在机器学习众多经典算法中,支持向量机(Support Vector Machine,SVM)是兼具数学严谨性、泛化能力与实用性的标杆算法。不同于决策树、逻辑回归等轻量化简易算法,SVM 凭借最优分类超平面、核函数映射、间隔最大化等核心特性,在小样本、高维度、非线性分类场景中表现尤为突出,至今仍是传统机器学习领域不可或缺的核心模型。本文将从基础定义、与机器学习的核心关联、底层原理、落地应用、主要代码这五个维度,聚焦算法本质与工业落地逻辑。
一、什么是支持向量机(SVM)
支持向量机是一种有监督的二分类机器学习算法,后续逐步拓展支持多分类、回归任务,其核心目标是在样本空间中,寻找一个最优的决策边界(超平面),实现不同类别样本的精准分割,同时保证模型具备最强的泛化能力。
很多初学者会被"支持向量"这个专业名词困惑,其本质含义十分直白:在所有训练样本中,距离最优分类超平面最近的样本点,就是支持向量。整个SVM模型的训练过程,仅由这些少量的支持向量决定,远离超平面的样本点对模型最终决策边界无任何影响。这也是SVM区别于多数机器学习算法的核心特点------模型训练聚焦关键样本,而非全部样本,极大降低了冗余数据的干扰。
从适用场景来看,SVM 原生适配二分类任务,通过一对一、一对多的拆分策略可拓展多分类;同时衍生出SVR(支持向量回归)算法,可用于连续值预测,是传统机器学习中少有的"分类+回归"双适配、高鲁棒性算法。
二、SVM与机器学习的核心关系
要理清二者关系,首先要明确机器学习的核心逻辑:机器学习是通过海量样本数据学习数据分布规律,构建通用模型,实现对未知数据预测、分类、拟合的技术体系,而SVM是这一体系中经典的判别式模型,是传统机器学习的核心基石算法之一。二者的从属与关联关系可从三个核心维度拆解:
- 从属关系:经典监督学习核心算法
机器学习分为监督学习、无监督学习、半监督学习、强化学习四大分支,SVM 隶属于监督学习范畴。其训练依赖带标签的标注数据,通过学习输入特征与输出标签的映射关系,生成决策模型,与逻辑回归、随机森林、KNN共同构成传统机器学习四大核心算法。在深度学习兴起之前,SVM 是工业界和学术界分类任务的最优算法,是机器学习落地的核心支撑。 - 算法定位:小样本高维数据的最优解
多数传统机器学习算法存在明显短板:逻辑回归对非线性数据拟合能力差、KNN对高维数据失效、决策树容易过拟合。而SVM 精准弥补了这些缺陷,它专门针对小样本、高维度、非线性、高噪声数据场景优化,是传统机器学习中泛化能力最强、容错率最高的算法,也是高维特征任务的首选模型。 - 理论地位:机器学习最严谨的数学模型
大部分机器学习算法基于经验损失优化,缺乏严格的数学理论支撑,可解释性弱。而SVM 完全基于凸优化、间隔最大化、结构风险最小化理论构建,模型训练的最优解是全局唯一的,不存在局部最优问题,这是神经网络、决策树等算法无法比拟的优势,也让SVM 成为机器学习理论研究的标杆性算法。
三、支持向量机核心原理
SVM 的核心原理可层层递进拆解为三个核心阶段,从线性可分基础场景,到线性不可分场景,再到非线性高维场景,完整覆盖算法核心逻辑,避开晦涩的纯公式推导,聚焦原理本质。
- 核心思想:间隔最大化(最优分类标准)
在二维平面中,分类任务就是找一条直线分割两类数据;在三维空间中是找一个平面;在高维空间中,这个分割边界统称为超平面。
普通分类算法(如逻辑回归)仅要求"分割正确",只要训练样本分类无误即可,因此会产生无数个分割超平面。而SVM 的核心差异化逻辑是:不仅要分割正确,还要让两类样本距离超平面的间隔最大。
间隔越大,说明模型对样本扰动的容错能力越强,泛化能力越好,越不容易出现过拟合。这就是SVM 结构风险最小化的核心体现------不追求训练集100%拟合,而是追求模型对未知数据的适配能力。而决定这个最大间隔的,正是前文提到的支持向量。 - 软间隔:解决线性不可分与噪声问题
基础的硬间隔SVM要求所有样本必须完全正确分割,现实场景中几乎不存在绝对线性可分的数据,少量噪声、异常点就会导致硬间隔模型失效。为此SVM 引入软间隔机制。
软间隔允许少量样本突破间隔边界、甚至错分,通过引入惩罚系数C,平衡"分类准确率"和"间隔最大化":C值越大,对错误样本的惩罚越重,模型越严格,容易过拟合;C值越小,容错率越高,模型泛化性越强,容易欠拟合。通过这一机制,SVM 完美适配现实中带噪声的线性数据。 - 核函数:破解非线性数据分类难题
面对完全非线性、无法通过线性超平面分割的数据,SVM 引入核函数实现维度升维,这是SVM 最核心、最精髓的创新点。其底层逻辑非常简单:低维空间无法分割的数据,映射到高维空间后,大概率可以实现线性可分。
直接将数据映射到高维空间会产生巨大的计算量,而核函数的核心价值是:无需显式完成高维映射,通过核函数计算低维样本的内积,等效实现高维空间分类,极大降低了计算成本。
工业界最常用的三类核函数:
- 线性核:适用于数据本身线性可分的场景,计算速度最快,是文本分类、高维稀疏数据首选;
- 高斯核(RBF核):通用核函数,适配绝大多数非线性场景,无需手动调参,容错率最高,是工业默认首选;
- 多项式核:适用于特征存在多项式关联的数据,多用于结构化数据挖掘场景。
四、SVM在机器学习中的应用场景
SVM 并非万能算法,其优势集中在小样本、高维特征、高精度需求场景,在大数据、超大规模样本场景中,训练速度远不如深度学习、梯度提升树,因此落地场景具有极强的针对性,传统机器学习工业落地中使用率极高。
- 文本分类与情感分析
这是SVM 最经典、最成熟的落地场景。文本数据经过TF-IDF、词向量处理后,具备高维稀疏的特征特点,SVM 线性核对高维稀疏数据适配性极强,训练速度快、分类精度高,效果优于朴素贝叶斯、逻辑回归。广泛用于垃圾邮件识别、新闻主题分类、用户评论情感判别、违规文本审核等任务。 - 图像识别与特征分类
在深度学习普及前,SVM 是图像分类、人脸识别、手写数字识别的核心算法。通过提取图像HOG、SIFT人工特征,输入SVM模型即可实现精准分类,至今仍用于轻量化图像检测场景,如工业微小缺陷识别、证件图像分类、人脸特征比对等,优势是无需大量图像样本,小数据集即可达到高精度。 - 医疗数据诊断预测
医疗数据普遍存在样本量少、特征维度高、数据噪声大的特点,完美契合SVM的算法优势。常被用于肿瘤筛查、疾病风险预测、心电信号分类、医学影像特征判别等任务,模型稳定性强、误判率低,符合医疗场景的高精度、高可靠性要求。 - 金融风控与异常检测
金融风控中的欺诈识别、用户违约预测、交易异常检测,核心是小概率、高风险样本分类问题。SVM 对异常样本敏感度高、泛化能力强,可精准区分正常交易与欺诈交易、优质用户与违约用户,是传统金融风控体系的经典算法。 - 小样本回归预测(SVR)
除分类任务外,SVR支持向量回归可用于小样本连续值预测,如短期销量预测、传感器数据拟合、气象小幅预测等。相较于线性回归,SVR 抗噪声能力更强,不会被极端异常值干扰,小样本预测精度远优于传统回归算法。
五、SVM核心代码
以下基于Python sklearn实现SVM分类实战,包含数据集加载、模型训练、参数调优、评估分析、可视化全流程,是工业项目通用标准代码,适配绝大多数分类场景。
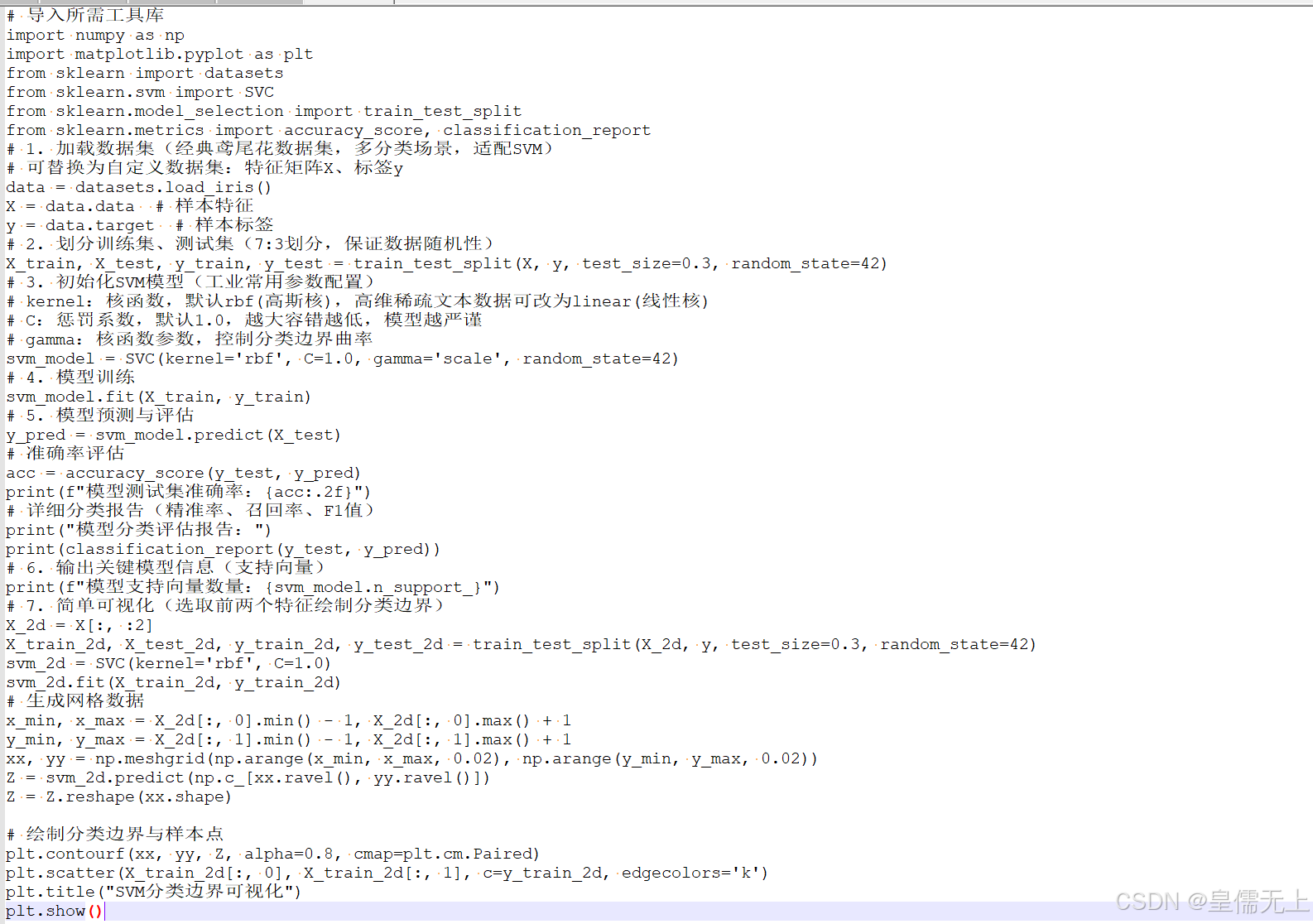
核心参数调优经验(工业落地关键)
-
高维稀疏数据(文本、用户特征):优先使用 kernel='linear',训练速度快、无过拟合风险;
-
非线性复杂数据、小样本数据:默认使用 kernel='rbf',微调C值适配噪声;
-
数据噪声大:减小C值(0.1、0.5),降低惩罚力度,提升泛化能力;
-
训练精度不足:增大C值(2、5、10),强化模型拟合能力。
六、总结:SVM的核心价值与定位
从算法本质来看,支持向量机是传统机器学习中理论最完善、泛化能力最强、容错率最高的经典算法。它区别于其他算法的核心优势,在于摒弃了"拟合全部数据"的粗放逻辑,聚焦核心支持向量,通过间隔最大化与核函数升维,同时解决了线性、非线性、小样本、高维数据的分类难题。
在深度学习大行其道的当下,SVM 并未被淘汰。对于标注数据稀缺、特征维度高、要求模型可解释、需要高精度稳定输出的传统工业场景,SVM 依然是不可替代的最优选择,也是机器学习从业者必须掌握的核心底层算法。相较于深度学习的黑盒特性,SVM 严谨的数学逻辑、可控的参数调优、稳定的输出效果,使其在传统AI落地场景中始终占据核心地位。