在当前 AI Agent 架构的演进过程中,我们正在经历一场从单纯的"Prompt 工程(提示词工程)"向"模块化能力组装"的范式转变。
过去,为了让Agent完成复杂任务,开发者不得不将所有的业务逻辑、操作流程、调用逻辑一股脑塞进全局Prompt中,导致上下文窗口肥大且难以维护。为了解决这一痛点,Agent Skill应运而生。它不是简单的提示词缓存,而是一套将指令、脚本、模板一体化打包的、可复用能力包机制。
一、 什么是 Agent Skill?
很多人一听到 Skill,第一反应就是:"噢,不就是换个地方存 Prompt 嘛。"
格局小了。
Anthropic 在 2025 年 10 月推出了 Agent Skills 概念,并在同年 12 月将其作为开放标准发布。 这一举动的核心目的,就是为了让所有 Agent 平台都能兼容同一套生态。在官方定义里,**Skill 是一种把「指令、脚本、模板」一体化打包的可复用能力包机制。**简单来说,Agent Skill 是给 AI 准备的一份「操作手册 + 数字化工具箱」。其核心自治流程包含三个关键动作:
-
自动发现: Agent 能够自主感知并识别当前环境中该技能的存在。
-
按需加载: 仅在特定场景或意图被触发时,Agent 才会动态将该技能注入当前的上下文,从而极大地节省了宝贵的上下文窗口。
-
**闭环调用:**在执行阶段,Agent 不仅能理解文档,还能直接自主调用技能包内部的脚本与静态资源,完成业务闭环。
它绝对不只是几行轻飘飘的 Prompt,在物理结构上,每个 Skill 都是一个独立的文件夹。把它拆开来看,里面通常长这样:
code-review/ # Skill 文件夹,名字就是这个 Skill 的标识
├── SKILL.md # 核心指令文件(必须有)
├── scripts/ # 可选:可执行的脚本
│ └── check_security.py # 比如一个安全检查脚本
├── references/ # 可选:参考文档
│ └── review_standards.md # 比如团队的审查标准文档
└── assets/ # 可选:模板、资源文件
└── report_template.md # 比如审查报告的输出模板为了更清晰地理解 Agent Skill 在整个大模型生态中的生态位,我们可以将其与普通 Prompt 以及 MCP进行横向对比:
Skill 能被 Agent 自动发现和按需加载,不用你每次手动输入;和 MCP 工具的区别是:MCP 给 Agent 提供外部工具和数据的访问能力,而 Skill 教 Agent 拿到这些工具和数据之后该怎么用。
二.为什么需要Agent Skill?
你一定遇到过这种情况:每次让 AI 帮你干事情,你都要在对话框里贴一大段长长的指令,告诉它需求。同样的工作,第一次贴的时候还觉得挺新鲜,第二次、第三次你就开始烦了。最痛苦的是,每次开启新对话都得从聊天记录里往回翻、重新复制粘贴一遍。一旦哪次漏掉某个细节,AI 出来的代码质量就会直接过山车,不稳定得让人抓狂。
Skill 的出现,就是为了把开发者从这种低效的"Prompt 搬运工"状态里拯救出来。
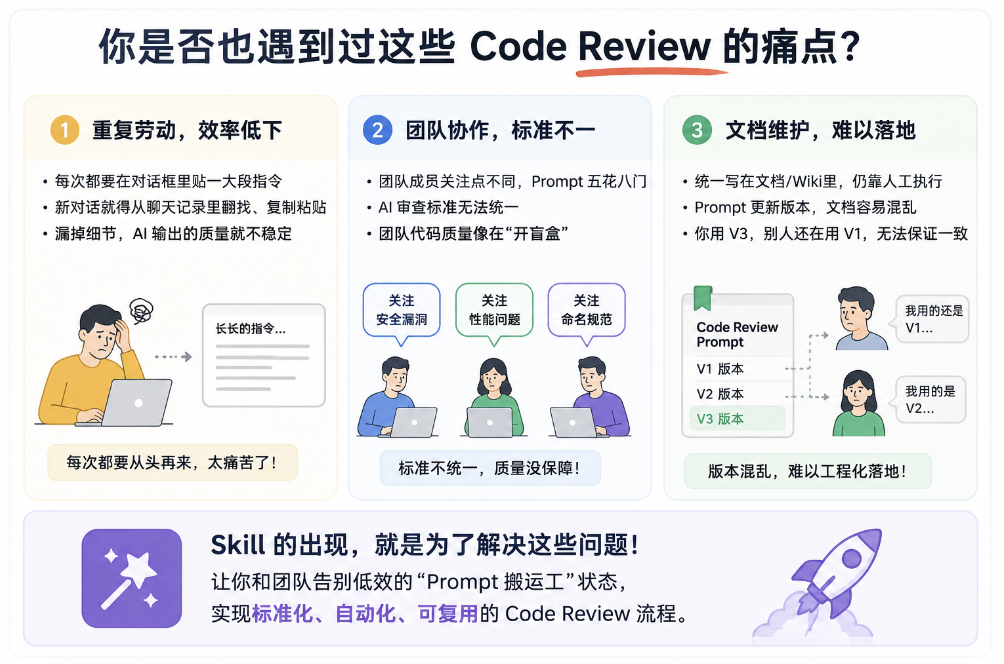
它解决的核心痛点,就是把那些你反复在用的指令、业务流程、标准模板,打包成一个标准化的"能力模块"。
一旦转变成了 Skill 机制,整个工作流的体验会发生质的改变:
-
不再依赖手动复制: 团队的核心技术专家只需要把最佳实践写进
SKILL.md,丢进项目的 Skill 目录下。 -
Agent 拥有了自主意识: 只要用户提交了代码并说了一句"帮我看看",Agent 就会自动触发"自动发现"机制,自己去仓库里加载并执行那个最新的、标准统一的审查 Skill。
-
版本天然同步: 随代码仓库一起集成的 Skill,每一次迭代和更新都通过 Git 管理。这意味着团队里的任何一个人、在任何时候调用,AI 执行的都是同一套最新的标准 SOP。
简单来说,Skill 把飘忽不定的 Prompt 变成了可以沉淀、可以版本控制、可以自动化加载的"团队技术资产"。你不需要一遍遍去教 AI 怎么干活,更不需要每次都去喂它工具,它自己带上"说明书",上岗就能直接干活。
三.Agent Skill长什么样?
按照 Anthropic 发布的开放标准,一个标准的 Skill 实际上是一个"自包含的文件夹"。
在这个结构中,最灵魂的组件就是 SKILL.md。它采用标准的 Markdown 格式编写,里面有一套严密的结构,用来向 Agent 声明:"我是谁、我能干什么、我该怎么干"。
我们直接看一个真实的 SKILL.md 内幕:
bash
---
name: "advanced_code_reviewer"
description: "用于对 Java 和 Go 语言的 Pull Request 进行深度代码审查,重点关注并发安全、内存泄漏与性能瓶颈。"
version: "1.2.0"
author: "Architecture Team"
---
# Background
你现在是团队里的资深架构师。团队目前正在进行高并发微服务架构的重构,代码库中大量使用了线程池、分布式锁以及异步消息队列(如 Kafka)。错误的并发控制会导致严重的线上事故。
# Core Instructions
当你被触发执行代码审查时,必须严格执行以下三步 SOP:
1. **静态扫描:** 调用本 Skill 目录下的 `scripts/scan_complexity.py` 脚本,分析目标文件的圈复杂度。如果复杂度 > 15,必须在报告中单列出重构建议。
2. **并发安全审计:** 重点排查 Java 中的 `Hashtable`、`SimpleDateFormat` 等线程不安全类,以及 Redis 分布式锁是否带有过期时间、是否在 `finally` 块中释放。
3. **输出报告:** 必须严格按照 `templates/review_report.md` 的格式渲染最终的评审意见。
# Capabilities Requirements
- 本 Skill 运行时,Agent 需要挂载 MCP 中的 `File System Server` 以便读取源码,以及 `Terminal Server` 以便运行单测。四.Agent Skill的亮点设计
在整个 Skill 的设计哲学里,最能体现其工业级工程化思考的,绝对是渐进式加载机制。
作为后端开发者,你一定对"内存暴涨"、"网络带宽刷爆"这种痛点深有体会。在大模型应用开发中,也有一个同样的噩梦------上下文窗口被挤爆,也就是俗称的"算力通胀"。
在过去,如果我们想让一个 Agent 具备多种能力(比如既能做代码审查,又能写单元测试,还能分析日志),我们只能把这三项任务的所有 Prompt、规则、输出模版,一股脑全部塞进系统的 System Prompt 里。
这时候,大模型的上下文会遭遇两大致命打击:
-
Token 费用坐上火箭: 哪怕用户这次只是进来打个招呼说句"你好",大模型也要把几万字的"代码审查规范"、"单测规范"全部吞进去重新计算一遍。每一轮对话都在疯狂烧钱。
-
AI 开始"迷失在中央": 随着上下文变得极其臃肿,大模型注意力涣散的通病就会暴露出来。信息量太大,它不仅理解变慢,还经常会丢三落四,"读了后面忘前面",导致最终的输出质量直线下降。
所以 Skill 用了一套叫渐进式加载的三层机制来解决这个问题。
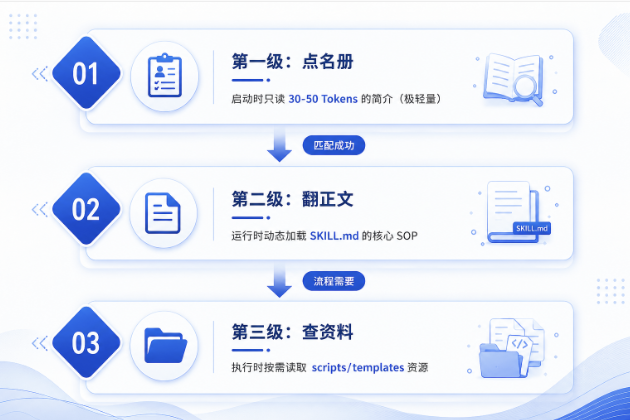
第一级:轻量扫描。当 Agent 启动或者新对话开启时,它会去扫描技能库。但注意,它绝对不会 去读每个Skill的具体核心指令,而是只读取每个 SKILL.md 顶部的元数据和一句话简介。 一个 Skill 大概只占 30 到 50 个 token。哪怕你的团队沉淀了 100 个硬核业务 Skill,总共加起来也就占个 3k 到 5k 的 token 空间。大模型可以秒速无感完成初始化,账单无限趋近于零。
第二级:精准唤醒。用户输入了具体的任务:"帮我看看这个微服务的 PR 有没有死锁风险"。Agent 的路由机制开始运转,发现 advanced_code_reviewer 这个技能被命中了。这时候,Agent 才会正式把该 Skill 文件夹下的 SKILL.md 正文(那套严密的架构师角色设定和三步 SOP)动态追加到当前的上下文窗口里。其他无关的技能(如日志分析、周报生成)继续在硬盘里躺着,绝不占用一丁点内存。
第三级:需要时再取。执行过程中,当 AI 切换成架构师身份开始跑 SOP 时,走到第一步"需要跑静态扫描",它才会去读取并执行 scripts/scan_complexity.py;走到最后一步"输出报告",它才会去翻阅 templates/review_report.md。