3121
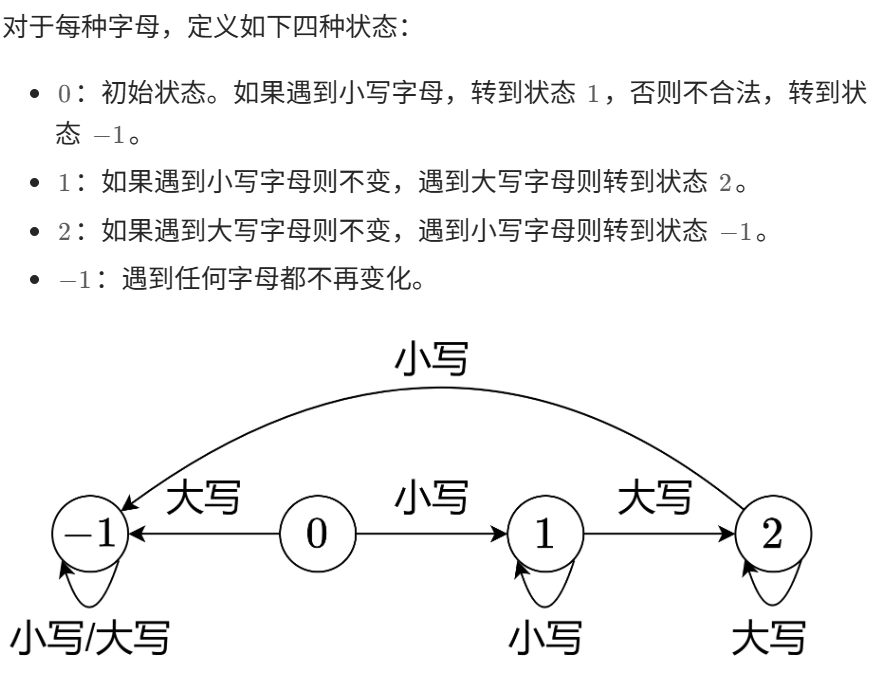
比昨天简单,一个数组就行,都不用哈希表
这个数组专门统计小写字母是否出现,出现时就打1
遇到小写字母时,先看对应位置上是不是0,如果是0就打为1,否则直接过
遇到大写字母时,看对应位置上是不是1,如果是1,就改写为2,并计数++,否则直接过
class Solution {
public:
int numberOfSpecialChars(string word) {
vector<int>flag(26,0);
int res=0;
for(int i=0;i<word.size();i++){
if(word[i]>='a'&&word[i]<='z'){
if(flag[word[i]-'a']==0){
flag[word[i]-'a']=1;
}
else if(flag[word[i]-'a']==2){
res--;
flag[word[i]-'a']=3;
}
continue;
}
if(word[i]>='A'&&word[i]<='Z'){
if(flag[word[i]-'A']==1){
flag[word[i]-'A']=2;
res++;
}
else if(flag[word[i]-'A']==0){
flag[word[i]-'A']=-1;
}
continue;
}
}
return res;
}
};看漏了,应该是所有小写字母都要出现在大写字母之前
发现这个题本质是个状态机,或者说我现在想的,就是状态机的想法,1234就是对应的状态

2569
这个相当于是要维护两个线段树,对nums1要维护一个,然后对nums2也是
对nums1就是维护加和就行,lazy标识最后是否反转
对nums2,是要查询一次nums1的所有区间和,然后每个其中的元素都要加上nums1*p
那也就是说nums2一开始算一下自己的和,之后每次op2,都是在原来的基础上加一个查询结果*长度即可
nums2就直接返回行了
就一个线段树,简单
LLM
就是说原来的输入,通过分词拆成一个一个的token,这里直接就变成数字了吗?如果是的话,那由原来各种各样的输入(比如包含中文、英文、数字以及各类特殊字符)是怎么知道要变成怎样的数字?以及对于不同的请求,相同的输入所变成的数字是否一样?然后再对每个token进行一个嵌入,即embedding,这里嵌入是在做什么?因为之前以为是在嵌入时才会把各类输入变成数字,那如果在Tokenize时就已经做了,那这里嵌入是要做什么?看上面的例子是变成了vec_hello,这个是什么意思?然后说进行了一次公式计算,得到了注意力分数,这个应该就是模型内部所在做的事情,然后输出一个概率分布,这个应该就是所有可能输出的token的概率分布?还要再乘V?V是什么?为什么要再乘V?再过FFN?这又是什么?什么叫下一层Transformer?那如果说有很多层Transformer,那最后输出时,怎么知道值是多少?以及,对于每个Token,就是传入模型的输入vec_hello,是一次就经过所有的transformer层,还是所先所有的Token都经历一遍一层transformer后,再统一一起走?

那embedding层将Token ID转换成高维语义向量的这个过程,是模型负责的,还是推理框架负责的?以及对于相同的Token Id,看意思是说可能会转换出不同的语义向量吗?

我现在知道了原始输入经过tokenizer变成token Id,再经过embedding变成语义向量,之后就是直接和WQ,WK,WV做运算得到注意力,最后得到一个输出后,再乘一个WV是吗?然后最后再映射到实际的Token ID,再查一次表得到最后的输出;那推理框架都做了什么?
请求调度是什么意思?prompt是原始输入吗?如果说是比赛要求的单计算卡,这个Continuous Batching还能执行吗?就是这个机制是什么意思?排序prompt请求也能提高效率吗?以及说"每个 token 生成后立即判断能否插入新请求"是什么意思?难带模型还能同时处理多个输入吗,即我先问"Hello",在等待模型返回"hello"的响应时,还能继续输入"你好",然后模型能同时计算这两个输入的输出吗?prompt的prefill是什么意思?
"Kernel 调度:Attention、Linear、LayerNorm 等算子如何排布、是否融合"这个kernel是指什么?你说的这些算子,不是模型在负责计算的吗?推理框架负责计算吗?如果负责计算,主要是计算了什么?
在Prefill时,说一次喂入5个token。然后Transformer走完所有层,这个tanrsormer走完所有层的过程,是发生在模型里,还是发生在推理框架里?token的K和V,是在进transformer前产生但还是出来后产生的?
对于Decode,prefill不是直接把所有输入的token给到transformer吗?那模型输出不该是针对这个prompt的所有输出吗?那decode说每次只喂入一个新Token,这个新token是什么意思?来自于哪里?是模型生成的token吗?那模型生成的,不是直接所有的输出token?

既然kernel融合能减少读写显存的次数,那为什么不直接针对每个可能的请求,预制好所有的计算路径,然后把他们打包进一个kernel当中?
意思就是说prefill根据prompt的所有token,调用一次模型计算出一个logits,即所有输出的可能概率后,经过采样(这里采样不就是选logits里的最大值吗?还有别的方法吗?)从logits中选出一个token作为decode阶段的输入;之后decode先是根据prefill产生的第一个token,调用模型计算出返回时衔接在它后面的下一个token,之后就是不断以decode刚产生的那个token作为输出,不断调用模型来进行计算,产生输出token;比如输入prompt有100个token,输出假设有50个token,在prefill时,先是根据输入prompt的100个token,产生输出的第一个token,这里调用了1次模型计算,之后decode就是依据prefill产生的第一个Token,不断调用模型,调用49次模型,产生后续输出的剩余49个Token,对吗?
2589
看样子是要寻找所有的区间,最终能重叠到多短
这样,对每个区间,处理思路都是先看是否有和别的区间重合的部分,如果存在,那就是优先填满那些重合最多的部分,直到自己的任务时间处理完;这里在填补的时候,也要同步修改重叠的那些任务
这样的话数据结构可能会很复杂
如果直接搜索答案,二分验证?验证感觉也不是很好验证,怎么做?
思路是什么?
针对每个时间做标记
贪心策略:将所有任务按着开始时间从小到大去排序
然后去数自己所在的那个区间里有多少个时间是工作的,如果满足了自己的要求,就直接过
否则自后向前标记时间为工作的
错误,不是按照任务开始时间去排序,而是按照任务结束时间去排序
否则
在这个操作当中,要频繁地去查询开始和结束区间里ti为true的数量
以及当cnt不够时,与duration的差值,要从最后去更新ti
如果说是维护一个线段树的话,查询操作没问题,但是要更新时,如何实现这个从后往前更新的偏向更新?

确实是不需要懒标记的,因为每次修改,都可能是从后向前针对到点上的修改,所以就不需要懒标记;需要懒标记的是那种一下子更新、修改整个区间的

这里需要注意的就是先右递归,这样就能保证每次修改都是从最右侧开始的;以及用的是引用


线段树提升了点时间,但内存占用翻了个倍,时间提升也没那么巨大
P1352 没有上司的舞会
dp定义为选这个点时所能达到的最大快乐值
选了当前这个点后,那么它的所有孩子都不可选,可选的是孩子的孩子,又或者是孩子的孩子的孩子,即把树上奇偶点都考虑到
那么对于每个点的DP
dpcur=max(dpcur的孩子的孩子,dpcur的孩子的孩子的孩子)+r
不过对于不相邻的孩子,他们那一层应该是可以都选的?
那就是说对当前节点上的每个延申下去的分支,都对孩子的孩子,和孩子的孩子的孩子取一次Max
即dpcur=rcur
for当前的节点的所有分支
dpcur+=max(dp此处分支孩子的孩子,dp此处分支孩子的孩子的孩子)
要初始化,就从叶子节点开始,叶子节点上一层和叶子节点那层的dp值,都是自己的r
从底向上第三层后,就是先判断每个分支的孩子的孩子与孩子的孩子是否存在

那就是dpi表示当前节点所能取得的最大收益,存两个状态,就是选当前节点以及不选当前节点
那么dpi1=sum(dp孩子0)+numi
dpi0=sum(dp孩子1)+numi
对于孩子,也不一定就是一定要选,因为孙子可能值更大,比如
小小大的排序时,当前就不能要孩子而是要孙子,至于为什么不要当前这个节点,就是可能有序列
大小小大,所以父亲节点选择,当前就不能选择,但是孙子节点很大,所以也不选择孩子,而是等孙子
所以dpi0,1的设计就能包括各种排序序列
那就是先建树,然后后序遍历,如果是叶子节点
就是保存自己的孩子节点,如果没有的话,就说明自己是叶子节点
不过怎么知道树的根节点是哪个,以这种方式存的话?