当数据洪流席卷工业现场,你需要的不只是一个数据库,而是一个能"思考"的数据平台。
一、工业物联网的"数据悖论"
传感器越来越密,采样频率越来越高,数据量呈指数级膨胀------这是当下工业物联网的真实写照。一座大型水电站动辄部署超百万测点,每秒产生的数据量以百万计;一条新能源车产线上的检测设备,年累积实验数据可达万亿级。
然而,企业投入大量资金采集数据后,往往发现真正的问题才刚刚开始:
- 存得下,但查不快:传统数据库面对亿级数据的聚合查询,响应时间动辄数十秒甚至超时;
- 查得出,但算不了:想做振动信号的傅里叶变换、多频传感器数据对齐,不得不借助外部计算平台,链路冗长;
- 算得出,但来不及:从数据采集到异常告警,端到端延迟动辄十几秒,设备故障早已发生。
这就是工业物联网的"数据悖论"------数据越丰富,价值越难以兑现。
二、DolphinDB:不止于存储,更擅于计算
DolphinDB 是浙江智臾科技自主研发的高性能分布式时序数据库,同时也是集存储、计算、流处理于一体的一站式大数据平台。它没有走传统时序数据库"重存储、轻计算"的老路,而是从底层架构出发,将强大的计算能力内嵌到数据库核心。

2.1 极致性能:从写入到查询的全面提速
海量并发写入,稳如磐石。 DolphinDB 采用深度优化的存储引擎(支持 TSDB、OLAP、PKEY、IMOLTP、VECTORDB 等多模引擎),在新能源车企的实际场景中,单集群即可稳定支撑每秒 1.8 亿测点 的不间断写入,写入过程中资源利用率保持在 40% 左右,系统依然从容应对并发查询请求。
PB 级数据,毫秒级响应。 得益于原生分布式架构与向量化计算引擎,DolphinDB 可以轻松扩展至数百节点。在百亿级数据量下,即席查询的响应时间仍在毫秒量级。列式存储结合多种高压缩比算法(LZ4、Delta-of-Delta、CHIMP、字典压缩等),压缩率可达 10:1 甚至更高,大幅降低存储成本。
2.2 流批一体:一套代码,实时与历史兼得
这是 DolphinDB 最具差异化的能力之一。
在传统架构中,实时流处理和历史批处理是两套完全独立的系统------开发两套代码、维护两套环境、调试两套逻辑。DolphinDB 首创流批一体设计,用户在研发环境中基于历史数据编写的分析脚本,无需任何修改即可直接应用于生产环境的实时数据流,且保证计算结果完全一致。
内置的流计算引擎种类丰富,涵盖:
- 时间序列聚合引擎:滑动窗口、累计窗口等时序计算
- 异常检测引擎:毫秒级实时筛查异常数据
- 响应式状态处理引擎:将"连续 N 次超阈值"等复杂告警逻辑抽象为可配置规则
- 横截面处理引擎:对同一时刻的多个实体进行截面分析
- CEP 复杂事件处理引擎:从事件流中检测特定模式并触发动作
- 会话窗口引擎:处理不定长的时间窗口
这些引擎可灵活串联,构建强大的实时计算流水线,实现亚毫秒级的处理延迟。

2.3 全栈计算:2000+ 内置函数,复杂分析库内完成
DolphinDB 内置超过 2000 个经过深度优化的专业函数,覆盖时序处理、统计分析、信号处理、机器学习等领域。
这意味着什么?
过去,要做一个设备的振动频谱分析,需要将数据导出到 Python 环境,调用 SciPy 库,编写数百行代码。而在 DolphinDB 中,只需几行脚本即可在数据库内部直接完成------从数据清洗、特征提取到模型推理,全部在库内闭环,省去了数据搬运的开销和风险。
对于工业 AI 场景,DolphinDB 原生支持 Tensor 数据格式,内置轻量化机器学习推理模块,并可通过 libTorch、xgboost 等插件加载模型进行在线预测,真正实现"数据在哪里,计算就在哪里"。
2.4 多范式编程:简洁灵活,表达力强
DolphinDB 内置图灵完备的编程语言,支持命令式、函数式、向量化、SQL 等多种编程范式。兼容 SQL-92 标准,并在此基础上扩展了组内计算、透视表等高级功能,同时兼容 Oracle 和 MySQL 等主流 SQL 方言。
对于熟悉 SQL 的工程师,上手成本几乎为零;对于追求极致性能的开发者,向量化编程能充分发挥 CPU 算力。
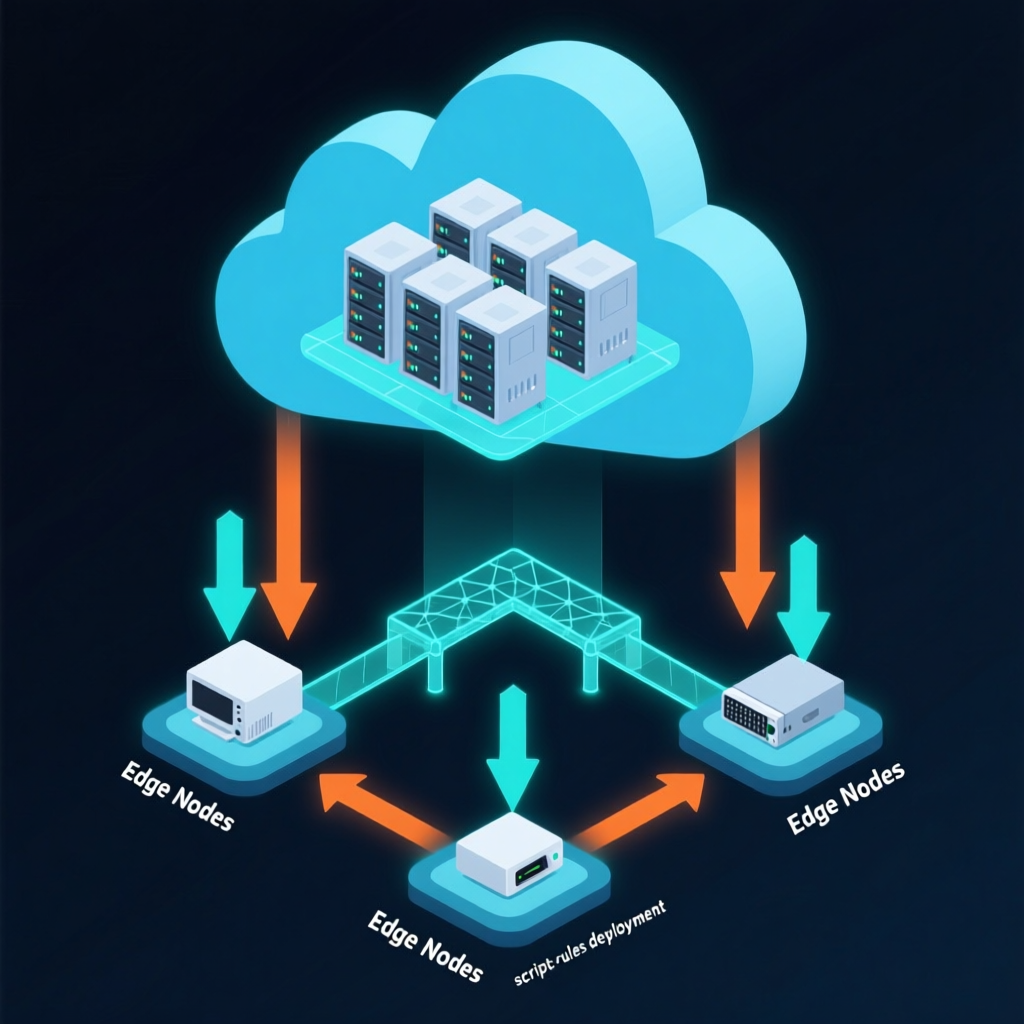
三、云边一体:从边缘到云端的无缝协同
在工业物联网中,边缘端设备往往资源有限、网络条件不稳定,但又要求极高的实时性。DolphinDB 提供了端边云一体架构解决方案:
- 边缘端轻量化部署:部署包仅几十 MB,可在工控机等边缘设备上一键部署,提供存储、分析和实时计算能力;
- 云端全量分析:数据在边缘端预处理后,按需同步至云端,进行跨站点、跨区域的深度分析;
- 云边协同:云端脚本可快速下发至边缘端,便捷实现数据上传、规则下发的双向协同。
某电力监测设备生产商正是利用这一架构,在资源有限的工控机上搭建了变电站振动监控系统。边缘端完成振动数据的降采样和异常波形录制,云端则负责设备运行状态的全局监控与分析,数据存储成本大幅降低。
四、实战淬炼:来自一线的验证
技术好不好,客户说了算。DolphinDB 已经在能源电力、智能制造、核工业、车联网、航空航天等多个行业落地,服务了多家世界 500 强企业。
案例一:百万测点的统一底座------某大型水电企业
某水电企业是中国乃至全球最大的水电上市公司,拥有多个地理位置分散的水电站,面临数据孤岛、实时分析能力不足等挑战。
方案: 基于 DolphinDB 搭建统一工业互联网平台,采用云边协同架构------六大水电站边缘侧部署轻量级节点进行数据预处理,云端进行全量汇聚与深度分析。
成效:
- 百万级水电测点的高并发实时写入与监控计算
- 关键设备故障预警从"分钟级"压缩至"毫秒级"
- 多源数据关联查询响应从分钟级缩短至秒级
- 复杂分析任务处理效率提升 5-6 倍

案例二:核电安全的分析基石------某核工业研究院
某核工业研究院原有基于 MySQL 的工业组态监控体系,随着仪表测点增多和采样频率提高,已无法满足大量数据并发写入、实时查询和聚合计算的需求。
方案: 利用 DolphinDB 替代 MySQL,借助其一站式分析能力与内置机器学习组件,在数据库内直接完成核反应堆运行数据的实时清洗、深度分析与 AI 预测。
成效:
- 单表百亿数据量级下的毫秒级查询响应
- 数据处理与分析效率提升 10 倍
- 无需额外搭建复杂的外部分析体系,大幅降低技术投入
案例三:无人工厂的实时守护------某智能制造企业
某全球领先的智能制造企业,需要搭建统一平台实现产线设备状态数据的实时存储、异常检测和综合生产指标计算。
方案: 仅采用 3 台 4 核 32GB 服务器部署 DolphinDB 集群,利用内置异常检测引擎实时筛查设备状态异常,并通过流计算引擎实现低延时的综合生产指标计算。
成效:
- 实时写入 32.4 万点/秒(双副本),满足产线监控需求
- 百亿数据量级下,高并发即席查询毫秒级响应
- 低延时异常检测引擎降低开发与维护成本
- 高可用架构确保系统持续可用

案例四:车联网大数据平台------某新能源车企
某新能源车企需要搭建车辆信息监控与分析系统,面临每秒 1.8 亿测点的写入压力和单车 7000 测点的大宽表存储需求。
方案: 基于 DolphinDB 构建轻量化车联网大数据处理架构,利用分布式表存储海量轨迹数据,通过流计算引擎实现车辆异常状况的毫秒级预警。
成效:
- 满足每秒 1.8 亿测点不间断写入,支持乱序数据
- 写入过程中单点查询平均耗时 100ms 以内
- 毫秒级异常检测,保障车辆安全

五、开放生态:连接一切,扩展无限
DolphinDB 拥有完整而开放的生态系统:
编程接口: 支持 Python、C++、Java、C#、Go、R、JavaScript、RUST 等主流语言 SDK,无缝对接现有技术栈。
数据采集: 支持 MQTT、OPC UA/DA、Modbus、IEC 104 等工业协议,轻松接入 PLC、DCS 等设备。
插件市场: 提供机器学习(xgboost、svm)、消息队列(Kafka、RabbitMQ、RocketMQ)、云存储(Amazon S3)、信号计算(signal、gurobi)等多种插件,按需扩展。
工具集成: 与 Grafana、SmartBI、帆软、Node-RED、Prometheus、Docker、Airflow 等主流工具深度适配。
信创兼容: 全面支持鲲鹏、飞腾、海光、兆芯、龙芯等国产芯片,以及统信 UOS、银河麒麟等国产操作系统。

六、写在最后:选择正确的数据底座
在工业数字化转型的深水区,企业面临的核心问题已不再是"要不要做实时分析",而是"用什么样的技术底座来做"。
DolphinDB 的价值主张清晰而坚定:
- 一站式:从数据采集、存储、计算到智能分析,一个平台覆盖全链路
- 高性能:千万级写入、毫秒级查询、亚毫秒级流处理
- 低成本:高压缩比存储、存算一体减少数据搬运、流批一体降低开发运维负担
- 易扩展:原生分布式架构,支持水平扩展与云边协同
- 国产自主:完全自主知识产权,信创生态完善
告别烟囱式架构,让工业数据的每一秒都有价值。
如需了解更多或申请试用,请联系 sales@dolphindb.com 或致电 0571-82853925
