小肥柴的Hadoop之旅 快速实验篇(A2-1)基于MapReduce的数据质量筛查与清洗
-
- 目录
- [0. 概要](#0. 概要)
- [1. 准备工作](#1. 准备工作)
-
- [1.1 前置条件与输入](#1.1 前置条件与输入)
- [1.2 集群环境验证(关键前置步骤)](#1.2 集群环境验证(关键前置步骤))
-
- [1.2.1 YARN 节点注册检查](#1.2.1 YARN 节点注册检查)
- [1.2.2 完整调度链路测试](#1.2.2 完整调度链路测试)
- [2 虚拟机内存适配与集群配置](#2 虚拟机内存适配与集群配置)
-
- [2.1 Worker节点内存压力分析](#2.1 Worker节点内存压力分析)
- [2.2 集群全局配置](#2.2 集群全局配置)
-
- [2.2.1 更新配置文件内容](#2.2.1 更新配置文件内容)
- [2.2.2 同步配置](#2.2.2 同步配置)
- [2.3 作业资源适配分析](#2.3 作业资源适配分析)
- [3. 数据质量校验规则](#3. 数据质量校验规则)
- [4. 代码实现](#4. 代码实现)
-
- [4.1 选择MultipleOutputs的理由](#4.1 选择MultipleOutputs的理由)
- [4.2 Mapper关键API:setup / map / cleanup](#4.2 Mapper关键API:setup / map / cleanup)
- [4.3 完整代码](#4.3 完整代码)
- [5 本地开发环境配置(Windows + IDEA + Maven)](#5 本地开发环境配置(Windows + IDEA + Maven))
-
- [5.1 安装 Eclipse Temurin JDK 8](#5.1 安装 Eclipse Temurin JDK 8)
- [5.2 IDEA 配置](#5.2 IDEA 配置)
- [5.3 项目结构与 pom.xml](#5.3 项目结构与 pom.xml)
- [5.4 编译打包](#5.4 编译打包)
- [6. 作业提交](#6. 作业提交)
-
- [6.1 命令说明](#6.1 命令说明)
- [6.2 运行日志关键节点说明](#6.2 运行日志关键节点说明)
- [7. 首次运行结果与数据质量探查](#7. 首次运行结果与数据质量探查)
-
- [7.1 输出文件结构](#7.1 输出文件结构)
- [7.2 行数统计(单个 Map 输出文件示例)](#7.2 行数统计(单个 Map 输出文件示例))
- [8. 在实验过程中常见问题与排查记录](#8. 在实验过程中常见问题与排查记录)
- [9. 实验A2-1总结](#9. 实验A2-1总结)
- [与 A2-2 的衔接和任务预告](#与 A2-2 的衔接和任务预告)
目录
0. 概要
| 项目 | 说明 |
|---|---|
| 定位 | 农业气象干旱分析模块的第2个任务,首次使用MapReduce进行批量数据处理 |
| 目标 | 1. 应用MapReduce对CSV数据执行七项质量校验 2. 将合规记录与问题记录(含原因)分流输出 3. 在2GB内存受限环境中完成集群配置与调优 4. 完成首次清洗运行,进行数据质量探查与问题定位 |
| 输入 | HDFS路径 /drought/raw/test_set.csv(含表头,约1.07GB,22个字段) |
| 输出 | /drought/cleaned:通过全部校验的记录 /drought/rejected:未通过校验的记录及异常标签 |
1. 准备工作
1.1 前置条件与输入
- 集群状态:Hadoop 完全分布式集群已搭建,HDFS 和 YARN 服务已启动
- 基础数据 :HDFS 中存在
/drought/raw/test_set.csv(由上一阶段生成,约 10 个 Block) - 开发工具:Windows 环境下的 IntelliJ IDEA + Maven,需额外配置 JDK 8(即使系统默认 JDK 为更高版本);或直接在集群节点上用 Vim + 命令行编译
- 物理机环境:内存 16GB,运行 5 台虚拟机(每台 2GB)后总内存占用约 10GB,建议关闭浏览器等非必要应用
1.2 集群环境验证(关键前置步骤)
jps 命令仅能确认 Java 进程存在,无法验证服务间的通信和资源就绪情况。以下检查必须在作业提交前全部通过,确保所有节点通讯正常、可用。
1.2.1 YARN 节点注册检查
bash
yarn node -list(1)预期输出 :3 个节点,状态均为 RUNNING。
(2)异常情况 Total Nodes:0 :检查 yarn-site.xml 中 yarn.resourcemanager.hostname 是否正确配置。
【注】也可以使用ARN Web UI 佐证,但也仅仅是佐证:
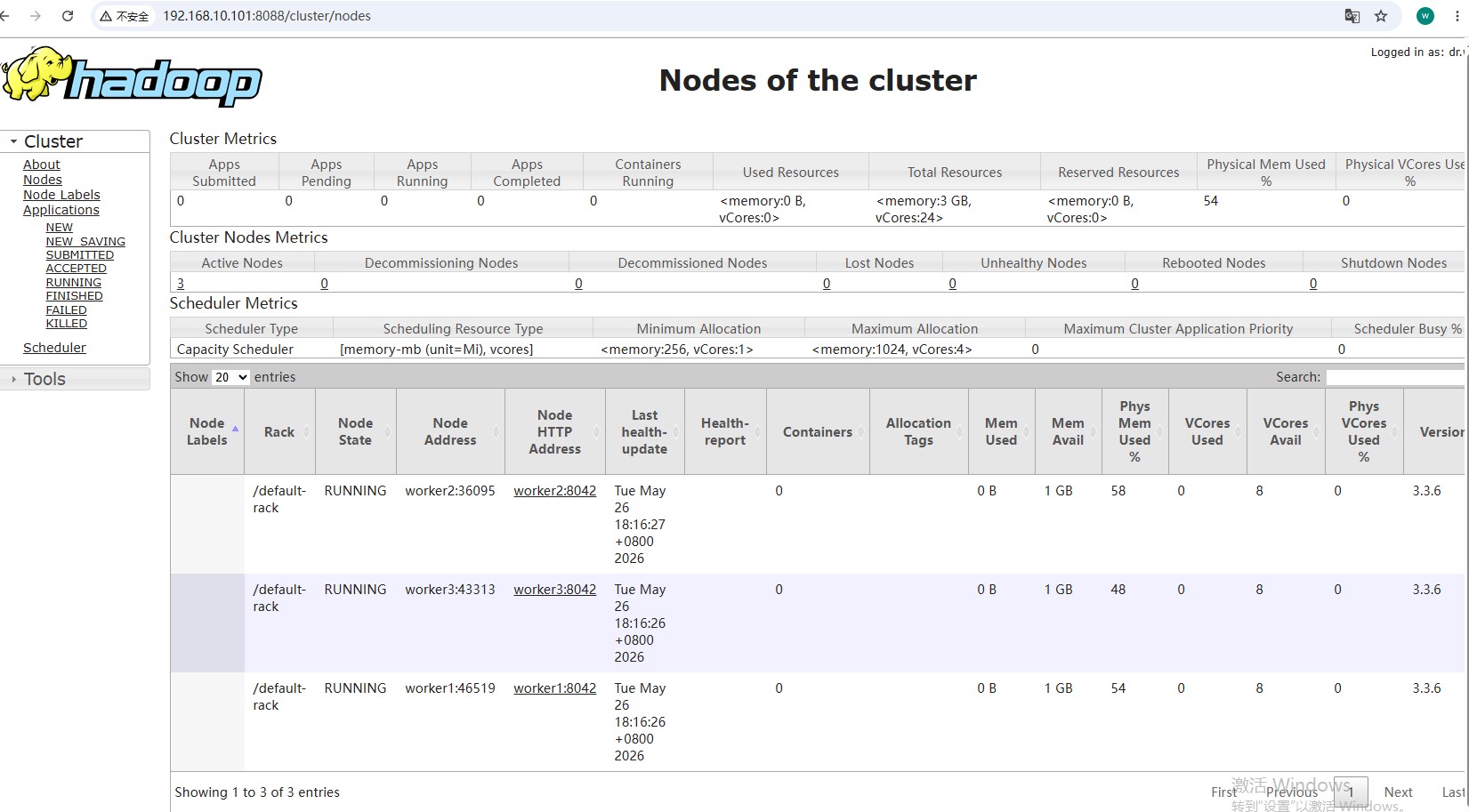
访问 http://192.168.10.101:8088 ,查看 Nodes 标签,确认每个 Worker 的 Memory 显示为 1024 MB(或者以上,我的是1.5GB)。
1.2.2 完整调度链路测试
尝试运行官方提供的案例程序,检测调度功能是否正常。
bash
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar pi 2 2(1)预期输出 :作业状态为 FINISHED 且 SUCCEEDED。
(2)若失败,常见原因:
MRAppMaster找不到,检查:mapred-site.xml是否缺失yarn.app.mapreduce.am.env配置。mapreduce_shuffle服务不存在,检查:yarn-site.xml是否缺失yarn.nodemanager.aux-services配置。- 容器内存超限,检查:
yarn.scheduler.maximum-allocation-mb配置。
2 虚拟机内存适配与集群配置
各节点仅2GB物理内存,必须精细裁剪YARN与MapReduce参数,否则作业无法获取任何Container;因此需要调整配置参数。
2.1 Worker节点内存压力分析
| 组件 | 预估占用 | 说明 |
|---|---|---|
| Ubantu 最小化安装 | 300--400 MB | 无GUI |
| DataNode进程 | 512 MB | HADOOP_DATANODE_HEAPSIZE=512 |
| NodeManager进程 | 512 MB | YARN_NODEMANAGER_HEAPSIZE=512 |
| 系统缓存及其他 | 200--300 MB | 文件系统缓存等 |
| 剩余给YARN Container | 约300--400 MB | 必须将Container内存限定在此范围 |
默认的 yarn.scheduler.minimum-allocation-mb=1024 会直接导致资源无法分配,需要调整。
2.2 集群全局配置
2.2.1 更新配置文件内容
以下配置在所有节点的相应XML文件中生效,建议先在master节点更新文件,后同步到其他节点。
(1)yarn-site.xml
bash
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>standby:9868</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>256</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>3</value>
</property>
</configuration>(2)mapred-site.xml
bash
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 使用 YARN 作为 MapReduce 框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- ApplicationMaster 内存 -->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>384</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx256m</value>
</property>
<!-- Hadoop 环境变量(解决 MRAppMaster 找不到类) -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<!-- Map Task 内存 -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>384</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx256m</value>
</property>
<!-- Reduce Task 内存(Map-only 作业用不到,但配置了无害) -->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>384</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx256m</value>
</property>
<!-- 排序缓冲 -->
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>64</value>
</property>
<!-- 关闭推测执行 -->
<property>
<name>mapreduce.map.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>false</value>
</property>
</configuration>(3)hdfs-site.xml(可选)
bash
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>standby:9868</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>256</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>3</value>
</property>
</configuration>2.2.2 同步配置
(1)使用命令同步配置文件:
bash
# 同步所有配置
for host in worker1 worker2 worker3 standby; do
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml $host:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml $host:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $host:$HADOOP_HOME/etc/hadoop/
done同步完成后,需要重启yarn:
bash
stop-yarn.sh
start-yarn.sh或者
bash
stop-yarn.sh && start-yarn.sh且重启后再次使用命令查看节点在线情况(对照"1.2.1 YARN 节点注册检查"):
bash
yarn node -list(2)配置文件核对要点:
- 严禁出现重复的
<?xml?>声明或多个<configuration>块,否则解析器行为不可预测。 - 修改配置使用
cat >命令完整覆盖文件,避免 vim 追加导致重复。 - 修改后必须同步到所有节点并重启受影响服务。
2.3 作业资源适配分析
- 输入分片:1.07GB → 9个Block → 9个Map Task。
- 任务特性:纯过滤,Reducer数量设为0。作业代码中必须强制指定0 Reducer:
java
job.setNumReduceTasks(0);- 单Container:384MB物理内存,256MB JVM堆,处理逐行文本绰绰有余。
- 最大并发:每 Worker 可运行 2 个 Container(2 × 384 = 768MB < 1024MB),3 个 Worker 共 6 个 Map 可并行,剩余 4 个排队分批执行。
3. 数据质量校验规则
CSV第一行为表头,从第二行开始逐行检查。采用"短路"策略,每条记录仅报告第一个命中的违规规则。
| 规则ID | 检查项 | 判定逻辑 | 异常标签 |
|---|---|---|---|
| R1 | 字段数量 | 逗号分隔后必须为22列 | COLUMN_COUNT_MISMATCH |
| R2 | 站点ID | 非空,仅含字母、数字、下划线 | INVALID_STATION |
| R3 | 日期格式 | yyyy-mm-dd且为合法日期 |
INVALID_DATE |
| R4 | 数值字段 | 第5列及之后所有气象指标可解析为数字 | NON_NUMERIC_VALUE |
| R5 | 降水量范围 | PRECTOT(第6列)≥ 0 |
PRECTOT_NEGATIVE |
| R6 | 温度范围 | T2M(第9列)在 -50~50℃ 之间 |
T2M_OUTLIER |
| R7 | 风速范围 | WS10M(第17列)在 0~100 m/s |
WS10M_OUTLIER |
【注】
(1)R5--R7的阈值基于地理常识,可在代码中修改以适应不同的业务约束。
(2)R2 规则在本阶段使用 [A-Za-z0-9_]+,首次运行后将被发现与真实数据特征不匹配,将在 实验A2-2 阶段修正。
4. 代码实现
(Java版)基于MultipleOutputs的Map-only作业
4.1 选择MultipleOutputs的理由
需求是一次读取、两路输出(cleaned和rejected)。若采用"Mapper打标签→Reducer分流"将引入不必要的Shuffle和Reduce阶段,在2GB内存下极易OOM。MultipleOutputs让作业保持Map-only,单次扫描即可将记录写入不同命名输出,无网络传输开销,且输出目录结构清晰,方便后续Hive直接消费。
4.2 Mapper关键API:setup / map / cleanup
Mapper类的三个核心方法由框架按固定顺序调用,第一次接触简单了解即可:
setup(Context context):每个Map Task初始化时执行一次,适合一次性资源分配,如创建MultipleOutputs对象。map(LongWritable key, Text value, Context context):对输入分片中的每一行调用一次,核心业务逻辑写在此处。cleanup(Context context):Map Task结束时执行一次,用于释放资源,必须在此关闭MultipleOutputs,否则输出文件可能不完整。
4.3 完整代码
(1)DroughtClean.java (Driver,包名:com.lab.a2)
【注】可以根据需要调整入参判定逻辑。
java
package com.lab.a2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class DroughtClean {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: DroughtClean <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Drought Data Cleaning");
job.setJarByClass(DroughtClean.class);
job.setMapperClass(CleanMapper.class);
job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
MultipleOutputs.addNamedOutput(job, "cleaned",
TextOutputFormat.class, Text.class, Text.class);
MultipleOutputs.addNamedOutput(job, "rejected",
TextOutputFormat.class, Text.class, Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}(2)CleanMapper.java (Mapper,包名:com.lab.a2)
java
package com.lab.a2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import java.io.IOException;
import java.text.SimpleDateFormat;
public class CleanMapper extends Mapper<LongWritable, Text, Text, Text> {
private MultipleOutputs<Text, Text> mos;
private static final int COL_STATION = 0;
private static final int COL_DATE = 1;
private static final int COL_PRECTOT = 5;
private static final int COL_T2M = 8;
private static final int COL_WS10M = 16;
private static final SimpleDateFormat DATE_FORMAT = new SimpleDateFormat("yyyy-MM-dd");
@Override
protected void setup(Context context) throws IOException, InterruptedException {
mos = new MultipleOutputs<>(context);
DATE_FORMAT.setLenient(false);
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
if (line.startsWith("station")) return;
String[] fields = line.split(",");
String reason = null;
if (fields.length != 22) {
reason = "COLUMN_COUNT_MISMATCH:" + fields.length;
}
else if (!fields[COL_STATION].matches("[A-Za-z0-9_]+")) {
reason = "INVALID_STATION";
}
else if (!isValidDate(fields[COL_DATE])) {
reason = "INVALID_DATE";
}
else if (!areMetricsNumeric(fields)) {
reason = "NON_NUMERIC_VALUE";
}
else if (Double.parseDouble(fields[COL_PRECTOT]) < 0) {
reason = "PRECTOT_NEGATIVE";
}
else if (Math.abs(Double.parseDouble(fields[COL_T2M])) > 50) {
reason = "T2M_OUTLIER";
}
else if (Double.parseDouble(fields[COL_WS10M]) < 0 ||
Double.parseDouble(fields[COL_WS10M]) > 100) {
reason = "WS10M_OUTLIER";
}
if (reason != null) {
mos.write("rejected", new Text(line), new Text(reason));
} else {
mos.write("cleaned", new Text(line), new Text("OK"));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
mos.close();
}
private boolean isValidDate(String dateStr) {
try {
DATE_FORMAT.parse(dateStr);
return true;
} catch (Exception e) {
return false;
}
}
private boolean areMetricsNumeric(String[] fields) {
for (int i = 4; i < fields.length; i++) {
try {
Double.parseDouble(fields[i]);
} catch (NumberFormatException e) {
return false;
}
}
return true;
}
}5 本地开发环境配置(Windows + IDEA + Maven)
当前Hadoop3需要适配JDK8,但很多朋友的版本是高于需求的,不适配(譬如当前系统已安装 Java 25),需要做如下调整。
5.1 安装 Eclipse Temurin JDK 8
- 访问 Adoptium 官网,这是官方认可的JDK适配第三方。
- 选择 Temurin 8 (LTS) ,操作系统 Windows ,架构 x64 ,下载
.msi安装包。 - 运行安装程序,保持默认路径。不要勾选"将 Java 添加到系统 PATH",避免覆盖系统默认 JDK。
5.2 IDEA 配置
调整编译和打包配置:
(1)File → Project Structure → Project:SDK 选择 JDK 8,Language level 设为 8 。
(2)File → Settings → Maven → Runner:JRE 选择 Use Project JDK 。
(3)File → Settings → Java Compiler:Project bytecode version 设为 8。
5.3 项目结构与 pom.xml
bash
MyHadoopA/
├── pom.xml
└── src/main/java/com/lab/a2/
├── DroughtClean.java
└── CleanMapper.java对应pom文件内容:
xml
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.lab</groupId>
<artifactId>drought-mr</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.3.6</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<manifest>
<mainClass>com.lab.a2.DroughtClean</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>【注意 】<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 不可或缺,否则含中文字符的源码会被 Maven 以 GBK 编码编译而报错。
5.4 编译打包
(1)Maven打包 :使用 IDEA 右侧 Maven 面板,依次双击 clean → package。生成的 jar 包位于 target/drought-mr-1.0.jar;此方式强制使用项目指定的 JDK 8。
(2)验证字节码版本 :在 IDEA 中打开 target/classes/com/lab/a2/DroughtClean.class,IDE 状态栏会显示"Java 8"。
6. 作业提交
6.1 命令说明
jar 包 pom.xml 中已配置 Main-Class,命令行中不应再出现主类名 ,否则会被 Hadoop 误当作参数传入,导致 Usage 提示。
bash
# 正确命令
hadoop jar drought-mr-1.0.jar /drought/raw/test_set.csv /drought/output_a2也可以尝试如下命令(调整Driver中参数检测逻辑后):
powershell
# 如需显式覆盖内存参数(全局配置已生效时无需)
hadoop jar drought-mr-1.0.jar \
-D mapreduce.map.memory.mb=384 \
-D mapreduce.map.java.opts=-Xmx256m \
-D mapreduce.job.reduces=0 \
/drought/raw/test_set.csv \
/drought/output_a2建议在每次执行前,先删除HDFS上已存在的输出目录:
bash
hdfs dfs -rm -r /drought/output_a26.2 运行日志关键节点说明
控制台中输出信息很多,建议运行成功后(SUCCESS字样)抛给AI快速学习解读这些信息,能够学到更多知识,此处仅给出关键要点方便核对运行情况:
bash
Submitted application application_xxx #提交作业ID
Running job: job_xxx
map 0% reduce 0%
map 10% → 25% → 50% → 74% → 90% → 100% #运行进度
Job job_xxx completed successfully以下关键信息仅供参考:
- Launched map tasks: 10
- Map input records: 9,218,701
- Map output records: 0(因使用 MultipleOutputs,不走传统计数!)
此外请自行查看WebUI(譬如我的查询地址:http://192.168.10.101:8088),监控任务提交后的运行情况,但如果内存比较吃紧的话,谨慎操作;个人建议有条件的话,应该点开页面上的各种按钮,能学到很多新知识,特别是log的解读;我们这个教程属于短平快类,加上AI能够辅助解读,所以就不做深入讨论了,充分留白嘛。
7. 首次运行结果与数据质量探查
7.1 输出文件结构
按照之前提交作业的命令设定,查看HDFS上的输出目录
bash
hdfs dfs -ls /drought/output_a2实际输出目录包含三类文件:
_SUCCESS:作业成功标记cleaned-m-00000 ~ cleaned-m-00009:清洗后的合规数据rejected-m-00000 ~ rejected-m-00009:被拒数据(含拒绝原因)part-m-00000 ~ part-m-00009:框架默认输出(大小为 0,符合预期)
7.2 行数统计(单个 Map 输出文件示例)
执行如下命令,可以统计两种清洗结果文件数据信息:
powershell
hdfs dfs -cat /drought/output_a2/cleaned-m-00000 | wc -l # 485,481
hdfs dfs -cat /drought/output_a2/rejected-m-00000 | wc -l # 492,570【实际观察到的现象】 :cleaned 和 rejected 文件大小几乎对称,脏数据比例异常偏高。
【反思】 如何解释这个不太理想的数据清洗结果:难道这种真实的官方数据质量那么差吗?是数据本身的问题?还是咱们的清洗策略有问题?回想之前清洗程序对失效数据做了分类标记,使用如下命令查看统计情况:
bash
hdfs dfs -cat /drought/output_a2/rejected-m-* | awk -F'\t' '{print $2}' | sort | uniq -c | sort -nr实际输出结果:
bash
4616190 INVALID_STATION打开原始数据文件,观察后可以确认:数据集中站点 ID 为带负号的长整数(如 -6912263433155848174),而规则 R2 使用的正则 [A-Za-z0-9_]+ 不允许负号,导致约 50% 数据被拒。但需要意识到:本质上这并不是程序错误,而是数据质量评估的积极成果,因为它揭示了规则与真实数据特征的冲突,为下一阶段迭代指明了方向,这也是为何数据清洗过程被拆分成两个实验项目(A2-1、A2-2)的原因。只有真的实践了,才能认识到给AI算法模型准备原料这份工作的重要性,因此更不能否认大数据技术/大数据分析之前的知识累积在AI时代仍具有较高的价值,毕竟"挖石油"的工作虽然辛苦,却是十分有意义。
前这个筛选结果可以认为是实际应用场景中,数据清洗要面对的真实情况:
(1)清洗规则是过滤器,不是修正工具 。 之前编写各种规则,只会对每行数据做"通过"或"不通过"的判断,不会去改数据本身。通过的打上 OK 标签进 cleaned,不通过的则标记具体原因,归到 rejected。
(2)真实数据到处是坑 。 test_set.csv 是个 1.07GB 的真实气象数据集。一旦程序扫出大量脏数据,基本就说明实际数据质量比预想的差得多。比如:
1)字段缺失:很多观测站可能根本没记录风速(WS10M)或温度(T2M),数值校验必然失败。
2)格式不统一:日期存在多种写法,导致 isValidDate 这类规则直接失效。
3)异常值出现:传感器一抽风,温度或风速就可能远超所设定的 -50, 50 或 0, 100 这些物理合理范围。
(3)逐字段"一票否决"有待商榷。 代码里用的是 if-else if 短路判断,只要一个字段踩中规则,整行立刻被扔进 rejected,同时附上诊断信息。
**【重要推论】**在实际数据清洗作业中,我们不要妄图一轮操作就能拿到预期的质量合格的数据集,这个过程实际上需要多次、多轮的尝试,期间还要参考一些抽样方法做数据状态预检测,万不能瞧不上这个关键步骤哦!
8. 在实验过程中常见问题与排查记录
| 现象 | 根因 | 解决 |
|---|---|---|
yarn node -list 显示 Total Nodes:0 |
yarn-site.xml 未配置 yarn.resourcemanager.hostname |
添加 yarn.resourcemanager.hostname=master |
| 作业提交后立刻失败:MRAppMaster 找不到 | 未配置 AM 环境变量 | 在 mapred-site.xml 中配置 yarn.app.mapreduce.am.env |
| 作业卡在 PREP 状态 | 默认 AM 请求 1536MB,超过最大分配 | 配置 yarn.app.mapreduce.am.resource.mb=384 |
所有 Map 任务失败:InvalidAuxServiceException |
未配置 shuffle 辅助服务 | 在 yarn-site.xml 中添加 yarn.nodemanager.aux-services |
| WebUI 显示 Worker 内存仍为 1.5GB | 配置文件内容重复,解析器仅读取旧值 | 用 cat > 完整覆盖文件 |
参数个数报 Usage |
jar 包 Main-Class 与命令行类名冲突 |
去掉命令行中的类名 |
| 打包时"编码 GBK 不可映射字符" | 缺少 UTF-8 编译参数 | pom.xml 添加 project.build.sourceEncoding=UTF-8 |
| 物理机卡死 | 16GB 总内存被 5 台 VM 占满 | 关闭非必要应用 |
9. 实验A2-1总结
(1) 集群配置是系统工程 :RM 地址、AM 内存、Shuffle 服务、环境变量等缺一不可,任一遗漏都会导致作业失败。
(2) jps 不可靠 :进程存在不等于服务可用,必须通过 yarn node -list、WebUI 和实际作业测试验证集群完整性。
(3)低内存环境需严格管控 :yarn.nodemanager.resource.memory-mb 设为 1024MB,为 OS 保留约 700MB,确保不触发 OOM。
(4)数据清洗是迭代过程 :规则不能一成不变,必须与真实数据对话。A2-1 的探查结果为 A2-2 的策略修正提供了明确方向。
与 A2-2 的衔接和任务预告
A2-2 将基于本阶段的探查结果,实施以下工作:
- 修正 R2 规则(将正则调整为
-?[0-9]+)。 - 重新打包运行,验证修正后的清洗效果。
- 实现 Python Hadoop Streaming 版本。
- 对比 Java 与 Python 方案的性能与资源消耗。