AIOps缺的不是一个单纯的聊天入口,而是一个运行在浏览器扩展里的智能执行助手:能理解当前页面,能根据自然语言任务操作控制台,能在不确定或高风险时把控制权交还给人,也能把一次成功的操作沉淀成可复放脚本和可追踪记录。
AI控制页面演示: PG恢复
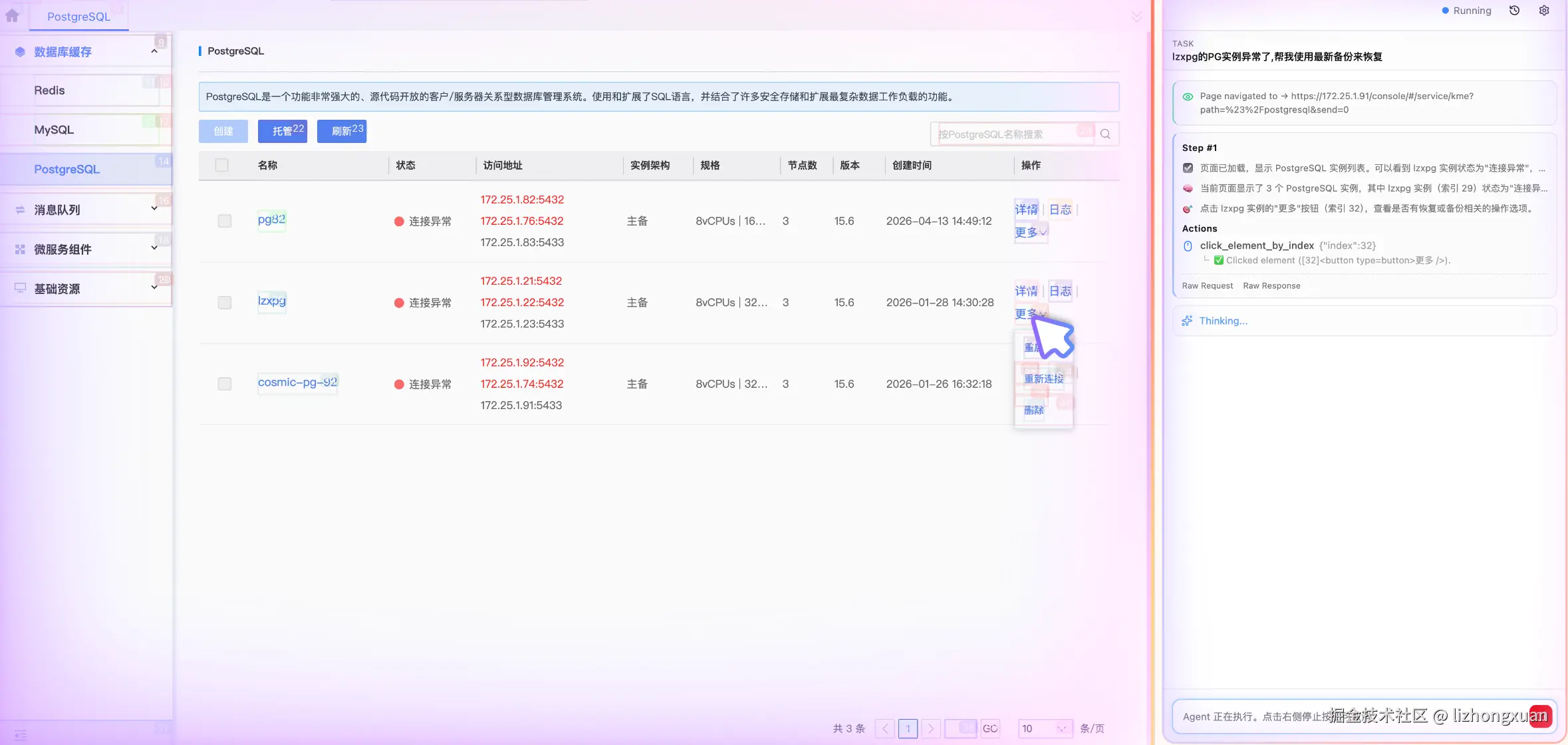
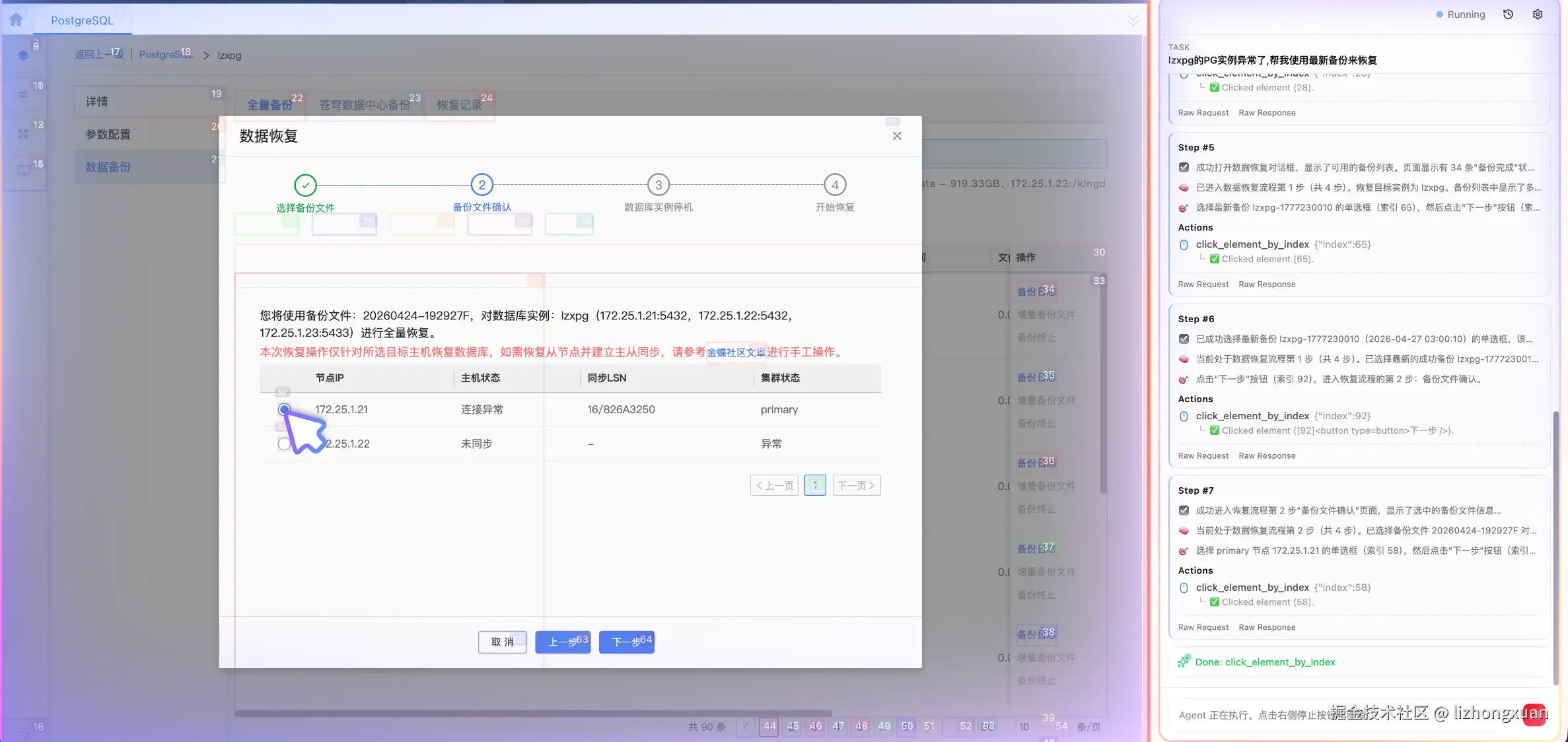
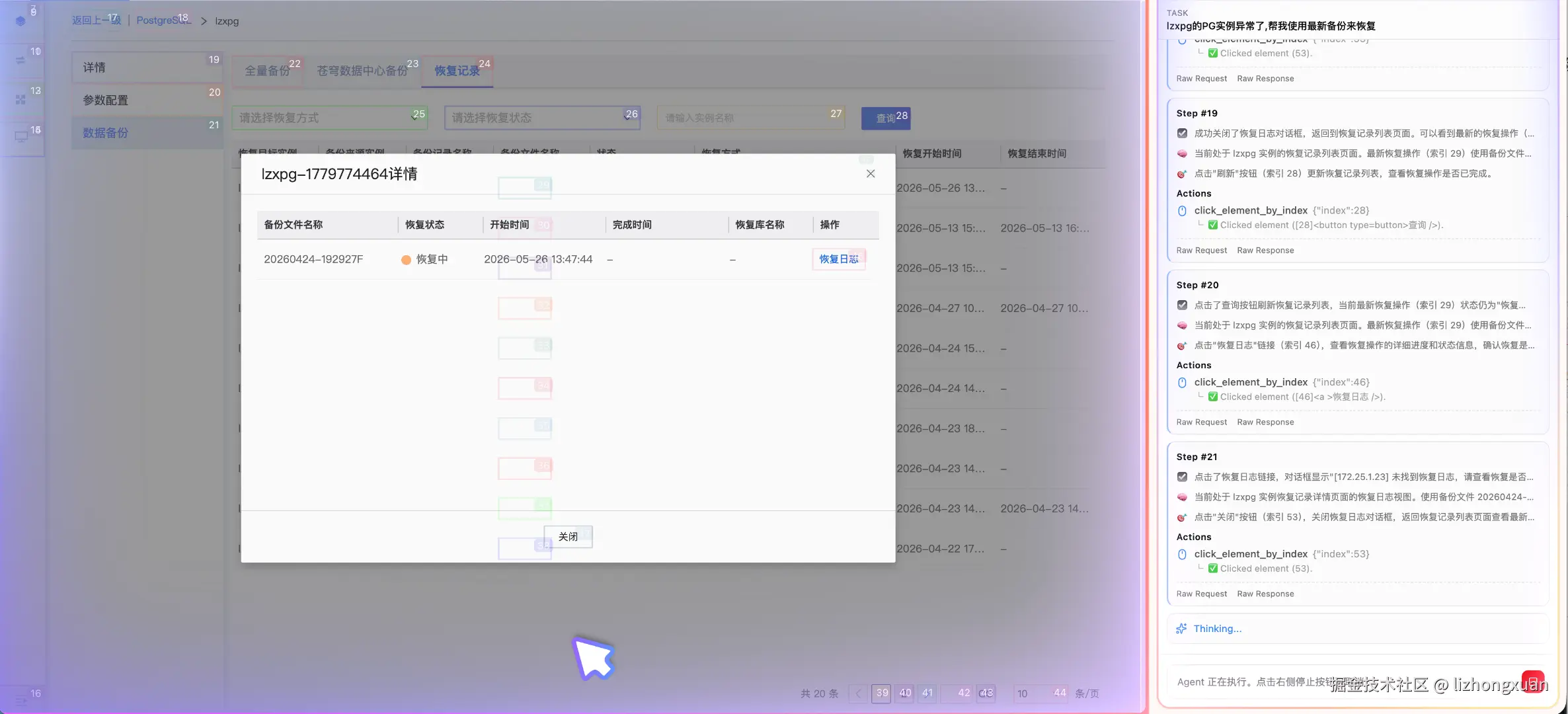
这篇文章介绍 aiops page ext 的设计思路、核心架构和它如何与 AIOps 场景结合。
AIOps 为什么需要浏览器扩展
很多 AIOps 系统已经具备告警聚合、异常检测、根因分析和知识库问答能力。但一旦进入处理阶段,工程师仍然会面对大量浏览器操作:
- 打开告警详情,确认影响范围、服务名、集群、实例和时间窗口。
- 跳到日志平台,用 traceId、requestId、podName 或错误码筛选日志。
- 切到监控大盘,对比 QPS、错误率、延迟、资源水位和依赖状态。
- 查 CMDB 或服务拓扑,确认负责人、上下游依赖和最近变更。
- 进入发布平台,查看发布批次、回滚入口和变更记录。
- 更新工单或故障群,把排查过程和结论同步给团队。
这些动作并不总是复杂,但它们高度依赖页面上下文,而且分散在多个系统中。传统脚本难以覆盖所有页面变化;单纯的聊天机器人又无法直接操作控制台。aiops page ext 的切入点是:让 Agent 直接站在工程师所在的浏览器里,围绕页面完成可解释、可确认、可复放的操作。
核心定位:AIOps 的页面执行层
aiops page ext 可以理解为 AIOps 平台和浏览器控制台之间的"页面执行层"。
上层可以是告警平台、ChatOps、MCP 客户端、故障协同系统或人工输入的自然语言任务;下层是真实浏览器页面。扩展负责把页面状态转成模型能理解的文本结构,再把模型的计划转成点击、输入、滚动、选择、等待、询问用户等可控动作。
典型任务可能是:
text
帮我排查 prod 集群 checkout-service 过去 30 分钟 5xx 升高的原因,
先看告警详情,再查相关日志和最近变更,不要执行回滚。在这个任务里,Agent 不只是回答"你应该怎么查",而是可以逐步打开页面、筛选条件、读取结果、总结发现,并在涉及危险动作时停下来让人确认。
技术路线:用文本化 DOM 理解控制台
aiops page ext 默认不依赖截图识别页面,而是读取浏览器里的 DOM 结构,将当前页面抽取成模型可读的文本化状态。
这个选择对 AIOps 场景很重要:
- 运维控制台通常信息密度高,DOM 中有大量按钮、表格、筛选器和链接。
- 文本化页面状态更容易记录和复盘,便于故障后审计。
- 动作可以绑定到交互元素 index,而不是不稳定的屏幕坐标。
- 不需要把截图作为默认输入,降低权限、成本和敏感信息暴露面。
每次执行动作前,扩展都会重新观察当前页面,得到最新的 URL、标题、滚动位置、页面尺寸和交互元素列表。这样可以避免在动态页面中复用过期元素位置。
这条闭环让 aiops page ext 更适合处理真实控制台:页面加载、弹窗、筛选结果刷新、表格分页、跳转新 tab,都可以通过持续 observe 来修正下一步动作。
架构:浏览器执行内核 + AIOps 增强层
aiops page ext 从一开始就按"浏览器执行内核 + AIOps 增强层"的方式设计。浏览器执行内核负责页面观察、动作规划、多标签页调度和 DOM 操作;AIOps 增强层负责知识库、人机确认、操作录制、脚本导出和外部 Agent 接入。这样既能保证页面操作链路稳定,又能把运维场景里的知识、风险和审计能力放到合适的位置。
整体链路可以概括为:
几个关键模块分别承担不同职责:
| 模块 | 职责 |
|---|---|
| Multi-page agent | 负责跨标签页任务规划、执行和历史管理 |
| Remote page controller | 在目标页面执行 DOM 抽取和点击、输入、滚动等动作 |
| WebOps interaction layer | 在页面内展示高亮、确认、交接、输入等人机协作组件 |
| Knowledge context provider | 检索项目知识库、运维手册、页面说明和操作规则 |
| Session recorder | 记录一次任务中的关键操作、选择器和脱敏数据 |
| Playwright exporter | 将成功流程导出为可复放的 Playwright 项目 |
| MCP bridge | 允许外部 Agent 客户端触发浏览器任务 |
这种拆分适合 AIOps:自动化可以往前走,但人、知识库、审计和复放能力都能在明确位置接入。
架构演进
围绕 AIOps 的真实处理链路设计。设计过程可以拆成三个阶段。
第一阶段是浏览器执行内核。目标是让 Agent 能可靠地观察页面、理解任务、生成动作、执行点击输入滚动,并把每一步结果记录下来。这个阶段确定了几个基础能力:文本化 DOM、Observe-Think-Act 循环、工具调用协议、多标签页调度、可停止的任务生命周期和结构化历史。
第二阶段是 AIOps 增强层。仅有页面操作还不够,运维场景需要业务语义和风险控制。因此设计中加入了知识库检索、页面高亮、就地确认、人工交接、敏感信息处理和外部 Agent 入口。这些能力不直接侵入执行内核,而是通过明确接口参与任务执行。
第三阶段是流程资产化。自然语言 Agent 适合处理变化和探索,但高频运维流程需要被固化。Session Recorder 和 Playwright Exporter 的引入,让一次成功的自然语言操作可以转成可复放资产,后续由脚本承担稳定流程,由 Agent 处理变化和例外。
这条演进路径背后的原则是:不把 AIOps 做成只能回答问题的孤立系统,而是把它设计成能进入浏览器现场、协助执行、沉淀流程的工程系统。
模块边界:哪些能力放在哪里
aiops page ext 的模块边界遵循一个简单规则:执行内核只负责"稳定地看页面和操作页面",AIOps 增强层负责"让操作符合运维语义、风险要求和审计要求"。
| 边界 | 负责什么 | 不负责什么 |
|---|---|---|
| Agent runtime | 任务生命周期、Observe-Think-Act 循环、历史、工具协议、上下文拼装 | 不直接渲染页面组件,不内置具体运维规则 |
| Page controller | DOM 抽取、元素索引、点击输入滚动等页面动作 | 不关心 LLM、知识库和多 tab 调度 |
| LLM client | OpenAI-compatible 调用、tool schema、重试和错误类型 | 不关心页面结构和业务流程 |
| Extension orchestrator | 多 tab 调度、远程页面控制、扩展任务生命周期 | 不直接承载知识库、录制和页面交互组件实现 |
| Interaction layer | 页面高亮、确认气泡、交接提示、输入提示 | 不执行 Agent 规划,不直接改业务页面状态 |
| Knowledge layer | 知识库检索、格式化、注入 Agent 上下文 | 不直接决定页面动作 |
| Recorder | 记录动作、目标、知识命中和脱敏信息 | 不生成脚本模板 |
| Replay exporter | 把录制会话导出为 Playwright 项目 | 不参与在线 Agent 执行 |
| External bridge | 把浏览器任务暴露给外部 Agent 或 ChatOps 系统 | 不理解具体 AIOps 业务规则 |
这个边界能避免一个常见问题:所有能力都堆进 Agent 主循环。Agent 主循环越复杂,越难测试、越难复用,也越难判断错误来自模型、页面、知识库还是 UI。拆开以后,每个模块都有自己的输入输出,排查问题时可以更快定位。
例如,知识库不可用时,Agent 仍然可以按页面 DOM 执行;录制失败时,不应该影响当前故障排查;页面交互组件渲染失败时,也不应该破坏 RemotePageController 的基础点击和输入能力。AIOps 系统最需要的不是"每次都装作成功",而是失败边界清楚、风险可见、能继续降级。
工程实践:渐进增强、可测试、可追踪
aiops page ext 的工程实践可以概括为三句话:内核稳定、增强可插拔、证据优先。
内核稳定,指的是把页面观察、动作执行、模型调用和任务历史做成清晰的基础能力。它们承担的是 aiops page ext 的执行可靠性,任何 AIOps 场景增强都不应该破坏这条主链路。
增强可插拔,指的是每个能力都能独立开关和降级。知识库默认可以关闭;页面交互组件只在需要确认、交接或提示时出现;录制和导出依赖会话历史,不阻塞在线任务;外部 bridge 是额外入口,不改变侧边栏的基本使用方式。这样可以先上线低风险能力,再逐步扩大自动化范围。
证据优先,指的是每一步都要留下可追踪信息。Agent history 记录 reflection、action、tool output 和错误;Session Recorder 记录动作目标、选择器快照、知识库命中和脱敏输入;Playwright 导出把成功流程变成可复查资产。对 AIOps 来说,自动化做了什么,比自动化声称自己做了什么更重要。
仓库层面采用 npm workspaces 的 monorepo 组织方式,按执行内核、浏览器扩展、AIOps 增强模块、外部连接模块拆分目录。workspaces 按依赖拓扑排列,避免底层能力反向依赖上层应用。常用质量门禁包括 typecheck、lint、单元测试和面向真实浏览器的验收测试。
这套实践让 aiops page ext 能保持两个方向的弹性:向下保持浏览器执行内核稳定,向上承载越来越具体的 AIOps 业务流程。
知识库增强:让 Agent 知道"这个页面在运维里意味着什么"
仅靠页面 DOM,Agent 可以知道"这里有一个输入框"和"这里有一个按钮",但不一定知道这些控件在具体业务里的含义。AIOps 场景尤其如此:同一个"重启""回滚""确认""屏蔽"按钮,在不同系统里的风险完全不同。
aiops page ext 通过 Knowledge Context Provider 接入项目知识库。它可以根据当前任务、URL、页面标题和可见内容检索相关材料,例如:
- 服务负责人、业务域、SLO 和依赖关系。
- 告警处理手册、Runbook、升级路径。
- 日志平台字段含义和常用查询模板。
- 发布平台操作规范和回滚条件。
- 特定页面的筛选方式、字段解释和注意事项。
检索结果会被格式化后加入模型上下文,让 Agent 在操作页面前先拿到业务语义。例如,当页面出现"屏蔽告警"按钮时,知识库可以告诉 Agent:这类操作只能在确认误报或维护窗口内执行,并且需要填写原因。
这让 aiops page ext 不只是"会点页面",而是能把组织内部的运维经验带进页面操作过程。
页面交互组件:自动化必须让人看得懂
AIOps 自动化最怕两件事:一是悄悄做了危险动作,二是失败后没人知道它刚才做了什么。aiops page ext 在目标页面内注入一层轻量交互组件,让用户在关键时刻能看见、确认和接管。
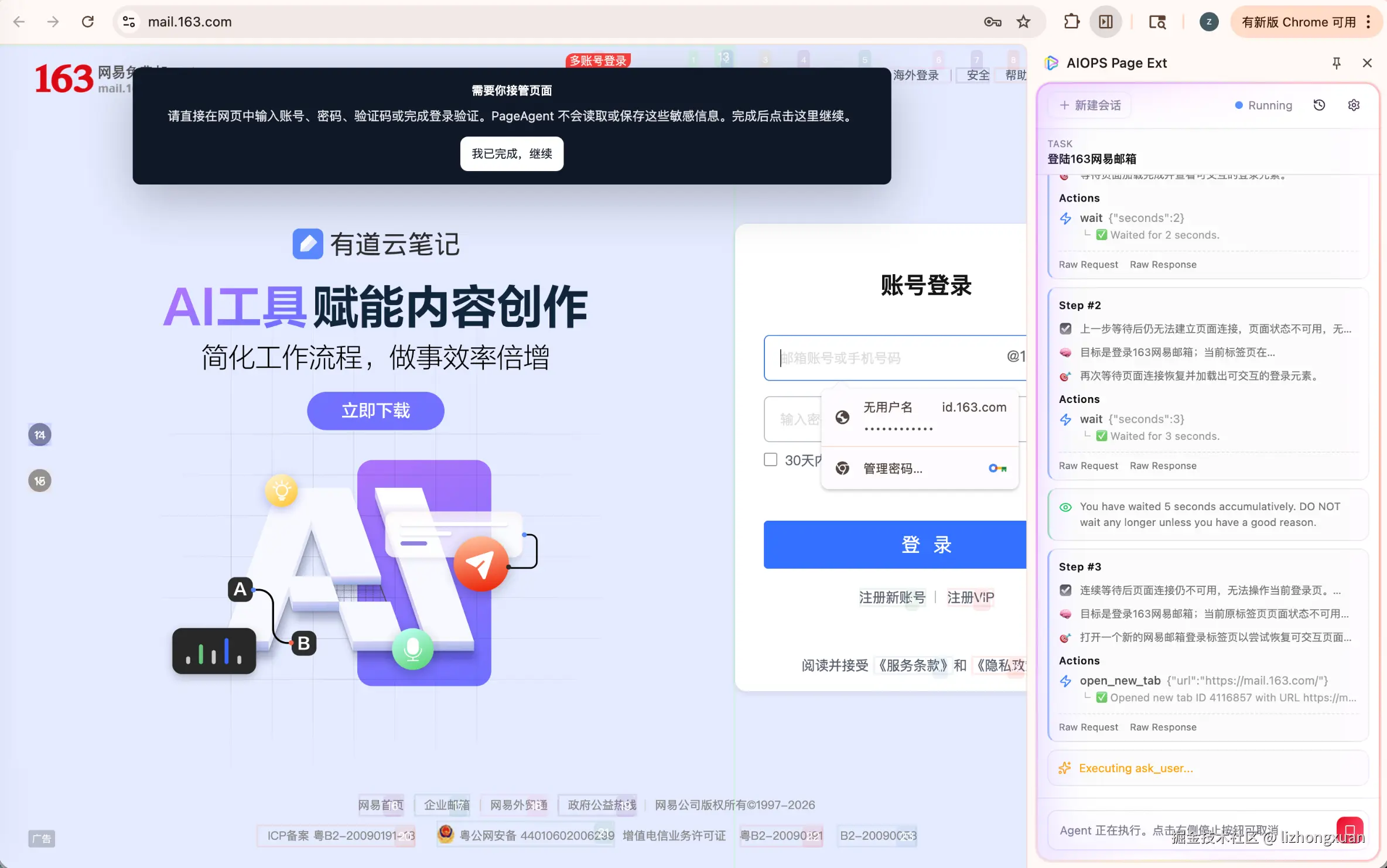 主要组件包括:
主要组件包括:
- Action Spotlight:高亮 Agent 准备操作的目标元素。
- Anchor Bubble:当页面上存在多个相似目标时,就地询问用户"是不是这个"。
- Handover Banner:遇到登录、MFA、验证码、密码、风控等场景时暂停,并提示用户手动完成。
- Input Prompt:需要用户补充信息时,在当前页面收集输入。
- Progress Toast:用轻量提示说明 Agent 当前动作和结果。
这些组件不是为了"炫 UI",而是为了让运维自动化具备可观察性和可控性。尤其在生产控制台里,用户需要知道 Agent 正在看哪里、准备做什么、为什么停下来。
操作录制与复放:从一次排查沉淀成可重复流程
AIOps 里的很多流程具有重复性:每天巡检、故障初筛、容量检查、发布前检查、告警处理、工单更新。自然语言 Agent 可以帮助探索第一次流程,但稳定流程不应该永远依赖 LLM。
aiops page ext 的 Session Recorder 会记录任务中的关键步骤,包括动作类型、目标元素、页面信息、选择器快照和必要的脱敏输入。成功执行后,Playwright Exporter 可以把这些步骤生成一个可复放项目。
这带来两个价值:
第一,探索阶段用 Agent 提升效率;沉淀阶段用脚本提升稳定性。
第二,故障处理过程可以被审计和复盘。团队可以看到 Agent 做过哪些页面操作、在哪一步遇到人工确认、哪些信息被用于判断。
一个可复放流程可以变成:
- 每天自动打开核心服务大盘并检查关键指标。
- 告警触发后自动收集日志、链路、变更记录。
- 发布前自动检查灰度状态和错误率。
- 工单关闭前自动补充排查证据和处理结论。
这正是 AIOps 从"智能问答"走向"智能执行"的关键一步。
风险控制:高权限场景必须可确认、可停止、可追踪
浏览器扩展天然拥有较强页面访问能力,AIOps 又经常连接生产系统,所以风险控制是基础能力,而不是附加项。
aiops page ext 在设计上遵循几个原则:
- 当前页面状态是事实来源,历史摘要不能直接作为可执行元素索引。
- 遇到登录、验证码、密码和敏感凭证时交给用户处理。
- 涉及回滚、删除、重启、屏蔽、扩缩容等高风险动作时应触发确认。
- 每一步动作要记录输入、输出、耗时和错误信息。
- 用户可以随时停止当前任务。
- 敏感字段进入录制和导出前需要脱敏。
这套机制不会让自动化变慢很多,却能避免 AIOps 系统从"帮忙处理问题"变成"制造新问题"。
与 MCP 和外部 Agent 的连接
aiops page ext 不只能从扩展侧边栏启动,也可以通过 MCP bridge 接入外部 Agent 客户端。这样,故障协同系统或桌面 AI 助手可以把浏览器任务交给扩展执行。
例如,ChatOps 中收到告警后,可以让外部 Agent 调用浏览器扩展:
text
打开告警详情,收集 checkout-service 最近 30 分钟的日志错误样例、
相关 trace 和最近发布记录,生成初步排查摘要。扩展执行完成后,结果可以回到对话上下文,也可以落到工单或故障记录里。这样,AIOps 的"分析"和"执行"不再割裂。
适合的 AIOps 场景
aiops page ext 特别适合这些场景:
- 告警初筛:打开告警详情,收集影响面、指标趋势和异常样例。
- 日志排查:根据服务名、traceId、错误码、时间窗口生成查询并阅读结果。
- 巡检:按固定清单检查大盘、资源水位、发布状态和错误率。
- 变更核查:查询最近发布、配置变更、扩缩容记录和关联工单。
- 工单辅助:补充排查证据、处理过程和结论摘要。
- 跨系统操作:在监控、日志、链路、CMDB、发布平台之间串联上下文。
- 流程沉淀:把高频排查路径导出为 Playwright 脚本。
它不适合无边界地替代人做生产决策。更合理的定位是:让 Agent 完成信息收集、页面跳转、重复操作和初步总结,让人负责风险判断、授权和最终动作。
工程落点:为什么它能在现有系统里落地
aiops page ext 的工程优势在于低侵入。
它不要求各个运维系统立即改造后端 API,也不要求把所有控制台统一重建。只要工程师能在浏览器里访问这些系统,扩展就有机会读取页面结构、理解任务并执行操作。
同时,它又不是一次性脚本:
- 通过文本化 DOM 保持可解释。
- 通过知识库增强补充业务语义。
- 通过页面交互组件保持人机协作。
- 通过录制和导出沉淀稳定流程。
- 通过 MCP bridge 接入更大的 Agent 生态。
这使它适合作为 AIOps 平台的一层渐进式增强:先帮助工程师减少重复操作,再沉淀高频流程,最后把成熟流程接入自动化和故障协同。
小结
aiops page ext 的价值可以用一句话概括:把 AIOps 从"会分析"推进到"能在浏览器控制台里协助执行"。
它用文本化 DOM 理解页面,用扩展能力连接多个运维系统,用知识库补足业务语义,用交互组件保留人工控制,用录制和 Playwright 导出沉淀可复放流程。对于已经有监控、日志、告警和工单体系,但仍然被大量浏览器操作拖慢的团队来说,这是一条务实的 AIOps 落地路径。
真正有用的 AIOps 不应该停在答案里。它应该能进入工程师每天工作的页面,帮忙收集证据、减少重复动作、留下过程记录,并在关键节点把决定权交还给人。aiops page ext 要做的,就是这一层连接。