一、强化学习中的回报
状态:
回报:
(更快的获得奖励可能比需要很长时间才能得到的奖励更具有吸引力)
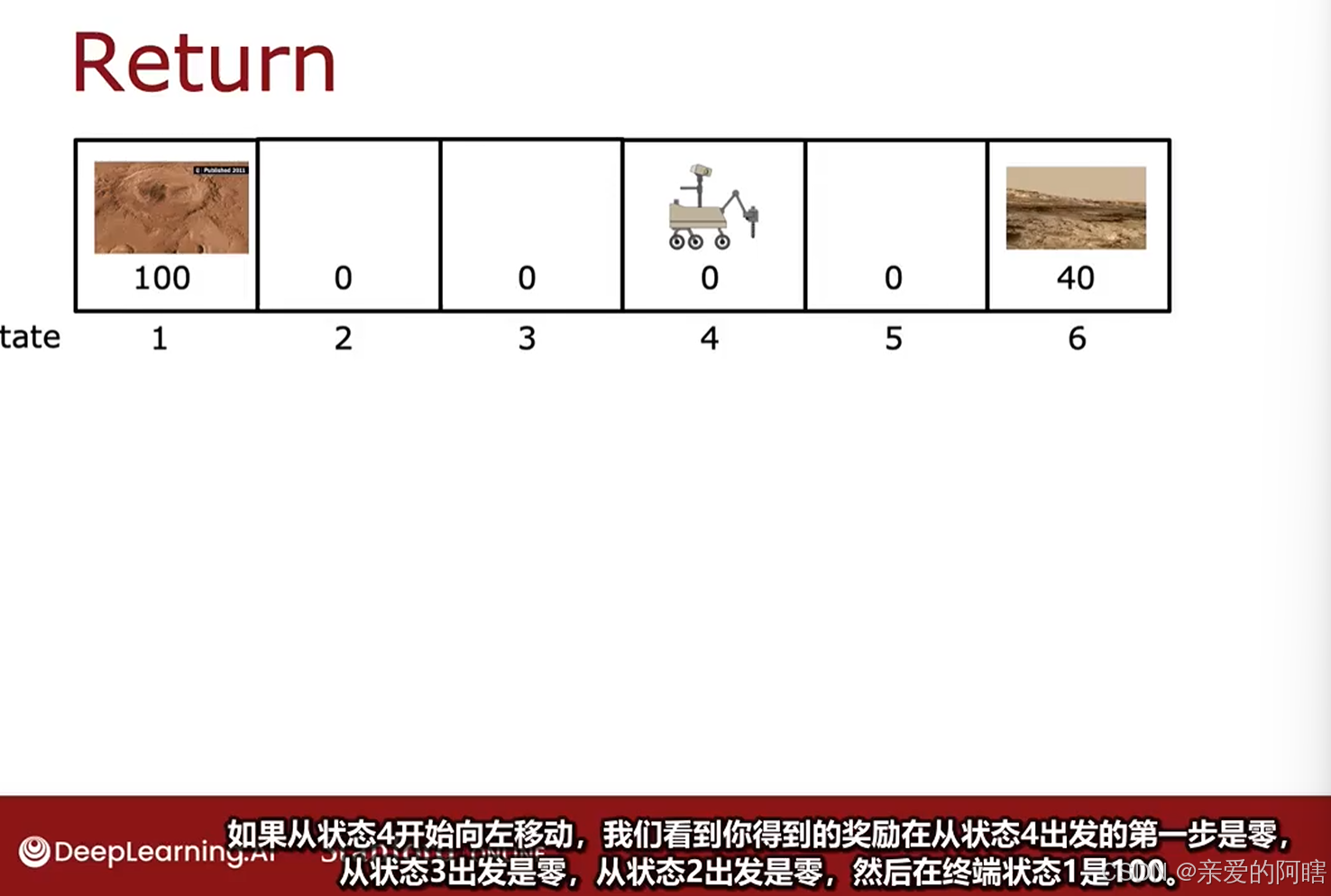
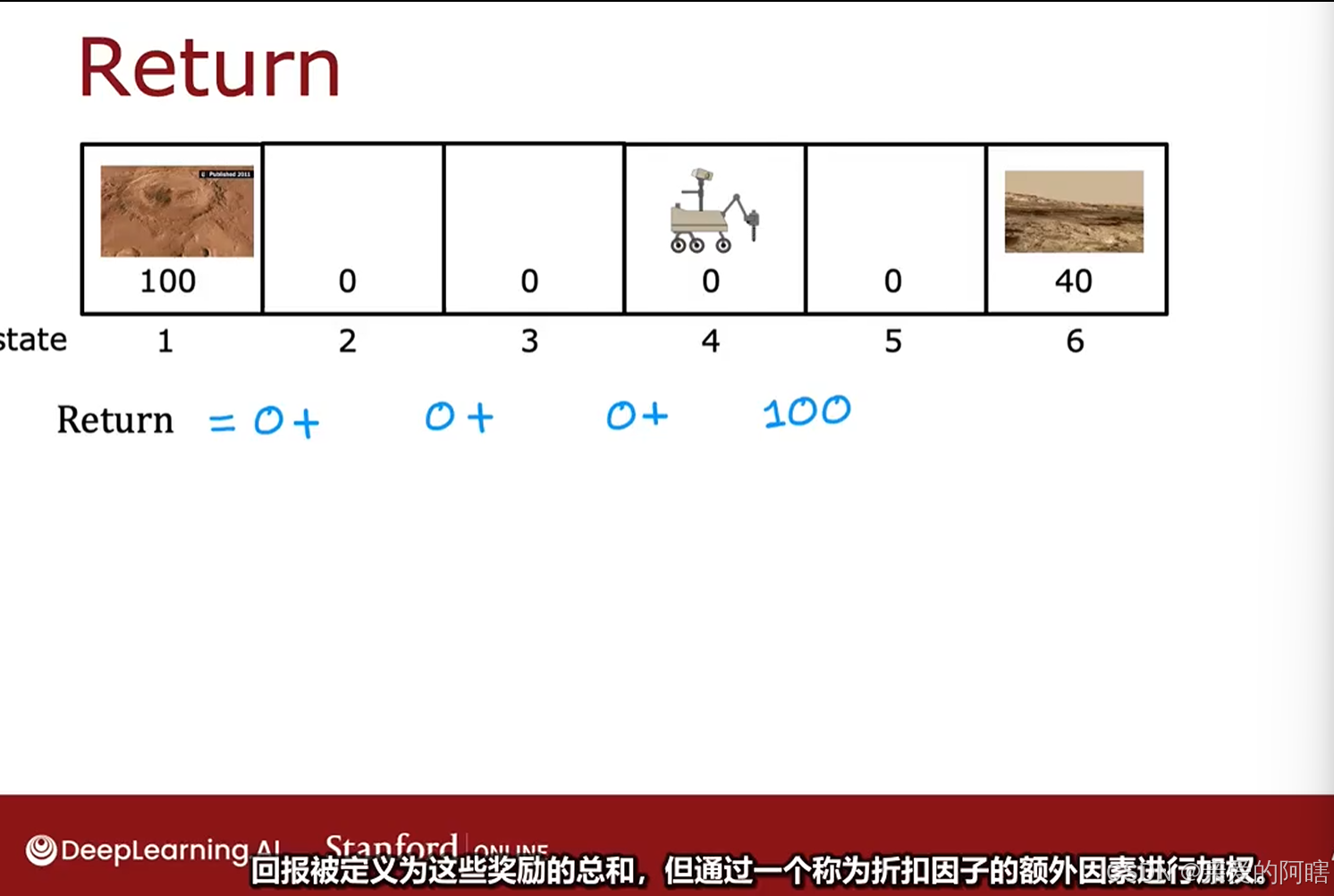
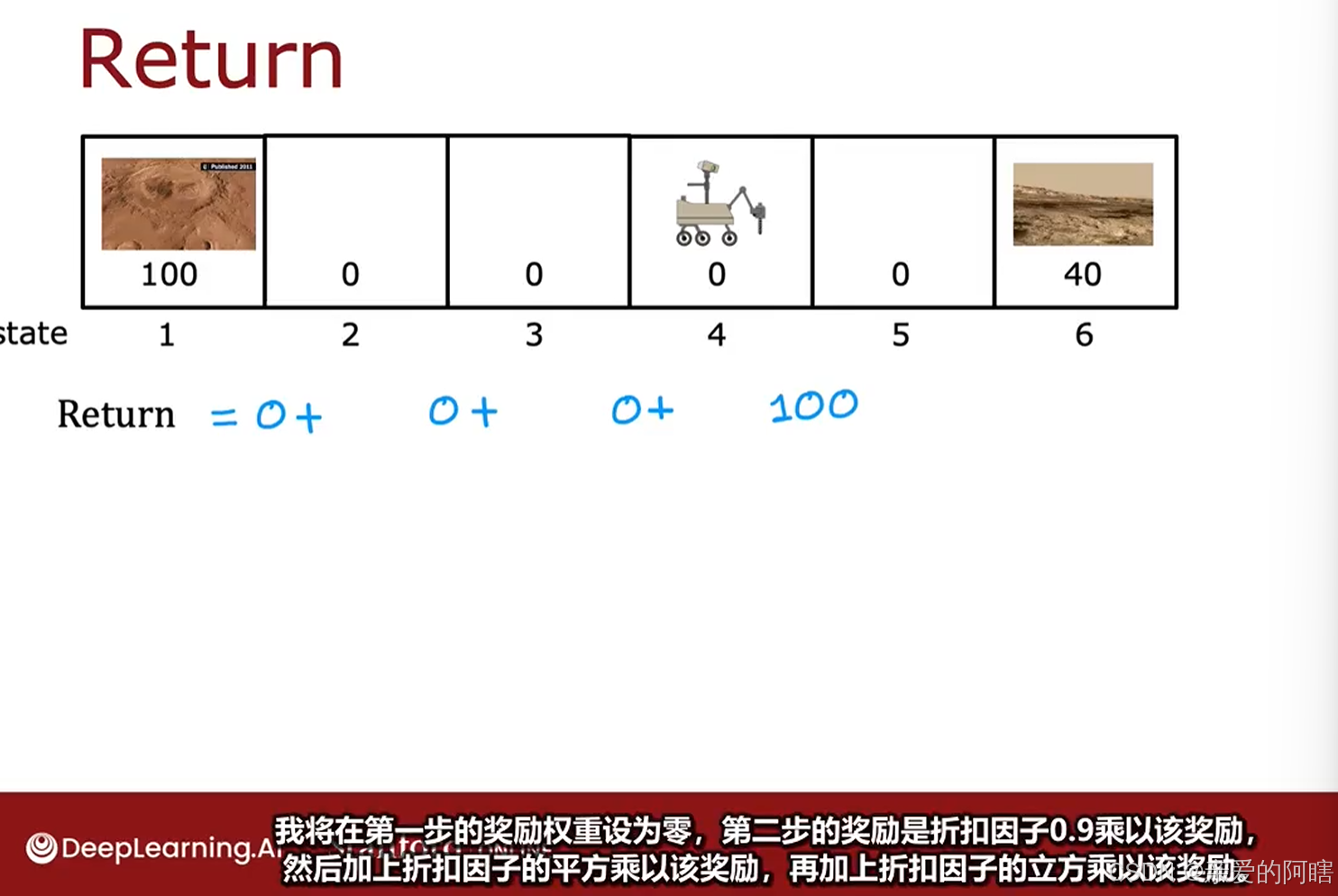



折扣因子一般是比1少一点的数,如0.9,0.99,0.999等,下面为了说明目的,暂且使用0.5的折扣因子,这将极大的降低未来奖励的权重,或者说极大的折扣了未来的奖励,因为每经过一个时间戳,你只能获得比前一步少一半的奖励信用。

例子:
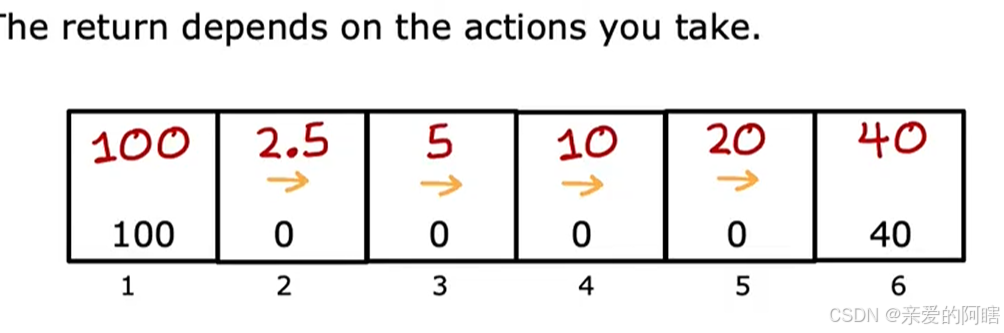
(你得到的奖励取决于奖励,而奖励又取决于你采取的行动,因此回报取决于你采取的行动)
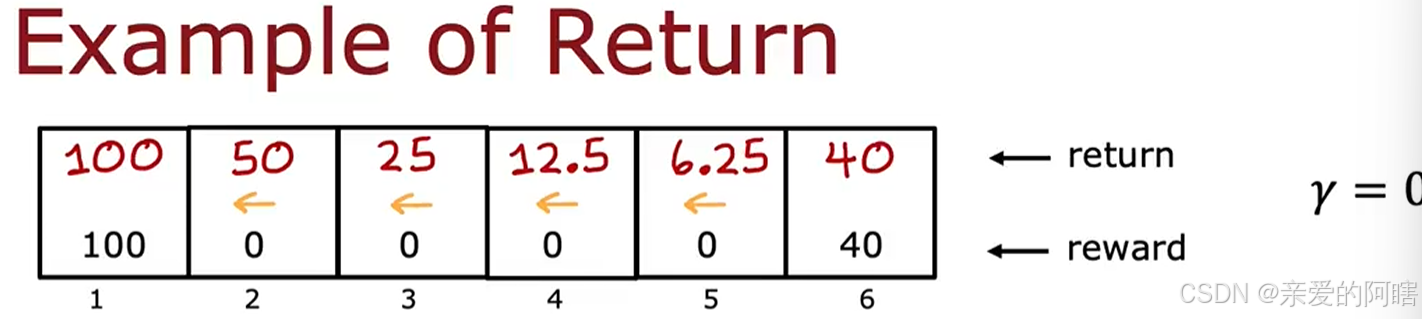
例1:基于上述例子,若一直只往左走,折扣因子=0.5,则分别从不同状态起步获得的奖励计算如下:
例2:如果总往右走,那么如果从状态4开始,(下图中第一个0右上角的4表示状态4)
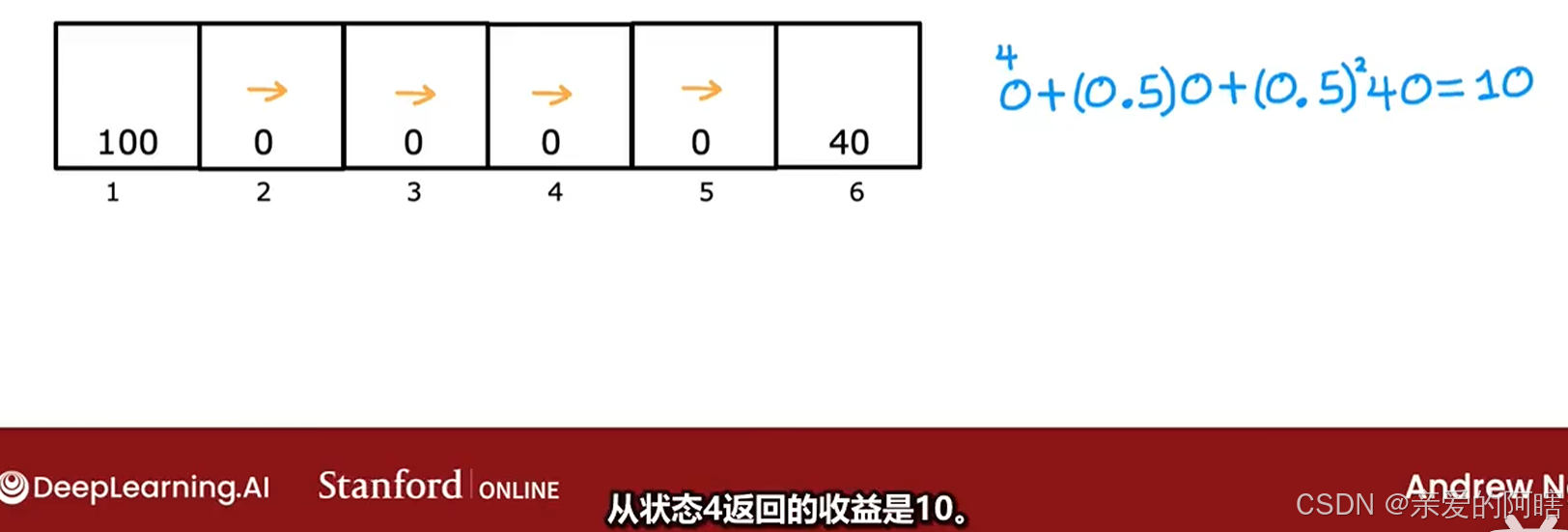
分别从不同状态起步获得的奖励计算如下:
二、强化学习中的策略
在强化学习中,我们的目标是提出一个称为策略Pi的函数,其任务是接收任何状态s作为输入,并将其映射到它希望我们采取的某个动作a。
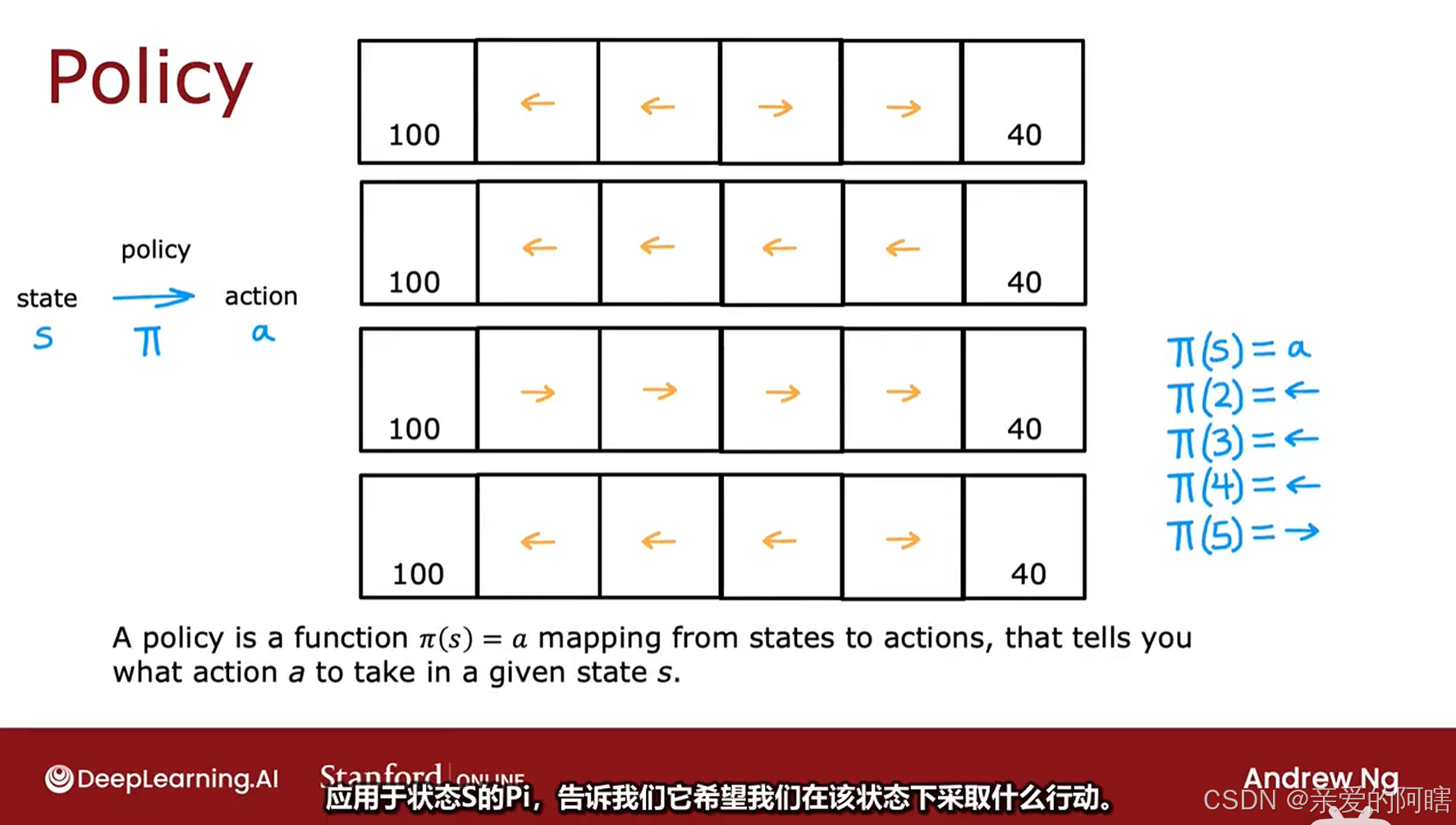
强化学习的目标是找到一个策略Pi或S的Pi,它告诉你在每个状态下应采取什么行动,以最大化回报。