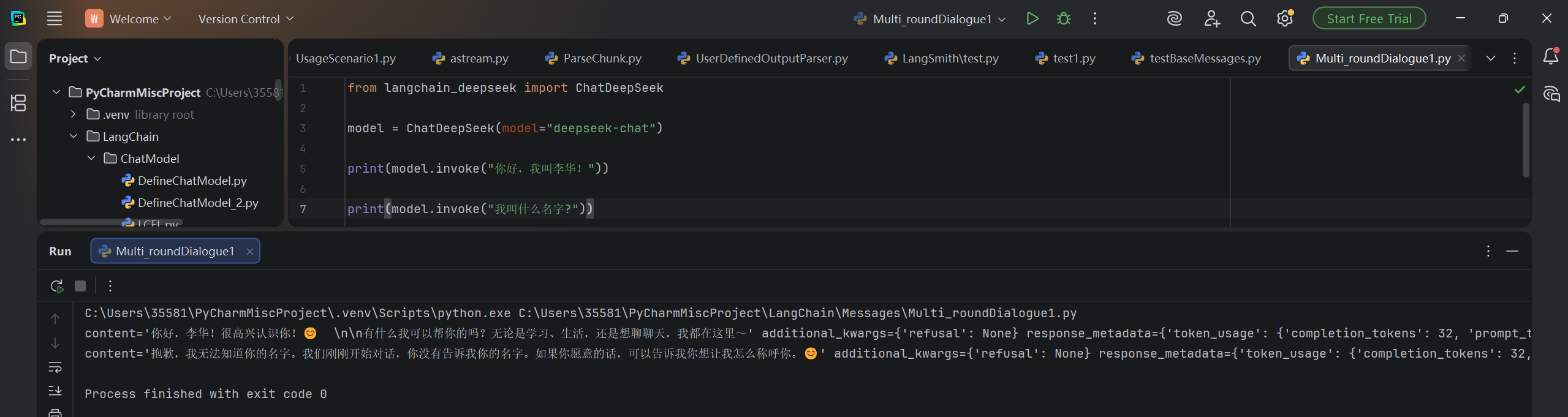
可以发现,聊天模型并不认识我们,更别说支持更多轮的对话了~
稍作修改,让我们将AI 回复给我们的响应跟着新的用户消息一起发给聊天模型试试。
python
from langchain_deepseek import ChatDeepSeek
from langchain_core .messages import HumanMessage ,AIMessage
model = ChatDeepSeek(model="deepseek-chat")
#
# print(model.invoke("你好,我叫李华!"))
#
# print(model.invoke("我叫什么名字?"))
messages = [
HumanMessage("你好,我叫李华!"),
AIMessage("你好,李华!"),
HumanMessage("我叫什么名字?")
]
model.invoke(messages).pretty_print()运行结果:
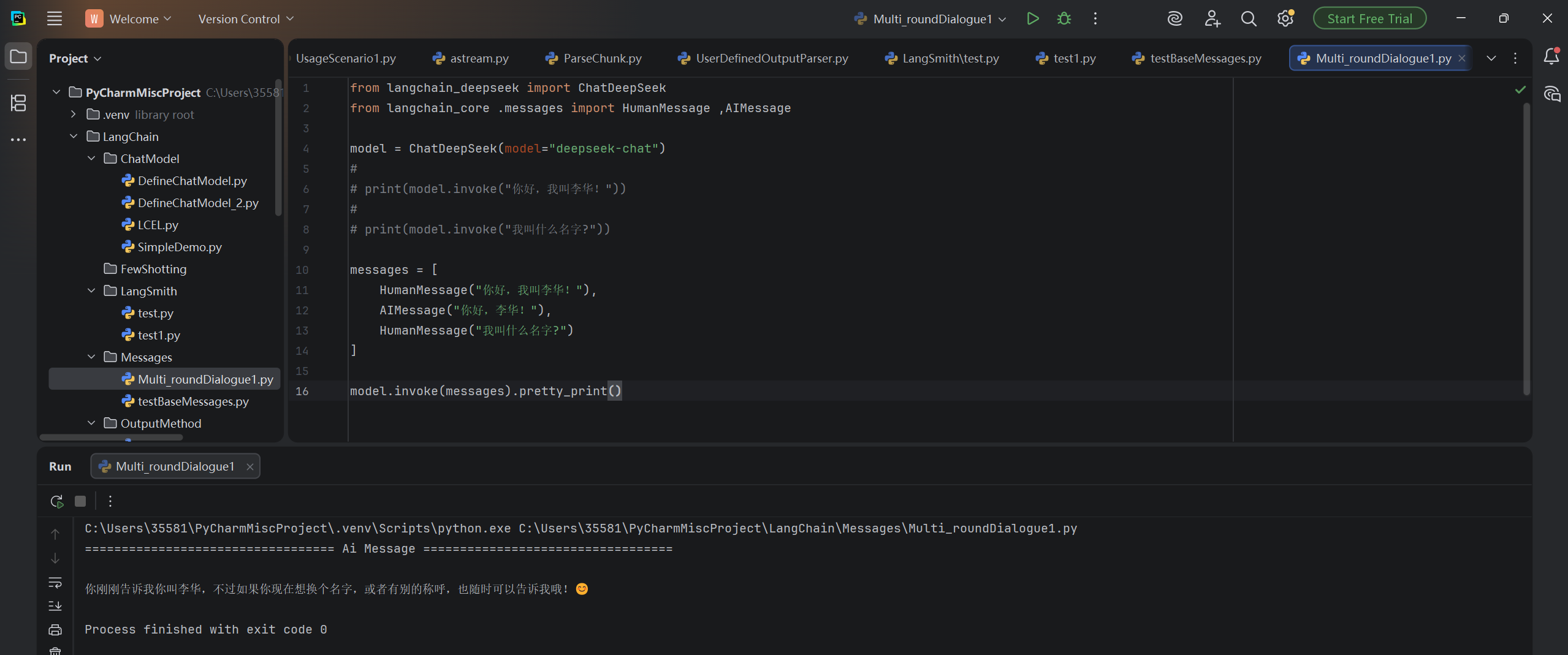
从结果可知,只要将历史消息,重新发送给聊天模型,那么就可以实现多轮对话的功能。
1.3.2. 内存缓存
那么对于历史消息的管理就显得尤为重要。在LangChain 老版本中,可以使用RunnableWithMessageHistory 消息历史类来包装另一个Runnable 并为其管理聊天消息历史记录。它将跟踪模型的输入和输出,并将其存储在某个数据存储中。未来的交互将加载这些消息,并将其作为输入的一部分传递给链。
代码如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core .messages import HumanMessage ,AIMessage
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core .runnables .history import RunnableWithMessageHistory
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat")
store = {}
# 接受一个 seesion_id 并返回一个消息历史对象
# 这个 session_id 用于区分不同的对话,并作为配置的一部分再调用新链时传入
def get_session_history(session_id: str)->BaseChatMessageHistory:
if session_id not in store:
# InMemoryChatMessageHistory() 将消息存储在内存列表中。
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装model,管理来哦天消息历史记录
with_message_history = RunnableWithMessageHistory(model, get_session_history)
config = {"configurable": {"session_id": "1 "}}
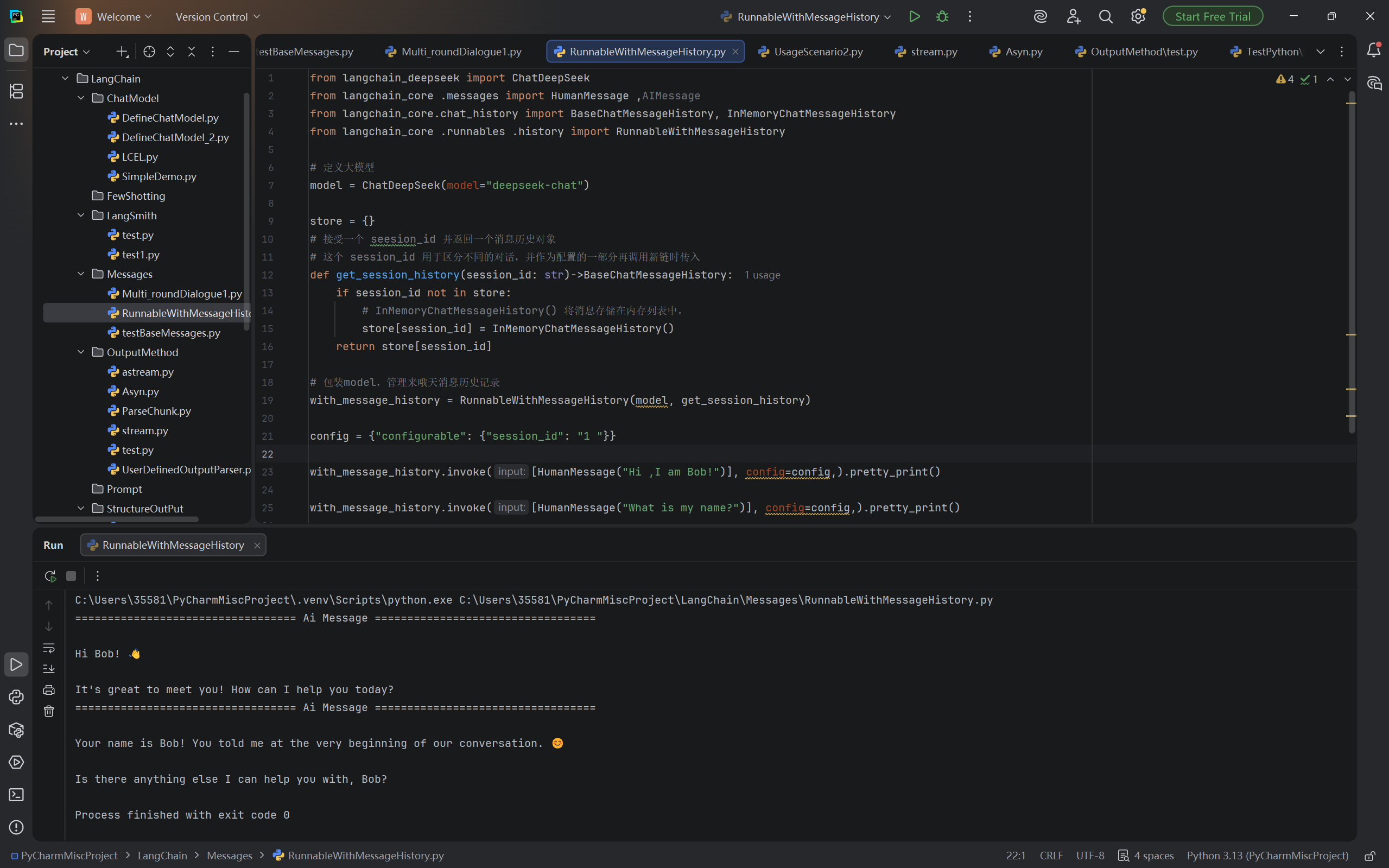
with_message_history.invoke([HumanMessage("Hi ,I am Bob!")], config=config,).pretty_print()
with_message_history.invoke([HumanMessage("What is my name?")], config=config,).pretty_print()运行结果:
class langchain_core.runnables.history.RunnableWithMessageHistory类初始化参数说明:
- runnable:被包装Runnable实例
- get_session_history:返回类型为BaseChatMessageHistory的函数,传入后作为回调函数。此函数接受一个session_id 字符串类型,并返回相应的聊天消息历史记录实例。
- .invoke ()方法:此方法与其他Runnable 实例的.invoke () 方法相同。只不过注意其config配置,需要配置成config ={"configurable ": {"session_id ": ""}},RunnableWithMessageHistory 可以读取到会话id。
1.4. 管理历史消息
1.4.1. 前置概念
1.4.1.1. 上下文窗口
管理历史消息,⽆⾮就是理解如何"管理","管理"⽆⾮也就是⼀些 "CRUD"。那么在了解如何
管理消息之前,需要先了解下多轮对话的核⼼概念:上下⽂窗⼝。上下⽂窗⼝可以理解为模型的"短 期⼯作记忆区",即 LLM 在⼀次处理请求时,所能查看和处理的最⼤ Token 数量,它包含了:
- 用户的输入
- LLM的输出
- 有时候还包括系统指令和历史对话
1.4.1.2. Token
在⾃然语⾔处理(NLP)中,Token 是⽂本的基本单位。它不是完全等同于⼀个单词或⼀个汉字,⽽ 是⼀个更细粒度的划分。
为什么用Token 计算机⽆法直接理解⽂字,它需要将⽂本转换为数字(向量)。Tokenization(令
牌化)就是这个转换过程的第⼀步,将句⼦分解成模型可以理解和处理的碎⽚。
- 对于英文:1个Token ~= 4个字符或0.75个单词 ,1000 个 Tokens 约等于 750 个英⽂单词。
⼀个 Token 可以是⼀个单词(如 "apple" )、⼀个词根(如 "un" 在 "unlikely" 中),
或者⼀个标点符号(如 "." )。例如, "ChatGPT is great!" 可能会被分成 "Chat", "G", "PT", " is", " great", "!" 这 6 个 Token。 - 对于中文:对于中⽂: 1个汉字 ~= 1.5-2个Tokens ,1000 个 Tokens ⼤约相当于 500-700 个汉字。常⻅的词和字可能是⼀个 Token,⽣僻字或复杂词可能会被拆分成多个。
举个例⼦, 上下⽂窗⼝就像⼀个固定⼤⼩的⼯作台,再把 Token ⽐作⼀个积⽊零件,把⼤模型⽐作⼀ 个⼯匠。⼯匠需要拼出模型,必须把所需的零件(输⼊的 Token) 放在⼯作台上,⼀边拼装(⽣成回复),⼀边把拼好的部分(输出的 Token)也放在⼯作台上。整个过程(输⼊+输出)中,⼯作台上的所有积⽊(Tokens)总数都不能超过⼯作台的最⼤容量(上下⽂窗⼝⼤⼩)。

如果最初的零件太多,占满了⼯作台,⼯匠就没有空间进⾏拼装了。这时你就需要减少零件(精简输⼊)。
1.4.2. 消息裁剪
有了上下⽂窗⼝和 Token 的认知,再来看多轮对话的实现原理,其实就是:
- 输入 = 系统信息 + 历史对话 + 用户的最新问题
- 对于模型来说,并不是真正的"记忆",而是每次都将完整的上下文重新输入。
由于所有模型的上下⽂窗⼝⼤⼩都是有限的,这意味着作为输⼊的 Token 也是有限的。如果有累积了很⻓的消息历史记录,则需要管理传递给模型的消息的⻓度。
trim_messages 可⽤于将聊天历史记录的⼤⼩减⼩为指定的令牌计数或指定的消息计数。
1.4.2.1. 基于Token数的消息裁剪
下⾯演⽰⼀个通过 trim_messages 裁剪消息的⽰例(基于输⼊ Token 数的修剪)。
先来看看不做任何输⼊限制的聊天:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,trim_messages
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
print(model.invoke(messages))打印结果:
python
content="You're Bob! 😊"
additional_kwargs={'refusal': None}
response_metadata={
'token_usage': {
'completion_tokens': 6,
'prompt_tokens': 149,
'total_tokens': 155,
'completion_tokens_details': None,
'prompt_tokens_details': {
'audio_tokens': None,
'cached_tokens': 0},
'prompt_cache_hit_tokens': 0,
'prompt_cache_miss_tokens': 149},
'model_provider': 'openai',
'model_name': 'deepseek-v4-flash',
'system_fingerprint': 'fp_8b330d02d0_prod0820_fp8_kvcache_20260402',
'id': 'f058ba2c-d4fa-446e-8358-a25d01456b12',
'finish_reason': 'stop', 'logprobs': None}
id='lc_run--019e5f19-6f39-7e91-a8db-dbe13b7fe7d0-0'
tool_calls=[] invalid_tool_calls=[]
usage_metadata={'input_tokens': 149, 'output_tokens': 6, 'total_tokens': 155, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}
}从打印结果看来,LLM 还认识我们,且共输⼊了 88 tokens。接下来让我们对消息进⾏裁剪,我们只希望将来输⼊时,最多输⼊ 65 tokens,超出的需要按照⼀定的"规则"进⾏裁剪,代码如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,trim_messages
from langchain_core.messages.utils import count_tokens_approximately
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 使用trim_messages 减少发送给模型的数量消息
trimmer = trim_messages(
max_tokens = 65, # 修建消息的最大令牌数量,在实际的使用情况中根据你想要的谈话长度来调整
strategy = "last", # 修建策略:"last"(默认):保留最后的消息。"first":保留最早的消息
token_counter = count_tokens_approximately, #传入一个函数或者语言模型来计算token数量
include_system = True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model # 注意chain的顺序要先调用消息裁剪器在调用大模型
print(chain.invoke(messages))运行结果:

可以看到大模型并不认识我们了。
1.4.2.2. 基于消息数的裁剪
除了基于token的裁剪,还可以通过设置token_counter = len根据消息数修剪聊天记录。在这种情况下max_tokens将控制最大消息数。示例如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage,trim_messages
# 定义大模型
model = ChatDeepSeek(model="deepseek-chat")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 使用trim_messages 减少发送给模型的数量消息
trimmer = trim_messages(
max_tokens = 5, # 修建消息的最大令牌数量,在实际的使用情况中根据你想要的谈话长度来调整
strategy = "last", # 修建策略:"last"(默认):保留最后的消息。"first":保留最早的消息
token_counter = len, #传入一个函数或者语言模型来计算token数量
include_system = True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model # 注意chain的顺序要先调用消息裁剪器在调用大模型
print(chain.invoke(messages))运行结果:

我们可以看到大模型并不认识我们。
1.4.3. 消息过滤
在更复杂的场景下,我们可能会使⽤消息列表来跟踪状态,例如我们可能只想将这个完整消息列表的⼦集传递模型调⽤,⽽不是所有的历史记录。
filter_messages方法则可以轻松按照类型,ID或者名称过滤message。
下面演示相关过滤示例:
python
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, filter_messages
messages = [
SystemMessage("你是⼀个聊天助⼿", id="1"),
HumanMessage("⽰例输⼊", id="2"),
AIMessage("⽰例输出", id="3"),
HumanMessage("真实输⼊", id="4"),
AIMessage("真实输出", id="5"),
]
# 按照类型筛选
print(filter_messages(messages, include_types="human"))
print("========================================")
# 按照ID筛选
print(filter_messages(messages, include_ids=["3"]))
print("========================================")
# 按照类型+ID筛选
print(filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"]))运行结果:

1.4.4.消息合并
若我们的消息列表存在连续某种类型相同的消息,但实际上某些模型不⽀持传递相同类型的连续消
息。因此对于这种情况,我们可以使⽤ merge_message_runs ⽅法轻松合并相同类型的连续消
息。 ⽰例如下:
python
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, merge_message_runs
model = ChatDeepSeek(model="deepseek-chat")
# 历史消息记录
messages = [
SystemMessage("你是⼀个聊天助⼿。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使⽤ LangChain?"),
HumanMessage("为什么要使⽤ LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage("不过别担⼼,它不会"分散"你的注意⼒!"),
HumanMessage("选择LangChain还是LangGraph?"),
]
final_messages = merge_message_runs(messages)
print(final_messages)
model.invoke(final_messages).pretty_print()运行结果:
python
[
SystemMessage(content='你是⼀个聊天助⼿。\n你总是以笑话回应。', additional_kwargs={}, response_metadata={}),
HumanMessage(content='为什么要使⽤ LangChain?\n为什么要使⽤ LangGraph?', additional_kwargs={}, response_metadata={}),
AIMessage(content='因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!\n不过别担⼼,它不会"分散"你的注意⼒!', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='选择LangChain还是LangGraph?', additional_kwargs={}, response_metadata={})
]
================================== Ai Message ==================================
这个问题就像是在问"选择⼑叉还是⼑具"?我的建议是:
如果你想要⼀个完整的厨房来烹饪AI,选LangChain;如果你想精确地切割每个逻辑步骤,选LangGraph!不过说实话,我最喜欢的还是选...⼀个能帮我点外卖的AI框架!