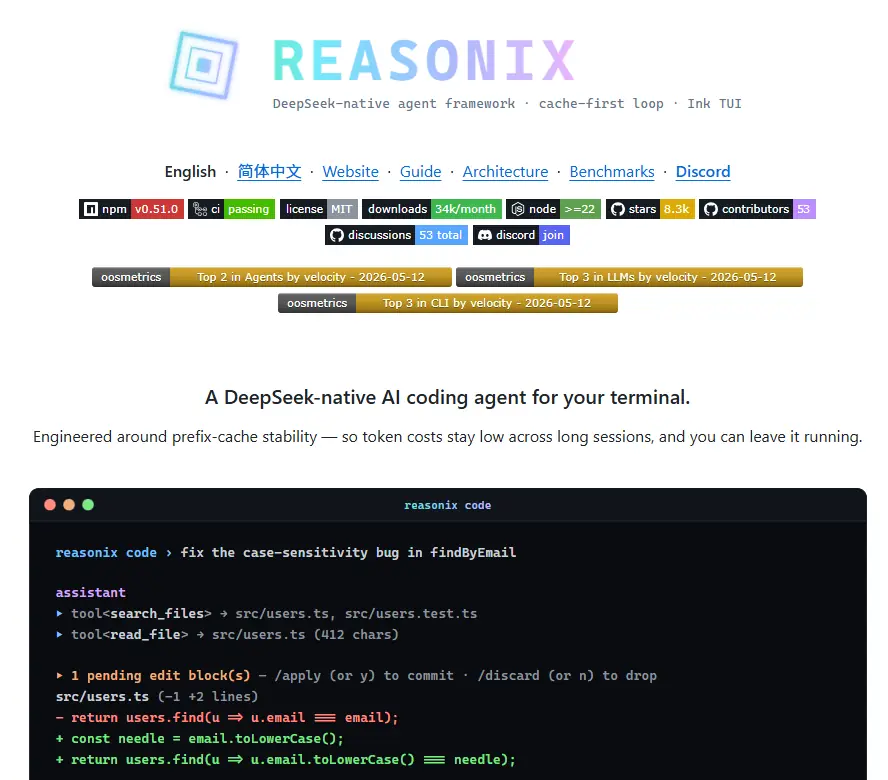
Claude Code、Cursor、GitHub Copilot...选择挺多,但有个共同毛病:贵。
这时候我盯上了 DeepSeek,但问题是:如果只是模型便宜,大家直接用 Claude Code 或 OpenCode 连 DeepSeek API 不就行了?干嘛还专门做个工具?
答案藏在 DeepSeek 的一个隐藏功能里:前缀缓存(Prefix Cache)。
Github:
一句话说清楚
DeepSeek-Reasonix 是专门给 DeepSeek 做的终端编程助手,靠着"缓存优先"的设计,缓存命中率能做到 85%-99%,API 成本砍 80%-93%。
简单说:它不是那种啥模型都支持的通用工具,而是 DeepSeek 的"专属搭档",把 DeepSeek 的省钱能力榨得干干净净。
为什么通用框架不行?
DeepSeek 的 API 有个很诱人的功能:缓存命中的输入 Token 只收 10% 的钱。
也就是说,如果这次请求和上次请求的开头完全一样,这部分 Token 直接打一折。
听着挺美,对吧?但问题是:通用框架根本用不好这个功能。
通用框架的问题
LangChain、LlamaIndex 这些通用框架把 DeepSeek 当成"换了个 base URL 的 OpenAI",每轮对话都在折腾:重新排序历史消息、塞新的时间戳、重构 system prompt、工具列表每次序列化结果都不一样。
结果就是:缓存命中率常常不到 20%。
DeepSeek 明明给了张 90% 折扣的优惠券,通用框架却只会用 10% 的额度。
Reasonix 的三大技术支柱
Reasonix 从底层设计就围着 DeepSeek 的前缀缓存机制转,靠三大支柱把成本控制到极致:
第一支柱:缓存优先循环
Reasonix 把每次请求的上下文拆成三块,每块都有严格的不变性保证:
css
┌─────────────────────────────────────┐
│ IMMUTABLE PREFIX │ ← 整个会话永不变
│ system + tool_specs + few_shots │ 这是缓存的靶子
├─────────────────────────────────────┤
│ APPEND-ONLY LOG │ ← 只能追加
│ [user₁][assistant₁][tool₁]... │ 旧 turn 作为新 turn 的 prefix
├─────────────────────────────────────┤
│ VOLATILE SCRATCH │ ← 每轮重置
│ R1 思考、临时 plan state │ 永不上传
└─────────────────────────────────────┘不可变前缀里放着系统提示词、工具声明、Few-shots 示例,整个会话期间固定不动,这是缓存命中的核心靶子。仅追加日志保存历史对话,严格只追加不修改,确保旧的对话轮次作为新轮次的 prefix 被复用。易失性草稿每轮重置,放着 R1 的思考过程、临时的 plan state,绝不发给上游模型,避免污染后续缓存。
靠这种三区设计,Reasonix 实现了字节级稳定的前缀缓存,缓存命中率能做到 85%-99%。
第二支柱:R1 思考链回收
DeepSeek-R1 会在 reasoning_content 里输出很长的思考链。通用框架要么直接回传给下一轮(DeepSeek 官方明确说不推荐,会降低效果),要么显示给用户看一眼就扔了。
Reasonix 的做法是:从 R1 的思考链里提取结构化信息。
R1 思考结束后,再发一次 V3 请求(便宜,大概 $0.0001)在 JSON 模式下提取:
typescript
interface TypedPlanState {
subgoals: string[]; // R1 识别出的子目标
hypotheses: string[]; // R1 探讨的假设
uncertainties: string[]; // R1 标记的不确定点
rejectedPaths: string[]; // R1 考虑后放弃的路径
}实际效果示例(问一道逻辑题):
scss
‹ subgoals (3): 列出所有可能的标签与内容组合 · 确定从哪个盒子摸水果 · 验证唯一性
‹ hypotheses (3): 从"苹果"标签盒摸 · 从"橘子"标签盒摸 · 从"混合"标签盒摸
‹ uncertainties (2): 摸到水果是否能唯一确定 · 混合盒摸到的概率
‹ rejected (2): 从"苹果"盒摸(信息量不足) · 从"橘子"盒摸(对称问题)这不是幻觉,真实对应 R1 思考链里的实际内容。
这个功能默认关着,可以通过 --harvest 参数或 TUI 里的 /harvest on 打开。
第三支柱:工具调用修复
DeepSeek 的 function calling 有几个已知 bug,通用框架不处理就直接崩。
| 问题 | 表现 |
|---|---|
| 深嵌套 schema 丢参数 | 工具 schema 有 >10 个参数或嵌套 >2 层时,V3/R1 经常漏字段 |
R1 把 tool call JSON 藏在 <think> 里 |
忘了冒泡到 tool_calls 字段 |
| max_tokens 截断 tool arguments JSON | 导致下游 JSON.parse 崩 |
| Call-storm | 同一个工具 + 同样参数连续调用 |
Reasonix 的 Repair 层用四个模块对应修复:Auto-flatten 深 schema 自动检测复杂 Schema,转成"点分表示法";Think-block scavenger 扫描 think 块,把逃逸的 tool call 抓回来;Truncation recovery 检测到截断时自动重试或修复;Deduplication 检测并合并重复的 tool call。
省钱效果有多夸张?
这是 Reasonix 最香的地方,直接看数据:
实测数据对比
| 指标 | Reasonix + DeepSeek | Claude Sonnet 4.6 | 节省比例 |
|---|---|---|---|
| 5 轮中文多轮对话成本 | $0.000923 | $0.015174 | 93.9% |
| 缓存命中率 | 85.2% | N/A | - |
| Tool-use 场景(2轮) | $0.0003 | $0.0072 | 95.8% |
| 单日 4.35 亿 Token | $12 | ~$61 | 80% |
真实用户案例
有开发者一天处理了 4.35 亿输入 Token,缓存命中率 99.82%,实际花费大概 12 美元。
如果没有 Reasonix 的缓存优化,哪怕用低成本的 DeepSeek-V4-Flash,也得花 61 美元左右。
直接省掉 49 美元,相当于打 2 折。
换算成人民币:本来要花 430 多块,实际只花了 85 块。
三种工作模式
Reasonix 提供三种使用方式,适应不同场景:
1. reasonix code
这是最核心的模式,支持项目级别的上下文理解:
bash
cd /path/to/your-project
npx reasonix code特点:
- 使用经典的 SEARCH/REPLACE 块进行精准代码编辑
- 所有磁盘写入都需要用户手动输入
/apply确认 - 支持文件系统工具、Shell 命令执行
2. reasonix chat
去掉了文件系统工具的访问权限,纯粹用于技术讨论:
bash
npx reasonix chat特点:
- 不碰文件系统,保障隐私与速度
- 适合架构设计、头脑风暴
- 避免不必要的文件扫描
3. reasonix run
用于一次性任务,流式输出到标准输出:
bash
npx reasonix run "分析这个文件的依赖关系"特点:
- 可以直接嵌入 Shell 管道脚本
- 无会话模式,省掉上下文维护开销
- 适合自动化运维或脚本处理
安装与使用
系统要求
Node.js ≥ 22(推荐最新 LTS 版),支持 Windows / macOS / Linux,还需要一个从 platform.deepseek.com 获取的 DeepSeek API Key。
安装方式
方式一:npx 运行(推荐),无需安装,每次自动拉最新版:
bash
cd your-project
npx reasonix code方式二:全局安装:
bash
npm install -g reasonix
reasonix code首次配置
第一次运行会弹出配置向导:粘贴 DeepSeek API Key,选择运行模式(默认 smart),可选配置 MCP。配置自动保存到 ~/.reasonix/config.json。
常用命令
| 命令 | 功能 |
|---|---|
npx reasonix code |
启动编码 Agent |
npx reasonix chat |
纯聊天模式 |
npx reasonix run "任务" |
一次性任务 |
/pro |
切换到 V4-Pro 模型 |
/preset max |
整个 session 都用 Pro |
/plan |
进入只读规划模式 |
/apply |
确认执行 plan 的改动 |
/stats |
查看 Token 消耗和成本 |
/skill new 名称 |
创建可复用技能脚本 |
/mcp add |
添加 MCP 外部工具 |
进阶特性
除了核心的 AI 编码能力,Reasonix 还有一些进阶功能:
联网搜索默认用保护隐私的 Mojeek 搜索引擎,也支持自托管的 SearXNG,让 AI 随时获取最新的 API 文档和技术资讯。
MCP 支持兼容模型上下文协议,可以轻松扩展工具链。
计划模式下,执行复杂重构前 AI 会先输出大纲和步骤,经用户确认后再动手。
语义搜索与自动检查点功能可以智能索引项目代码,自动创建代码检查点(Checkpoint),方便随时回滚。
嵌入式 Web 仪表盘提供了一个简洁的 Web 界面,实时查看当前的缓存命中率、Token 消耗以及成本曲线。
Flash/Pro 双模智能切换让你平时用极其廉价的 Flash 跑日常迭代,遇到难关输入 /pro 一键切换到 Pro 模型。
适用人群
DeepSeek 重度用户:如果你已经在用 DeepSeek API,Reasonix 能让你把成本再降 80%。
预算敏感的开发者:不想每月花 20 美元订阅 Cursor,也不想按量付费时被账单吓到。
终端党:习惯在终端里工作,不喜欢 IDE 插件的侵入性。
长上下文场景:需要处理大型项目、超长会话,对 Token 消耗敏感。
同类工具对比
| 工具 | 模型支持 | 成本 | 缓存优化 | 特点 |
|---|---|---|---|---|
| Reasonix | DeepSeek 专属 | 极低 | ⭐⭐⭐⭐⭐ | 缓存命中率 85%-99% |
| Claude Code | Claude 系列 | 高 | ❌ | 官方优化,功能全面 |
| Cursor | 多模型 | 20美元/月 | ❌ | IDE 集成,体验好 |
| OpenCode | 多模型 | 中 | ❌ | 开源,子 Agent 支持 |
| Aider | 多模型 | 中 | ❌ | 终端友好,Git 集成 |
Reasonix 的优势很明显:首先是成本最低,缓存后的成本只有其他工具的 1/10 甚至 1/20;其次是缓存优化最强,专为 DeepSeek 前缀缓存设计;第三是 DeepSeek 原生,能充分利用 R1 的 reasoning_content;最后是轻量无侵入,终端运行,不绑定 IDE。
当然它也有一些局限:只支持 DeepSeek,不能用其他模型;功能相对专注,不如 Claude Code 全面;终端界面,对 GUI 党不够友好。
Github:
写在最后
Reasonix 走了一条极致的专精路线:不搞大而全的多模型兼容,而是死磕一个模型,把它用到极致。
这种设计哲学的优势在于成本极低,缓存命中率能做到 85%-99%,成本降低 80%-93%;性能优化方面针对 DeepSeek 的特定 bug 做了专项修复;还能充分利用 DeepSeek 的特性,比如 R1 的思考链回收、前缀缓存机制。
总的来说,如果你是 DeepSeek 用户,或者想找一款极致省钱的 AI 编程助手,Reasonix 是目前最好的选择。
关注
如果你觉得这篇文章对你有帮助,欢迎关注我们的公众号,获取更多开源工具的深度解读和使用指南。