Ceph 分布式存储简介
Ceph 简介
Ceph 是一款开源、分布式、软件定义存储 。
Ceph 具备极高的可用性、 扩展性和易用性, 用于存储海量数据。
Ceph 存储可部署在通用服务器上, 这些服务器的CPU可以是x86架构, 也可以是ARM架构。
Ceph 支持在同一集群内既有x86主机,又有ARM 主机。
软件定义 software-defined storage (SDS)
Ceph访问方式-简介
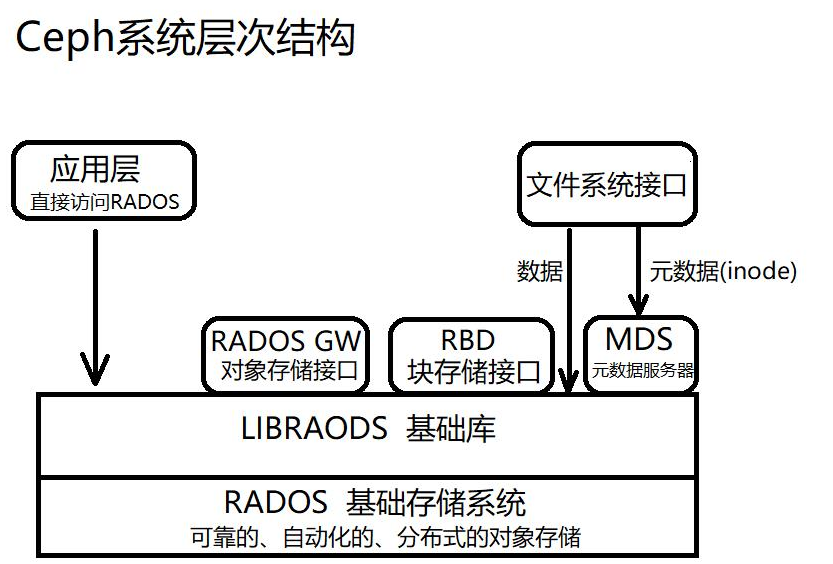
Ceph提供以下访问Ceph集群的方法:
Ceph原生API(librados)
Ceph块设备(RBD、librbd),也称为 RADOS块设备(RBD)镜像
Ceph对象网关(RADOSGW、librgw)
Ceph文件系统(CephFS、libcephfs)
Ceph存储后端组件-简介
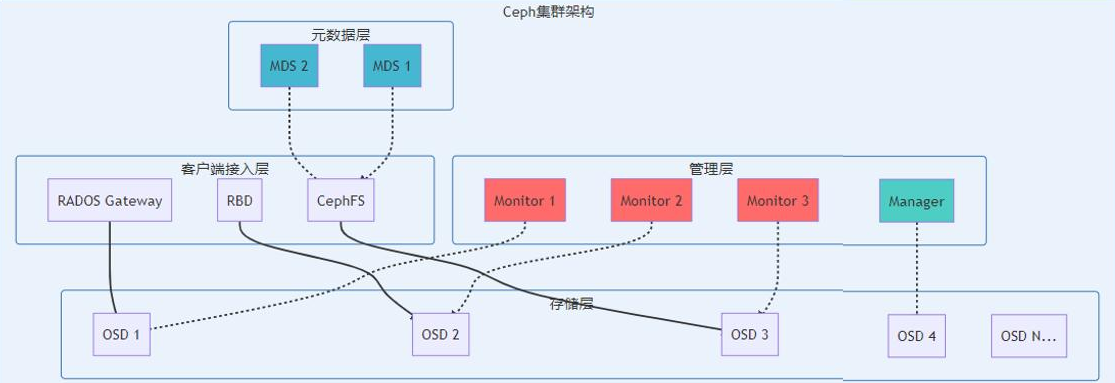
监控器(MON)维护集群状态映射。它们可帮助其他守护进程互相协调。
对象存储设备(OSD)存储数据并处理数据复制、恢复和重新平衡。
管理器(MGR)通过基于浏览器的仪表板和RESTAPI,跟踪运行时指标并公开集群信息。
元数据服务器(MDS)存储CephFS使用的元数据(而非对象存储或块存储),以便客户端能够高效运
行 POSIX命令。
Ceph 分布式存储 部署过程
Ceph 集群环境说明
部署方法:cephadm
操作系统:Centos Stream 8(最小化安装)
硬件配置:2 cpu、4G memory、1个系统盘+3个20G scsi数据盘
准备虚拟机模板
基于 CentOS-Stream-8-template 模板克隆出 ceph-template
bash
# 1 配置主机名解析
[root@localhost ~]# cat >> /etc/hosts << EOF
###### ceph ######
192.168.108.10 client.zhu.cloud client
192.168.108.11 ceph1.zhu.cloud ceph1
192.168.108.12 ceph2.zhu.cloud ceph2
192.168.108.13 ceph3.zhu.cloud ceph3
EOF
# 2 关闭 SELinux
[root@localhost ~]# sed -ri 's/^SELINUX=.*/SELINUX=disabled/g'
/etc/selinux/config
# 3 关闭防火墙
[root@localhost ~]# systemctl disable firewalld --now
# 4 配置yum仓库
[root@localhost ~]# cat << 'EOF' > /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/centos-vault/8-stream/storage/x86_64/cephpacific
enabled=1
gpgcheck=0
EOF
# 5 安装基础软件包
[root@localhost ~]# dnf install -y bash-completion vim lrzsz unzip rsync sshpass tar
# 6 配置时间同步
[root@localhost ~]# dnf install -y chrony
[root@localhost ~]# systemctl enable chronyd --now
# 7 安装 cephadm
[root@localhost ~]# dnf install -y cephadm
[root@localhost ~]# cephadm --help
usage: cephadm [-h] [--image IMAGE] [--docker] [--data-dir DATA_DIR]
[--log-dir LOG_DIR] [--logrotate-dir LOGROTATE_DIR]
[--sysctl-dir SYSCTL_DIR] [--unit-dir UNIT_DIR] [--verbose]
[--timeout TIMEOUT] [--retry RETRY] [--env ENV]
[--no-container-init]
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rmcluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,checkhost,prepare-host,add-repo,rm-repo,install,registry-login,gatherfacts,exporter,host-maintenance,disk-rescan}
...
Bootstrap Ceph daemons with systemd and containers.
positional arguments:
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rmcluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,checkhost,prepare-host,add-repo,rm-repo,install,registry-login,gatherfacts,exporter,host-maintenance,disk-rescan}
sub-command
version get ceph version from container
pull pull the default container image
inspect-image inspect local container image
ls list daemon instances on this host
......
# 安装 cephadm 的时候,会自动安装官方推荐的容器引擎 podman
[root@localhost ~]# rpm -q podman
podman-4.9.4-0.1.module_el8+971+3d3df00d.x86_64
# 8 提前下载镜像
[root@localhost ~]#
podman pull quay.io/ceph/ceph:v16
podman pull quay.io/ceph/ceph-grafana:8.3.5
podman pull quay.io/prometheus/node-exporter:v1.3.1
podman pull quay.io/prometheus/alertmanager:v0.23.0
podman pull quay.io/prometheus/prometheus:v2.33.4
# 准备配置主机脚本
[root@localhost ~]# cat > /usr/local/bin/sethost <<'EOF'
#!/bin/bash
hostnamectl set-hostname ceph$1.zhu.cloud
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.108.1$1/24 ipv4.gateway 192.168.108.2 ipv4.dns 192.168.108.2
init 0
EOF
##添加可执行权限
[root@localhost ~]# chmod +x /usr/local/bin/sethost关机虚拟机,并打快照
准备集群节点
克隆出其他虚拟机,并配置主机名和IP地址。
bash
##之前模板配置好脚本,直接运行脚本配置
#ceph1到ceph3按以下修改
[root@localhost ~]# sethost 1 #ceph1用1Ceph 集群初始化
bash
[root@ceph1 ~]# cephadm bootstrap --mon-ip 192.168.108.11 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password xxxxx --dashboard-password-noupdate
##初始化时会输出内容,网站用户名密码会显示在输出内容里面--mon-ip 192.168.108.11,指定 monitor ip。
--allow-fqdn-hostname,指定允许使用长名称。当主机名是长名称时,初始化时必须使用该参
数。
--initial-dashboard-user admin,指定 Web UI 登录的管理员账户。
--initial-dashboard-password ,指定 Web UI 登录的管理员账户对应密码。
--dashboard-password-noupdate,指定不要更新 Web UI 登录密码。
随后登陆网站
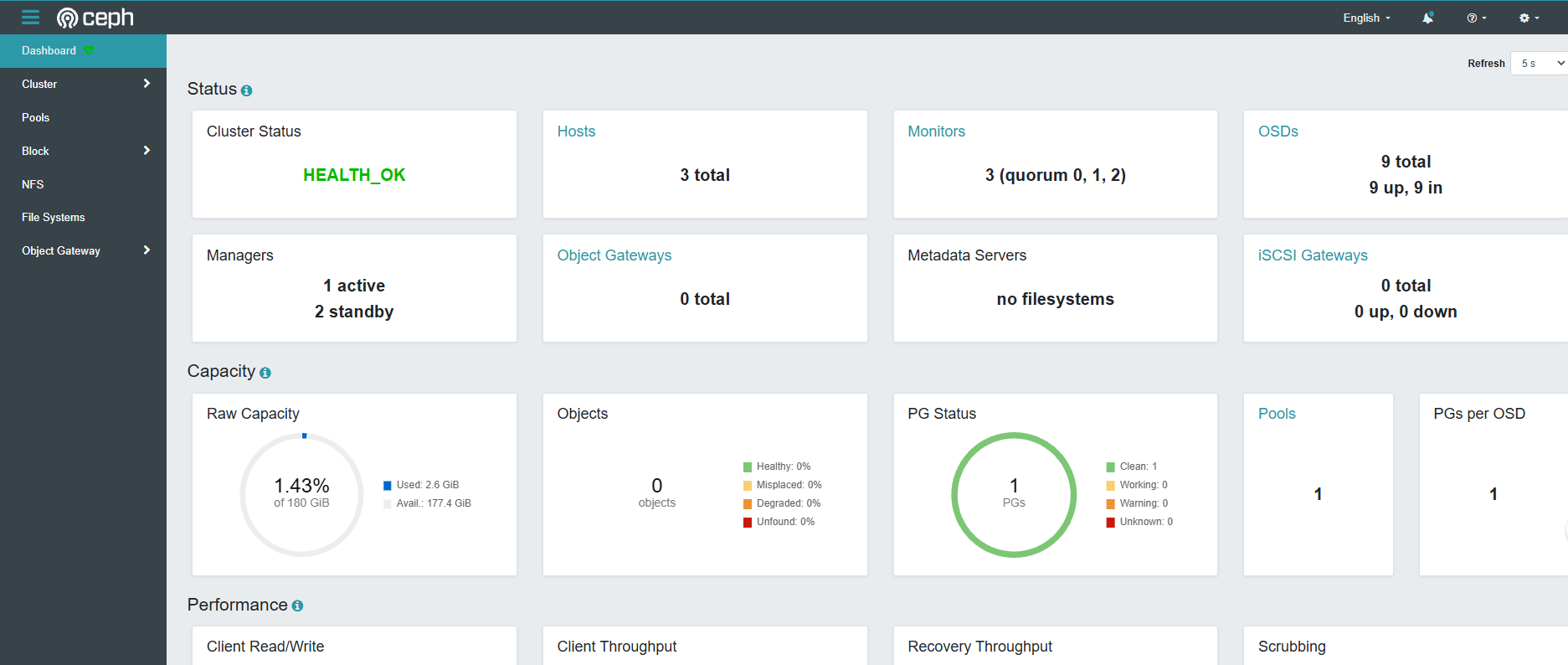
添加节点
添加节点过程:
- Ceph采用共享秘钥进行身份验证, 使用命令"ceph cephadm get-pub-key" 获取到主机接入集群时
所需的ssh 公钥。 - 获取到公钥后, 使用该公钥实现对节点的免密ssh管理。
- 使用命令"ceph orch host add" 添加主机。
bash
# 为了配置方便,我们在ceph1上安装ceph客户端工具 ceph-common
[root@ceph1 ~]# dnf install -y ceph-common
# 获取集群公钥
[root@ceph1 ~]# ceph cephadm get-pub-key > ~/ceph.pub
# 推送公钥到其他节点
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph2.zhu.cloud
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph3.zhu.cloud
# 添加节点
[root@ceph1 ~]# ceph orch host add ceph2.zhu.cloud
Added host 'ceph2.zhu.cloud' with addr '192.168.108.12'
[root@ceph1 ~]# ceph orch host add ceph3.zhu.cloud
Added host 'ceph3.zhu.cloud' with addr '192.168.108.13'
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.zhu.cloud 192.168.108.11 _admin
ceph2.zhu.cloud 192.168.108.12
ceph3.zhu.cloud 192.168.108.13
3 hosts in cluster
# 等待自动部署服务到其他节点,部署完成后效果如下:
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 8m ago 9m count:1
crash 3/3 8m ago 9m *
grafana ?:3000 1/1 8m ago 9m count:1
mgr 2/2 8m ago 9m count:2
mon 3/5 8m ago 9m count:5
node-exporter ?:9100 3/3 8m ago 9m *
prometheus ?:9095 1/1 8m ago 9m count:1
# crash 3/3个
# mgr 2/2个
# mon 3/5个
# node-exporter 3/3个部署 mon 和 mgr
bash
# 禁用 mon 和 mgr 服务的自动扩展功能
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
[root@ceph1 ~]# ceph orch apply mgr --unmanaged=true
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 56s ago 12m count:1
crash 3/3 57s ago 12m *
grafana ?:3000 1/1 56s ago 12m count:1
mgr 2/2 57s ago 3s <unmanaged>
mon 3/5 57s ago 8s <unmanaged>
node-exporter ?:9100 3/3 57s ago 12m *
prometheus ?:9095 1/1 56s ago 12m count:1
# mon 和 mgr 的 PLACEMENT 状态为 <unmanaged>
# 配置主机标签,ceph2 和 ceph3 添加标签" _admin"
[root@ceph1 ~]# ceph orch host label add ceph2.zhu.cloud _admin
Added label _admin to host ceph2.zhu.cloud
[root@ceph1 ~]# ceph orch host label add ceph3.zhu.cloud _admin
Added label _admin to host ceph3.zhu.cloud
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.zhu.cloud 192.168.108.11 _admin
ceph2.zhu.cloud 192.168.108.12 _admin
ceph3.zhu.cloud 192.168.108.13 _admin
3 hosts in cluster
# 将 mon 和 mgr 组件部署到具有_admin标签的节点上
[root@ceph1 ~]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
[root@ceph1 ~]# ceph orch apply mgr --placement="label:_admin"
Scheduled mgr update...
#观察现象
[root@ceph1 ~]# ceph orch ls | egrep 'mon|mgr'
mgr 3/3 2m ago 14s label:_admin
mon 3/3 2m ago 28s label:_admin部署 OSD
bash
# 将所有主机上闲置的硬盘添加为 OSD
[root@ceph1 ~]# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update...验证
查看集群中部署的服务
bash
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 42s ago 2h count:1
crash 3/3 42s ago 2h *
grafana ?:3000 1/1 42s ago 2h count:1
mgr 3/3 42s ago 2h label:_admin
mon 3/3 42s ago 2h label:_admin
node-exporter ?:9100 3/3 42s ago 2h *
osd.all-available-devices 9 42s ago 2h *
prometheus ?:9095 1/1 42s ago 2h count:1查看集群状态
bash
[root@ceph1 ~ 17:08:27]# ceph -s
cluster:
id: bdee4f9e-5996-11f1-8dce-000c294cc7b5
health: HEALTH_OK ##ok
services:
mon: 3 daemons, quorum ceph1.zhu.cloud,ceph2,ceph3 (age 52m)
mgr: ceph1.zhu.cloud.fvwqgp(active, since 52m), standbys: ceph3.nytnqr, ceph2.noelbi
osd: 9 osds: 9 up (since 52m), 9 in (since 2h)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 1 active+clean
#HEALTH_OK:表示健康状态良好
#HEALTH_WARN:表示集群存在告警,需进行排查处理后,可转为HEALTH_OK
#HEALTH_ERR:表示集群存在比较严重的错误,需要立即处理查看集群 osd 结构
bash
[root@ceph1 ~ 17:10:48]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-7 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000
-5 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000查看集群组件
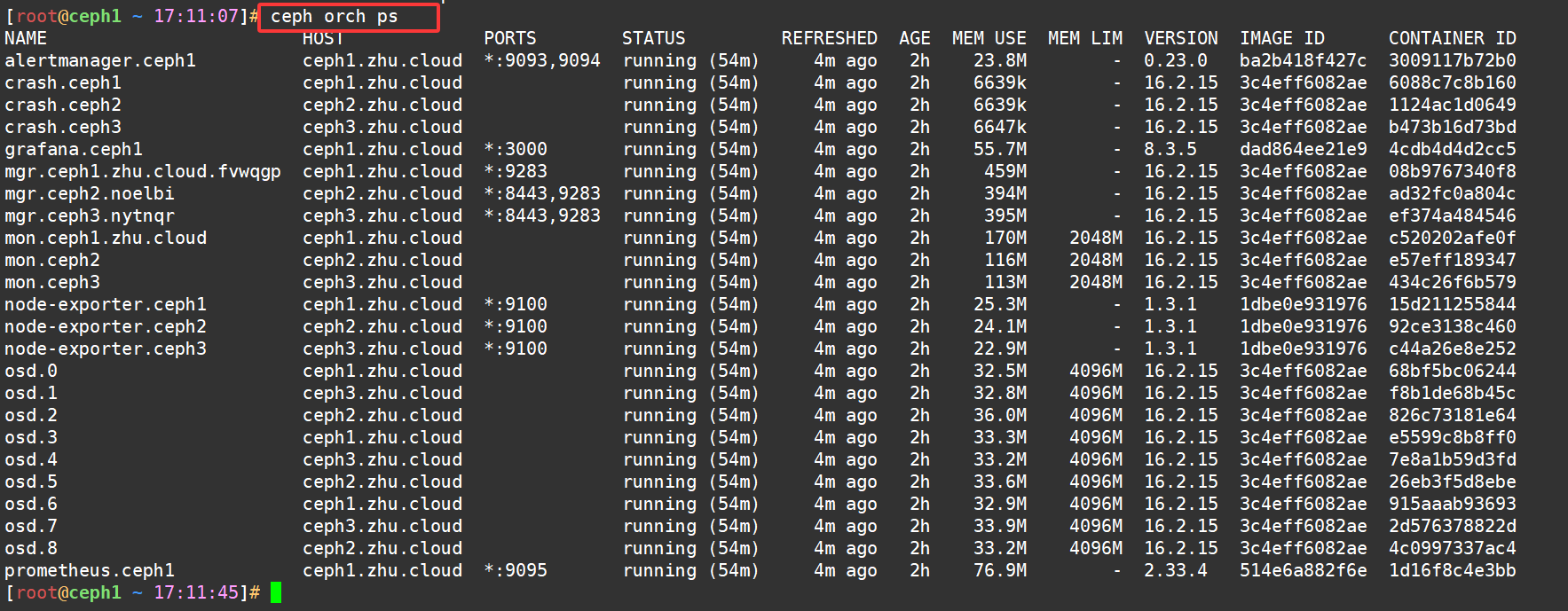
集群中运行的主要组件:
mgr,ceph 管理程序
monitor,ceph 监视器
osd,ceph 对象存储进程
rgw,ceph 对象存储网关
其他组件:
crash,崩溃数据收集模块
prometheus,监控组件
grafana,监控数据展示dashboard
alertmanager,prometheus告警组件
node_exporter,prometheus节点数据收集组件