一句话概括 :Prompt Engineering 教你怎么「说话」,Context Engineering 教你怎么「备料」,Harness Engineering 教你怎么「造车」。
开篇:三个概念,三次进化
先从大模型的本质说起
把 ChatGPT、Claude 的外壳拨开,里面的大模型(LLM)本质就是一个磁盘上的超大参数文件 。将它加载到显卡内存里,配上 HTTP 接口,就成了大模型 API 服务;给它加个聊天界面,就变成了聊天 AI;加个代码编辑器,就成了 AI IDE。
大模型做的事情很简单:基于当前输入的内容,预测下一个 token 会是什么 。简单来说就是"文字接龙 ",它本质上只是在"猜"我们想要什么。所以如果我们给它的指令太宽泛,预测结果就会非常发散。
在这个基础上,AI 应用开发先后涌现了这三个核心工程概念。它们不是彼此替代,而是层层递进、逐步包含 的关系------就像你先学会说话,再学会准备材料,最后学会建造整个系统。
graph LR
FILE["磁盘上的参数文件"] -->|"加载到 GPU"| MEM["显存中的模型"]
MEM -->|"+ HTTP 接口"| API["大模型 API"]
API -->|"+ 聊天 UI"| CHAT["ChatGPT / Claude"]
API -->|"+ 代码编辑器"| IDE["AI IDE(Cursor/Trae)"]
API -->|"+ 工具 + 循环"| AGENT["Agent(Claude Code/Codex)"]
style FILE fill:#F3E5F5,stroke:#6A1B9A,stroke-width:2px,color:#4A148C
style AGENT fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
演进时间线
timeline
title 三大工程概念的演进时间线
2022 年底 ~ 2023 年 : Prompt Engineering(提示词工程)
2025 年 6 月 : Context Engineering(上下文工程)
2026 年 2 月 : Harness Engineering(驾驭工程)
什么是 Prompt Engineering?
Prompt Engineering (提示词工程)是最早被广泛认知的 AI 工程实践,2022 年底随 ChatGPT 的爆发而广泛传播 。还衍生出了新的岗位:提示词工程师。
它的核心是:通过精心设计输入给大模型的文本(即 Prompt),来操控模型的输出概率分布 ,从而获得更高质量的响应。
常见的误解是把它当作"和 AI 沟通的技巧"。但其本质远非沟通------Prompt 是一个条件信号 ,它决定了模型从哪个概率分布里采样。改变 Prompt 就是改变分布的形状,分布变了,采样结果自然不同。
Prompt 的内容包括:角色设定、背景、历史对话、参考文档、限制输出格式等。这些约束构成了提示词,而有意识地调整和设计它们,让模型稳定地朝你预期的内容和格式输出------这就是 Prompt Engineering。
它解决的问题 :大模型无引导乱说话。
什么是 Context Engineering?
Context Engineering (上下文工程)是随着 AI Agent 的兴起而独立出来的工程概念。
提示词写得越长越仔细,模型知道的就越多,回答就越准。反过来,大模型回答不准,大概率是因为知道得不够多。于是大家很自然地不断往大模型里塞各种资料------这些打包发给大模型的所有信息 就叫上下文 ,提示词只是上下文的一部分。
但大模型再强,一次性能处理的上下文也有最大限制,这个限制叫上下文窗口 。在多轮对话中很容易将窗口打满,需要压缩或丢弃部分信息,这个过程中不可避免会丢失关键信息------这类问题被统称为上下文腐化 (Context Corruption),表现为模型开始记不住、回答前后不一致。
于是问题来了:怎么在合适的时候,将合适的内容塞入有限的上下文中? 负责动态管理大模型上下文的技术,就是上下文工程 。提示词是上下文的一部分,自然提示词工程也是上下文工程的一部分。
它解决的问题 :上下文的组织和腐化。
什么是 Harness Engineering?
Harness Engineering (驾驭工程)是 AI Agent 开发领域最新的工程方法。2026 年 2 月 ,因为 Open AI 的一篇博客迅速在 AI 圈火了起来。"Harness" 一词来自马具 ------缰绳、马鞍等引导马匹的装备。业界给出了一个公式:
Agent = Model + Harness
模型包含智能,Harness 让这个智能变得有用。把模型想成引擎,Agent 就是整辆车,而 Harness 就是方向盘和刹车。最好的引擎没有方向盘和刹车,去不了任何有用的地方。
更直接的定义:只要不是大模型的那部分,都属于 Harness Engineering 的范畴。所以我们围绕大模型所做的各种 skill 、mcp 服务搭建、工作流编排等都是在进行 Harness Engineering。
它和 Context Engineering 的区别在于:上下文工程关注"给 Agent 看什么",而 Harness Engineering 的范围更广------还包括架构约束、自验证循环、熵治理和系统的可演进性 。上下文工程是 Harness 的子集。
它解决的问题 :Agent 的可靠性和可演进性。
三种工程方法的关系
flowchart TD
subgraph Harness["Harness Engineering"]
style Harness fill:#fce4ec,stroke:#d81b60,stroke-width:2px,color:#000
subgraph Context["Context Engineering"]
style Context fill:#e3f2fd,stroke:#1e88e5,stroke-width:2px,color:#000
subgraph Prompt["Prompt Engineering"]
style Prompt fill:#e8f5e9,stroke:#43a047,stroke-width:2px,color:#000
LLM(("大语言模型(LLM)"))
style LLM fill:#fff3e0,stroke:#f57c00,stroke-width:2px,color:#000
end
end
end
第一阶段:Prompt Engineering --- 操控模型的输出分布
1.1 底层机制:条件概率分布
大模型做的事情本质上是计算一个条件概率分布 :给定我们输入的所有文本,模型计算下一个 Token 是什么的概率。
我们的 Prompt 不是指令,而是条件信号 ------ 它决定了模型从哪个概率分布里采样输出。
改了 Prompt → 改了条件概率分布的形状 → 采样结果不同 → 输出不同。所以 Prompt Engineering 的本质不是和模型沟通,而是操控模型的输出分布 。更精确的条件输入,便会产生更精确的输出。
graph TD
subgraph 模型内部
A["海量能力<br/>(翻译/摘要/分类/推理/...)<br/>高度纠缠在参数中"] --> B{"条件概率分布<br/>P(next_token | prompt)"}
end
P["你的 Prompt"] -->|"条件信号"| B
B -->|"采样"| O["输出结果"]
style P fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style B fill:#FFF9C4,stroke:#F57F17,stroke-width:2px,color:#E65100
style O fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style A fill:#F3E5F5,stroke:#6A1B9A,stroke-width:2px,color:#4A148C
1.2 三大经典技巧的底层机制
在这个认知基础上,我们逐一拆解具体 Prompt 技巧为什么有效。
1.2.1 Few-Shot:不是教新知识,而是激活已有能力
**Few-Shot:少样本提示。**指的是在向大模型提出具体任务需求时,先在提示词(Prompt)里提供少量(通常是2 ~ 5 个)相关的输入和输出示例,然后再让模型去回答新的问题或完成新的任务。
模型在预训练阶段已经从海量文本中学到了非常多的任务模式------翻译、摘要、分类、问答等等。这些能力已经编码在模型参数里,但问题是,模型不知道你现在 想让它执行哪一种。
所以 Few-Shot 示例本质上是在帮模型定位 :你想让我做的是哪种格式的任务。
graph LR
subgraph 预训练阶段
D["海量文本"] --> M["模型参数<br/>编码了无数任务模式"]
end
subgraph 推理阶段
E["Few-Shot 示例"] -->|"格式定位"| M
M -->|"激活对应能力回路"| R["正确输出"]
end
style E fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style M fill:#FFF9C4,stroke:#F57F17,stroke-width:2px,color:#E65100
style R fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
关键实验证据 :即使你故意把 Few-Shot 里的标签打错(比如正面情感标成负面),模型的表现也不会大幅下降。这说明模型真正在意的不是你例子里的具体答案,而是你的例子所展示的任务格式和输入输出结构 。
推理时参数完全不更新,模型没有在"学习"这几个例子------它只是在用你的例子来定位已有的能力回路。
1.2.2 思维链(Chain-of-Thought):用生成长度换计算深度
有研究论文表明,对于复杂任务,在 prompt 中加入一句 "Let's think step by step" 就能把模型输出的准确率提高一大截。
核心原因 :Transformer(大模型的底层架构) 的计算深度是固定的。不管问题多复杂,都是那么多层 Attention (注意力机制)和 FFN(前馈神经网络),走一遍就出结果。对于简单问题够用了,但对于需要多步推理的问题,一次前向传播的计算量可能根本不够。
生成长度 很好理解:思维链让模型把中间推理步骤以文本形式生成出来,每一步生成的文本又变成下一步的输入上下文,这样对比没有思维链的时候,模型计算一次就给出结果,生成的 token 数就多很多。
graph TD
subgraph "无思维链"
Q1["复杂问题"] -->|"一次前向传播<br/>计算深度固定"| A1["直接跳到答案<br/>(中间推理全压缩,容易出错)"]
end
subgraph "有思维链"
Q2["复杂问题"] -->|"第1次前向传播"| S1["中间步骤 1"]
S1 -->|"作为输入上下文"| S2["中间步骤 2"]
S2 -->|"作为输入上下文"| S3["中间步骤 3"]
S3 -->|"第N次前向传播"| A2["最终答案<br/>(每步只处理一小步)"]
end
style Q1 fill:#FFEBEE,stroke:#C62828,stroke-width:2px,color:#B71C1C
style A1 fill:#FFEBEE,stroke:#C62828,stroke-width:2px,color:#B71C1C
style Q2 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style A2 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
早期的模型,思维链是一种外置的 Prompt 技巧,需要用户手动去触发(比如加上 Let's think step by step),从 2024 年下半年 OpenAI 发布 O1 推理模型后,思维链已经从"一种 Prompt 技巧 "正式变成了"模型底层的原生能力 "。模型在回答问题之前,会主动思考。
计算深度 怎么理解?可参考:大模型的思维链(Chain-of-Thought)
思维链 = 用生成长度换计算深度。 没有思维链时,模型要直接从问题跳到答案,中间推理全压缩在一次前向传播里,容易出错。有了思维链,每一步都被显式写出来,模型可以基于中间结果继续推。
1.2.3 角色扮演:缩窄输出分布的采样区域
在与大模型对话的过程中,我们有时会给模型设定角色,比如:"你是一个资深的前端工程师",加上这个设定,就能明显改变模型的输出风格和质量,这是为什么?
原因和模型预训练数据的分布 有关。训练语料里包含了各种各样的人写的各种各样的文本。当我们说"你是一个资深的前端工程师"时,其实是在把输出分布的条件缩窄到一个特定子集 ------在训练数据中,由资深工程师身份写出的那类文本的分布。
graph TD
subgraph "模型的输出分布空间"
ALL["全部训练语料的分布"]
ALL --> SUB1["'资深工程师'子集<br/>专业、精确、逻辑强"]
ALL --> SUB2["'小学老师'子集<br/>通俗、耐心、易懂"]
ALL --> SUB3["'论坛初学者'子集<br/>随意、可能有误"]
end
R["角色描述 Prompt"] -->|"缩窄条件"| SUB1
style R fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style SUB1 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style SUB2 fill:#FFF9C4,stroke:#F57F17,stroke-width:1px,color:#E65100
style SUB3 fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
我们没有教会模型任何新东西,我们只是通过角色描述帮它选了一个更合适的输出分布区域。模型的参数没变,能力没变,只是换了一个采样区域。
1.3 小结:Prompt Engineering 的本质
记住:在与模型对话的过程中,我们并没有训练模型,而是操控模型的输出分布。
graph LR
subgraph "提示词工程核心框架"
N["本质"] --> N1["Prompt 是条件信号<br/>改变 Prompt = <br>改变输出分布"]
T["三大技巧"] --> T1["Few-Shot:定位任务模式<br/>激活已有能力回路"]
T --> T2["思维链:显式化中间步骤<br/>用生成长度换计算深度"]
T --> T3["角色扮演:缩窄分布子集<br/>选择更优的采样区域"]
H["高级观点"] --> H1["不是给模型新能力<br/>而是从已有能力中<br/>选择正确的那个"]
end
style N fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style T fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style H fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
Prompt Engineering 有效,本质上是因为大模型在预训练阶段已经获得了足够多的能力,但这些能力高度纠缠在一起。Prompt 的作用是解耦------从模型庞大的能力空间中,精准调出你当前需要的那一块。
核心认知:别把 Prompt Engineering 当沟通技巧,要把它当成对模型输出分布的精确操控 。
但 Prompt Engineering 解决的只是"大模型无引导乱说话"的问题。模型是更聪明了,但它只能聊天,没法帮我们干活。于是我们给大模型加入 Bash 沙箱、文件系统、MCP 等能力,让它能操作外部工具、读写文件、执行命令------它们共同构成了执行层 。将它们串成流程,外部套一层循环,就有了 Agent。而 Agent 带来的新问题,就需要下一层工程来解决。
第二阶段:Context Engineering --- 管理模型的工作记忆
2.1 从一问一答的聊天机器人到 Agent
给大模型加入工具和循环后,它就不再只是一个聊天机器人,而是变成了一个能执行任务的 Agent 。Claude Code 就是业界最佳的 Agent。
我们可以从 Claude Code 的设计哲学中学到,一个工具 ➕ 一个循环就是一个最简单的 Agent: github.com/shareAI-lab...
graph LR
subgraph "Agent 的 ReAct 的循环"
CTX["组装上下文<br/>(提示词工程+上下文工程)"] --> LLM["大模型思考<br/>(决定下一步行动)"]
LLM --> EXEC["外部程序执行<br/>(Bash/文件/MCP)"]
EXEC -->|"执行结果<br/>加入上下文"| CTX
end
style CTX fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style LLM fill:#FFF9C4,stroke:#F57F17,stroke-width:2px,color:#E65100
style EXEC fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
Agent 的本质就是一个 for 循环 :组装上下文 → 大模型思考 → 执行行动 → 结果回到上下文 → 继续循环。(这就是 Agent 的典型架构:ReAct,其他的架构还有 Plan-and-Solve(Claude Code 的 plan 模式)、Reflection)
但这个循环一旦变长,问题就来了。一个任务可能经过多轮工具调用,每一轮都会产生工具调用的参数、返回的结果、模型的中间推理------这些信息不断累积在上下文里。
2.2 核心矛盾:信息膨胀与上下文腐化
上下文窗口就这么大,只要 Agent 的循环一长,上下文就一定会膨胀 。即使现在前沿模型的窗口已经能容纳百万 Token,但是:窗口大不等于问题解决了,反而可能是一种负担。
graph TD
subgraph "Agent 循环过程"
T1["Step 1<br/>工具调用 + 结果"] --> T2["Step 2<br/>工具调用 + 结果"]
T2 --> T3["Step 3<br/>..."]
T3 --> TN["Step N<br/>上下文已膨胀"]
end
TN --> P["核心矛盾"]
P --> C1["窗口有限<br/>需要压缩/丢弃信息"]
P --> C2["上下文腐化<br/>关键信息丢失<br/>回答前后不一致"]
P --> C3["注意力衰减<br/>Lost in the Middle<br/>目标被噪声淹没"]
style P fill:#FFEBEE,stroke:#C62828,stroke-width:2px,color:#B71C1C
因为大模型跟人一样是有注意力(transformer 的注意力机制 )的,就像我们读一本书,读到三四十页的时候,可能已经忘了前面三四页的内容是什么。那同样的,随着 Agent 看过的文件越来越多、拿到的信息越来越杂,前面定好的目标和约束后面可能慢慢就被冲淡了------理解也会越来越偏。这就是上下文腐化 。
所以,上下文工程的目标 = 找到最小的、高信噪比的 Token 集合,最大化期望结果的概率。简单来说就是从膨胀的上下文中提取出与任务目标最相关的信息继续交给大模型,让模型尽可能地正确地完成任务。
注意:不是尽可能多塞信息,而是找到最小的高质量集合(关键信息) 。
2.3 上下文工程的三步法:召回、压缩、组装
不同的 Coding Agent(Cursor、Claude Code、Trae)技术实现各有差异,但总的来说可以总结为三个步骤 :
graph LR
subgraph "① 召回 Recall"
R1["外部知识(文档/API)"]
R2["过去聊天记录"]
R3["当前代码环境"]
R4["程序运行报错"]
end
subgraph "② 压缩 Compact"
COMP["分段发给大模型做总结<br/>将信息变小"]
end
subgraph "③ 组装 Assemble"
ASM["按结构重新排列<br/>越靠后越被关注<br/>进入模型的上下文<br/>更精简、更相关"]
end
R1 & R2 & R3 & R4 --> COMP --> ASM
style COMP fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style ASM fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
召回 :找什么信息。来源包括外部知识、过去的聊天记录、当前代码环境、程序运行报错等------从中找出最相关的内容(涉及 RAG、Memory 等技术)
压缩 :信息很多但窗口有限,需要将信息变小。比如分段发给大模型做总结/摘要
组装 :信息的位置和顺序会直接影响模型的理解和输出(越靠后越容易被关注),所以需要用一定的结构重新组装压缩后的内容
2.4 六层工程体系
在三步法的基础上,前沿团队提炼出了六层具体的工程实践:
graph TB
L1["① 压缩重启<br/>摘要压缩,翻页续写"] --> L2["② 外化记忆<br/>写入文件系统<br/>跨会话持久化"]
L2 --> L3["③ 及时加载 Just-in-Time Context<br/>维护引用,按需拉取"]
L3 --> L4["④ 上下文隔离<br/>Multi-Agent 设计<br/>子 Agent 独立上下文<br/>互不污染"]
L4 --> L5["⑤ 工具设计 <br/>精简工具集"]
L5 --> L6["⑥ 缓存友好架构 <br/>稳定前缀 + 追加式更新"]
style L1 fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style L2 fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style L3 fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style L4 fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style L5 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style L6 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
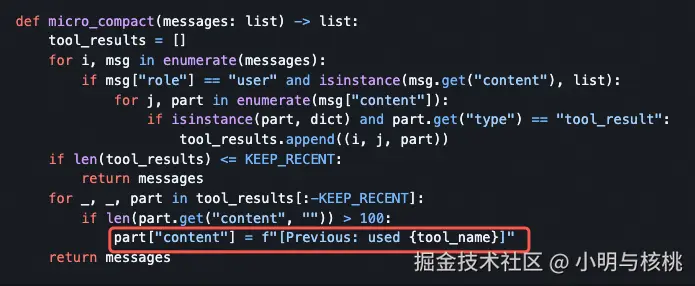
① 压缩重启------ 第一道防线
当对话接近上下文窗口上限时(比如 Claude Code 的上下文超过窗口容量的 80% 后,自动触发 compaction,我们也可以执行 /compact 命令,手动压缩上下文),模型自己对当前上下文做一次摘要总结 ,然后用摘要重新初始化新的上下文窗口。
相当于模型写了一页笔记,然后翻开新的一页继续工作。
在这个过程中,关键在于选择保留什么、丢弃什么 。Anthropic 的建议是:先最大化召回(确保每一条重要信息都被捕获),然后再迭代提升精确度。一个容易入手的优化是:把已完成的工具调用和原始返回结果清理掉,只保留结论。比如 Claude Code 在每次 LLM 调用前,将旧的 tool result 替换为占位符,如下图所示:
sequenceDiagram
participant A as Agent
participant C as 上下文窗口
loop 执行循环
A->>C: 工具调用 + 结果不断累积
C-->>C: 上下文持续膨胀...
end
Note over C: 接近窗口上限!
A->>A: 触发 Compaction<br/>对当前上下文做摘要
A->>C: 用摘要重新初始化(翻页续写)
loop 继续执行
A->>C: 基于摘要继续工作
end
② 外化记忆------ 跨会话持久化
Compaction 解决的是"上下文太长怎么办",但还有一类信息------它不属于当前对话,但 Agent 在后续步骤甚至后续会话中还需要。这类信息需要写到外部文件 中。
产品
外化记忆方式
Claude Code
创建 Todo List 追踪任务进度
Manus(2025年3月推出,全球首个通用Agent)
维护 Notes.md 记录中间结论
Manus 团队的深层洞察 :
文件系统是终极的无限上下文。 代码和数据保存在文件里,原始搜索结果存入文件而不是留在对话中,活跃的上下文里只保留结论和下一步操作。文件系统不是辅助工具,而是上下文架构的核心组成部分 。
③ 及时加载(Just-in-Time context,优雅的"懒加载 (Lazy Loading)")-- 上下文放能力而非信息
传统 RAG 思路:用户提问后,一次性把所有可能相关的信息检索出来塞进上下文(贪婪的"预加载 (Pre-loading)" )。这种方式在单轮问答中没问题,但在多步执行的 Agent 场景中会面临致命打击:
无法预测未来 :Agent 在执行第 1 步时,我们根本不知道它在第 10 步会需要什么信息。如果一开始就把所有可能相关的资料全塞进去,上下文窗口瞬间爆满。
Lost in the middle(注意力丢失) :大量的无关背景信息会形成严重的"噪声",导致模型在长上下文中忽略真正关键的指令。
Anthropic 推荐的做法是,Agent 不预加载所有数据,而是维护轻量级的标识符。比如文件路径、数据库查询、网页链接。需要的时候,Agent 用工具动态加载数据到上下文中。用完就可以在下一次 compaction 时清理掉。
graph LR
subgraph "传统 RAG"
Q["用户提问"] --> R["一次性检索<br/>所有可能相关信息"] --> CTX1["塞满上下文"]
end
subgraph "Just-in-Time"
Q2["任务启动"] --> REF["维护轻量引用<br/>(文件路径/查询/链接)"]
REF -->|"Step 5 需要"| LOAD1["按需加载数据 A"]
REF -->|"Step 10 需要"| LOAD2["按需加载数据 B"]
LOAD1 -->|"用完清理"| CLEAN["保持上下文精简"]
end
style CTX1 fill:#FFEBEE,stroke:#C62828,stroke-width:2px,color:#B71C1C
style CLEAN fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
Just-in-Time context 重点:上下文里放的不是信息本身,而是获取信息的能力。
④ 上下文隔离------ 多 Agent 架构(主 Agent 和子 Agent 的上下文是相互隔离的)
当任务足够复杂时,即使做了压缩、外化记忆、及时加载,单个上下文窗口也可能不够用------更准确地说,不是放不下,而是不同子任务的上下文会互相干扰 。
graph TD
MAIN["主 Agent<br/>规划和分配任务"]
MAIN --> SA1["子 Agent 1<br/>独立上下文窗口"]
MAIN --> SA2["子 Agent 2<br/>独立上下文窗口"]
MAIN --> SA3["子 Agent 3<br/>独立上下文窗口"]
SA1 -->|"只返回结果"| MAIN
SA2 -->|"只返回结果"| MAIN
SA3 -->|"只返回结果"| MAIN
SA1 -.-|"互不可见"| SA2
SA2 -.-|"互不可见"| SA3
style MAIN fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style SA1 fill:#E3F2FD,stroke:#1565C0,stroke-width:1px,color:#0D47A1
style SA2 fill:#E3F2FD,stroke:#1565C0,stroke-width:1px,color:#0D47A1
style SA3 fill:#E3F2FD,stroke:#1565C0,stroke-width:1px,color:#0D47A1
主 Agent 承接到任务后,拆分成各个子任务,分配给子 Agent,各个子 Agent 在其自身的上下文中完成各自的任务,最终返回结果。
多 Agent 架构在上下文层面的应用:子 Agent 只把其任务的最终结果返回给主 Agent,中间过程的推理信息、工具调用结果不污染主 Agent 上下文。
⑤ 工具设计------ 容易被忽略的关键
这一层容易被忽略,但 Anthropic 明确指出:工具设计是上下文工程的核心组成部分 。原因有三:
工具的定义 本身占据上下文空间
工具的返回结果 是上下文膨胀的主要来源
工具集的大小 直接影响模型决策质量
所以工具的定义要简洁,遵循"单一职责",同时 Agent 的工具声明要最小化,用到什么工具就声明什么工具,不要"贪心加载"。
更多的工具可能让 Agent 变蠢!
⑥ 缓存友好架构(Cache-Friendly)------ 稳定前缀,追加式更新
Manus 团队的判断:
如果只能选一个指标来衡量生产级 AI Agent 的质量,那就是 K-V Cache(键值缓存)命中率 。它同时决定了延迟和成本。
K-V Cache 可参考:大模型中的 K-V Cache 原理解析
graph LR
subgraph "上下文结构(追加式)"
direction TB
SYS["系统指令(固定)"] --> TOOL["工具定义(固定)"]
TOOL --> H1["历史轮次 1(已缓存)"]
H1 --> H2["历史轮次 2(已缓存)"]
H2 --> NEW["新增内容(仅计算这部分)"]
end
KV["KV Cache<br/>命中率最大化"]
SYS -.->|"复用"| KV
TOOL -.->|"复用"| KV
H1 -.->|"复用"| KV
H2 -.->|"复用"| KV
NEW -.->|"计算"| KV
style NEW fill:#FFF9C4,stroke:#F57F17,stroke-width:2px,color:#E65100
style KV fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
以 Claude Sonnet 为例:不带缓存的输入成本 3美元/百万Token ,启用 Prompt Caching 后降到 0.3美元/百万Token ,省了 90%。
核心原则 :稳定的内容(系统指令、工具定义)放在最前面形成固定前缀 ,每一轮新内容追加在后面。前缀部分的 KV Cache 完全复用,只需计算新追加的部分。反过来,如果你在中途修改了前面的内容(比如动态增删工具、重写系统指令),前缀变了,后面所有内容的缓存全部作废------代价是灾难性的。
2.5 两个容易被忽略的细节
1. 保留错误信息
直觉上你会觉得 Agent 犯了错,应该把错误步骤清理掉,但实际保留错误信息会让模型在下次执行时不再犯同样的错误。
不要擦除失败,因为失败就是证据。 模型看到之前的错误才能避免重复同样的错误。清理掉错误 = 移除学习信号。
2. Todo 复述对抗注意力衰减
长任务中 Agent 容易"忘记"总体目标------不是信息丢了,而是目标被埋在了上下文中间,模型的注意力没有对准它(Lost in the Middle 现象)。
解决方案很简单:在每一步结束后让 Agent 重写 Todo List ,把当前目标和剩余任务刷新到上下文末尾。利用模型对末尾内容注意力更强的特性,用自然语言偏置模型的注意力焦点,不需要任何架构改动。
2.6 小结
上下文工程 = 管理大模型推理时的工作记忆。
和 Prompt Engineering 的区别:Prompt Engineering 关注指令怎么写,上下文工程关注的是每一次推理时上下文窗口里的信息组成和动态变化 。
操作三步法:召回 (找什么信息)→ 压缩 (信息变小)→ 组装 (结构化排列)。
目标:用最小的、高信噪比的 Token 集合 ,最大化期望结果的概率。
但上下文工程做再好也可能会腐化------Agent 的循环只要够长,上下文就一定会膨胀,前面定好的目标和约束就可能被冲淡。怎么办?这就引出了下一层工程。
第三阶段:Harness Engineering --- 给引擎装上方向盘和刹车
3.1 马与马具的隐喻
Harness 的中文是:马具,所以 Harness Engineering 叫驾驭工程,在这里,马是大模型,而马具就是人类工程师为驾驭马准备各种工具,让马可以按照指定的方向达成某个目标。
graph TD
subgraph "Agent = Model + Harness"
RIDER["骑手(人类工程师)<br/>提供方向,而不是亲自跑"] --> HARNESS["Harness(缰绳+马鞍+刹车)<br/>骑手和马之间的控制系统"]
HARNESS --> HORSE["马(AI 模型)<br/>强大、快速<br/>但不知道该往哪走"]
end
HORSE --> OUTPUT["到达目的地"]
NO_HARNESS["最好的引擎<br/>没有方向盘和刹车"] -.->|"去不了任何<br/>有用的地方"| NOWHERE["???"]
style RIDER fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style HARNESS fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style HORSE fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style NO_HARNESS fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
style NOWHERE fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
3.2 Harness 的四层架构
从系统架构的视角看,Harness 包裹着大模型,形成一个完整的工程外壳 ,由四个层次组成:
graph TB
subgraph HARNESS["Harness 四层架构"]
direction TB
ORC["编排层 Orchestration<br/>全局规划 → <br/>任务拆解 → <br/>分步执行<br/>以规划为核心的全流程管控"]
MEM["记忆层 Memory<br/>规则文件(Rules.md)<br/>项目背景、技术栈、<br/>代码风格、禁止事项<br/>作为系统提示词<br/>自动注入上下文"]
FEED["反馈层 Feedback<br/>Linter / 单元测试 / CI 输出<br/>校验结果回传,驱动自动修复"]
EXEC["执行层 Execution<br/>Bash 沙箱 / 文件系统 <br/> MCP / Skill<br/>读写代码<br/>执行命令<br/>操作工具"]
end
LLM["大模型<br/>(核心推理引擎)"]
ORC --> LLM
MEM --> LLM
LLM --> EXEC
EXEC --> FEED
FEED -->|"错误/结果<br/>回到上下文"| LLM
style ORC fill:#F3E5F5,stroke:#6A1B9A,stroke-width:2px,color:#4A148C
style MEM fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style FEED fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style EXEC fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style LLM fill:#FFF9C4,stroke:#F57F17,stroke-width:3px,color:#E65100
层次
职责
典型实现
编排层 全局规划,将大任务拆解为有明确执行标准的子任务,按规划驱动 Agent 分步执行
任务拆解、子任务调度、结束条件判断
记忆层 保证每次给大模型的上下文中都包含可复用的核心信息,减少理解偏移
CLAUDE.md 等规则文件
反馈层 通过校验结果回传错误来实现自动修复
Linter、单元测试、CI 输出回传
执行层 让大模型能像人一样操作外部工具
Bash 沙箱、文件读写、MCP 工具、Skill
记忆层的关键设计:规则文件与路由
只要保证每次给大模型的上下文中都包含一些可复用的核心信息 (项目目标、技术栈、需求背景、代码风格、禁止事项等),大模型就能在大框架约束下减少理解偏移。
这些核心信息可以单独写成文件,固定在代码仓库里:
工具
规则文件
Claude Code
CLAUDE.md
Cursor
.cursor/rules/
规则文件写多了也会变长,上下文压力增大。解决方案:拆文件 + 路由加载 。
graph TD
RULES["规则文件(主入口)<br/>只包含文件路径索引"]
RULES -->|"背景相关"| BG["bg.md<br/>项目背景"]
RULES -->|"技术栈相关"| STACK["stack.md<br/>技术栈约束"]
RULES -->|"代码风格相关"| STYLE["style.md<br/>代码规范"]
RULES -->|"禁止事项"| FORBIDDEN["forbidden.md<br/>禁止操作"]
NOTE["一般只加载路径<br/>需要时才加载全部内容"]
style RULES fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style NOTE fill:#FFF9C4,stroke:#F57F17,stroke-width:1px,color:#E65100
这本质上就是上下文工程里的 "Just-in-Time Context" 思想在记忆层的落地。
反馈层的闭环:自动修复循环
Agent 写完代码后,可以跑 Linter 和单元测试。如果发现问题,测试输出和报错会被加入上下文,驱动 Agent 在下一轮循环中自动修复 :
sequenceDiagram
participant A as Agent
participant E as 执行层
participant F as 反馈层
A->>E: 写代码 / 修改文件
E->>F: 运行 Linter + 单元测试
alt 测试通过
F-->>A: 继续下一个子任务
else 测试失败
F-->>A: 错误信息注入上下文
A->>E: 基于错误自动修复
E->>F: 再次验证...
end
3.3 Harness 的六大支柱
在四层架构之上,我们还可以从工程实践 的角度拆解出六大支柱:
graph TD
H["Harness Engineering<br/>六大支柱"]
H --> P1["① 上下文架构<br/>给地图,不给百科全书"]
H --> P2["② 架构约束<br/>确定性规则 > Prompt 建议"]
H --> P3["③ 自验证循环<br/>中间件钩子防循环/跳验证"]
H --> P4["④ 上下文隔离<br/>子 Agent 作为上下文防火墙"]
H --> P5["⑤ 熵治理<br/>Agent 自维护文档 <br/>及时处理过时信息"]
H --> P6["⑥ 可拆卸性<br/>模块化,随时可移除"]
style H fill:#FFF3E0,stroke:#E65100,stroke-width:3px,color:#BF360C
style P1 fill:#E3F2FD,stroke:#1565C0,stroke-width:1px,color:#0D47A1
style P2 fill:#E3F2FD,stroke:#1565C0,stroke-width:1px,color:#0D47A1
style P3 fill:#E8F5E9,stroke:#2E7D32,stroke-width:1px,color:#1B5E20
style P4 fill:#E8F5E9,stroke:#2E7D32,stroke-width:1px,color:#1B5E20
style P5 fill:#F3E5F5,stroke:#6A1B9A,stroke-width:1px,color:#4A148C
style P6 fill:#F3E5F5,stroke:#6A1B9A,stroke-width:1px,color:#4A148C
① 上下文架构 ------ 给地图而非百科全书
前沿团队一致发现:给 Agent 塞太多信息反而有害。有研究表明,Agent 的性能在上下文利用率超过约 40% 后开始下降。
团队
做法
OpenAI
把 Agent 的指引文件控制在约 100 行,只充当目录 指向更深层文档
Anthropic
Skill 渐进式加载,Agent 需要什么自己去查
关键不是给 Agent 一本百科全书,而是给他一张地图,让他按需查找。
② 架构约束 ------ 确定性规则 > Prompt 建议
大多数人靠 Prompt 来约束 Agent 的行为,写"请遵循以下规则"。但 Prompt 里的规则本质上是建议 ,模型可以听也可以不听。
graph LR
subgraph "Prompt 约束(弱)"
P["'请遵循以下规则...'"] -->|"建议,可听可不听"| M1["模型行为不确定"]
end
subgraph "确定性约束(强)"
L["自定义 Linter / 结构化测试"] -->|"机械式执行<br/>不依赖模型自觉"| M2["行为确定可靠"]
end
style P fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
style M1 fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
style L fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style M2 fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
前沿团队的做法:用确定性的工具(比如脚本)来执行约束 ------自定义 Linter、结构化测试。规则一旦编码,就在所有 Agent 会话中同时生效,不依赖模型的"自觉性"。
③ 自验证循环 ------ 中间件钩子
Agent 有两个常见失败模式:
陷入死循环 :对同一个文件反复编辑十几次,问题始终没解决
跳过验证 :第一个看起来合理的方案就直接输出了
解法:通过 hook 进行拦截,输出前先验证。
sequenceDiagram
participant A as Agent
participant MW as 中间件钩子
participant V as 验证器
A->>MW: 编辑文件 X(第 N 次)
MW->>MW: 检查:该文件已编辑 N 次
alt N > 阈值
MW-->>A: 提醒:重新审视方案!
else N <= 阈值
MW-->>A: 继续
end
A->>MW: 准备提交结果
MW->>V: 拦截!强制执行完整验证
V-->>A: 验证结果
④ 上下文隔离 ------ 子 Agent 作为防火墙
当任务复杂到需要多 Agent 协作时,关键不是按角色分工(前端 Agent / 后端 Agent),而是把子 Agent 当做上下文防火墙 :
⑤ 熵治理 ------ Agent 运行越久,混乱度越高,这是一个熵增的过程
Agent 持续运行时间越长,系统的混乱度就越高:文档过时、知识库和代码不一致。
OpenAI 的方案 :引入一个后台运行的文档梳理 Agent ,定期扫描过时文档并自动提交修复。
graph LR
AGENT["Agent 运行"] -->|"产生"| ENTROPY["熵增加<br/>文档过时"]
ENTROPY -->|"检测"| DOC_AGENT["文档梳理 Agent<br/>(后台运行)"]
DOC_AGENT -->|"自动修复"| DOCS["更新文档"]
DOCS -->|"服务"| AGENT
style ENTROPY fill:#FFEBEE,stroke:#C62828,stroke-width:1px,color:#B71C1C
style DOC_AGENT fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
为 Agent 服务的文档,由 Agent 来维护 。
⑥ 可拆卸性
我们构建的各种 Harness 组件必须是可拆卸的,每个组件独立添加特定能力,不需要的时候直接移除,不影响其他部分。这是为什么?
因为更强大的模型会让某些 Harness 组件变成 Agent 的累赘。比如现在一个复杂的任务可能需要编排一个工作流去完成,未来可能一个 Prompt 就搞定了。所以,大模型越强,Harness 这层外壳就可以做得越薄,那之前过时的 Harness 设计就可以移除了。
Harness 组件必须是模块化的、可拆卸的。
3.4 小结
Harness Engineering 的核心主张 :Agent 的可靠性瓶颈不在模型,在模型周围的系统。
模型是引擎,Agent 是整辆车。引擎再强,没有方向盘和刹车,到不了目的地。
四层架构:编排层 (全局规划)+ 记忆层 (规则文件)+ 反馈层 (自动修复)+ 执行层 (工具能力)。
大模型越强,外壳越薄------但外壳必须有。
总结:三次进化的完整脉络
graph TB
subgraph "第一阶段"
PE["Prompt Engineering<br/>操控输出分布"]
PE_S["解决:无引导乱说话"]
end
subgraph "第二阶段"
CE["Context Engineering<br/>管理工作记忆"]
CE_S["解决:上下文腐化"]
end
subgraph "第三阶段"
HE["Harness Engineering<br/>工程化整个系统"]
HE_S["解决:Agent 可靠性"]
end
PE -->|"模型能说了,但不能干活<br/>加工具 + 循环 = Agent"| CE
CE -->|"上下文管好了,但系统不可靠<br/>需要方向盘和刹车"| HE
style PE fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style CE fill:#FFF3E0,stroke:#E65100,stroke-width:2px,color:#BF360C
style HE fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
进化阶段
核心问题
解决的问题
核心隐喻
一句话总结
Prompt Engineering
怎么说?
无引导乱说话
和马说话的技巧
不是给模型新能力,而是从已有能力中选择正确的那个
Context Engineering
看什么?
上下文腐化
给马规划路线和喂料
用最小的高信噪比上下文,最大化期望行为
Harness Engineering
系统预防/测量/修复什么?
Agent 可靠性
给马装缰绳和刹车
模型是引擎,Harness 让引擎到达目的地
最终洞察 :这三层不是替代关系,而是叠加关系 。即使到了 Harness Engineering 阶段,我们依然需要写好 Prompt、管理好上下文。它们是同一条演进路径上的三个里程碑,共同指向一个目标------
让 AI 的能力在真实世界中可靠地发挥出来。