线程池里的任务为啥不会乱序?核心是阻塞队列在"排队"
生产环境用 LinkedBlockingQueue 为啥老 OOM?90% 的人没指定容量
ArrayBlockingQueue 和 SynchronousQueue 谁的吞吐量更高?
面试被问线程池底层时,BlockingQueue 绝对是绕不开的核心!它就像线程池的"任务缓冲站",解决了生产者和消费者的速度匹配难题,更是 JUC 并发包的经典设计。
今天这篇文章,不讲废话,只讲面试高频考点:用通俗类比 + 源码拆解 + 实战选型,30 分钟吃透 BlockingQueue 全家桶,看完直接能背会用!
一、先搞懂:BlockingQueue 到底是个啥?(大白话版)
咱们用生活场景类比:
- 生产者 = 餐厅后厨做菜的厨师
- 消费者 = 前台取餐的服务员
- BlockingQueue = 出餐口的餐架
👉 核心逻辑:
- 餐架摆满(队列满):厨师只能等着,直到有服务员取走菜品(阻塞生产者)
- 餐架空了(队列空):服务员只能等着,直到厨师做好菜品(阻塞消费者)
底层原理超简单:基于 AQS 的 Condition 条件队列实现等待与唤醒,不用手动处理线程同步,JUC 已经帮我们封装好了!
必背核心方法(面试直接默写)
| 行为 | 抛出异常 | 返回布尔值 | 阻塞等待 | 超时退出 |
|---|---|---|---|---|
| 入队 | add(e) |
offer(e) |
put(e) |
offer(e, timeout) |
| 出队 | remove() |
poll() |
take() |
poll(timeout) |
| 查看 | element() |
peek() |
--- | --- |
💡 面试考点 :put/take 是阻塞方法,offer/poll 是非阻塞方法,实际开发中优先用阻塞方法(避免空轮询)
二、三大核心实现:源码拆解 + 核心特性(面试重点)
1. ArrayBlockingQueue:有界数组队列(稳定安全首选)
底层结构 :基于固定容量的数组实现,创建时必须指定容量(比如 new ArrayBlockingQueue(9))
java
public class ArrayBlockingQueue<E> {
final Object[] items; // 存储元素的数组(固定大小)
final ReentrantLock lock; // 独占锁:入队出队共用一把锁
private final Condition notEmpty; // 队列非空条件(唤醒消费者)
private final Condition notFull; // 队列非满条件(唤醒生产者)
}✅ 核心优点:
- 有界队列,不会无限扩容,无 OOM 风险(生产环境首选)
- 结构简单,性能稳定,适合生产消费速度均衡的场景
❌ 注意点:
- 读写共用一把锁,高并发下吞吐量一般
- 支持公平/非公平锁(默认非公平,公平锁性能更低)
2. LinkedBlockingQueue:链表队列(高吞吐但需谨慎)
底层结构 :基于单向链表实现,可指定容量(有界)或不指定(无界,默认 Integer.MAX_VALUE)
java
public class LinkedBlockingQueue<E> {
private final int capacity; // 容量(不指定则为无界)
private final AtomicInteger count; // 元素计数(原子类保证线程安全)
private final ReentrantLock takeLock; // 出队锁(独立)
private final ReentrantLock putLock; // 入队锁(独立)
}✅ 核心优点:
- 读写锁分离,生产者和消费者不互斥,并发吞吐量远超
ArrayBlockingQueue - 链表结构,插入删除效率高
❌ 致命坑点(面试必问):
- 不指定容量时为无界队列,若生产速度 > 消费速度,队列会无限膨胀,最终 OOM
Executors.newFixedThreadPool默认用它(无界),生产环境严禁直接用!
3. SynchronousQueue:同步队列(无存储高吞吐)
底层结构:内部不存储任何元素,相当于"直接手递手"传递任务
java
public class SynchronousQueue<E> {
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
}✅ 核心优点:
- 容量为 0,无存储开销,吞吐量极高
- 每一个
put操作必须等待take操作,适合任务处理速度极快的场景
❌ 注意点:
- 无缓冲,若没有消费者,生产者会一直阻塞
Executors.newCachedThreadPool默认用它,高并发下易创建过多线程
三、源码核心逻辑:以 put/take 方法为例(面试拆解)
以 ArrayBlockingQueue 为例,看懂这两个方法,就懂了所有阻塞队列的核心逻辑:
1. put 方法(阻塞入队)
java
public void put(E e) throws InterruptedException {
lock.lockInterruptibly(); // 加锁(支持中断)
try {
// 队列满了,在 notFull 条件队列等待
while (count == items.length)
notFull.await();
enqueue(e); // 入队
} finally {
lock.unlock(); // 解锁
}
}
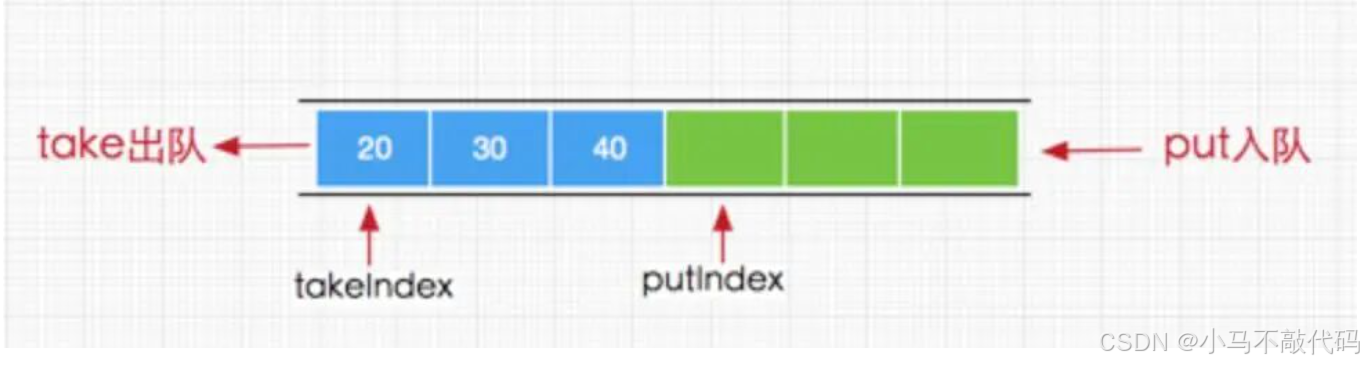
private void enqueue(E x) {
items[putIndex] = x;
putIndex = (putIndex + 1) % items.length; // 循环数组
count++;
notEmpty.signal(); // 唤醒等待的消费者
}2. take 方法(阻塞出队)
java
public E take() throws InterruptedException {
lock.lockInterruptibly(); // 加锁
try {
// 队列空了,在 notEmpty 条件队列等待
while (count == 0)
notEmpty.await();
return dequeue(); // 出队
} finally {
lock.unlock(); // 解锁
}
}
private E dequeue() {
E x = (E) items[takeIndex];
items[takeIndex] = null; // 清空元素
takeIndex = (takeIndex + 1) % items.length;
count--;
notFull.signal(); // 唤醒等待的生产者
return x;
}💡 核心逻辑闭环(面试必说):
- 生产者满等
notFull,消费者空等notEmpty - 生产成功唤醒消费者,消费成功唤醒生产者
- 全程基于 AQS Condition 实现,线程安全有保障
四、实战选型对比:生产环境怎么选?(直接抄)
| 特性 | ArrayBlockingQueue | LinkedBlockingQueue | SynchronousQueue |
|---|---|---|---|
| 结构 | 数组 | 单向链表 | 无存储 |
| 容量 | 必须指定(有界) | 可选(默认无界) | 0 |
| 锁机制 | 独占锁 | 读写分离锁 | 直接移交机制 |
| 吞吐量 | 一般 | 高 | 极高 |
| OOM 风险 | 无 | 无界时极高 | 无 |
| 线程池应用 | 手动指定核心池 | FixedThreadPool | CachedThreadPool |
| 适用场景 | 生产消费均衡 | 高并发(指定容量) | 任务轻量快速处理 |
生产环境避坑指南(重中之重)
- 严禁使用无界 LinkedBlockingQueue ,必须指定容量(比如
new LinkedBlockingQueue(1000)) - 高并发 + 任务轻量 →
SynchronousQueue(配合核心线程数动态调整) - 大多数场景优先选
ArrayBlockingQueue(稳定无风险) - 线程池队列选型公式:核心线程数 + 队列容量 = 系统能承载的最大并发
五、面试高频题:提前背会直接答
1. 为什么 ArrayBlockingQueue 不能扩容?
答:基于固定数组实现,设计初衷是"有界可控",避免扩容带来的性能开销和 OOM 风险。
2. LinkedBlockingQueue 的吞吐量为什么比 ArrayBlockingQueue 高?
答:读写分离锁,生产者和消费者可以同时操作,而 ArrayBlockingQueue 是独占锁,读写互斥。
3. SynchronousQueue 适合什么场景?为什么容量为 0?
答:适合任务处理速度极快的场景,容量为 0 是为了实现"直接传递",无存储开销,吞吐量最高。
4. 生产环境中,线程池的阻塞队列怎么设置容量?
答:根据业务峰值 QPS 和处理耗时计算,公式:容量 = 峰值 QPS × 平均处理耗时 - 核心线程数 。
程数