如何判断一个代码的时间复杂度?
代码的时间复杂度核心是:总操作次数,而非循环数 。如果所有循环加起来总共处理N个元素,即使它有多个循环嵌套,时间复杂度任然是O(N)
举例:
java
int i = n - 1;
while (i >= 0) { // 外层循环
while (i >= 0 && arr[i] == ' ') i--; // 内层1:跳过空格
int right = i;
while (i >= 0 && arr[i] != ' ') i--; // 内层2:跳过单词
// ... 复制单词(每个字符只复制一次)
}关键观察:
- 变量 i 只减不增:从 n-1 一直递减到 -1,永远不会回退。
- 每次内层循环执行时,i 都在向前移动(向左),消耗未处理的字符。
- 整个过程中,i 总共移动了 n+1 步(从 n-1 到 -1)。
- 时间复杂度为O(N)
真正的O(N*N)嵌套循环:
java
for (int i = 0; i < n; i++) { // 外层:i 从 0 到 n-1
for (int j = 0; j < n; j++) { // 内层:每次 j 都从 0 重新开始!
// 操作
}
}内层循环每次都完整遍历整个数组。
总操作次数 = n × n = O(N²)。
关键区别:内层循环是否依赖外层状态而"重置起点"。
什么是剪枝?
在算法中,"剪枝"(Pruning) 是一种优化搜索过程 的技术,主要用于减少不必要的计算或状态探索 ,从而提升算法效率 。它常见于回溯算法(Backtracking) 、深度优先搜索(DFS) 、广度优先搜索(BFS) 以及树/图的遍历等场景。
为什么叫"剪枝"?
这个术语来源于对搜索树的比喻:
- 每一个可能的选择构成一棵"搜索树";
- 如果某些分支不可能产生有效解或不可能优于当前已知最优解,就提前"剪掉"这些分支,避免继续深入;
- 就像园丁修剪果树的无用枝条一样,故称"剪枝"。
剪枝的核心思想:尽早排除无效或低效的搜索路径,避免浪费时间。
常见的剪枝类型
- 可行性剪枝(Feasibility Pruning)
如果当前路径已经违反问题约束条件,就不再继续。
例子:在组合求和问题中,若当前和已超过目标值,则停止继续添加数字。 - 最优性剪枝(Optimality Pruning / Bound Pruning)
如果当前路径即使继续下去也无法比已知最优解更好,就剪掉。
常用于最优化问题(如最小路径、最大价值等)。
例子:在旅行商问题(TSP)中,若当前路径长度已大于已知最短路径,则放弃。 - 重复性剪枝(Avoiding Duplicates)
避免搜索重复的状态或排列。
例子:在全排列中,若数组有重复元素,需跳过相同元素的重复选择。 - 顺序剪枝(Order-based Pruning)
通过限制选择顺序(如只允许非递减序列)来减少等价解。
例子:组合问题中只允许从当前位置往后选,避免 1,2 和 2,1 重复。
剪枝的好处:
大幅降低时间复杂度(有时从指数级降到多项式级);
减少内存占用(避免生成大量无效状态);
是解决 NP 难问题(如背包、N皇后、数独)的关键技巧。
什么是哨兵?
- 哨兵是一个人为添加的、不参与实际逻辑的辅助元素。
它的作用是简化边界条件 ,避免在循环或递归中频繁检查"是否越界"或"是否是第一个元素"。 - 在 KMP 中,这个空格就是哨兵------它永远不会被匹配(因为空格不在原始串中),但让整个算法逻辑更干净。
识别使用BFS的算法题
当看到寻求最小次数的时候,并且每一个操作的代价权重是相等的话,应该要想到BFS。
递归与迭代
递归是通过函数调用自身来解决问题。
递:程序不断深入调用自身,通常传入更小或者更简化的参数,直到达到终止条件。
归:触发终止条件后,程序从最深层的递归函数不断逐层返回,汇聚每一层的结果。
递归代码其实包含三个要素:
1.终止条件
2.递归调用
3.返回结果
迭代与递归的逻辑方式是不同的:
迭代:"自下而上"地解决问题。从最基础的步骤开始,然后不断重复或累加这些步骤,直到任务完成。
递归:"自上而下"地解决问题。将原问题分解为更小的子问题,这些子问题和原问题具有相同的形式。接下来将子问题继续分解为更小的子问题,直到基本情况时停止(基本情况的解是已知的)。
迭代的时间复杂度是O(n),递归是O(1)。
递归通常比迭代更耗费内存空间,因为递归函数每次调用自身,系统会为新开启的函数分配内存,这些数据信息存储在"栈帧空间"。
在实际中,编程语言允许的递归深度通常是有限的,过深的递归可能导致栈溢出错误。
如果函数在返回前的最后一步才进行递归调用,这种情况被称为尾递归。
图搜索问题
当题目里存在"状态"和"从一个状态走到另一个状态的规则"时,通常就可以把它翻译成图搜索问题。
判断一道题能否转换成图搜索主要需要问自己下面四个问题:
我现在在哪里?
我下一步能去哪里?
我要找什么目标?
会不会重复回到以前的位置?上述问题都有答案,可以考虑DFS或者BFS。
图搜索的本质是可达性的考虑
问能不能到达:DFS 和 BFS 都可以
问最少几步:优先 BFS
问遍历所有可能:DFS 或 BFS 都可以
问所有路径:通常 DFS / 回溯一旦问题可能死循环,那么应该想到这是图搜索,要记录 visited
DFS 是"一条路走到底",BFS 是"按距离一层一层扩散";问能不能到达时两者都能用,问最短步数时通常优先 BFS。
| 对比点 | DFS | BFS |
|---|---|---|
| 中文名 | 深度优先搜索 | 广度优先搜索 |
| 搜索方式 | 一条路走到底,再回头 | 一层一层向外扩散 |
| 常用结构 | 递归,或者栈 | 队列 |
| 适合问题 | 是否存在路径、遍历所有可能、回溯类问题 | 最短路径、最少步数、层序遍历 |
| 找到目标的特点 | 不一定是最近的目标 | 第一次找到通常就是最短距离 |
| 空间特点 | 递归深度可能很深 | 队列可能存很多同层节点 |
| 风险 | 递归太深可能栈溢出 | 队列可能占用较多内存 |
Python 的内部函数会自动捕获外层函数变量,所以这类 DFS 可以少传 arr、vis、n。
Java 的普通方法不会自动捕获另一个方法里的局部变量,所以通常要显式传参,或者把变量写成类成员变量。
Java 也有闭包,但主要体现在 lambda / 匿名内部类中,并且捕获的局部变量必须是 final 或 effectively final。
Go语言中make方法主要用于创建内置引用类型 :slice、map、channel。make创建适合输入长度不固定场景。长度固定内容明确可以不需要make。
一般来说,在go里可以使用这种格式:dfs := func(i int) bool { return true}。定义匿名函数。但是在递归中,如果要在函数内部调用自己并且使用闭包的特性,就需要写递归匿名函数。第一点:var dfs func(int) bool。先让函数名存在。第二点dfs = func(i int) bool { }。再把匿名函数赋值给它。
Rust中,vec! 为什么要设计成宏,而不是普通函数?因为宏可以在编译阶段展开代码,比普通函数更灵活。比如vec!支持这种特殊语法:vec!false; n
这里不是普通函数参数的形式,而是一种更像"语法糖"的写法。
双指针
只要题目里出现"两个有序数组 / 两个有序序列 / 要找公共元素 / 要合并 / 要比较大小",就先想双指针。
双指针不是"技巧",而是"谁小谁移动"。
集合论和位运算
首先,如果编程的题目当中,有对集合的数据类型的东西进行操作,为了使效率提高,我们通常会使用位运算的一个技巧。首先集合是可以使用二进制进行表示的。
集合可以用二进制表示,二进制从低到高第 i 位为 1 表示 i 在集合中,为 0 表示 i 不在集合中。
集合里的数字不是二进制数本身,而是二进制中哪些位置要填 1。
比如{0, 2, 3}表示的是第0位、第2位、第3位的二进制位数的值填1,第1位填0。即1101。一般一个非负整数集合 可以压缩成一个数字: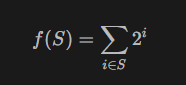
比如集合{0, 2, 3}可以压缩成二的零次方加二的二次方加二的三次方等于十三也就是二进制数目1101。
左移 i 位相当于乘以2的 i 次方。右移 i 位相当于除以2的 i 次方。
将集合和位运算连接起来,就可以提高那个算法的效率。
通过"寻找不变性"与"归一化"思维解决某种规则变换后相等问题
最关键的思维突破点是寻找变换过程中的"不变量",并利用这个不变量进行"归一化"。
题目定义:如果两个字符串可以通过全员循环移位(Caesar Cipher)变得相等,它们就是相似的。
我们需要思考:在一个字符串不断变幻的过程中,什么东西是始终保持不变的?
虽然字母在变,但相邻字母之间的相对距离(差值)是不变的。
结论: 只要两个字符串的"相邻字符差值序列"完全相同,它们就是相似的。
归一化思维:
既然一个字符串可以变成 26 种样子,那我们就强制规定:所有字符串都必须变成"以字母 'a' 开头"的那个样子。
就是让一个字符串向另一个字符串靠齐。
操作方法:
看字符串的第一个字母距离 'a' 有多远(设偏移量为 d)。
把字符串里的每一个字母都向前移动 d 位。
如果 fusion 归一化后变成了 af...,而 layout 归一化后也变成了 af...,那它们就一定相似。
这种将"多对多"的比较转化为"多对一"的映射,是解决匹配类问题的通用套路。
"在一堆数里找特定组合"的题目时,"总和减去部分等于剩余"是一种非常经典的转化技巧。
它能把一个涉及 n 个数的复杂组合问题,降维成一个"两数之和"的问题。
前缀和思想
前缀和的核心思想是:提前把"从开头到当前位置的累计结果"存起来,以后查询任意区间时,就不用重新遍历,而是用两次查询相减,直接得到答案。
前缀和最适合处理"频繁查询区间和、区间计数、区间是否存在某种元素" 的问题。只要一个题目反复问你"某一段里面有多少、总和是多少、是否出现过",就应该优先想到前缀和。
前缀和到底是什么?
假设有一个数组:nums = 2, 4, 1, 7, 3
如果你想知道下标 1 到下标 3 的元素和,也就是:
nums1 + nums2 + nums3
普通做法是直接加:4 + 1 + 7 = 12
如果只查一次,这样当然没问题。但是如果题目让你查很多次,比如:
求 [1, 3] 的和
求 [0, 4] 的和
求 [2, 4] 的和
求 [1, 1] 的和
...每次都重新遍历一遍区间,就会很慢。前缀和的想法是:
我先提前算好"从数组开头到每个位置之前"的总和。
以后想求任意区间和,就用两个前缀和相减。前缀和数组怎么定义?
最常见、最推荐的定义方式是:
prefix0 = 0
prefixi + 1 = nums0 + nums1 + ... + numsi
也就是说:
prefixi 表示 nums0 到 numsi - 1 的和
注意这里 prefix 比原数组 nums 多一位。
例如:nums = 2, 4, 1, 7, 3
构造前缀和:
prefix[0] = 0
prefix[1] = 2
prefix[2] = 2 + 4 = 6
prefix[3] = 2 + 4 + 1 = 7
prefix[4] = 2 + 4 + 1 + 7 = 14
prefix[5] = 2 + 4 + 1 + 7 + 3 = 17所以:
nums: [2, 4, 1, 7, 3]
index: 0 1 2 3 4
prefix: [0, 2, 6, 7, 14, 17]
index: 0 1 2 3 4 5为什么区间和可以用两个前缀和相减?
如果你想求:numsleft + numsleft + 1 + ... + numsright
也就是区间 left, right 的和。
按照前缀和定义:prefixright + 1 = nums0 + nums1 + ... + numsright
而:prefixleft = nums0 + nums1 + ... + numsleft - 1
两者相减:prefixright + 1 - prefixleft
前面重复的部分会被消掉,剩下:numsleft + numsleft + 1 + ... + numsright
所以公式是:区间 left, right 的和 = prefixright + 1 - prefixleft
这个公式非常重要。