引言:绝大多数AI智能体,都困在"金鱼式瞬时记忆"的瓶颈里
几乎所有长期使用Claude等大模型的用户,都会遭遇同一个无解难题,无论反复多少次告知自己的工作习惯、写作偏好、业务规则和纠错要求,只要开启一轮新对话,AI就会彻底清零记忆。昨天刚刚修正的输出错误、上周磨合出的专属工作方案、一直强调的内容输出禁忌,全部不复存在。AI依旧沿用默认的通用模板输出,重复犯下一模一样的低级错误,我们只能反复复述、反复纠正、反复磨合,极大拉低了工作效率。
很多人误以为这是模型能力不足,或是自己使用方式不对,但本质上,这是大语言模型与生俱来的底层运行特性。所有主流LLM的原生运行逻辑都是会话隔离,每一次全新对话都是独立的空白实例,不会自动继承过往会话的上下文、经验和偏好。如果没有人为搭建专属记忆体系、主动导入历史上下文,AI永远处于出厂默认状态,这就是业内常说的"金鱼式记忆"问题。
这种特性用于日常闲聊、单次临时问答尚且可以接受,但如果我们需要AI承担重复性办公、长期项目跟进、常态化内容创作、固定业务处理等工作,瞬时记忆就会成为最大的效率瓶颈。没有记忆沉淀的AI,第一百次使用和第一次使用的效果完全一致,永远无法积累经验、迭代优化,这也是绝大多数人搭建的AI智能体始终无法进阶、长期停留在浅层工具阶段的核心原因。
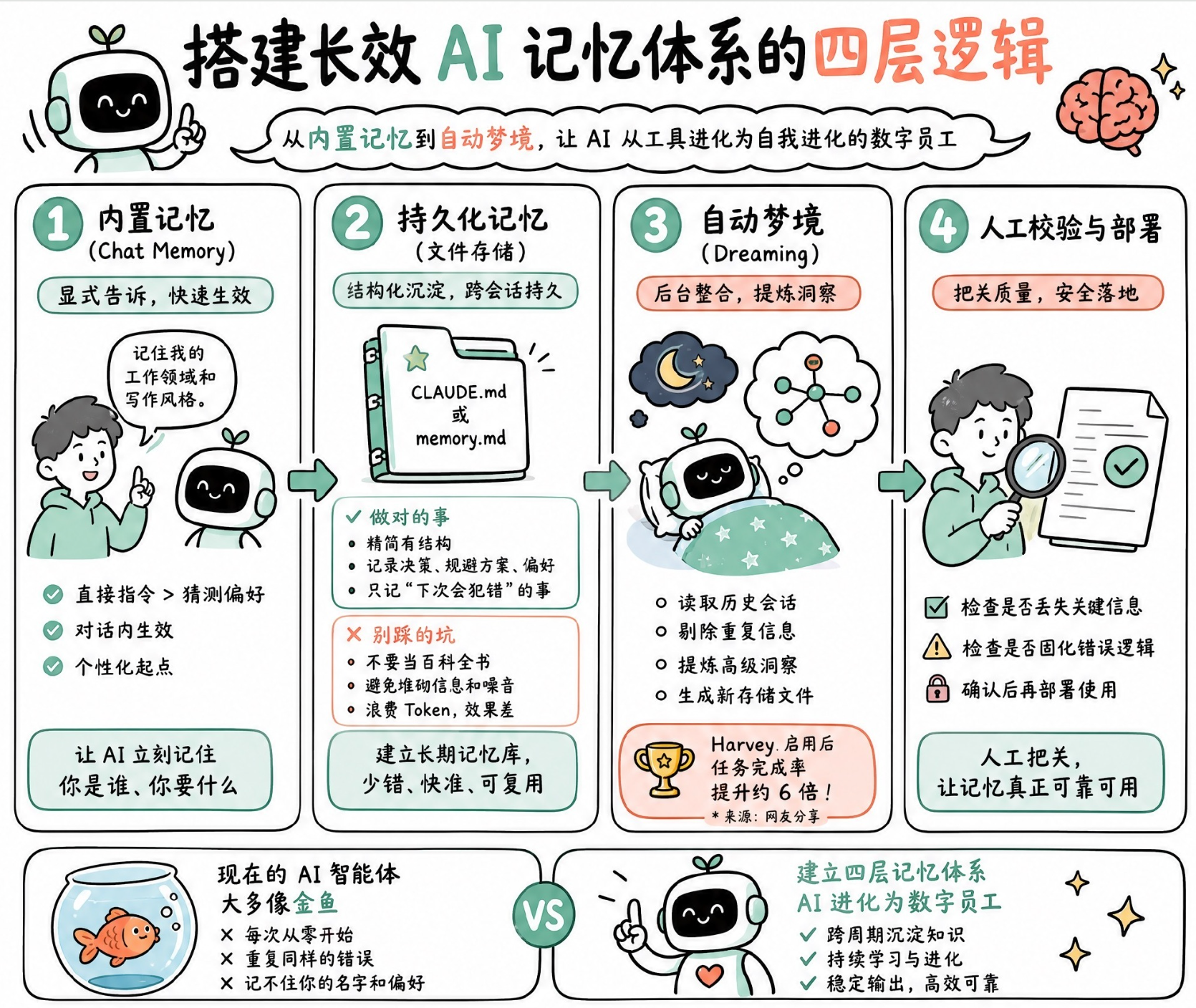
直到2026年Anthropic连续更新Chat Memory持久记忆、Dreaming梦境自我迭代两大核心能力,普通用户和开发者才真正拥有了搭建AI长效记忆的完整能力。在此之前,跨周、跨会话的AI持续进化几乎无法实现,而现在,我们可以通过一套标准化的12步落地流程,搭建起从基础留存到自主进化的四层完整记忆架构,让AI彻底摆脱健忘属性,从被动执行指令的工具,蜕变为能够持续沉淀经验、自我优化、贴合专属场景的全职数字员工。
这套四层记忆体系层层递进、闭环迭代,涵盖普通用户轻量化配置、开发者工程化部署、AI自主复盘进化、人工安全兜底全流程,能够彻底解决AI重复犯错、记忆失效、适配性差、无法迭代的痛点,真正实现AI能力的长期复利增长。
第一层:显性预置记忆与项目空间,筑牢AI记忆基础底座
四层记忆体系的第一层为轻量化固定记忆,主打零门槛、高适配,面向所有普通用户,无需代码、无需开发,通过官方原生功能快速锁定个性化偏好和工作规则,彻底解决"每次对话重新解释"的繁琐问题。这一层包含四大核心实操步骤,也是整套记忆体系的基础核心。
第一步,开启Claude官方原生持久化Chat Memory功能。2026年3月,Anthropic正式为所有免费、付费Claude账号全面上线Chat Memory持久记忆能力,这是绝大多数用户都未曾用好的原生核心功能。开启后,Claude会默认跨会话留存用户偏好、项目信息、工作风格,不会因新建对话自动清零。
具体开启路径十分清晰,打开Claude客户端或网页端,点击个人头像,进入设置界面,找到能力配置板块,下滑至记忆设置专区,确保"从聊天历史生成记忆"功能处于开启状态。该功能底层搭载Memory Synthesis记忆合成机制,系统会每24小时自动梳理全局对话记录,提炼用户专属特征并固化为基础记忆,为后续所有记忆迭代提供底层支撑。
第二步,主动种子植入记忆,拒绝被动等待AI推断。很多用户的记忆失效误区,就是被动等待AI自行学习、总结偏好。官方文档明确指出,AI每日一次的自动记忆合成存在24小时延迟,且被动推断极易出现偏差、遗漏。最高效的方式是主动显性植入核心记忆,即时生效、零误差。
我们可以在全新对话中,直接输入标准化预置指令,一次性固化所有核心个性化规则,彻底杜绝重复沟通:
Plain
Remember the following about me for future conversations:
- I work in [具体行业领域] and my main projects are [核心项目1、核心项目2]
- I prefer [行文风格/排版习惯/回复长度要求]
- My writing style is [详细描述专属写作风格]
- Never [必须规避的错误、固定避雷点]这条显性指令会被Claude直接写入永久记忆,无需等待系统自动合成,后续所有对话都会默认遵循该套规则,直接消除80%的基础磨合成本。
第三步,创建专属项目空间,打造固定工作记忆载体。Claude的Projects项目功能是第一层记忆的最强形态,区别于普通临时对话,项目空间是专属持久化工作区,自定义指令、角色定位、工作标准、约束规则会永久挂载在项目内,该空间下的所有对话都会自动继承配置,实现统一标准输出。搭建智能体务必以工作职能命名项目,而非场景话题,精准匹配专属业务需求。
第四步,厘清项目功能边界,避开核心记忆误区。这是多数用户踩坑的关键节点,必须明确,Claude项目空间仅持久化固定指令和角色规则,不会默认留存对话历史、过程数据、临时决策和调试记录。很多人搭建好项目、完成多轮工作沟通后,新建对话发现所有过程内容全部清零,本质就是混淆了"指令记忆"和"会话过程记忆",这也是AI智能体工作断层、经验丢失的核心原因之一。
第二层:结构化文件持久化,搭建可沉淀的专属记忆仓库
第一层记忆解决了基础风格、固定规则的留存问题,但无法承载复杂的业务决策、场景化 workaround、历史错误规避、项目专属细节。想要实现精细化、长期化、工程化的记忆留存,必须搭建第二层记忆体系,文件持久化存储,这也是高阶用户和开发者的核心落地方案。
第二层记忆的核心载体是轻量化专属记忆文件,通用标准文件为 CLAUDE\.md(适配Claude Code)或 memory\.md(通用智能体项目知识库)。区别于零散的对话记忆,该文件是AI的专属外部记忆仓库,AI会在每轮会话开始自动读取、会话结束按需更新,实现跨会话、跨周期的细节记忆留存。
这里必须坚守官方强调的核心原则,记忆文件绝对不能无脑堆砌资料,切忌当成百科文档随意填充冗余内容。大模型单次会话可承载的前置指令Token上限约20000,臃肿杂乱的记忆文件会大量消耗Token、提升使用成本,更会导致核心规则被无效信息淹没,出现AI输出失真、重点模糊的问题。如果使用工具自动生成初始记忆文件,务必手动精简,删除模型已知的通用常识、无效铺垫内容,只保留专属差异化信息。
同时需要开启自动记忆机制,在会话中输入指令开启自动记忆功能:
Plain
/memory也可在项目设置中开启 autoMemoryEnabled 配置,让AI在每轮工作结束后,自动记录用户修正内容、适配规则和优化点,让纠错经验不再随会话结束消失。
为了避免记忆文件随使用时间无限膨胀、沦为无效噪音,必须采用标准化结构化分区排版,精准沉淀四类核心有效信息,所有内容按需迭代、逐条归档:
Plain
## 个性化偏好 Preferences
- 状态更新优先文字详述,不使用纯列表输出
- 所有观点输出必须标注对应依据与来源
## 关键决策记录 Decisions
- 2026-04-18 业务选型:优先Postgres数据库,适配关联报表统计需求
## 场景适配方案 Known workarounds
- 超大文件处理:大于50MB文件需提前拆分,避免导出工具报错失效
## 避坑清单 Recurring mistakes to avoid
- 禁止自动审核通过涉及权限模块的代码合并请求除此之外,必须建立严格的记忆筛选机制,这是长效记忆有效的核心关键。并非所有会话内容都需要留存,唯一的筛选标准是,这条信息是否会改变AI下一次的执行行为。专属决策、特殊适配、固定错误、场景方案必须留存,一次性调试、临时闲聊、通用常识全部主动舍弃。全量存储的记忆和无记忆没有任何区别,精简、精准、有效的沉淀,才是第二层记忆的核心价值。
第三层:代码级持久记忆,实现智能体常态化自我存档
在前两层记忆的基础上,针对开发者和高频自动化工作场景,可落地第三层工程化记忆能力,实现记忆的自动化读写、常态化更新,彻底摆脱人工维护记忆文件的繁琐操作。这一层是衔接基础静态记忆与高阶动态进化记忆的关键过渡层,让AI记忆从"人工固化"走向"自动留存"。
这套机制的核心逻辑是,让智能体在每次会话启动时自动读取记忆文件,加载所有历史沉淀的规则、决策、避坑方案;会话结束后,自动梳理本次工作的有效信息,更新记忆文件、剔除冗余内容、迭代旧方案,实现记忆的动态更新。全程无需人工干预,自动化完成经验存档。
需要重点强调,第三层记忆仅适配高频复用的"劳动力型智能体"。如果智能体只是偶尔使用、场景零散、任务无固定规律,没有足够的重复工作样本,自动化记忆存档无法积累有效模式,最终只会堆砌无效数据,毫无价值。只有用于日常固定编码、文书撰写、合规审核、数据处理、项目复盘的高频智能体,才能最大化发挥文件持久记忆的效果。
第四层:Dreaming梦境迭代,让AI实现自主复盘进化
前三层记忆实现了"留存经验、规避错误、固定规则",但依旧存在核心短板,所有记忆均依赖人工设定或人工修正,AI只能被动遵循规则执行,无法自主提炼规律、挖掘隐性经验、升级认知。2026年5月6日,Anthropic在Code with Claude发布会推出的Dreaming梦境迭代技术,正式补齐了这一短板,构成四层记忆体系的最高阶闭环能力。
Dreaming的设计逻辑完全复刻人类大脑的记忆巩固机制,人类白天接收海量信息、处理事务后,会在睡眠中自动梳理、整合、精简信息,将零散经验沉淀为长期认知。而AI的梦境迭代,就是专属后台自我复盘系统,在智能体闲置、无任务执行的时段,自动启动后台进程,读取历史会话记录、现有记忆仓库、全部工作数据,完成去重、精简、迭代、洞察四大核心动作。
它会自动合并重复记忆、替换过期规则、清理无效碎片化信息,同时从海量重复的工作场景中,提炼人工无法察觉的隐性工作规律、高效执行逻辑和通用解决方案,将零散的单次经验,升级为体系化的高阶认知。行业标杆案例极具说服力,知名法律AI企业Harvey启用Dreaming机制后,法律文书撰写、合规审核等标准化工作的任务完成率直接提升6倍,彻底解决了AI频繁遗忘场景适配规则、工具使用细节导致的任务失败问题。
作为面向托管智能体的内测预览能力,Dreaming有明确的落地前置条件,需要开发者配置托管智能体API密钥、申请官方内测权限,同时搭载Python或TypeScript最新SDK环境,仅支持 claude\-opus\-4\-7、claude\-sonnet\-4\-6 两大模型。
标准梦境迭代调用代码如下,可直接落地复用:
Plain
dream = client.beta.dreams.create(
inputs=[
{"type": "memory_store", "memory_store_id": store_id},
{"type": "sessions", "session_ids": [session_a, session_b]},
],
model="claude-opus-4-7",
instructions="Focus on coding-style preferences; ignore one-off debugging notes.",
)
print(dream.id) # 输出梦境任务ID调用时需要搭载专属内测请求头,完成能力激活:
Plain
anthropic-beta: managed-agents-2026-04-01,dreaming-2026-04-21官方明确建议,初期需采用小批量会话样本测试,确认记忆整合质量稳定后,再逐步扩容会话数量,控制成本同时保证迭代精准度。
人工兜底校验:规避AI记忆固化风险,守住稳定底线
Dreaming技术并非万能,其最大的特性是生成全新的独立记忆仓库,不会覆盖原有旧记忆,这既是安全优势,也是核心风险点。AI自主复盘整合的过程并非百分百精准,极易出现两类致命问题,一是误删小众但关键的专属特殊规则,造成有效记忆流失;二是从瑕疵会话、临时错误操作中提炼错误逻辑,将偏差规律固化为长期记忆。
因此,人工校验是四层体系不可或缺的终极防线,绝对禁止自动化直接部署梦境迭代结果。梦境任务完成后,会生成全新的输出记忆仓库,我们需要通过代码读取新仓库ID,逐条核验内容:检查核心规则是否完整留存、过期内容是否精准替换、新提炼的业务规律是否贴合实际场景、有无错误逻辑归纳和无效噪音。
Plain
# 获取梦境迭代后的全新记忆仓库ID
output_store_id = next(
output.memory_store_id
for output in dream.outputs
if output.type == "memory_store"
)只有人工核验无误后,才可替换原有记忆仓库地址,完成迭代更新。同时可根据智能体使用频率,设置每日或每周定时梦境复盘,形成"日间执行、夜间迭代、周度优化"的完整复利闭环,让智能体越用越精准、越用越高效。
AI记忆搭建必避五大致命误区
整套四层记忆体系的落地效果,取决于是否规避核心误区,绝大多数智能体无法进化,都是踩了可预见的坑,这里总结五大高频致命问题:
第一,混淆项目空间与记忆空间。项目仅留存固定指令,不保存会话历史与过程数据,切勿误以为搭建项目就拥有了完整长效记忆。
第二,无脑堆砌记忆文件。臃肿的全量存档会稀释有效信息、浪费Token资源,精简结构化的精准记忆远胜于冗长的完整记录。
第三,无筛选全量记忆。不加过滤的存档等于无记忆,只有能改变后续执行行为的信息,才具备留存价值。
第四,自动部署梦境结果。跳过人工校验会导致错误逻辑、无效内容被永久固化,彻底破坏智能体记忆体系。
第五,低频智能体启用Dreaming。无足够重复场景和工作样本,梦境迭代无法提炼有效规律,只会产生无效运算,毫无提升效果。
结语:搭建记忆闭环,拉开AI使用的终极差距
当下绝大多数用户的AI使用方式,依旧停留在原始的单次会话模式,每一次对话都是全新的空白模型,反复解释、反复纠错、反复磨合,永远无法积累经验。而真正的高阶玩家,通过这套四层十二步长效记忆体系,彻底重构了AI的使用价值。
从第一层显性预置记忆、项目固定规则,到第二层结构化文件持久存档,再到第三层自动化工程级记忆更新,最终通过第四层Dreaming梦境自主迭代+人工兜底,形成了一套完整的人机协同进化闭环。这套体系让AI不再是健忘的聊天工具,而是能够跨周、跨月长期沉淀经验,持续自我修正、自主升级的专属数字员工。