09aaaba-LayerNorm中心化操作是什么?📊
本文档深入解释 LayerNorm 中"减去均值"这一中心化操作的核心概念,涵盖数学定义与计算步骤、几何意义(正交投影)、为什么需要中心化,以及 RMSNorm 为何能去掉中心化仍保持性能 🔍
章节阅读路线图 🗺️
- 什么是中心化操作? → 理解 LayerNorm 中心化步骤的定义与角色
- 中心化的数学本质 → 从公式推导理解减去均值到底做了什么
- 中心化的几何意义 → 正交投影:将数据压入与全1向量正交的超平面
- 为什么需要中心化? → 中心化对训练稳定性和模型性能的影响
- 总结 → 回顾核心要点
1. 什么是中心化操作?🤔
本章定义 LayerNorm 中心化操作的基本概念
中心化操作(Centering / Mean Centering) 是 Layer Normalization 中的第一步:在归一化之前,先将输入向量减去其均值。
回顾 09aaa-LayerNorm是什么?(CSDN)中 LayerNorm 的完整公式:
LayerNorm(x)=γ⊙σ2+ϵ x−μ+β
其中中心化操作对应的是分子中的 x−μ 部分:
μ=d1i=1∑dxi⟹中心化后:x^=x−μ
通俗地说,就是把输入向量 x=x1,x2,...,xd 中的所有元素都减去它们的平均值 μ,使得输出向量的所有元素之和为零------即零中心化(Zero-Centered)。
为什么叫"中心化"?
想象一条数轴上的数据点:减去均值相当于把整个数据分布"平移"到原点附近,让分布的中心(均值)落在零的位置。这就好比把一把尺子的刻度重新对齐,让零刻度对准数据的重心。
中心化操作参考资料:
- Layer Normalization -- Learn Mechanistic Interpretability ⭐值得阅读
- Geometry and Dynamics of LayerNorm -- arXiv ⭐值得阅读
2. 中心化的数学本质 📝
本章拆解中心化操作的数学内涵
2.1 从统计视角看:消除均值偏移
在标准统计学中,对数据中心化是一种常见的预处理步骤。给定一个 d 维向量 x,其均值为 μ=d1∑i=1dxi,中心化后的向量为:
xi(1)=xi−μ,i=1,2,...,d
中心化后的向量满足一个重要性质:
i=1∑dxi(1)=0
即所有元素之和为零。这意味着数据分布的整体"偏移量"被消除,后续的方差归一化只关注数据的散布程度,不受均值位置的影响。
2.2 中心化与方差的关系
中心化操作直接影响方差的计算。原始向量的方差定义为:
σ2=d1i=1∑d(xi−μ)2=d1i=1∑d(xi(1))2
如果没有中心化,直接计算"原始值"的平方均值会混入均值偏移的影响:
d1i=1∑dxi2=σ2+μ2
这意味着一个偏移很大的向量( μ 很大)即使方差很小,其平方均值也会很大,导致归一化因子被均值"污染"。中心化确保了方差计算只反映数据的真实散布。
💡 关键理解 :去掉中心化后,归一化因子 d1∑xi2 实际上变为 σ2+μ2 ,混入了均值的影响。
中心化的数学本质参考资料:
- RMSNorm: Efficient Normalization for Modern LLMs -- mbrenndoerfer ⭐值得阅读
- On the Expressivity Role of LayerNorm in Transformers' Attention -- Technion ⭐值得阅读
3. 中心化的几何意义 🎯
本章从几何角度解释中心化操作的本质
减去均值不仅仅是一个统计步骤,它实际上是一个正交投影(Orthogonal Projection) ------将输入向量投影到与全1向量 1 正交的超平面上。
3.1 从代数到几何
先看一个关键观察:向量 x 的元素之和可以表示为点积:
i=1∑dxi=x⋅1
其中 1 =1,1,...,1 是 d 维全1向量。中心化后向量元素之和为零,意味着:
x(1)⋅1 =0
两个非零向量的点积为零,意味着它们相互垂直(正交) 。因此,中心化后的向量 x(1) 与全1向量 1 正交。
3.2 正交投影的数学推导
更精确地说,减去均值等价于减去向量在 1 方向上的投影。 1 方向上的单位向量为 1^=d 1 , x 在该方向上的投影长度为 x⋅1^,投影向量为:
proj1^(x)=(x⋅1^)1^
展开后得到:
proj1^(x)=d1(x⋅1 )1 =μ1
这正是均值向量------每个元素都是 μ 的向量。所以减去均值就是减去向量在 1 方向上的投影:
x(1)=x−μ1 =x−proj1^(x)
3.3 直观理解
可以把 d 维空间想象成一个房间,全1向量 1 是房间中从原点指向"对角"方向的一条线。中心化操作将任意数据点 x 投影到与这条线垂直的"墙"上------一个 d−1 维的超平面。
这个超平面的数学定义是:
H={v∈Rd∣i=1∑dvi=0}
所有经过 LayerNorm 中心化的数据都落在这个超平面上。这意味着原始数据被压缩了一个自由度 ------从 d 维空间降到了 d−1 维超平面。这个超平面上的数据均值为零,为后续的方差归一化做好了准备。
💡 几何直觉 :中心化操作就像把一个散落在三维空间中的点云"拍扁"到 x+y+z=0 这个平面上。在这个平面上,所有点的重心位于原点。
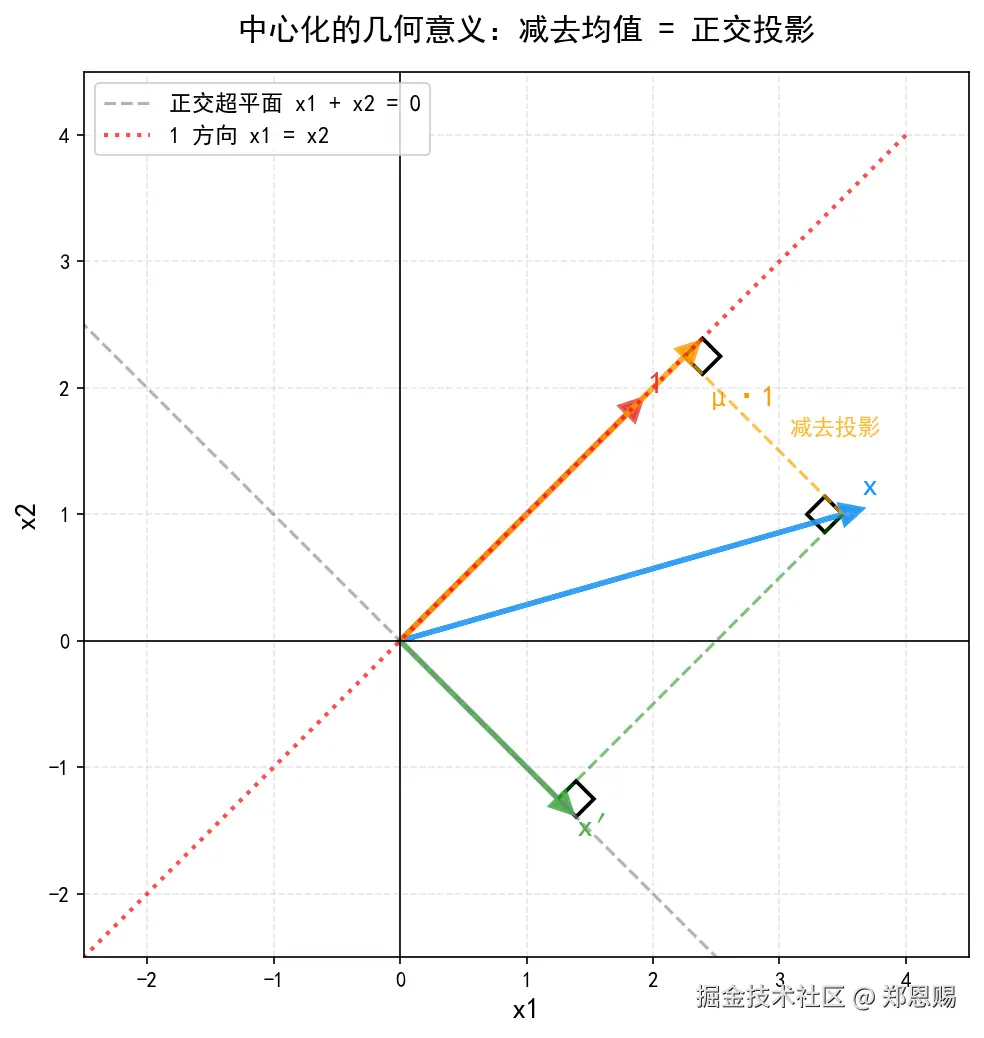
图:中心化的几何意义示意(d=2) ------蓝色向量 x=3.5,1.0 减去均值 μ 后得到绿色向量 x′=1.25,−1.25,它落在与 1 正交的超平面(灰色虚线 x1+x2=0)上。橙色向量 μ⋅1 是 x 在 1 方向上的投影。三个直角标记标出了各处的正交关系。
中心化的几何意义参考资料:
- Why Modern LLMs Dropped Mean Centering (And Got Away With It) -- Sifal Klioui ⭐值得阅读
- Geometry and Dynamics of LayerNorm -- arXiv ⭐值得阅读
- Layernorm is just two projections -- Reddit
4. 为什么需要中心化?💡
本章解释中心化操作在深度神经网络中的核心作用
中心化在 LayerNorm 中扮演着几个关键角色:
4.1 消除内部协变量偏移
深度网络训练的核心困难之一是内部协变量偏移(Internal Covariate Shift):每一层的输入分布随着前面层参数的更新而不断变化,导致后面的层需要不断适应新的输入分布。
中心化通过将每层输入的均值强制归零,使输入分布的中心位置保持稳定。这意味着后续层的激活函数始终工作在一个稳定的输入范围内,避免了因均值偏移导致的梯度饱和或消失。
4.2 保障方差归一化的准确性
如第 2 章所述,只有先中心化,方差计算才能真实反映数据的散布程度。如果数据存在均值偏移,归一化因子 σ2+μ2 会被均值项 μ2 污染,导致归一化后的数据仍然存在偏移------减弱了归一化的效果。
4.3 几何上的必要性
从几何角度看,中心化将数据约束到与 1 正交的超平面上,为下一步方差归一化(将数据映射到半径为 d 的超球面)创造了条件。经过中心化后的数据在 1 方向上不再有任何分量,使得后续的缩放操作可以均匀地作用于所有方向。
4.4 在残差网络中的特殊意义
在现代 Transformer 的 Pre-Norm 架构中,LayerNorm 出现在每个子层之前。残差连接本身已经在一定程度上维持了表征的稳定性,但残差路径上累积的更新仍然可能导致均值漂移。中心化确保了进入注意力层和前馈网络的输入具有稳定的中心位置,从而保护了注意力分数的计算------点积结果不会因为均值偏移而系统性偏大或偏小。
为什么需要中心化参考资料:
- 3.6 层归一化:为什么选择LayerNorm 而非BatchNorm -- GitBook
- Layer Normalization -- Learn Mechanistic Interpretability ⭐值得阅读
- LayerNorm 真的不可或缺吗?-- 知乎
5. 总结 📝
中心化操作( x−μ)是 LayerNorm 的关键第一步,其核心要点:
| 视角 | 本质 | 一句话总结 |
|---|---|---|
| 统计 | 消除均值偏移 | 使数据零中心化,方差计算不受均值污染 |
| 几何 | 正交投影 | 将数据投影到与 1 正交的 d−1 维超平面 |
| 训练 | 对抗协变量偏移 | 稳定每层输入的分布中心 |
| 进化 | RMSNorm 选择去掉 | 因为深度网络中均值自然接近零,中心化变得冗余 |
🔴 关键理解:
- 中心化本质上是正交投影 ,将数据从 d 维空间降维到 d−1 维超平面
- 没有中心化,方差归一化将混入均值偏移的影响,削弱归一化效果
- RMSNorm 的成功说明在训练良好的网络中,中心化的贡献有限
- RMSNorm 去掉中心化带来了效率提升,但在训练不稳定时存在方向坍缩风险
最后更新时间:2026-05-28