做个人技术博客时,真正耗时间的往往不是写第一篇文章,而是把主题切换、阅读页、代码块、目录和写作流程这些细节补齐。
RuyiBlog v0.1.1 是一次前端体验升级。我没有把它做成完整 CMS,而是先把个人博客模板里最容易影响二次开发的几件事梳理清楚:三套主题、首屏主题初始化、Markdown 阅读页,以及一个 AI 写作交互模拟舱。
本文记录这次版本的实现思路,也会把当前边界讲清楚。它适合做个人技术博客、作品集、前端主题系统练习,或者 AI 写作类 UI 原型,但还不是带后台、权限、数据库和真实模型调用的生产级内容平台。
text
版本:v0.1.1
技术栈:Next.js 16.2.6 / React 19.2.4 / marked 18 / Vanilla CSS / localStorage
重点:三状态主题系统、主题首屏初始化、Markdown 阅读页、AI 写作交互模拟为什么做 v0.1.1
RuyiBlog v0.1.0 已经有了基础博客骨架:Next.js App Router、首页列表、Markdown 阅读页和一个模拟 AI 写作面板。
到了 v0.1.1,我主要想解决三个问题:
- 主题表达太单一。只有一种偏 Cyber 的深色视觉,适合展示 AI 和前端项目,但不适合所有内容。
- 阅读场景需要更明确。技术博客最后还是要靠文章页留住读者,目录、代码块、排版和主题都要服务阅读。
- AI 写作舱要先跑通前端链路。真实模型接口可以后接,但交互闭环要先明确:输入参数、输出日志、字符流、Markdown 预览、本地保存。
所以这一版没有堆新页面,而是围绕一个小型前端博客模板做了几处可复用的工程处理。
功能范围先说清楚
当前项目更像一个前端模板,不是完整内容系统。
它包含:
- 三套主题预设:
cyber、bento、swiss localStorage保存主题偏好html[data-theme]驱动 CSS 变量- Markdown 渲染
- 阅读页 TOC
- 代码块复制
- AI 写作交互模拟
- 浏览器本地文章列表
它不包含:
- 后台 CMS
- 数据库持久化
- 多用户权限
- 多端同步
- 真实 LLM API 调用
- 面向投稿系统的安全 Markdown 处理
这类边界很重要。比如"发布到博客首页"在当前版本里指的是写入浏览器本地 localStorage,不是服务端发布。清缓存、换浏览器或换设备后,这些本地数据不会自动同步。
项目里的几个关键文件
这次升级主要集中在这些位置:
text
src/app/layout.js # 根布局、主题首屏初始化、背景层挂载
src/components/Navbar.js # 三状态主题切换
src/app/globals.css # 主题变量、背景层、阅读页样式
src/app/creator/page.js # AI 写作交互模拟舱
src/app/reader/[id]/page.js # Markdown 阅读页、TOC、代码块复制
src/mock/aiGenerator.js # 模拟流式生成器整体链路可以理解成这样:
Navbar theme button
localStorage: ruyiblog_theme
htmldata-theme
CSS variables in globals.css
Cyber / Bento / Swiss UI
Creator page
simulateAIGeneration async generator
logs + markdown chunks
marked.parse preview
localStorage: ruyi_posts
Home feed and reader page
Reader page
marked.parse markdown
TOC from ## / ###
copy button for language code blocks
三状态主题系统:用 data-theme 控制整套视觉
RuyiBlog v0.1.1 没有做普通的 dark/light mode,而是做了三套面向不同内容场景的主题:
cyber:适合 AI、开发工具、极客项目展示bento:适合高密度信息看板、项目列表、工具集合swiss:适合长文阅读、教程、复盘
主题入口不是路由,也不是组件级状态,而是 HTML 根节点上的 data-theme:
js
localStorage.setItem("ruyiblog_theme", newTheme);
document.documentElement.setAttribute("data-theme", newTheme);CSS 里则按主题定义变量:
css
:root,
[data-theme="cyber"] {
--background: hsl(230, 25%, 3%);
--foreground: hsl(210, 40%, 98%);
--primary: hsl(186, 100%, 69%);
}
[data-theme="bento"] {
--background: hsl(0, 0%, 96%);
--foreground: hsl(0, 0%, 5%);
--primary: hsl(120, 100%, 35%);
}
[data-theme="swiss"] {
--background: hsl(35, 25%, 96%);
--foreground: hsl(30, 15%, 15%);
--primary: hsl(350, 70%, 45%);
}这样做的好处是组件不用关心当前主题。按钮、卡片、导航、阅读页只使用 var(--primary)、var(--background)、var(--border) 这类变量。主题变化时,视觉系统跟着变量走。
Cyber 主题:深色背景层和玻璃态组件
Cyber 主题的重点不是"黑色背景",而是背景层和前景组件的分工。
背景层使用多个径向渐变光晕,组件层使用半透明面板、边框、模糊和高亮色。这样首页不会只是纯黑卡片,而是有更明确的技术展示氛围。
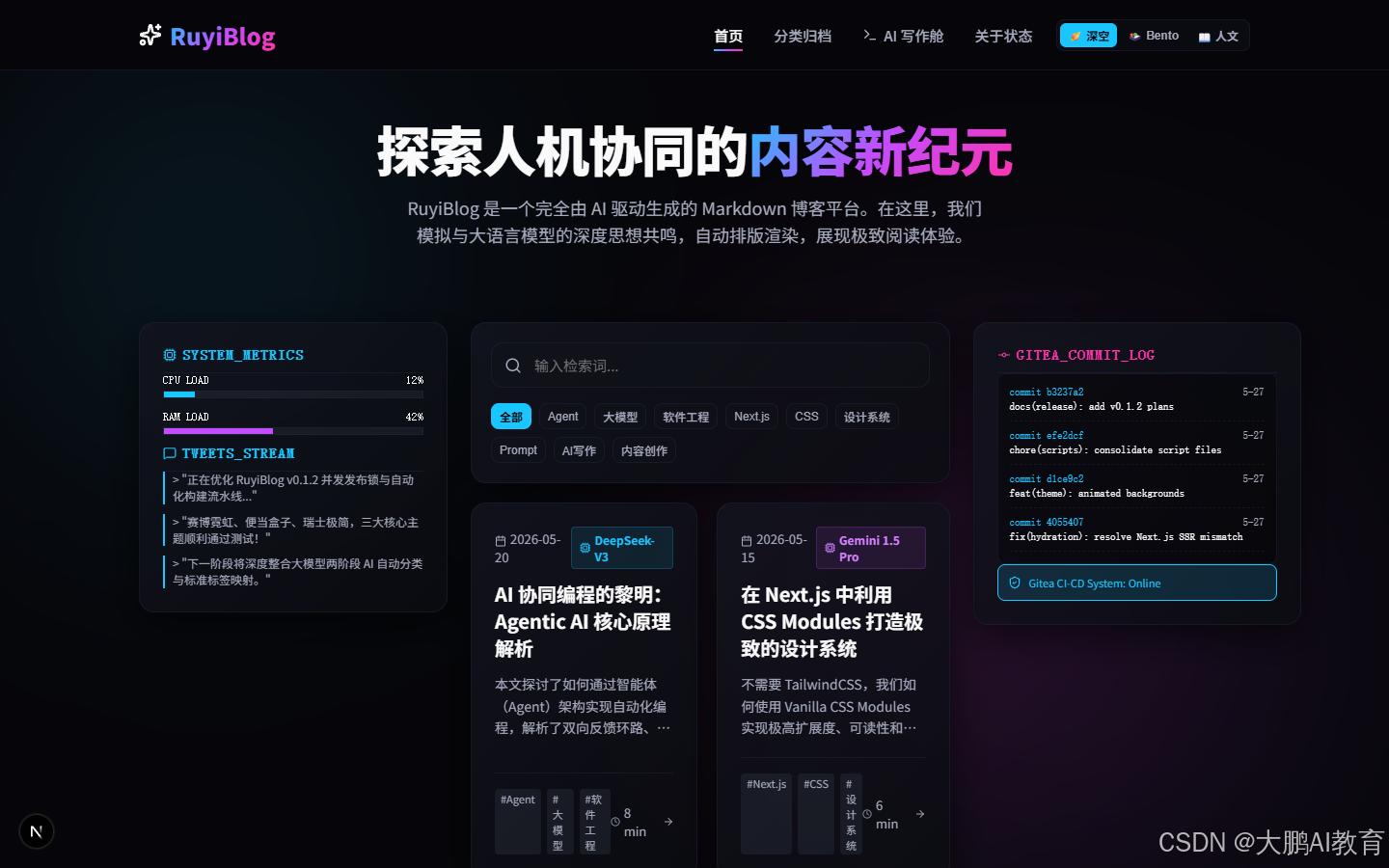
Bento 主题:把首页当成信息看板
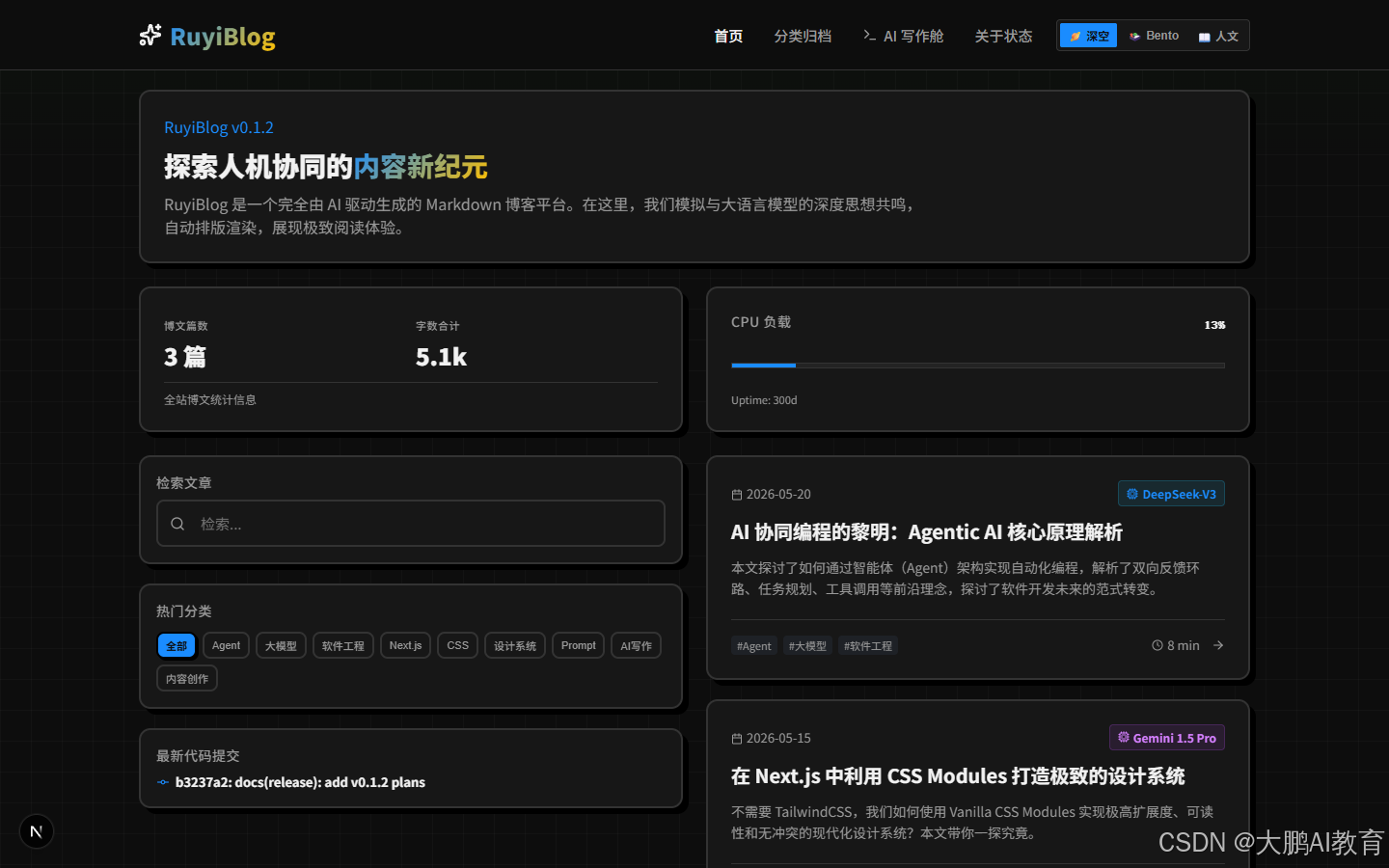
Bento 主题的核心是信息密度。它使用更硬的分割线、实心阴影、网格背景和扫描线动画,让首页更像一个项目控制台。
这套主题适合展示项目集合、分类统计、工具索引这类内容。它不是为了安静阅读,而是为了快速扫信息。
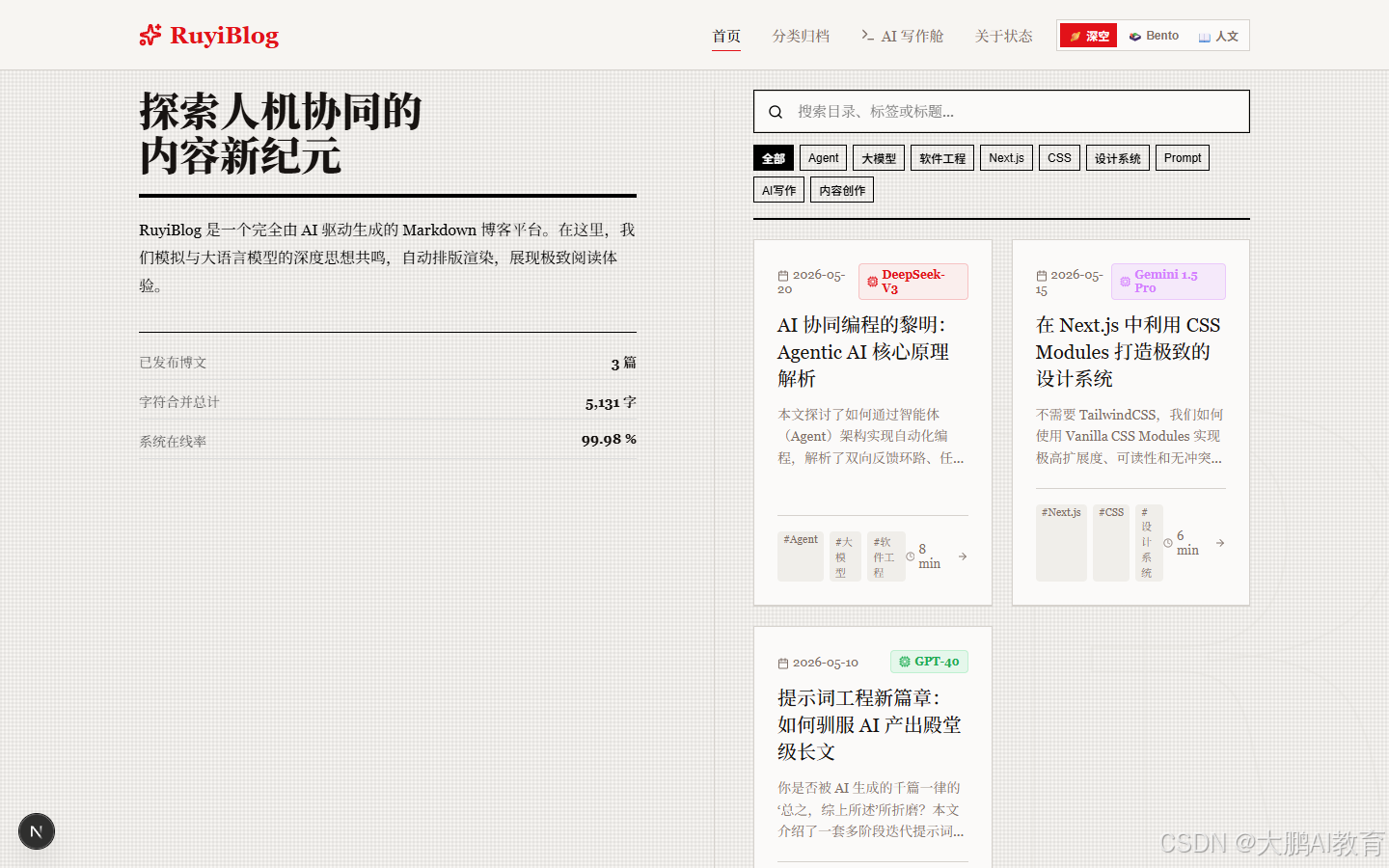
Swiss 主题:让文章页回到阅读
Swiss 主题主要服务长文。它使用更温和的纸张色、轻纹理、衬线标题和更克制的对比度。
对技术博客来说,首页可以有视觉记忆点,但阅读页要让代码和正文好读。Swiss 主题就是为这个目标准备的。
主题初始化:为什么要在 head 里写一个 IIFE
Next.js 里做主题切换时,很容易遇到刷新闪烁。
原因很简单:
- 用户选择的主题存在
localStorage - 服务端渲染阶段读不到浏览器的
localStorage - 如果等客户端 React hydrate 后再设置主题,页面会先渲染默认主题
- 用户看到的就是刷新时闪一下
所以 RuyiBlog 在根布局的 <head> 里放了一个很小的初始化脚本:
jsx
<html lang="zh-CN" suppressHydrationWarning>
<head>
<script
dangerouslySetInnerHTML={{
__html: `
(function() {
try {
const theme = localStorage.getItem('ruyiblog_theme') || 'cyber';
document.documentElement.setAttribute('data-theme', theme);
} catch (e) {}
})()
`,
}}
/>
</head>
<body>{children}</body>
</html>这个脚本的目的只有一个:在首屏绘制前尽早把主题写到 html[data-theme] 上,减少默认主题先出现再切换的闪烁。
这里还有一个配套处理:suppressHydrationWarning。
它不是用来掩盖所有 hydration 问题的。这里使用它,是因为 data-theme 这类单层属性可能在客户端提前写入,和服务端输出不一致。这个场景可以接受,但如果组件内容、列表结构或交互状态出现 hydration 差异,还是应该查根因。
阅读页:技术博客真正被使用的地方
首页决定读者是否点进来,阅读页决定读者是否读完。
RuyiBlog 的阅读页做了几个基础能力:
- 用
marked.parse(md)把 Markdown 转 HTML - 从
##和###提取目录 - 给标题生成 id,目录点击后滚动到对应位置
- 给带语言标记的代码块加复制按钮
- 适配 Swiss 主题的长文排版
目录提取逻辑比较直接:
js
const regex = /^(##|###)\s+(.*)$/gm;
while ((match = regex.exec(content)) !== null) {
const depth = match[1].length;
const text = match[2];
const cleanText = text
.replace(/\[([^\]]+)\]\([^)]+\)/g, "$1")
.replace(/[*_`]/g, "");
const slug = encodeURIComponent(
cleanText.trim().toLowerCase().replace(/\s+/g, "-")
);
headingsList.push({ depth, text: cleanText, slug });
}代码块复制用的是事件委托。Markdown 渲染后会注入复制按钮,点击按钮时再找到对应代码块,把 HTML entity 还原成普通文本后写入剪贴板。
js
const copyBtn = e.target.closest(".copy-btn");
if (!copyBtn) return;
const wrapper = copyBtn.closest(".code-block-wrapper");
const codeElement = wrapper?.querySelector("code");
const tempDiv = document.createElement("div");
tempDiv.innerHTML = codeElement.innerHTML;
const plainCode = tempDiv.innerText;
await navigator.clipboard.writeText(plainCode);这套实现够一个模板使用,但还不是完整阅读系统。当前版本还有几个明确限制:
- 目录不会跟随滚动自动高亮当前章节
- 相同标题会生成相同 slug,锚点可能冲突
- 代码块复制主要覆盖带语言 class 的 fenced code block
marked输出通过dangerouslySetInnerHTML注入,没有显式 HTML sanitize
如果后续要支持用户投稿或外部 Markdown 输入,必须补上 HTML 清洗策略,比如接入可信的 sanitizer,或者改成更严格的 Markdown/MDX 处理链路。
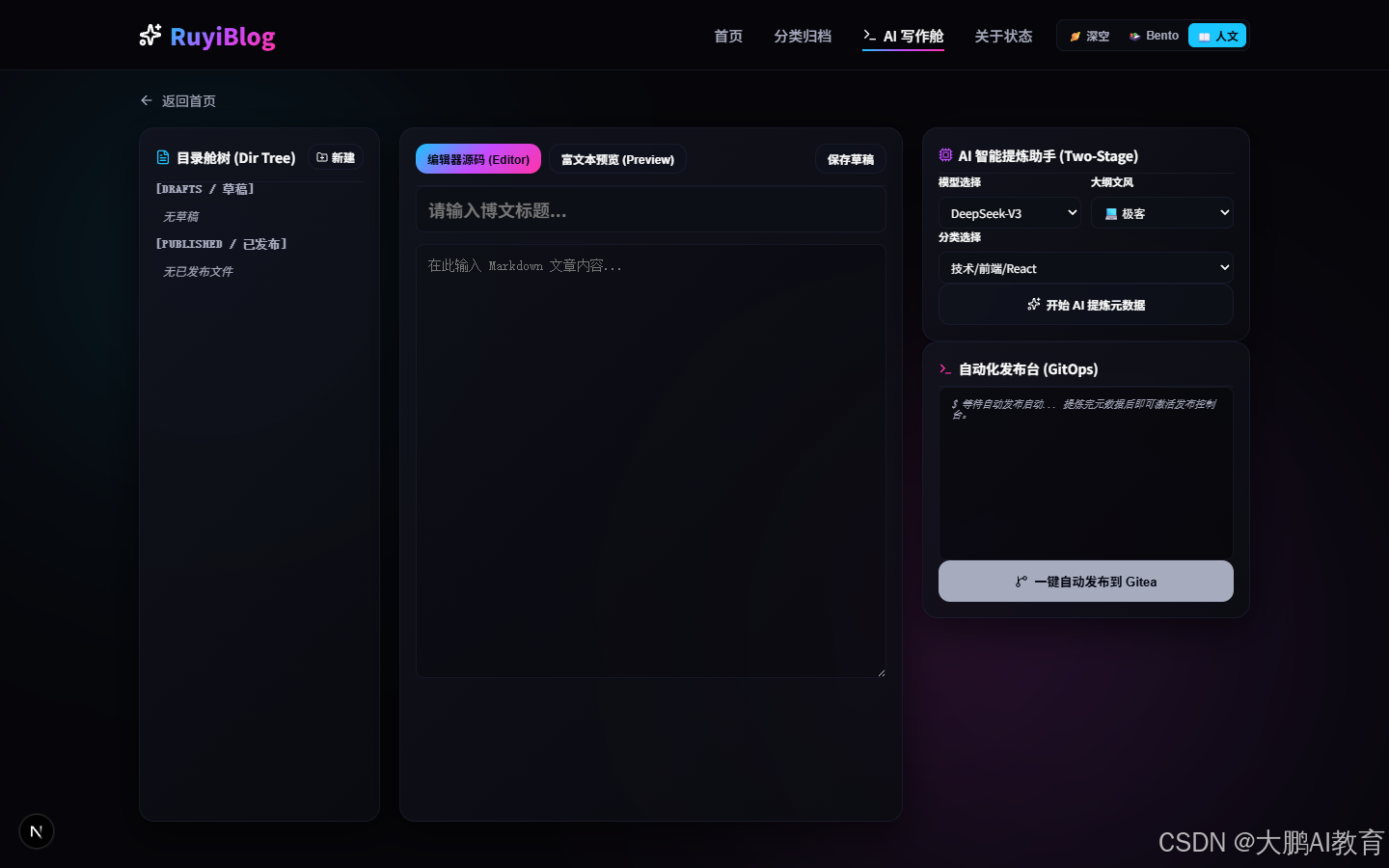
AI 写作交互模拟:先把前端闭环做出来
RuyiBlog v0.1.1 的 AI 写作舱不是直接调用真实模型 API。
它当前是一个前端交互原型:用 simulateAIGeneration 这个 async generator 模拟日志、字符流和生成结果,再用 marked 在右侧实时预览 Markdown。
核心链路大概是:
js
const generator = simulateAIGeneration(topic, model, style);
for await (const chunk of generator) {
if (chunk.type === "log") {
setLogs((prev) => [...prev, chunk.content]);
} else if (chunk.type === "content") {
setCurrentContent(chunk.fullContent);
} else if (chunk.type === "complete") {
setGeneratedPost(chunk.post);
setIsComplete(true);
}
}生成完成后,页面可以把文章写入浏览器本地:
js
const updatedPosts = [newPost, ...posts];
localStorage.setItem("ruyi_posts", JSON.stringify(updatedPosts));这不是服务端发布,也不是数据库持久化。它的价值在于先验证 UI 闭环:
- 参数输入是否顺手
- 控制台日志是否能解释过程
- 字符流是否能让用户理解正在生成
- Markdown 预览是否及时
- 生成后的文章是否能进入首页和阅读页
等真实模型接入时,可以把模拟 generator 换成真实流式接口,前端状态结构基本还能保留。
这次没有做什么
我有意没有在 v0.1.1 里把范围拉太大。
没有做 CMS,是因为当前目标是前端模板和交互原型,不是内容后台。
没有接数据库,是因为 localStorage 足够验证本地写作和阅读链路。等内容模型稳定后,再决定接文件系统、数据库,还是 Git-based content workflow。
没有接真实 LLM,是因为真实接口会带来 API Key、鉴权、计费、流式协议、失败重试和内容安全问题。先把前端体验做顺,再接服务端会更稳。
没有宣传"安全 Markdown 渲染",是因为当前 marked + dangerouslySetInnerHTML 更适合可信内容演示。如果要开放投稿或接外部内容源,这块必须重做安全边界。
下一步可以怎么演进
如果继续往下做,我会优先考虑这些方向:
- 给 Markdown 渲染增加 sanitize 处理,明确可信内容和外部内容的边界。
- 给 TOC 加滚动监听或 IntersectionObserver,支持当前章节高亮。
- 处理重复标题 slug,避免锚点冲突。
- 把
localStorage文章模型迁移到 MDX、文件目录或 Git-based workflow。 - 接入真实流式 LLM API,把模拟 generator 替换成服务端接口。
- 增加 RSS、站点地图、SEO metadata 和全文搜索。
- 补一套更标准的内容发布流程,让它从 Demo 模板逐步变成可长期维护的个人博客。
总结
RuyiBlog v0.1.1 这次升级,本质上不是"给博客换三套皮肤",而是把个人技术博客里几个容易被忽略的前端细节收束到一个模板里:
- 用
data-theme和 CSS 变量管理主题 - 用 head IIFE 减少主题首屏闪烁
- 用 Markdown 阅读页承接真实长文场景
- 用 async generator 模拟 AI 写作交互链路
- 用清晰边界避免把前端模板说成完整平台
一个个人博客项目最容易失控的地方,是一开始就想做成完整系统。v0.1.1 的取舍正好相反:先把展示、阅读和交互原型做扎实,再决定后端、模型和内容工作流怎么接。
如果你也在做个人博客、作品集或者 AI 写作类前端 Demo,可以优先参考这几个部分:主题状态管理、Markdown 阅读页、代码块交互和首屏主题初始化。
发布到掘金、知乎或 CSDN 前,记得把文中的 file:/// 截图替换为平台可访问图片。