Github:https://github.com/sgl-project/sglang/tree/main/sgl-model-gateway
Overview
SGLang Model Gateway 是一套面向大规模 LLM 部署场景的高性能模型路由控制面与数据面系统,专为 SGLang 推理运行时深度优化,同时对外暴露兼容 OpenAI 标准的 API 接口,可以无缝融入现有的 AI 应用生态。
简单来说,SGLang Model Gateway 是一个高性能网关组件,负责统一对外提供 API 接口,在内部完成请求路由、负载均衡和服务调度,将推理请求分发到合适的后端模型实例,支持多模型、多节点部署,同时保证推理服务在高并发场景下的稳定性和可观测性。
- 统一控制平面:提供统一的 worker 注册(Regular Worker、Prefill Worker 和 Decode Worker)、监控与调度能力,支持异构模型集群
- 多协议数据平面:支持多种协议统一路由,所有协议共享重试、限流、熔断机制
- 高性能 gRPC Pipeline:基于原生 Rust 实现高吞吐、低延迟的推理服务,兼容 OpenAI
- 多模型推理网关(IGW) :通过
--enable-igw开启,动态创建多套 Router,支持按模型粒度下发策略 - 会话状态集中管理:在 Router 层集中管理聊天上下文,会话历史与响应结果统一存储在网关层,避免将历史数据泄露给上游模型服务商,所有数据处理均在 Router 内完成,保障企业隐私
- 可靠性 Reliability core:重试机制(retry with jitter)、Worker 级熔断、限流与排队、后台健康检查、缓存感知负载监控
- 全面的可观测性: 40+ 项 Prometheus 指标、OpenTelemetry 链路追踪与结构化日志、Request ID 全链路透传
整体架构
系统架构分为两个核心层次:
控制面
负责 Worker 的生命周期管理
主要组成模块:
| 模块名称 | 功能描述 |
|---|---|
| Worker Manager | Worker 的注册与管理 |
| Job Queue | Worker 的添加与移除 |
| Load Monitor | 为 cache-aware 和 power-of-two 策略提供实时工作负载统计信息 |
| Health Checker | Worker 健康检查 |
| Tokenizer Registry | 管理系统中动态注册的 Tokenizer |
- Worker 管理器 是控制面的核心,通过主动拉取
/server_info和/get_model_info,验证新加入的 Worker(模型服务实例)是否健康、探测其能力(支持什么模型、什么参数规格),并注册到全局注册表(Registry)中, Worker 下线时进行删除 - 任务队列 负责将 Worker 的增加和删除操作串行化处理,避免并发操作引发状态不一致。每一个操作都有独立的任务 ID,客户端可以通过
/workers/{worker_id}接口查询 Worker 的状态 - 负载监控采集各 Worker 的实时负载,给路由策略(Cache-Aware、Power-of-Two)提供负载统计信息
- 健康检查 负责周期性探活,并暴露到 Router 侧的 Metrics
- 分词器注册表 支持动态注册,异步从 HuggingFace Hub 或本地路径加载
数据面
负责请求的路由与转发,处理实际的推理请求
主要组成模块:
| 模块名称 | 功能描述 |
|---|---|
| HTTP Router | 提供完整的 API(regular & PD)以及相关的管理接口 |
| gRPC Router | 直接将 Tokenized Request 发送到 gRPC Worker |
| OpenAI Router | 用于代理 OpenAI 兼容 API 请求到外部模型服务 |
- HTTP Router(Regular & PD) 面向主流 LLM 场景,提供
/generate,/v1/chat/completions,/v1/completions,/v1/responses,/v1/embeddings,/v1/rerank,/v1/classify,/v1/tokenize,/v1/detokenize等完整 API 和管理接口 - gRPC Router 全 Rust 实现的 OpenAI 兼容 gRPC 推理网关,支持单实例和 PD 两种模式,并支持 Embedding 和分类任务
- OpenAI Router 作为中间代理层,对外提供 OpenAI 兼容 API,对内把请求转发给 OpenAI、xAI、Gemini 等 OpenAI 等服务,但 Chat History 数据和管理在 Router 侧,保障企业数据隐私安全
部署模式
单进程部署
在单进程中同时启动 Router 和一组 SGLang Worker,可以直接用 sglang_router.launch_server
bash
python -m sglang_router.launch_server \
--model Qwen/Qwen3-4B \
--tp-size 1 \
--host 0.0.0.0 \
--port 30000分开部署(HTTP 模式)
Worker 与 Router 独立部署
bash
# Worker nodes
python3 -m sglang.launch_server --model Qwen/Qwen3-4B --port 8000
python3 -m sglang.launch_server --model Qwen/Qwen3-4B --port 8001
# Router node
python3 -m sglang_router.launch_router \
--worker-urls http://worker1:8000 http://worker2:8001 \
--policy cache_aware \
--host 0.0.0.0 --port 30000gRPC 模式部署
bash
# Workers
python3 -m sglang.launch_server \
--model Qwen/Qwen3-4B \
--grpc-mode \
--port 20000
# Router
python3 -m sglang_router.launch_router \
--worker-urls grpc://127.0.0.1:20000 \
--model-path Qwen/Qwen3-4B \
--reasoning-parser qwen3 \
--host 0.0.0.0 --port 8080使用 gRPC 模式,必须提供 --tokenizer 路径或 --model 路径
- HTTP 模式:直接转发原始文本给 Worker,由 Worker 负责 tokenizer
- gRPC 模式:传递的是 token ID 序列(通信协议),Router 层提前完成 tokenization,才能组装 gRPC 消息下发给 Worker
PD 分离部署
bash
python3 -m sglang_router.launch_router \
--pd-disaggregation \
--prefill http://prefill1:30001 9001 \
--decode http://decode1:30011 \
--prefill-policy cache_aware \
--decode-policy power_of_twoOpenAI 后端代理模式
将请求转发到 OpenAI 兼容后端,不用自己部署模型,同时把会话状态和历史上下文信息保留在本地 Router
bash
python3 -m sglang_router.launch_router \
--backend openai \
--worker-urls https://api.openai.com \
--history-backend memory # 对话历史保存在本地内存这个模式 Router 实例只支持一个 --worker-urls
多模型网关模式
普通 Router 模式 与 IGW 模式 区别:
-
普通 Router 模式下,把一批同 Worker 交给 Router 管理,它只把请求分发给哪台机器,只有一个模型。如果想同时对外提供多个模型,得启多个 Router 实例,需要客户端知道哪个端口是哪个模型,非常麻烦
- 无论客户端请求里的 model 字段写的是什么,选 Worker 的时候会把 model_id 强制变成 None,直接从全量 Worker 里按负载均衡策略随机选一个
-
IGW(Inference Gateway Mode)模式:一个入口,同时管理多个模型、多种后端。内部不再是一个Router,而是一个 RouterManager 同时持有多种路由器实例,根据请求的 model 字段和 Worker 类型自动分发
- 开启服务发现时会自动强制启用 IGW 模式(代码里写死了),K8s 动态发现的 Pod 可能跑着不同模型, IGW 模式用模型标签做正确路由
rust
客户端
│ POST /v1/chat/completions
│ model: "qwen2-72b" ◄── 路由器根据 model 字段决定发到哪里
▼
RouterManager
├── HTTP Regular Router ──► SGLang Worker(本地推理)
├── HTTP PD Router ──► Prefill + Decode Worker 组
├── gRPC Regular Router ──► gRPC Worker(本地推理)
├── gRPC PD Router ──► gRPC PD Worker 组
└── OpenAI Router ──► 外部 OpenAI
rust
// 在 startup() 解析完 CLI 参数之后,在构建 RouterConfig 之前,检查:如果开了 --service-discovery 但没有加 --enable-igw,就强制把 enable_igw 设为 true
if cli_args.service_discovery && !cli_args.enable_igw {
println!("INFO: IGW mode automatically enabled because service discovery is turned on");
cli_args.enable_igw = true;
}启动方式:
bash
# 启动网关
./target/release/sgl-model-gateway \
--enable-igw \
--policy cache_aware \
--max-concurrent-requests 512 # 并发上限
# 动态注册 Worker
curl -X POST http://localhost:30000/workers \
-H "Content-Type: application/json" \
-d '{
"url": "http://worker-a:8000",
"model_id": "mistral",
"priority": 10, # 优先级(调度用)
"labels": {"policy": "power_of_two"} # 标签路由
}'API 接口
推理 API
| 方法 | Path | 类型 | 说明 |
|---|---|---|---|
POST |
/generate |
原生接口 | SGLang 原生生成接口,非 OpenAI 标准接口 |
POST |
/v1/chat/completions |
对话生成 | OpenAI 兼容聊天接口,支持流式输出、工具调用等,多轮对话 |
POST |
/v1/completions |
文本补全 | OpenAI 兼容文本补全接口,适合单轮 prompt |
POST |
/v1/embeddings |
向量生成 | 生成文本向量,用于语义检索 RAG、聚类 (HTTP and gRPC) |
POST |
/v1/rerank, /rerank |
重排序 | 针对检索候选进行重排序,用于 RAG |
POST |
/v1/classify |
分类 | 用于文本分类(意图识别、内容审核、路由等场景) |
bash
curl -s http://192.168.57.211:8000/generate \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"prompt": "介绍一下湖南",
}'
bash
curl -s http://192.168.57.211:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"messages": [
{
"role": "user",
"content": "介绍一下湖南"
}
],
"max_tokens": 200,
"temperature": 0.7,
"chat_template_kwargs": {
"enable_thinking": false
}
}'
bash
curl -s http://192.168.57.211:8000/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"prompt": "翻译成英文:今天天气很好,我们去公园散步吧。",
"max_tokens": 120,
"temperature": 0.2,
"stream": false
}'
# 输出 "The weather is great today..."
bash
# 把文本变成向量(embedding)
curl -s http://192.168.57.211:8000/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"input": [
"How do I prune tomato plants?",
"Best time to water succulents"
]
}'
# 输出 [0.123, -0.88, 0.42, ...]
bash
curl -s http://192.168.57.211:8000/v1/rerank \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"query": "renewable energy incentives in Europe", # 用户问题
"documents": [ # 候选文档
"EU launches new subsidies for onshore wind in 2025.",
"Local US state offers credits for residential solar.",
"Survey about consumer preferences for electric cars in China."
],
"top_k": 2
}'
# 计算用户问题与文档的相关性,对已有文档排序,输出前两个文档,用于 RAG
yaml
# 给文本打标签
curl -s http://192.168.57.211:8000/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"inputs": [
"Customer says: The new firmware bricked my router, please fix ASAP.",
"Comment: Love this product! Shipping was fast."
],
"labels": ["Urgent Support", "Positive Feedback", "Neutral"],
"explain": true # 解释为什么这么分类
}'
# 输出:["Urgent Support", "Positive Feedback"]注意:当使用 /v1/embeddings、/v1/rerank、/rerank接口,启动服务时需要加参数 --is-embedding
分词 API
| 方法 | Path | 说明 |
|---|---|---|
POST |
/v1/tokenize |
将文本切分为 Token ID,支持单条或批量请求 |
POST |
/v1/detokenize |
将 Token ID 序列反解为文本,支持单条或批量请求 |
POST |
/v1/tokenizers |
注册新的分词器(异步执行),返回任务信息 |
GET |
/v1/tokenizers |
列出当前已注册的所有分词器 |
GET |
/v1/tokenizers/{id} |
根据 ID 查询分词器的详细信息 |
GET |
/v1/tokenizers/{id}/status |
查询分词器的状态 |
DELETE |
/v1/tokenizers/{id} |
从注册表中删除分词器 |
yaml
# Tokenize(单条文本)
curl -s http://192.168.57.211:8000/v1/tokenize \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"prompt": "Hello, world!"
}'
# 输出 [15339, 11, 1917, 0]
# Tokenize(批量文本)
curl -s http://192.168.57.211:8000/v1/tokenize \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"prompt": ["Hello", "World", "How are you?"]
}'
# Detokenize(单条)
curl -s http://192.168.57.211:8000/v1/detokenize \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"model": "Qwen3.5-35B-A3B-FP8",
"tokens": [15339, 11, 1917, 0],
"skip_special_tokens": true # 去掉特殊 token(如 <bos>, <eos>)
}'
# 输出 "Hello, world!"
# 注册 Tokenizer
curl -s -X POST http://192.168.57.211:8000/v1/tokenizers \
-H "Content-Type: application/json" \
-H "Authorization: Bearer qwen35-test-server" \
-d '{
"name": "qwen35",
"source": "Qwen3.5-35B-A3B-FP8"
}'
# 查询 Tokenizer 列表
curl -s http://192.168.57.211:8000/v1/tokenizers \
-H "Authorization: Bearer qwen35-test-server"
# 查看单个 Tokenizer 信息
curl -s http://192.168.57.211:8000/v1/tokenizers/a6fe6965-a3b9-49c7-b00e-91a10141ab17 \
-H "Authorization: Bearer qwen35-test-server"
# 查看 Tokenizer 加载状态
curl -s http://192.168.57.211:8000/v1/tokenizers/a6fe6965-a3b9-49c7-b00e-91a10141ab17/status \
-H "Authorization: Bearer qwen35-test-server"
# 删除 Tokenizer
curl -s -X DELETE http://192.168.57.211:8000/v1/tokenizers/a6fe6965-a3b9-49c7-b00e-91a10141ab17 \
-H "Authorization: Bearer qwen35-test-server"解析器 API
用于从 LLM 原始输出中提取结构化信息 ,比如把模型输出这种"混合文本",拆成结构化字段。相当于 parser 用来告诉 router ,要用哪种规则去理解和拆分模型输出,不同模型输出格式不一样,parser 参数用于指定模型输出的解析策略,不同模型可能采用不同的输出格式(如 <think> 标签或 JSON),网关通过对应解析器将非结构化文本转换为结构化数据。
| 方法 | Path | 说明 |
|---|---|---|
| POST | /parse/reasoning |
从模型输出中分离推理内容(如 <think> 标签)与最终文本 |
| POST | /parse/function_call |
从文本中解析函数调用或工具调用信息(如 JSON 格式) |
支持的推理解析器:
| Parser ID | 适用模型 |
|---|---|
deepseek-r1 |
DeepSeek-R1 系列 |
qwen3 |
Qwen-3 系列 |
qwen3-thinking |
Qwen-3 Thinking 变体 |
kimi |
Kimi K2 |
glm45 |
GLM-4.5/4.6/4.7 系列 |
step3 |
Step-3 系列 |
minimax |
MiniMax 系列 |
支持的函数调用解析器 :json、python、xml
yaml
# 请求:原始输出字符串 JSON
{
"text": "<think>Let me analyze this step by step...</think>The answer is 42.",
"parser": "deepseek-r1"
}
# 响应:拆分成两个字段
{
"normal_text": "The answer is 42.",
"reasoning_text": "Let me analyze this step by step..."
}
yaml
# 请求:字符串 JSON
{
"text": "{\"name\": \"get_weather\", \"arguments\": {\"city\": \"NYC\"}}",
"parser": "json"
}
# 响应:解析成结构化对象
{
"name": "get_weather",
"arguments": {
"city": "NYC"
}
}分类 API
| 方法 | Path | 说明 |
|---|---|---|
| POST | /v1/classify |
用于执行文本分类任务 |
基于序列分类模型(Sequence Classification Models),例如:
- Qwen 系列分类模型(如
Qwen2ForSequenceClassification) - BERT 分类模型(如
BertForSequenceClassification)
可以理解为用专门的分类模型,给一段文本打标签,把文本直接映射成标签 + 概率(不生成文本)
yaml
# 请求示例
curl http://localhost:30000/v1/classify \
-H "Content-Type: application/json" \
-d '{
"model": "qwen/Qwen2.5-1.5B-apeach",
"input": "I love this product!"
}'
# 响应示例
{
"id": "classify-a1b2c3d4-5678-90ab-cdef-1234567890ab",
"object": "list",
"created": 1767034308,
"model": "jason9693/Qwen2.5-1.5B-apeach",
"data": [
{
"index": 0,
"label": "positive", # 预测类别,来自模型的配置
"probs": [0.12, 0.88], # 每个类别的概率
"num_classes": 2 # 类别数量
}
],
"usage": {
"prompt_tokens": 6,
"completion_tokens": 0,
"total_tokens": 6
}
}会话 API
| 方法 | Path | 说明 |
|---|---|---|
| POST | /v1/responses |
创建后台响应 |
| GET | /v1/responses/{id} |
获取已存储的响应 |
| POST | /v1/responses/{id}/cancel |
取消后台响应 |
| DELETE | /v1/responses/{id} |
删除响应 |
| GET | /v1/responses/{id}/input_items |
列出响应的输入项 |
| POST | /v1/conversations |
创建会话 |
| GET | /v1/conversations/{id} |
获取会话信息 |
| POST | /v1/conversations/{id} |
更新会话 |
| DELETE | /v1/conversations/{id} |
删除会话 |
| GET | /v1/conversations/{id}/items |
列出会话中的所有消息项 |
| POST | /v1/conversations/{id}/items |
向会话中添加消息项 |
| GET | /v1/conversations/{id}/items/{item_id} |
获取指定会话消息项 |
| DELETE | /v1/conversations/{id}/items/{item_id} |
删除指定会话消息项 |
Worker 管理 API
管理后端推理 Worker
| 方法 | Path | 说明 |
|---|---|---|
| POST | /workers |
注册 Worker |
| GET | /workers |
列出所有 Worker(含健康、负载等信息) |
| GET | /workers/{worker_id} |
查看指定 Worker 或任务队列信息 |
| PUT | /workers/{worker_id} |
更新 Worker(异步) |
| DELETE | /workers/{worker_id} |
删除 Worker(异步) |
bash
curl -X POST http://localhost:30000/workers \
-H "Content-Type: application/json" \
-d '{"url":"http://0.0.0.0:31000","worker_type":"regular"}' # worker_type:regular / prefill / decode
bash
curl http://localhost:30000/workers
# 返回
{
"workers": [
{
"id": "2f3a0c3e-...",
"url": "http://0.0.0.0:31378",
"model_id": "mistral",
"priority": 50, # 优先级,用于调度
"cost": 1.0, # 成本,用于调度
"worker_type": "regular",
"is_healthy": true,
"load": 0, # 当前负载
"connection_mode": "Http"
}
],
"total": 1, # worker 数量
"stats": { # 统计信息
"prefill_count": 0,
"decode_count": 0,
"regular_count": 1
}
}管理和健康 API
| 方法 | Path | 说明 |
|---|---|---|
| GET | /liveness |
存活检查(始终返回 OK),判断服务有没有挂 |
| GET | /readiness |
就绪检查(检查 worker 是否可用,是否可以处理推理请求) |
| GET | /health |
liveness 的别名 |
| GET | /health_generate |
生成能力健康检查,实际跑一次生成检查推理链路是否正常 |
| GET | /engine_metrics |
获取 worker 推理引擎内部指标(request throughput、队列长度、cache 命中率...) |
| GET | /v1/models |
列出可用模型 |
| GET | /get_model_info |
获取模型详细信息 |
| GET | /server_info |
获取服务器信息 |
| POST | /flush_cache |
清空所有缓存(KV cache 等) |
| GET | /get_loads |
获取所有 worker 负载 |
| POST | /wasm |
上传 WASM 模块 |
| GET | /wasm |
列出 WASM 模块 |
| DELETE | /wasm/{module_uuid} |
删除 WASM 模块 |
WASM 可理解为插件模块扩展机制,可自定义。例如在请求前做处理或者在响应后做处理,以及加自定义逻辑。
负载均衡策略
提供 5 种负载均衡策略:
| 策略 | 说明 | 用法 |
|---|---|---|
| random | 均匀随机选择 Worker | --policy random |
| round_robin | 按顺序轮询 Worker,Worker A → B → C → A → B → C | --policy round_robin |
| power_of_two | 随机选择两个 Worker,选负载更低的一个 | --policy power_of_two |
| cache_aware | 结合缓存命中与负载均衡(默认策略) | --policy cache_aware |
| bucket | 按负载分桶并动态调整边界,按负载分组(轻 / 中 / 重)选轻的桶 | --policy bucket |
Cache-Aware 参数详解:
| 参数 | 默认值 | 说明 |
|---|---|---|
--cache-threshold |
0.3 | 判定 cache 命中的最小前缀匹配比例 |
--balance-abs-threshold |
64 | 触发负载均衡的绝对负载差阈值 |
--balance-rel-threshold |
1.5 | 触发负载均衡的相对负载比例阈值 |
--eviction-interval-secs |
120 | cache 清理周期(秒) |
--max-tree-size |
67108864 | cache 树的最大节点数 |
- --cache-threshold 0.3:比如请求命中率为 40%,则为命中;20%则不命中。若 prompt 很相似,可调高阈值,prompt 很随机则调低
- --balance-abs-threshold 64:比如 Worker A = 100;Worker B = 20;相差 80 > 64,触发负载均衡
- --balance-rel-threshold 1.5:比如 Worker A = 30;Worker B = 10;比例 30/10 = 3 > 1.5,触发负载均衡
- --eviction-interval-secs 120:两分钟清理一次 cache ,防止 cache 无限增长,控制内存
- --max-tree-size 67108864:cache 树最大节点数
关键代码实现:目录 sgl-model-gateway/src/policies/
- random
- 文件: src/policies/random.rs
- 过滤出所有 healthy worker,随机选一个 Worker,返回对应 worker 下标
- 无状态、实现最简单,可能连续打到同一台机器
rust
async fn select_worker(&self, workers, _info) -> Option<usize> {
let healthy_indices = get_healthy_worker_indices(workers);
if healthy_indices.is_empty() { return None; }
let mut rng = rand::rng();
// 在健康节点中随机选一个下标
let random_idx = rng.random_range(0..healthy_indices.len());
Some(healthy_indices[random_idx])
}- round_robin
- 文件: src/policies/round_robin.rs
- 维护一个全局计数器,每次请求让计数器加一,用计数器对健康节点数取模,依次轮转
- 每次都是对当前健康节点取模,而不是全部节点。所以某个节点宕机后,剩余节点继续均匀轮转
- 3 个节点,节点 1 宕机后:
- count: 0 1 2 3 4 5 ...
- 节点: 0 2 0 2 0 2 ...
- 3 个节点,节点 1 宕机后:
rust
pub struct RoundRobinPolicy {
counter: AtomicUsize, // 原子计数器
}
async fn select_worker(&self, workers, _info) -> Option<usize> {
let healthy_indices = get_healthy_worker_indices(workers);
if healthy_indices.is_empty() { return None; }
// fetch_add 原子自增,返回自增前的值
let count = self.counter.fetch_add(1, Ordering::Relaxed);
// 对健康节点数取模,实现循环
let selected_idx = count % healthy_indices.len();
Some(healthy_indices[selected_idx])
}- power_of_two
- 文件:src/policies/power_of_two.rs
- 不是所有节点都比一遍(开销大),也不是完全随机(不感知负载)。折中方案:随机挑两个节点,选负载更低的那个
- 随机选 idx1、随机选 idx2,两个 worker 都有 token 负载缓存,直接比较 token 数,没有则比较请求数
rust
async fn select_worker(&self, workers, _info) -> Option<usize> {
let healthy_indices = get_healthy_worker_indices(workers);
// 第一步:随机选两个不同的节点
let mut rng = rand::rng();
let idx1 = rng.random_range(0..healthy_indices.len());
// 用偏移量保证 idx2 ≠ idx1,O(1) 实现,无需循环重采样
let idx2 = (idx1 + 1 + rng.random_range(0..healthy_indices.len() - 1))
% healthy_indices.len();
// 第二步:比较两个节点的负载
let (load1, load2) = match (load1_tokens, load2_tokens) {
(Some(t1), Some(t2)) => (t1, t2), // 优先用 token 数
_ => (worker1.load() as isize, worker2.load() as isize), // 缺数据则用请求数
};
// 第三步:选负载更低的
let selected_idx = if load1 <= load2 { worker_idx1 } else { worker_idx2 };
workers[selected_idx].increment_processed();
Some(selected_idx)
}- cache_aware
- 文件: src/policies/cache_aware.rs
rust
每个请求到来
→ 计算负载差异
→ [是否失衡]
→ 是 → 最短队列(兜底)
→ 否 → 前缀树匹配
→ [match_rate > 阈值?]
→ 是 → 路由到命中节点
→ 否 → 路由到负载最小节点
→ 更新前缀树* 负载失衡检测
rust
// 必须同时满足 绝对差 和 相对比,才认为失衡
// 避免在负载都很低时(比如都只有 1、2 个请求)误判为失衡
let is_imbalanced =
max_load.saturating_sub(min_load) > self.config.balance_abs_threshold // 绝对差 > 32
&& (max_load as f32) > (min_load as f32 * self.config.balance_rel_threshold); // 且比值 > 1.1* 缓存命中路由
rust
let result = tree.prefix_match_with_counts(text); // 找最长前缀匹配
let match_rate = result.matched_char_count as f32 / result.input_char_count as f32;
if match_rate > self.config.cache_threshold { // 假设 0.5,即超过一半前缀命中
// 路由到命中节点(有缓存)
workers.iter().position(|w| w.url() == result.tenant)
} else {
// 前缀匹配率低,说明是新请求,选最空闲的节点
healthy_indices.iter().min_by_key(|&&idx| workers[idx].load())
}* 清理树节点
* 树会随时间不断增长,后台线程定期清理最久未使用的叶节点,防止内存溢出
rust
// 构造时启动后台任务
PeriodicTask::spawn(config.eviction_interval_secs, "Eviction", move || {
for tree in trees.iter() {
tree.evict_tenant_by_size(max_tree_size); // 超过 10000 个节点时开始淘汰
}
})- bucket
-
文件: src/policies/bucket.rs
-
按负载分组(轻 / 中 / 重),优先选轻的桶
- 把请求按文本长度(字符数)分桶,不同长度范围的请求路由到不同的节点,并随着流量变化自适应调整分桶边界
-
可以理解为根据请求长度,确定目标桶,在目标桶里找当前负载最低的 worker
-
真正解决的问题是避免长请求占用资源拖慢短请求,从而降低整体尾部延迟
-
rust
pub struct Bucket {
boundary: Vec<Boundary>, // 分桶边界表:[{url, [min, max]}, ...]
chars_per_url: HashMap<String, usize>, // 滑动窗口内各节点累计处理的字符数
request_list: VecDeque<SequencerRequest>, // 近期请求队列(用于时间窗口统计)
period: usize, // 时间窗口长度(毫秒)
}
rust
async fn select_worker(&self, workers, info) -> Option<usize> {
// 1. 统计请求文本的字符数
let char_count = info.request_text.map(|t| t.chars().count()).unwrap_or(0);
// 2. 检查是否失衡(比较各节点的累计字符数)
let is_imbalanced = abs_diff > balance_abs_threshold && max > min * rel_threshold;
let prefill_url = if is_imbalanced {
// 失衡:选当前承载字符数最少的节点
chars_per_url.iter().min_by_key(|(_, &chars)| chars)
} else {
// 均衡:按字符数查边界表,用二分查找定位到对应节点
bucket.find_boundary(char_count)
};
// 3. 更新统计:将本次请求的字符数加到对应节点,并清理过期请求
bucket.post_process_request(char_count, prefill_url);
}流量控制
重试机制
请求失败时,不是立刻报错,等待一段时间(backoff),按策略重试,重复直到成功或达到最大次数
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 http://worker2:8001 \
--retry-max-retries 5 \
--retry-initial-backoff-ms 50 \
--retry-max-backoff-ms 30000 \
--retry-backoff-multiplier 1.5 \
--retry-jitter-factor 0.2参数说明:
| 参数 | 默认值 | 说明 |
|---|---|---|
--retry-max-retries |
5 | 最大重试次数 |
--retry-initial-backoff-ms |
50 | 初始等待时间(毫秒) |
--retry-max-backoff-ms |
5000 | 最大等待时间(毫秒) |
--retry-backoff-multiplier |
2.0 | 指数退避倍数,每次放大倍数 |
--retry-jitter-factor |
0.1 | 随机抖动因子(0.0-1.0) |
--disable-retries |
false | 是否关闭重试(底层实现是把 max_retries 强制设为 1,走完一次就返回) |
实现:
- 可重试的状态码:
rust
pub fn is_retryable_status(status: StatusCode) -> bool {
matches!(
status,
StatusCode::REQUEST_TIMEOUT // 408 请求超时
| StatusCode::TOO_MANY_REQUESTS // 429 请求过多(上游限流)
| StatusCode::INTERNAL_SERVER_ERROR // 500 服务内部错误
| StatusCode::BAD_GATEWAY // 502 错误网关
| StatusCode::SERVICE_UNAVAILABLE // 503 服务不可用
| StatusCode::GATEWAY_TIMEOUT // 504 网关超时
)
}* 注意:400 BAD_REQUEST / 404 / 401 等客户端错误不重试,因为重试无意义。- 指数退避 :指数退避 + Jitter 随机扰动
- 每次重试之前不是立刻重发,而是等待一段时间,且等待时间按指数增长:第 1 次失败后等:50ms、第 2 次失败后等:75ms、第 3 次失败后等:112ms ......上限:30 秒
rust
pub fn calculate_delay(config: &RetryConfig, attempt: u32) -> Duration {
// 指数增长:initial * multiplier^attempt,倍数默认 1.5,上限 max_backoff_ms
let pow = config.backoff_multiplier.powi(attempt as i32);
let delay_ms = ((config.initial_backoff_ms as f32 * pow) as u64)
.min(config.max_backoff_ms);
// Jitter:D' = D * (1 + U[-j, +j]),均匀随机扰动
// 目的:防止多个客户端同时重试打垮恢复中的服务
if jitter > 0.0 {
let jitter_scale: f32 = rng.random_range(-jitter..=jitter);
let jitter_ms = (delay_ms as f32 * jitter_scale).round().max(-(delay_ms as f32));
let adjusted = (delay_ms as i64 + jitter_ms as i64).max(0) as u64;
return Duration::from_millis(adjusted);
}
Duration::from_millis(delay_ms)
}- 重试时换 Worker:
- 每次重试不是对同一个 Worker 再发一次,而是重新走一遍 Worker 选择流程
rust
let response = RetryExecutor::execute_response_with_retry(
&self.retry_config,
|_attempt| async {
// 每次都重新调用 route_typed_request_once,其中包含 select_worker
self.route_typed_request_once(headers, typed_req, route, model_id, is_stream, &text).await
},
|res, _attempt| is_retryable_status(res.status()),
|delay, attempt| {
Metrics::record_worker_retry(...);
Metrics::record_worker_retry_backoff(attempt, delay);
},
|| Metrics::record_worker_retries_exhausted(...),
).await;熔断机制
熔断器的作用是快速失败:当某个 Worker 被判定为不健康,直接跳过它,不发请求,立刻选其他 Worker
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 http://worker2:8001 \
--cb-failure-threshold 5 \
--cb-success-threshold 2 \
--cb-timeout-duration-secs 30 \
--cb-window-duration-secs 60参数说明:
| 参数 | 默认值 | 说明 |
|---|---|---|
--cb-failure-threshold |
5 | 连续失败次数阈值(触发熔断) |
--cb-success-threshold |
2 | 半开状态恢复所需成功次数(成功多少次恢复) |
--cb-timeout-duration-secs |
30 | 熔断后等待恢复时间(秒)(熔断多久后尝试恢复) |
--cb-window-duration-secs |
60 | 统计失败的时间窗口 |
--disable-circuit-breaker |
false | 是否关闭熔断器 |
熔断状态:
| 状态 | 说明 |
|---|---|
| Closed | 正常状态,所有请求正常转发 |
| Open | 熔断状态,选 Worker 时直接过滤掉,不发任何请求 |
| Half-Open | 半开状态,尝试恢复(服务可能恢复了,放行少量请求试探,成功足够多次则关闭熔断,任意失败则重新打开) |
rust
正常 连续失败达阈值 探测请求成功
Closed ─────────────────► Open ──────────────► Half-Open ──► Closed
◄────────────────
探测请求失败继续 Open实现:
- 状态检查与自动转换
rust
pub fn can_execute(&self) -> bool {
let state = self.state(); // 调用 check_and_update_state_returning 获取当前状态
match state { // 根据状态决定是否放行
CircuitState::Closed => true,
CircuitState::Open => false,
CircuitState::HalfOpen => true, // HalfOpen 允许放行,允许少量请求通过,用来测试服务是否恢复
}
}
fn check_and_update_state_returning(&self) -> CircuitState {
let state = CircuitState::from_int(self.state.load(Ordering::Acquire)); // 读取当前状态
// Open 状态下检查是否到了 timeout,到了则切到 HalfOpen
if state == CircuitState::Open {
// 从进入 Open 状态到现在过了多久
let elapsed_ms = now_ms().saturating_sub(self.last_state_change_ms.load(Ordering::Acquire));
if elapsed_ms >= self.config.timeout_duration.as_millis() as u64 { // 判断是否超过 timeout
if self.state.compare_exchange(STATE_OPEN, STATE_HALF_OPEN, ...).is_ok() {
// 完成了状态转换
info!("Circuit breaker: open -> half_open");
return CircuitState::HalfOpen;
}
// 其他线程已转换,重新读
}
}
state
}限流与排队
控制流量,避免系统过载
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 http://worker2:8001 \
--max-concurrent-requests 256 \
--rate-limit-tokens-per-second 512 \
--queue-size 128 \
--queue-timeout-secs 30| 参数 | 说明 |
|---|---|
--max-concurrent-requests |
最大并发请求数 |
--rate-limit-tokens-per-second |
每秒 token 速率限制 |
--queue-size |
请求队列最大长度 |
--queue-timeout-secs |
请求排队超时时间 |
超过并发限制的请求在FIFO队列中等待。
- 队列已满:返回
429 Too Many Requests - 排队超时:返回
408 Request Timeout
bash
请求进入 → 是否超过并发限制?
├─ 否 → 直接执行
└─ 是 → 进入队列 → 队列已满?
├─ 是 → 返回 429
└─ 否 → 等待 → 等待超时?
├─ 是 → 返回 408
└─ 否 → 执行请求代码文件:
- 实现:用 token 桶(Token Bucket)来控制并发。桶里放若干 token,每个请求进来消耗一个,请求结束后归还。桶空了就不接新请求。
rust
pub struct TokenBucket {
inner: Arc<Mutex<TokenBucketInner>>, // parking_lot::Mutex(同步安全,可在 Drop 中使用)
notify: Arc<Notify>, // tokio::sync::Notify 唤醒等待者
capacity: f64, // 最大令牌数(突发容量)
refill_rate: f64, // 每秒补充令牌数(0 = 纯并发限制模式)
}
struct TokenBucketInner {
tokens: f64, // 当前剩余令牌
last_refill: Instant, // 上次计算补充的时间
}-
两种工作模式
- 并发限制模式:token 不自动补充,靠请求结束后手动归还。桶的大小就是最大并发数,这是默认模式,用max_concurrent_requests 配置
- 速率限制模式:token 按时间自动补充,每秒补充 N 个,用完需等待。适合控制 QPS 而不只是并发数。用rate_limit_tokens_per_second 单独配置
-
补充令牌的方式
- 每次有请求尝试取 token 时,先算一下距上次取 token 过了多少时间,按比例补充相应数量,每次 try_acquire 时才计算时间差并补充
rust
fn try_acquire_sync(&self, tokens: f64) -> Result<(), ()> {
let mut inner = self.inner.lock();
let now = Instant::now();
let elapsed = now.duration_since(inner.last_refill).as_secs_f64();
let refill_amount = elapsed * self.refill_rate; // 按时间比例补充
inner.tokens = (inner.tokens + refill_amount).min(self.capacity); // 不超过容量上限
inner.last_refill = now;
if inner.tokens >= tokens {
inner.tokens -= tokens;
Ok(())
} else {
Err(()) // 令牌不足
}
}健康检查
定期检测 Worker 是否可用
bash
--health-check-interval-secs 30 \
--health-check-timeout-secs 10 \
--health-success-threshold 2 \
--health-failure-threshold 3 \
--health-check-endpoint /health| 参数 | 说明 |
|---|---|
--health-check-interval-secs |
健康检查间隔(秒) |
--health-check-timeout-secs |
请求超时时间 |
--health-success-threshold |
连续成功次数阈值(连续成功才算健康) |
--health-failure-threshold |
连续失败次数阈值(连续失败才算不健康) |
--health-check-endpoint |
健康检查接口路径 |
解析器
推理解析器
| Parser ID | 支持模型 | Think Tokens |
|---|---|---|
| deepseek-r1 | DeepSeek-R1 | <think>...</think> |
| qwen3 | Qwen-3 | <think>...</think> |
| qwen3-thinking | Qwen-3 Thinking | <think>...</think> |
| kimi | Kimi K2 | Unicode think tokens |
| glm45 | GLM-4.5/4.6/4.7 | <think>...</think> |
| step3 | Step-3 | <think>...</think> |
| minimax | MiniMax | <think>...</think> |
bash
python -m sglang_router.launch_router \
--worker-urls http://127.0.0.1:20000 \
--model-path deepseek-ai/DeepSeek-R1 \
--reasoning-parser deepseek-r1工具调用解析器
| Parser | 格式 | 说明 |
|---|---|---|
json |
JSON | 标准 JSON 工具调用 |
python |
Pythonic | Python函数调用格式 |
xml |
XML | XML结构工具调用 |
bash
python -m sglang_router.launch_router \
--worker-urls http://127.0.0.1:20000 \
--model-path deepseek-ai/DeepSeek-R1 \
--tool-call-parser json服务发现
在 Kubernetes 环境中自动发现并注册 Worker,无需手动 --worker-urls,Router 可以自动感知集群中的推理服务
bash
python -m sglang_router.launch_router \
--service-discovery \
--selector app=sglang-worker role=inference \
--service-discovery-namespace production \
--service-discovery-port 8000参数说明:
| 参数 | 说明 |
|---|---|
--service-discovery |
启用自动发现 |
--selector |
Pod label 选择器 |
--service-discovery-namespace |
指定 namespace |
--service-discovery-port |
Worker 服务端口 |
yaml
# Worker Deployment (Regular Mode)
apiVersion: apps/v1
kind: Deployment
metadata:
name: sglang-worker
namespace: production
spec:
replicas: 4
selector:
matchLabels:
app: sglang-worker
component: inference
template:
metadata:
labels:
app: sglang-worker
component: inference
model: llama-3-8b
spec:
containers:
- name: worker
image: lmsysorg/sglang:latest
ports:
- containerPort: 8000
name: http
- containerPort: 20000
name: grpc
bash
python -m sglang_router.launch_router \
--service-discovery \
--pd-disaggregation \
--prefill-selector app=sglang-worker component=prefill \
--decode-selector app=sglang-worker component=decode \
--service-discovery-namespace production| 参数 | 说明 |
|---|---|
--pd-disaggregation |
启用 PD 分离 |
--prefill-selector |
Prefill Pod 选择器 |
--decode-selector |
Decode Pod 选择器 |
--service-discovery |
启用 K8s 发现 |
bash
# Prefill Worker
metadata:
labels:
app: sglang-worker
component: prefill
annotations:
sglang.ai/bootstrap-port: "9001"
# Decode Worker
metadata:
labels:
app: sglang-worker
component: decode网关需要权限来查看 Pod:
bash
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: sglang-gateway
namespace: production
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: sglang-gateway
namespace: production
subjects:
- kind: ServiceAccount
name: sglang-gateway
namespace: production
roleRef:
kind: Role
name: sglang-gateway
apiGroup: rbac.authorization.k8s.io安全与认证
这 4 个安全机制保护的是两段不同的链路:
bash
客户端 ── [Router API Key / TLS] ──► 网关 ── [Worker API Key / mTLS] ──► Worker
客户端访问网关的安全 网关访问 Worker 的安全Router API Key
控制谁能访问网关,未携带合法 Key 的请求直接返回 401
bash
python -m sglang_router.launch_router \
--api-key "qwen3-api-key" \
--worker-urls http://worker1:8000代码实现:middleware.rs
rust
// 1. AuthConfig 持有配置好的 key,随 AppState 共享
pub struct AuthConfig {
pub api_key: Option<String>, // None 表示不启用鉴权
}
// 2. auth_middleware 在每个请求进来时执行
pub async fn auth_middleware(
State(auth_config): State<AuthConfig>,
request: Request<Body>,
next: Next,
) -> Result<Response, StatusCode> {
if let Some(expected_key) = &auth_config.api_key {
// 从请求头中提取 Authorization
let auth_header = request.headers()
.get(header::AUTHORIZATION)
.and_then(|h| h.to_str().ok());
match auth_header {
// 必须是 "Bearer <token>" 格式
Some(header_value) if header_value.starts_with("Bearer ") => {
let token = &header_value[7..]; // 截掉 "Bearer " 前缀
// 普通字符串比较在第一个不匹配字符就返回
if token_bytes.len() != expected_bytes.len() {
return Err(StatusCode::UNAUTHORIZED);
}
if token_bytes.ct_eq(expected_bytes).unwrap_u8() != 1 {
return Err(StatusCode::UNAUTHORIZED);
}
}
_ => return Err(StatusCode::UNAUTHORIZED),
}
}
// 验证通过,放行
Ok(next.run(request).await)
}Worker API Key
Worker 本身也可以设置鉴权,网关转发请求时自动携带对应 Worker 的 Key。每个 Worker 可以设不同的 Key,互相隔离。
Worker 级别的 key 通过动态注册 API 指定:
bash
curl -H "Authorization: Bearer qwen3-api-key" \
-X POST http://localhost:8080/workers \
-H "Content-Type: application/json" \
-d '{
"url":"http://worker:8000",
"api_key":"worker-qwen3-api-key"
}'代码实现:
rust
// 路由到 worker 之前,从 worker 元数据取出其 api_key
let api_key = worker.api_key().clone();
// 构建请求时,如果 worker 有 key 就注入 Authorization header
if let Some(key) = api_key {
let mut auth_header = String::with_capacity(7 + key.len());
auth_header.push_str("Bearer ");
auth_header.push_str(&key);
// 以 "Bearer <key>" 格式写入请求头,再转发给 worker
request_builder = request_builder.header("Authorization", auth_header);
}用户的 Authorization 优先:
rust
pub fn extract_auth_header(
headers: Option<&HeaderMap>,
worker_api_key: &Option<String>,
) -> Option<HeaderValue> {
// 先看用户请求里有没有 Authorization
let user_auth = headers.and_then(|h| {
h.get("authorization")
.or_else(|| h.get("Authorization"))
.cloned()
});
// 用户带了 key ,直接透传
// 用户没带,用 worker 自己配置的 key 兜底
user_auth.or_else(|| {
worker_api_key.as_ref()
.and_then(|k| HeaderValue::from_str(&format!("Bearer {}", k)).ok())
})
}TLS(HTTPS)配置
给网关监听端口加上 HTTPS,HTTP 变成加密的 HTTPS,客户端和网关之间的流量加密传输
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 \
--tls-cert-path /path/to/server.crt \
--tls-key-path /path/to/server.key| 参数 | 说明 |
|---|---|
--tls-cert-path |
服务端证书 |
--tls-key-path |
私钥 |
必须同时指定这两个参数,否则回退到纯 HTTP
代码实现:
rust
// 证书加载
fn read_server_certificates(mut self) -> ConfigResult<Self> {
match (&self.server_cert_path, &self.server_key_path) {
(Some(cert_path), Some(key_path)) => {
// 在 build() 阶段从磁盘读取,存入 RouterConfig
let cert = std::fs::read(cert_path)?;
let key = std::fs::read(key_path)?;
self.config.server_cert = Some(cert);
self.config.server_key = Some(key);
}
(None, None) => {} // 不配 TLS,正常 HTTP 启动
_ => {
// cert 和 key 必须同时配置,缺一不可
return Err("Both --tls-cert-path and --tls-key-path must be specified together");
}
}
Ok(self)
}
rust
// 绑定监听器
if let (Some(cert), Some(key)) = (&config.router_config.server_cert,
&config.router_config.server_key) {
info!("TLS enabled");
// 安装 ring 加密后端(rustls 的底层密码库)
ring::default_provider().install_default()?;
// 用 PEM 字节创建 rustls TLS 配置
let tls_config = axum_server::tls_rustls::RustlsConfig::from_pem(
cert.clone(),
key.clone()
).await?;
// 绑定 HTTPS 监听器
axum_server::bind_rustls(addr, tls_config)
.handle(handle)
.serve(app.into_make_service())
.await?;
} else {
// 没有证书配置,普通 HTTP 监听
axum_server::bind(addr)
.handle(handle)
.serve(app.into_make_service())
.await?;
}mTLS(双向 TLS)
网关访问 Worker 时,不仅验证 Worker 的证书(普通 TLS),Worker 也反过来验证网关的证书(双向认证)
bash
python -m sglang_router.launch_router \
--worker-urls https://worker1:8443 https://worker2:8443 \
--client-cert-path /path/to/client.crt \ # 网关自己的客户端证书(发给 Worker 证明身份)
--client-key-path /path/to/client.key \
--ca-cert-path /path/to/ca.crt # CA 证书(用于验证 Worker 的服务端证书)| 参数 | 说明 |
|---|---|
--client-cert-path |
客户端证书 |
--client-key-path |
客户端私钥 |
--ca-cert-path |
CA 证书(可多个) |
全启用配置:
bash
python -m sglang_router.launch_router \
--worker-urls https://worker1:8443 https://worker2:8443 \
--tls-cert-path /etc/certs/server.crt \
--tls-key-path /etc/certs/server.key \
--client-cert-path /etc/certs/client.crt \
--client-key-path /etc/certs/client.key \
--ca-cert-path /etc/certs/ca.crt \
--api-key "secure-api-key" \
--policy cache_aware可观测性
| 模块 | 启用方式 | 作用 |
|---|---|---|
| Prometheus Metrics | --prometheus-host/port |
指标监控 |
| OpenTelemetry Tracing | --enable-trace |
分布式链路追踪 |
| Logging | --log-level / --log-dir |
结构化日志 |
| Request ID Propagation | --request-id-headers |
请求链路串联 |
指标监控
bash
--prometheus-host 0.0.0.0 \
--prometheus-port 29000
bash
http://<router>:29000/metrics文件:metrics.rs
rust
// metrics.rs:343:所有 duration_seconds 后缀的指标共用
vec![0.001, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5,
1.0, 2.5, 5.0, 10.0, 15.0, 30.0, 45.0, 60.0, 90.0, 120.0, 180.0, 240.0]
// 1ms ~ 240s(4分钟),共 20 个桶- HTTP 层
- 从用户视角观测网关整体 HTTP 流量,不区分后端类型
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_http_* |
requests_total |
Counter | 网关收到的 HTTP 请求总数 |
request_duration_seconds |
Histogram(直方图) | 请求总耗时(端到端 HTTP 延迟分布) | |
inflight_request_age_count |
Gauge(可增可减) | 当前仍在处理中的请求按"已等待时长"的分布 | |
responses_total |
Counter(只增不减) | 网关返回给用户的响应总数,按 HTTP 状态码分类 | |
connections_active |
Gauge | 当前活跃 HTTP 连接数 | |
rate_limit_total |
Counter | 被限流请求数 |
rust
// 请求一到达就立即计数,网关收到的 HTTP 请求总数
pub fn record_http_request(method: &'static str, path: &str) {
counter!("smg_http_requests_total", "method" => method, "path" => path_interned)
.increment(1);
}- Router 层
- 观测路由分发行为,区分 router 类型、后端类型、模型
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_router_* |
requests_total |
Counter | 路由层实际转发的请求数,比 HTTP 层多了路由维度信息 |
request_duration_seconds |
Histogram | Router 总处理时间,包含选 worker、建连、等待后端响应的全部时间 | |
request_errors_total |
Counter | Router 错误总数,按错误类型 error_type 分类 | |
stage_duration_seconds |
Histogram | 请求处理各流水线阶段(如预处理、推理、后处理)的耗时分布 | |
upstream_responses_total |
Counter | 上游(后端 worker)返回的响应总数 |
- smg_router_upstream_responses_total 与 smg_http_responses_total 的区别:后者是网关返回给用户的,前者指标是后端 worker 返回给网关的,两者差值反映网关自身引入的错误
| error_type 值 | 含义 |
|---|---|
| no_workers | 无健康 worker 可用 |
| timeout | 请求超时 |
| backend_error | 后端返回错误 |
| validation_error | 请求参数校验失败 |
| internal_error | 网关内部错误 |
- 推理层
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_router_* |
ttft_seconds |
Histogram | Time To First Token,第一个 token 输出时间 |
tpot_seconds |
Histogram | Time Per Output Token,每个 token 平均生成时间 | |
tokens_total |
Counter | 处理的 token 总量,分 input/output 统计。用于计算吞吐 | |
generation_duration_seconds |
Histogram | 完整生成时间,从发出请求到收到最后一个 token。等于 TTFT + (output_tokens-1) * TPOT |
rust
let time_after_first = generation_duration.saturating_sub(ttft_duration);
let tpot = time_after_first / (output_tokens as u32 - 1);
// TTFT 之后的时间 / 剩余 token 数- Worker 层
- 观测后端 worker 健康状态、负载、选择行为
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_worker_* |
pool_size |
Gauge | 当前 worker 池中注册的 worker 数量,动态扩缩容时该值会变化 |
connections_active |
Gauge | 网关到后端 worker 的活跃连接数 | |
requests_active |
Gauge | 每个 worker 当前正在处理的请求数,即实时负载。power_of_two 和 cache_aware 策略的选择依据 | |
health |
Gauge | worker 健康状态(1.0=健康,0.0=不健康,-1.0=已移除) | |
health_checks_total |
Counter | 健康检查总次数 | |
selection_total |
Counter | 每个 worker 被选中的次数,按策略分类 | |
errors_total |
Counter | worker 级别错误(连接失败、超时等),与 smg_router_request_errors_total 的区别在于粒度更细,定位到具体 worker | |
routing_keys_active |
Gauge | 当前绑定到某 worker 的活跃路由数量(用于会话粘性路由) | |
smg_manual_policy_cache_entries |
Gauge | manual 策略(手动路由规则)缓存中的条目数 |
- 熔断指标
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_worker_cb_* |
state |
Gauge | 熔断器实时状态状态(0=Closed(正常)、1=Open(熔断)、2=Half-Open(探测恢复中)) |
transitions_total |
Counter | 状态转换总次数 | |
outcomes_total |
Counter | 通过熔断器的请求结果(success/failure)统计,failure 累积到阈值触发熔断 | |
consecutive_failures |
Gauge | 连续失败次数 | |
consecutive_successes |
Gauge | Half-Open 状态下的连续成功次数。达到阈值后熔断器恢复 Closed |
- 重试指标
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_worker_* |
retries_total |
Counter | 总重试次数 |
retries_exhausted_total |
Counter | 用尽所有重试次数后仍然失败的请求数 | |
retry_backoff_seconds |
Histogram | 每次重试的退避等待时长分布 |
- 服务发现指标
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_discovery_* |
registrations_total |
Counter | worker 注册次数 |
deregistrations_total |
Counter | worker 注销次数及注销原因 | |
sync_duration_seconds |
Histogram | 服务发现同步(扫描可用 worker)的耗时 | |
workers_discovered |
Gauge | 当前发现的 worker 数量 |
- MCP 层
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_mcp_* |
tool_calls_total |
Counter | MCP 工具调用总次数 |
tool_duration_seconds |
Histogram | MCP 工具执行耗时 | |
servers_active |
Gauge | 当前活跃的 MCP 服务连接数 | |
tool_iterations_total |
Counter | MCP 工具调用循环迭代总次数 |
- 数据库层
| Prefix | Metrics | 类型 | 说明 |
|---|---|---|---|
smg_db_* |
operations_total |
Counter | 数据库操作总次数,按操作类型和结果分类 |
operation_duration_seconds |
Histogram | 数据库操作耗时分布 | |
connections_active |
Gauge | 数据库连接池当前连接数 | |
items_stored |
Counter | 各存储类型累计写入的对象数量 |
全部指标汇总
rust
Layer 1 HTTP 层(6 个)
smg_http_requests_total Counter HTTP 请求总数
smg_http_request_duration_seconds Histogram HTTP 请求耗时
smg_http_inflight_request_age_count Gauge 在途请求按等待时长分布(非累积直方图)
smg_http_responses_total Counter HTTP 响应总数(按状态码)
smg_http_connections_active Gauge 活跃 HTTP 连接数
smg_http_rate_limit_total Counter 限流决策次数
Layer 2 Router 层(5 个)
smg_router_requests_total Counter 路由转发请求数
smg_router_request_duration_seconds Histogram 路由请求耗时
smg_router_request_errors_total Counter 路由错误数
smg_router_stage_duration_seconds Histogram 流水线各阶段耗时(gRPC)
smg_router_upstream_responses_total Counter 上游响应数
Layer 2 推理质量(4 个,gRPC Only)
smg_router_ttft_seconds Histogram Time To First Token
smg_router_tpot_seconds Histogram Time Per Output Token
smg_router_generation_duration_seconds Histogram 完整生成时间
smg_router_tokens_total Counter input/output token 总量
Layer 3 Worker 层(8 个)
smg_worker_pool_size Gauge Worker 池大小
smg_worker_connections_active Gauge Worker 活跃连接数
smg_worker_requests_active Gauge Worker 实时负载(正在处理的请求数)
smg_worker_health Gauge Worker 健康状态(1/0/-1)
smg_worker_health_checks_total Counter 健康检查次数
smg_worker_selection_total Counter Worker 被选中次数(按策略)
smg_worker_errors_total Counter Worker 级错误数
smg_worker_routing_keys_active Gauge 活跃路由键数(会话粘性)
smg_manual_policy_cache_entries Gauge 手动路由缓存条目数
Layer 3 熔断器(5 个)
smg_worker_cb_state Gauge 熔断器状态(0=关/1=开/2=半开)
smg_worker_cb_transitions_total Counter 熔断器状态转换次数
smg_worker_cb_outcomes_total Counter 熔断器记录的成功/失败次数
smg_worker_cb_consecutive_failures Gauge 连续失败次数(熔断前兆)
smg_worker_cb_consecutive_successes Gauge 连续成功次数(恢复依据)
Layer 3 重试(3 个)
smg_worker_retries_total Counter 重试尝试次数
smg_worker_retries_exhausted_total Counter 重试耗尽次数(直接影响用户成功率)
smg_worker_retry_backoff_seconds Histogram 重试退避时长
Layer 4 服务发现(4 个)
smg_discovery_registrations_total Counter Worker 注册次数
smg_discovery_deregistrations_total Counter Worker 注销次数
smg_discovery_sync_duration_seconds Histogram 发现同步耗时
smg_discovery_workers_discovered Gauge 已发现 Worker 数量
Layer 5 MCP(4 个)
smg_mcp_tool_calls_total Counter 工具调用次数
smg_mcp_tool_duration_seconds Histogram 工具执行耗时
smg_mcp_servers_active Gauge 活跃 MCP 服务数
smg_mcp_tool_iterations_total Counter 工具循环迭代次数
Layer 6 存储层(4 个)
smg_db_operations_total Counter 存储操作次数
smg_db_operation_duration_seconds Histogram 存储操作耗时
smg_db_connections_active Gauge 存储活跃连接数
smg_db_items_stored Counter 存储写入对象数
共 43 个指标,通过 Prometheus 端口 29000 暴露OpenTelemetry 分布式追踪
在分布式系统中,请求通常会经过多个服务节点,传统日志难以完整还原调用链路。通过引入 OpenTelemetry (OTel,是一个开源的可观测性Observability 框架),可以实现端到端的链路追踪(Tracing)。
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 \
--enable-trace \
--otlp-traces-endpoint localhost:4317| 参数 | 说明 |
|---|---|
--enable-trace |
启用分布式 tracing |
--otlp-traces-endpoint |
OTLP collector 地址 |
Logging 日志系统
bash
python -m sglang_router.launch_router \
--worker-urls http://worker1:8000 \
--log-level debug \
--log-dir ./router_logs| 参数 | 说明 |
|---|---|
--log-level |
日志级别(debug, info, warn, error) |
--log-dir |
日志文件输出目录 |
请求 ID 透传机制
网关内置了请求 ID 透传机制,方便在日志和链路追踪中定位问题。
每个请求进入网关时,会自动从请求 Header 中提取请求 ID;如果客户端没有携带,网关会自动生成一个(格式与 OpenAI 对齐,如 chatcmpl-AbCdEfGh...),并在响应 Header x-request-id 中返回给客户端。
如果使用自定义 Header 名,通过启动参数指定即可:
bash
python -m sglang_router.launch \
--request-id-headers my-trace-id x-request-id
bash
resp = requests.post(
"http://gateway/v1/chat/completions",
headers={"x-request-id": "my-request-001"},
json={...}
)
# 响应中可取回同一个 ID,用于日志查询
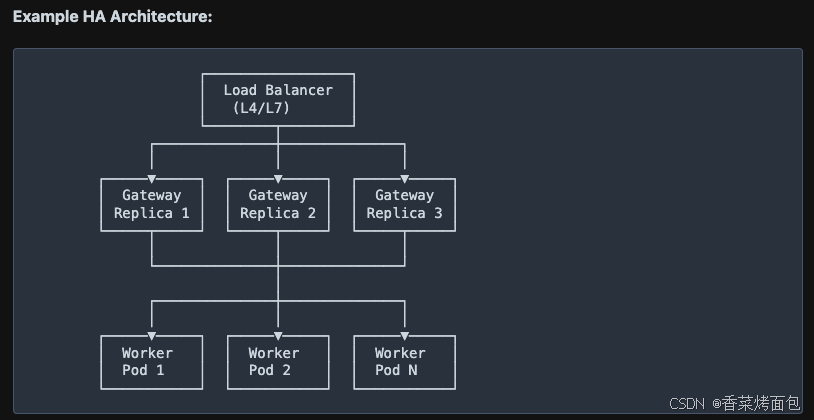
print(resp.headers["x-request-id"]) # my-request-001高可用
网关支持在负载均衡器后运行多个副本,实现高可用性。
- 网关无状态
- 多副本部署
- 负载均衡分发流量
- 各副本独立运行、互不依赖
组件共享情况:
| 组件 | 是否跨副本共享 | 影响 |
|---|---|---|
| Worker Registry | 否(独立) | 每个副本独立发现 worker |
| Radix Cache Tree | 否(独立) | 缓存命中率可能下降 10--20% |
| Circuit Breaker State | 否(独立) | 每个副本独立跟踪失败情况 |
| Rate Limiting | 否(独立) | 限流按副本生效,而非全局 |
-
优先使用水平扩展
- 优先部署多个较小的网关副本,而不是单个占用大量 CPU 和内存的大实例。
-
使用 Kubernetes 服务发现,让 Gateway 自动发现并管理 Worker
bash
python -m sglang_router.launch_router \
--service-discovery \
--selector app=sglang-worker \
--service-discovery-namespace production-
缓存效率
- 在多副本部署下,Cache-Aware 的路由策略中的 Radix Tree 不会在副本之间同步,每个副本都会构建自己的缓存树,同一用户的请求可能会命中不同的副本,预期缓存命中率下降:10--20%
-
会话亲和(Session Affinity)
- 如果缓存非常重要,基于用户 ID / API Key 做一致性哈希,将同一用户的请求固定路由到同一副本
高可用架构
通过负载均衡器将请求分发到不同副本,网关再发给 Worker: