前言
在上一篇中我们讲解了二叉树的顺序存储结构,并基于完全二叉树的顺序存储原理,深入学习了堆的原理与代码实现:
https://blog.csdn.net/gumidc/article/details/160929011?spm=1011.2124.3001.6209
但顺序存储只适合完全二叉树、满二叉树,对于普通形态不规则的二叉树,会造成大量空间浪费。
因此接下来,我们学习一下二叉树链式结构的实现,通过节点链式存储的方式,我们可以表示任意形态的二叉树。
1.前置说明
在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。考虑到大家目前对二叉树结构掌握还不够深入,为了降低入门门槛,此处手动快速创建一棵简单的二叉树,让大家可以立刻上手,直观理解二叉树各类遍历逻辑。等大家把二叉树结构了解的差不多时,我们再回头讲解二叉树真正的创建方式。
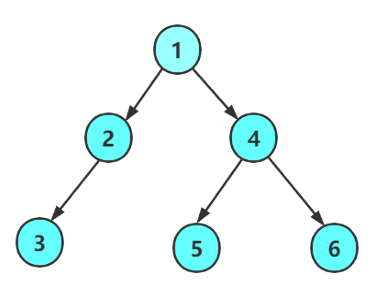
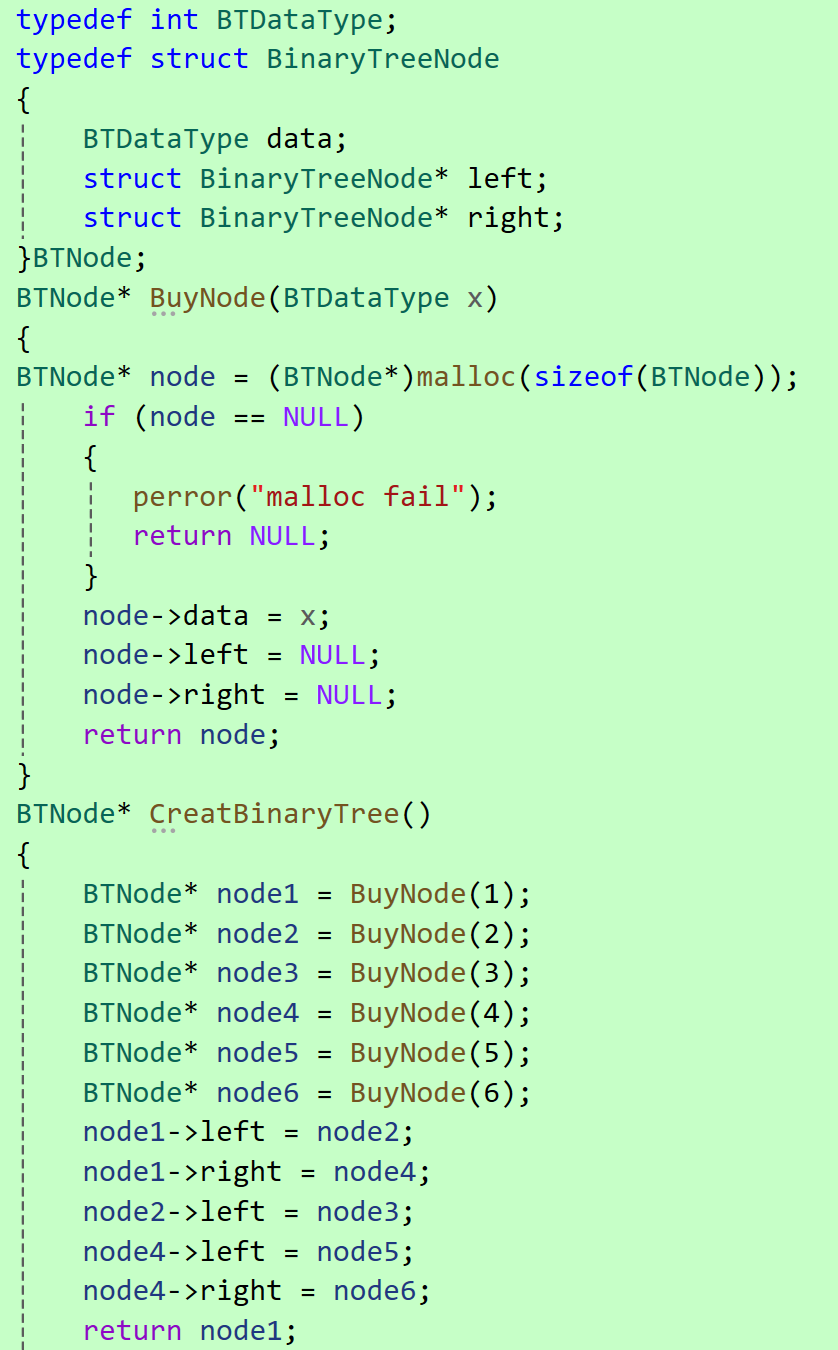
注意:上述代码并不是创建二叉树的方式,真正创建二叉树方式后续会重点讲解。
2.二叉树的遍历
二叉树最核心的基础操作就是遍历,根据对根节点的访问时机不同,分为三大递归遍历方式:
1. 前序遍历(Preorder Traversal )------访问根结点的操作发生在遍历其左右子树之前。
2. 中序遍历(Inorder Traversal)------访问根结点的操作发生在遍历其左右子树之间。
3. 后序遍历(Postorder Traversal)------访问根结点的操作发生在遍历其左右子树之后。
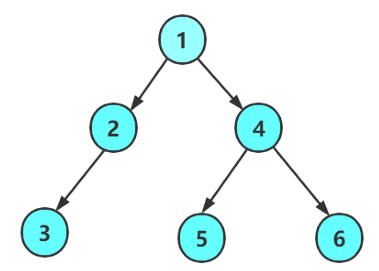
接下来以上面我们创建的二叉树为例,完整演示三种遍历的执行流程与最终访问顺序(N代表空节点):
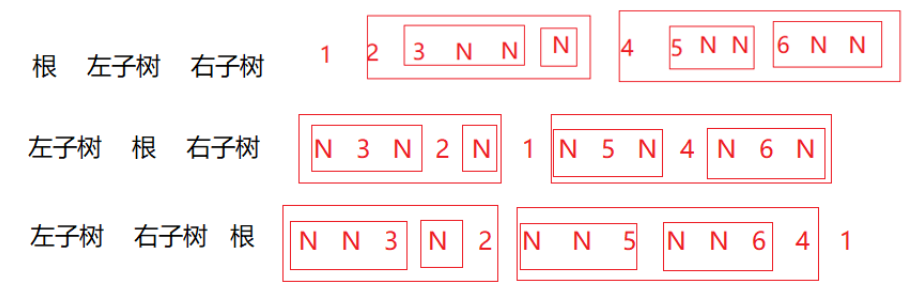
2.1 前序遍历(根 左 右)
遍历逻辑拆解:
1.先根:访问1
2.遍历左子树(以2为根):先根2 -> 左3(以3为根)-> 左空(N)-> 右空(N)-> 回退到2访问2的右子树(N)-> 回退到1
3.遍历右子树(以4为根):先根4 -> 左5(以5为根)-> 左空(N)-> 右空(N)-> 回退到4访问4的右子树6(以6为根)-> 左空(N)-> 右空(N)
代码实现:

接下来画一个代码调用过程的展开图,从逻辑上来进一步加深我们对于这个递归过程的理解,我画好了左子树的调用过程供参考,你可以试着画一画右子树:
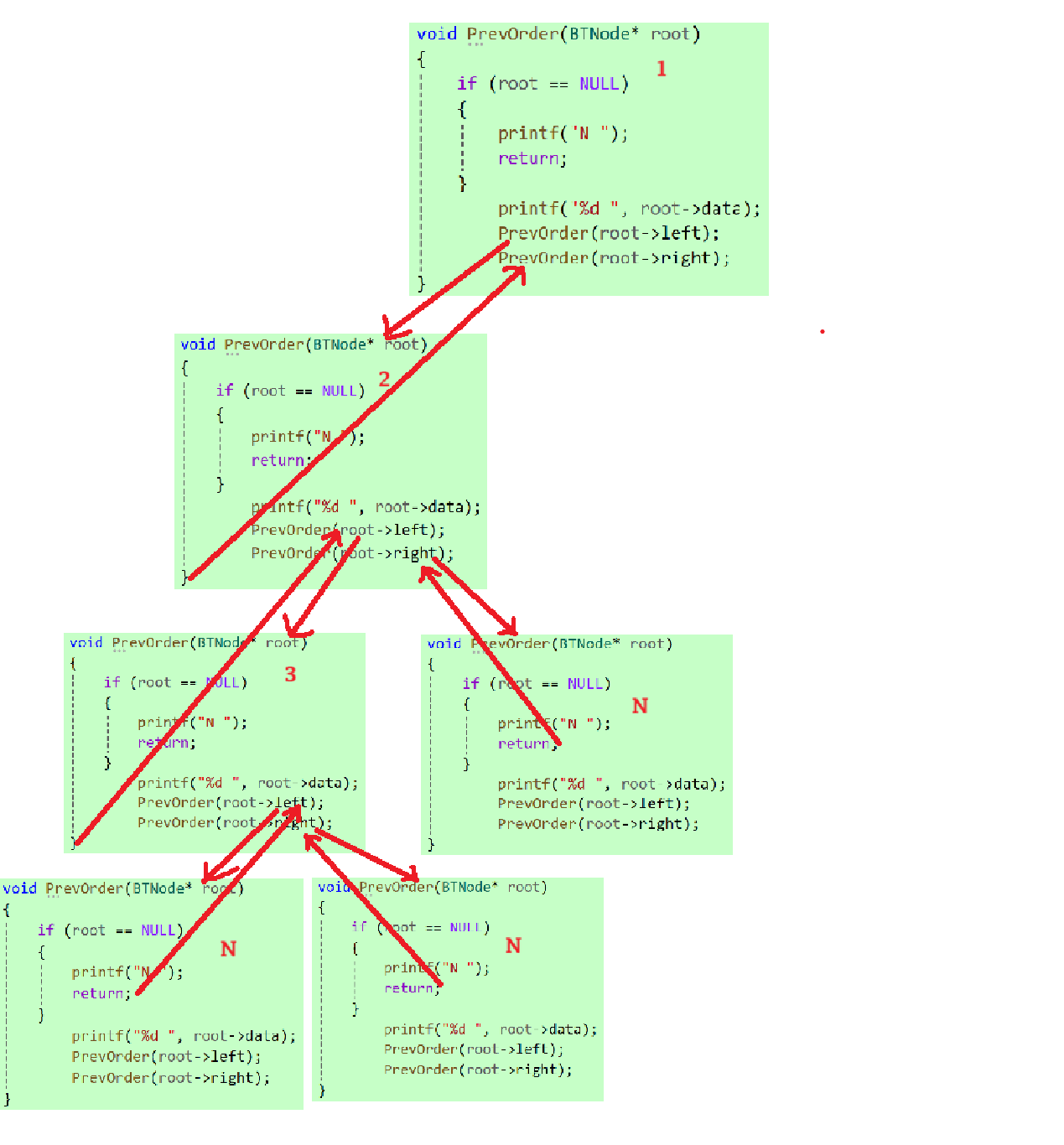
递归物理底层原理:
整个递归过程,本质是函数栈帧的反复创建、调用与销毁:
每次递归调用函数,都会在栈上开辟新的栈帧;函数执行结束后,栈帧随即销毁。
比如节点3的左子树调用、和右子树调用,复用的是同一块栈内存空间,并不会额外持续占用内存。
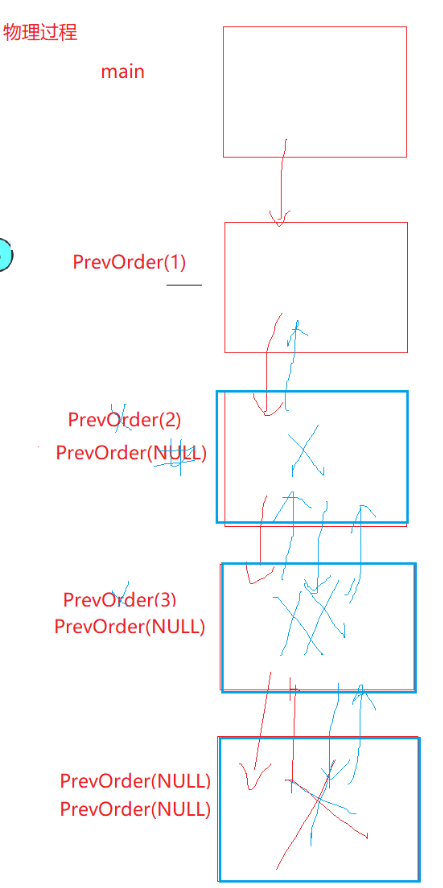
2.2 中序遍历(左 根 右)
遍历逻辑拆解:
1.左子树:左空(N)-> 根3 -> 右空(N) -> 根2 -> 2的右子树空(N)
- 访问总跟:1
3.右子树:左空(N)-> 根5 -> 右空(N)-> 根4 ->右6(以6为根)-> 左空(N)-> 右空(N)
代码实现:

2.3 后序遍历(左 右 根)
遍历逻辑拆解:
1.左子树:左空(N) -> 右空(N)-> 根3 -> 回退到2访问2的右子树(N)-> 根2
2.右子树:左空(N)-> 右空(N)-> 根5 -> 回退到4访问4的右子树6的左子树(N)-> 6的右子树(N)-> 根6 -> 根4
3.最后访问总根:1
代码实现:

2.4 二叉树基础递归练习
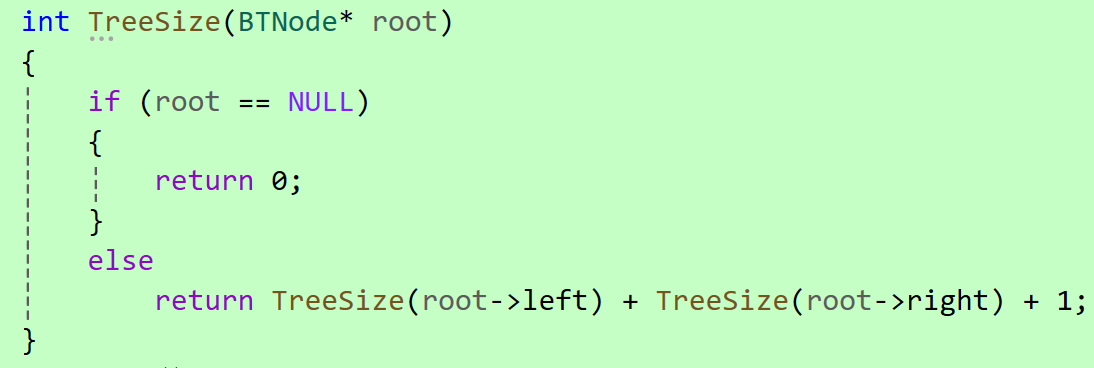
2.4.1 求二叉树的节点个数
思路一:运用前序遍历,节点不为空size就+1。

但是上述代码是存在问题的,如下图:

static修饰的局部变量,只会在程序启动时初始化一次,函数结束后数值不会清零销毁。
• 第一次调用统计:正确返回节点总数6
• 第二次重复调用:数值会在上一次结果基础上继续累加,错误输出12,和预期不符
想要解决size局部变量的特性,我们可以考虑使用全局变量:

但是这种写法也存在问题:全局变量size只会初始化一次,每次调用统计前必须在外层手动清零,代码维护性较差。
思路二:使用分治递归法,拆分问题:

代码实现:
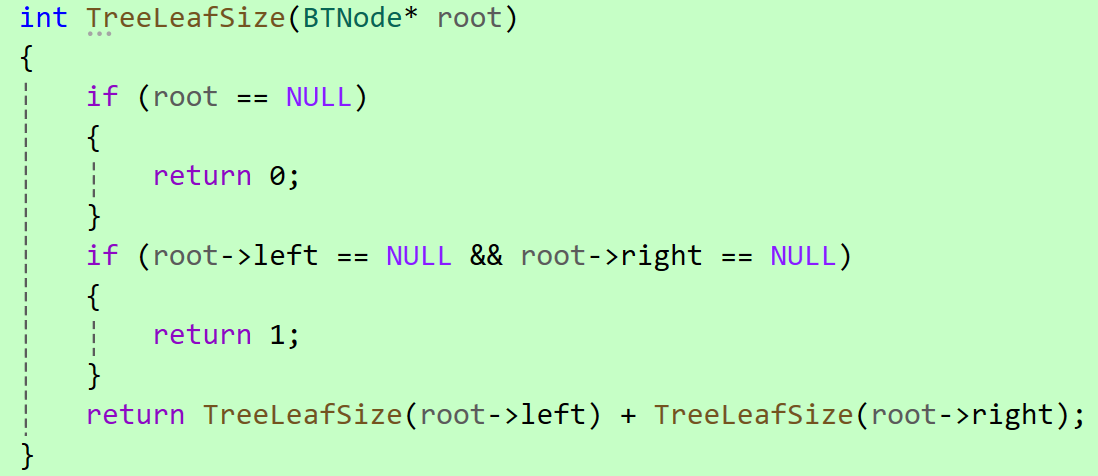
2.4.2 求二叉树叶子节点的个数
思路:使用分治递归法,拆分问题:

代码实现:
2.4.3 求二叉树的高度
思路:同上,二叉树的高度根据节点有无分为如下两种情况:

代码实现:

但是这样的写法在一些情况下会出现问题,接下来我们画一下简化递归调用图来理解为什么:
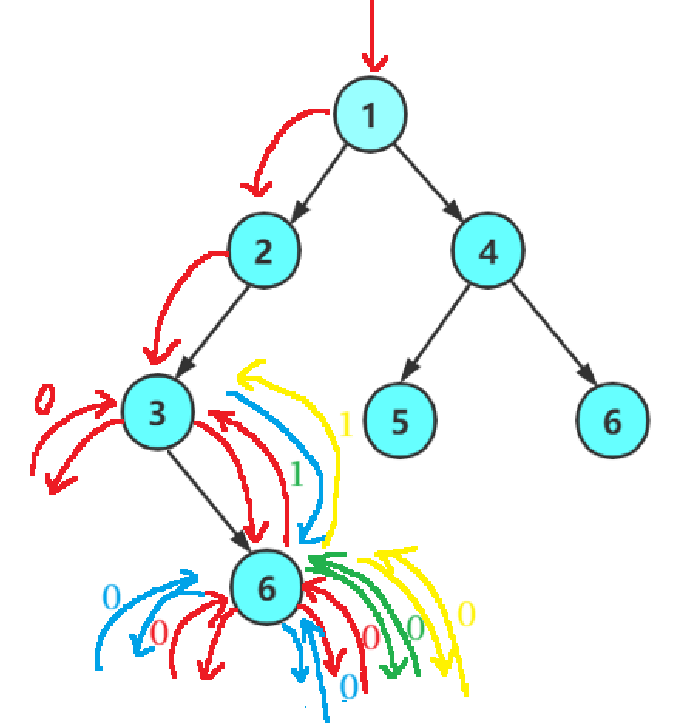
根据上图,递归先沿红色路径一路左探,节点3左子树为空返回0;递归继续走到节点6,先后算出左右子树全空,双双返回0。
节点6完成左右子树高度比较后,需要计算自身高度+1,但代码未缓存临时结果,只能重新递归右子树(绿色路径)。
结果返回节点3后,节点3判定右子树更高,同样的问题再次出现:之前算出的右子树高度丢失,节点3只能再次对右子树进行完整的递归(蓝色路径)。
连带底层的节点6,又被迫把全套递归流程跑一遍(黄色路径)。
向上回溯到节点2、节点1时,这个问题会逐层放大:每一层都遗忘下层已经算完的高度,每次比较结束后,都要把更高的子树完整重算一遍。
最终造成:大量节点被反复遍历,大树、深树场景下程序运行极慢,还极易栈溢出崩溃。
优化如下:
先提前计算,临时保存左右子树高度,全程每个节点仅遍历一次。

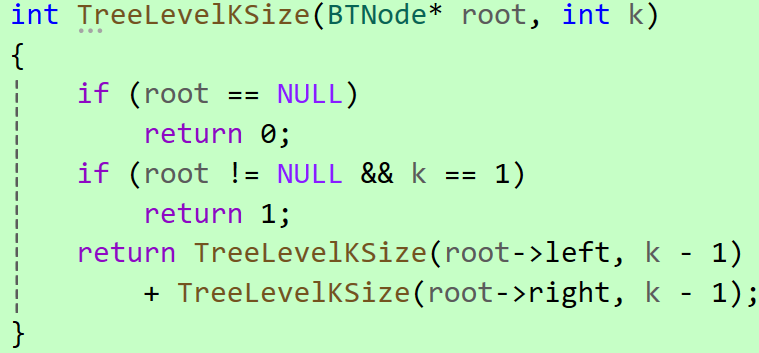
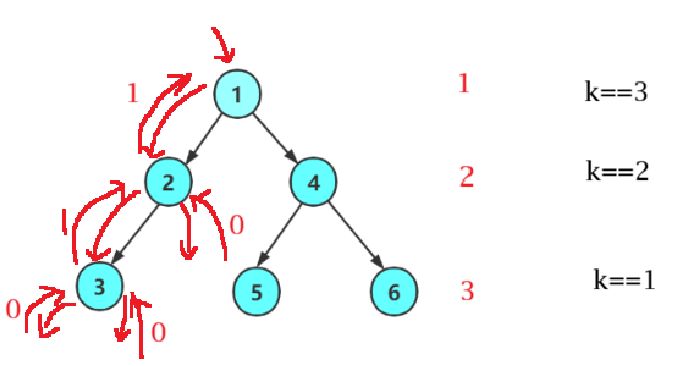
2.4.4 求二叉树第k层节点的个数
思路:使用分治递归法,拆分问题:

代码实现:
如下为该过程的简化递归调用图,我画好了左子树的调用过程供参考,你可以试着画一画右子树来加深理解:
2.4.5 二叉树查找值为x的结点
实现逻辑(前序遍历查找)
-
空树:直接返回NULL,查找失败
-
当前节点的值就是目标值:直接返回当前节点地址
-
先递归查找左子树,左子树找到就直接返回结果
-
左子树没找到,继续递归查找右子树
代码实现:

2.5 层序遍历
层序遍历是一种广度优先搜索(BFS) 策略。它要求我们按照"从上到下,从左到右"的顺序,逐层访问二叉树中的所有节点。
与之前的递归遍历(深度优先)不同,层序遍历的实现必须借助一个队列(Queue) 来辅助完成。
思路:
-
初始化:创建一个队列,并将二叉树的根节点入队。
-
循环遍历:当队列不为空时,重复以下步骤:
◦ 出队:将队首的节点取出。
◦ 访问:对取出的节点进行访问(如打印其值)。
◦ 入队:将该节点的左孩子和右孩子依次入队(如果孩子存在)。
- 结束:队列为空时,遍历完成。
创建队列部分的代码在这里不做赘述,不熟悉的同学可以再去回顾一下:
https://blog.csdn.net/gumidc/article/details/160866387?spm=1011.2124.3001.6209
参考代码如下:

2.5.1 判断二叉树是否是完全二叉树
思路:
1.层序遍历,即使遇到空节点也要将其入队。
-
遇到第一个空节点后,停止向队列中加入新节点
-
停止入队后,检查队列中剩余的所有元素:
◦ 如果队列中剩下的全是空节点,则这棵树是完全二叉树。
◦ 如果队列中还存在任何非空节点,则这棵树不是完全二叉树。
这个思路对于如下场景可行吗?
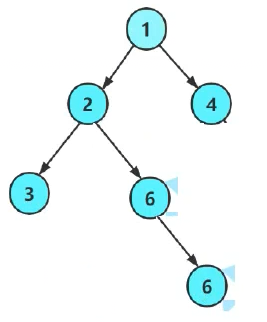
答案是可行的。因为当层序出到空时,如果前面非空都出完了,那么这些非空的子节点一定也进队列了。
参考代码如下:

3.二叉树基础OJ练习
理论学习后,我们通过经典的OJ题目来检验与巩固所学知识。
3.1 单值二叉树
https://leetcode.cn/problems/univalued-binary-tree/
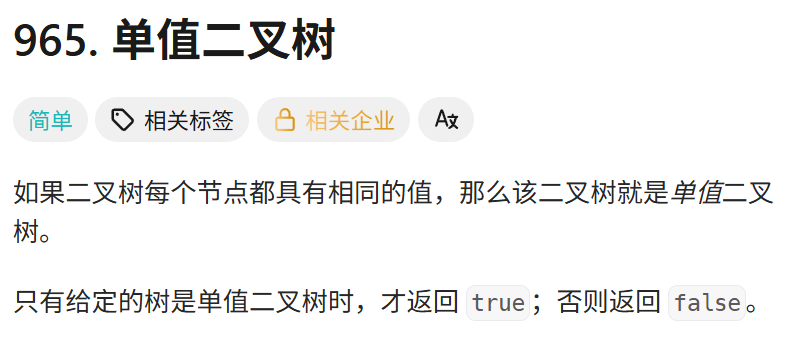
思路一:遍历,保存根节点的值,再对二叉树进行遍历,将各节点的值与根节点的值一一进行比较。
参考代码如下:

思路二:递归
参考代码如下:

3.2 相同的树
https://leetcode.cn/problems/same-tree/

参考代码如下:

3.3 对称二叉树
https://leetcode.cn/problems/symmetric-tree/

参考代码如下:

3.4二叉树的前序遍历
https://leetcode.cn/problems/binary-tree-preorder-traversal/


根据题意,我们要将二叉树中的元素全部拷贝到一个数组中去,并且数组的空间也需要我们自行开辟,所以我们封装一个新的函数TreeSize专门去管理开辟空间的大小。
注意:题目给出的原函数中的参数returnSize属于输出型参数,表示数组的大小
由此我们可以写出下述代码:

但是上述代码运行后是无法通过的。为什么?
下面的例子没有通过,那么我们就用这个例子来画代码递归图找问题:

根据上图我们就能清晰地找到问题了,由于i在遍历左树的时候+1并不会影响原来i的值,所以遍历右树的时候i接收的值还是1,所以最终得到的结果为【3,2,随机值】。
因此我们应该将 i 的地址传过去,修改后的代码如下:
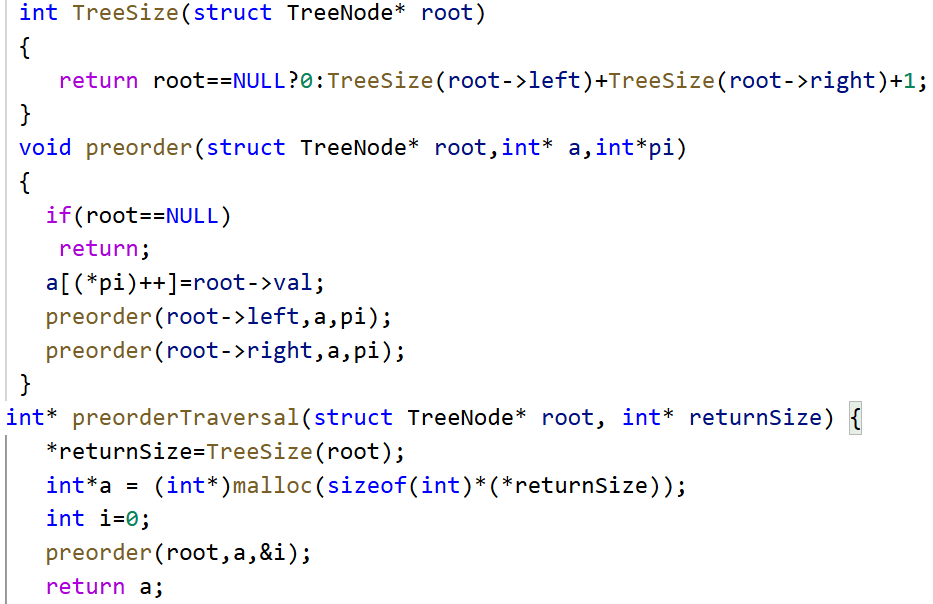
3.5 另一棵树的子树
https://leetcode.cn/problems/subtree-of-another-tree/
参考代码如下:
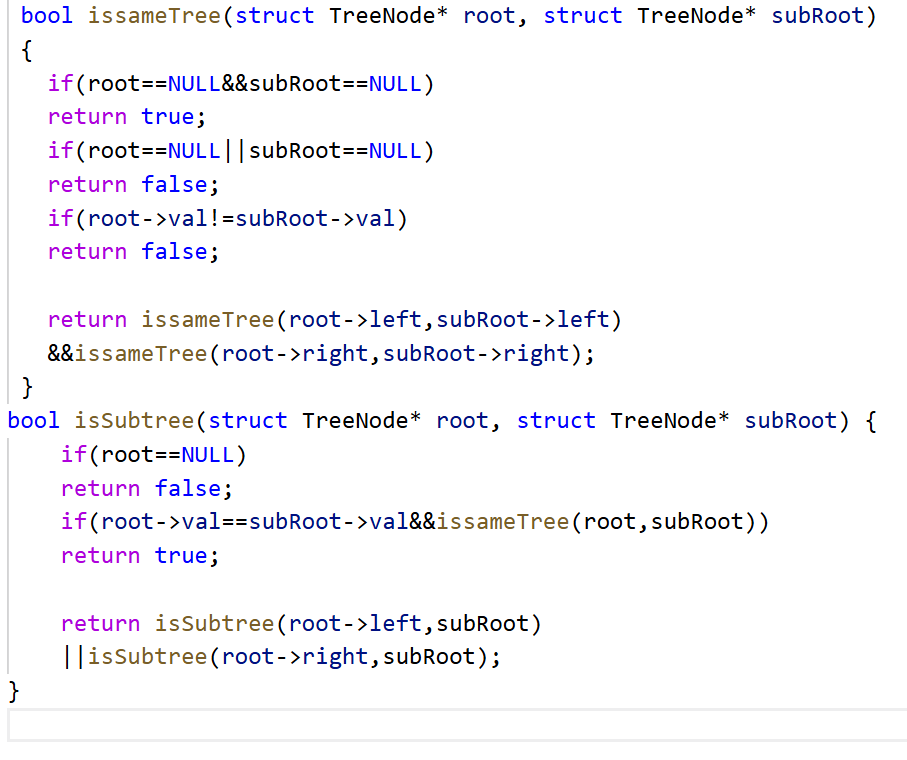
我们借助一个例子画如下的代码递归图来进一步理解这个实现过程:

4. 二叉树的创建与销毁
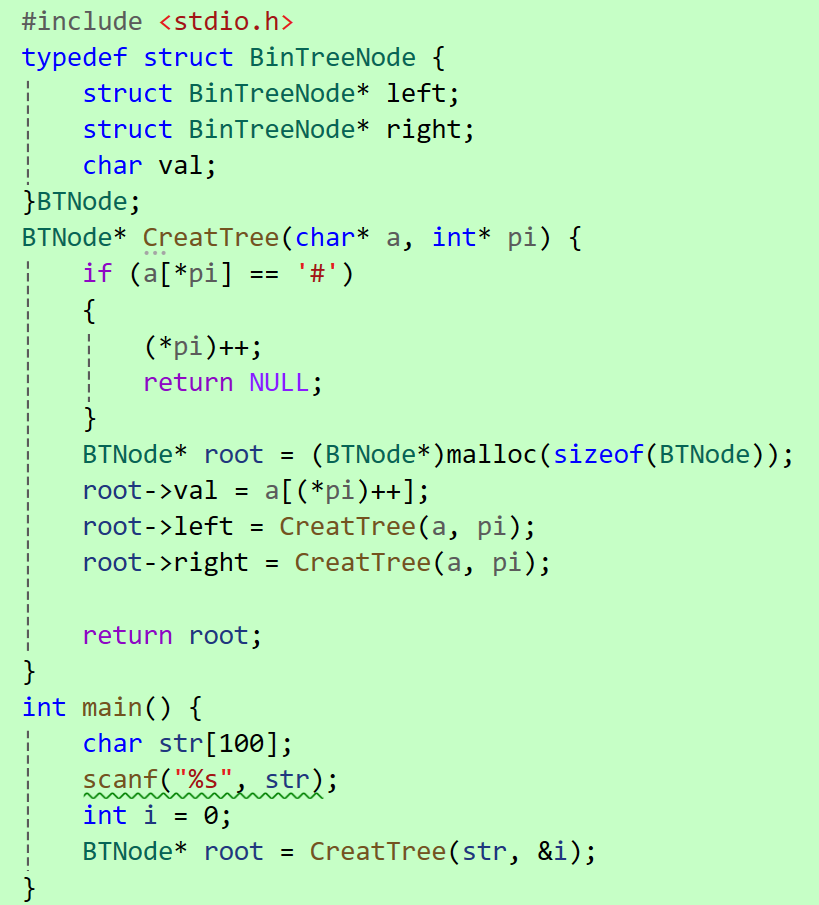
4.1通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
参考代码如下:
4.2二叉树的销毁
画如下简化递归图来帮助我们写代码:
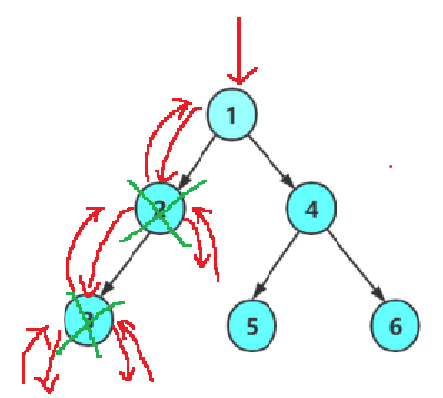
参考代码如下:

理论看懂不算真正学会,接下来请大家独立完成下面的练习题,彻底吃透二叉树的全部核心操作: