传统数字人要么要高配、要么链路复杂,魔珐星云直接把 3D 渲染、语音、表情全部封装,普通笔记本 / 工控机都能流畅跑,3 分钟搞定可交互数字人。

一、传统数字人:门槛太高,新手劝退
- ❌ 云端推视频,延迟 3--5 秒,不能打断
- ❌ 要自己串 TTS、渲染、动作,开发复杂
- ❌ 依赖高配置 GPU,成本高、难落地
一句话:看着炫,上手难。
本质:大模型缺个「会表达的 3D 身体」。
二、魔珐星云:端侧渲染,新手友好
核心是参数流 + 端侧渲染:
- ✅ 不传视频,只传 KB 级参数,带宽无压力
- ✅ 端侧实时渲染,集成显卡 / 百元开发板流畅跑
- ✅ 极简 API,3 行代码接入,零依赖
三、 3 分钟实战
3.1 初识星云控制台:创建的是「具身驱动应用」,用于构建可实时交互的具身智能体
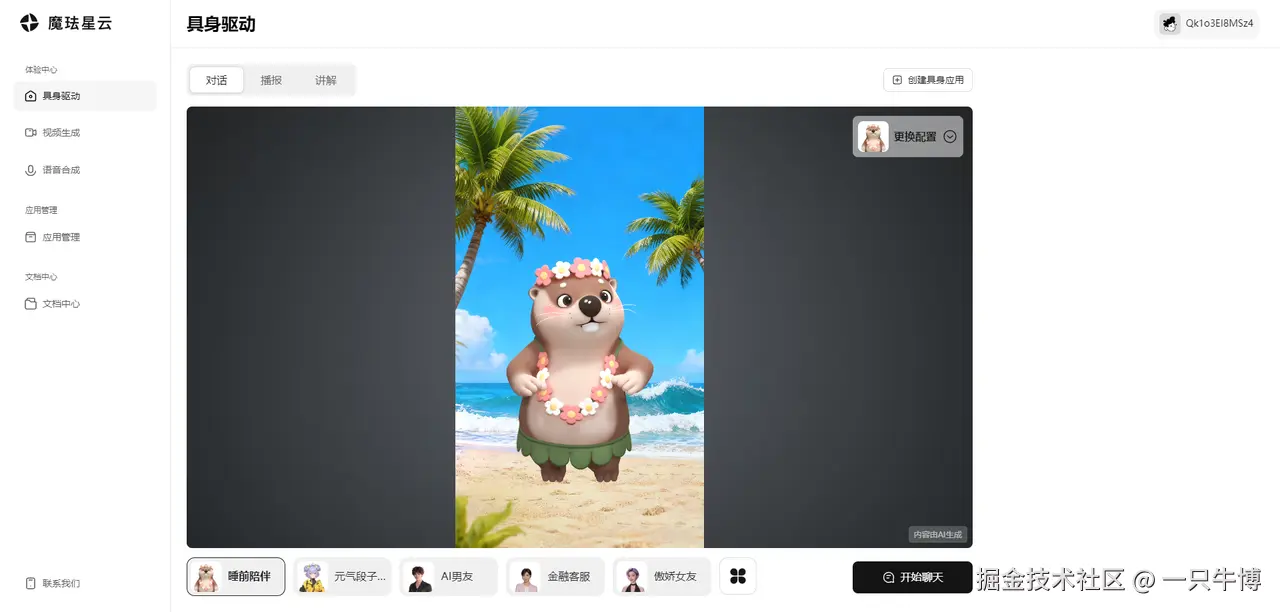
登录魔珐星云控制台,你会发现核心概念不是"上传模型",而是创建应用 。你在这里"培植"的是一个可被API实时驱动的智能体实例,而非一段多媒体文件。
3.2 3分钟极速集成:感受"底座"的易用性
魔珐星云提供了极简的HTML集成方案。只需几行代码,即可让数字人"活"起来:
xml
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>我的第一个数字人</title>
<style>
#avatar-container {
width: 800px;
height: 450px;
position: relative;
}
#sdk {
width: 100%;
height: 100%;
}
</style>
</head>
<body>
<div id="avatar-container">
<div id="sdk"></div>
</div>
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script>
const sdk = new XmovAvatar({
containerId: "#sdk",
appId: "你的AppID",
appSecret: "你的AppSecret",
gatewayServer: "",
onMessage: (message) => {
console.log("SDK message:", message);
},
});
sdk.init({
onDownloadProgress: (progress) => {
console.log("资源下载进度:", progress + "%");
},
});
</script>
</body>
</html>关键认知:魔珐星云不是传统数字人方案,而是可编程的具身驱动引擎,可直接构建端到端具身智能体。开发者只需关注业务逻辑,无需关心底层的3D渲染和语音合成。
四、实战:大模型 + 数字人联动
4.1 环境准备与配置
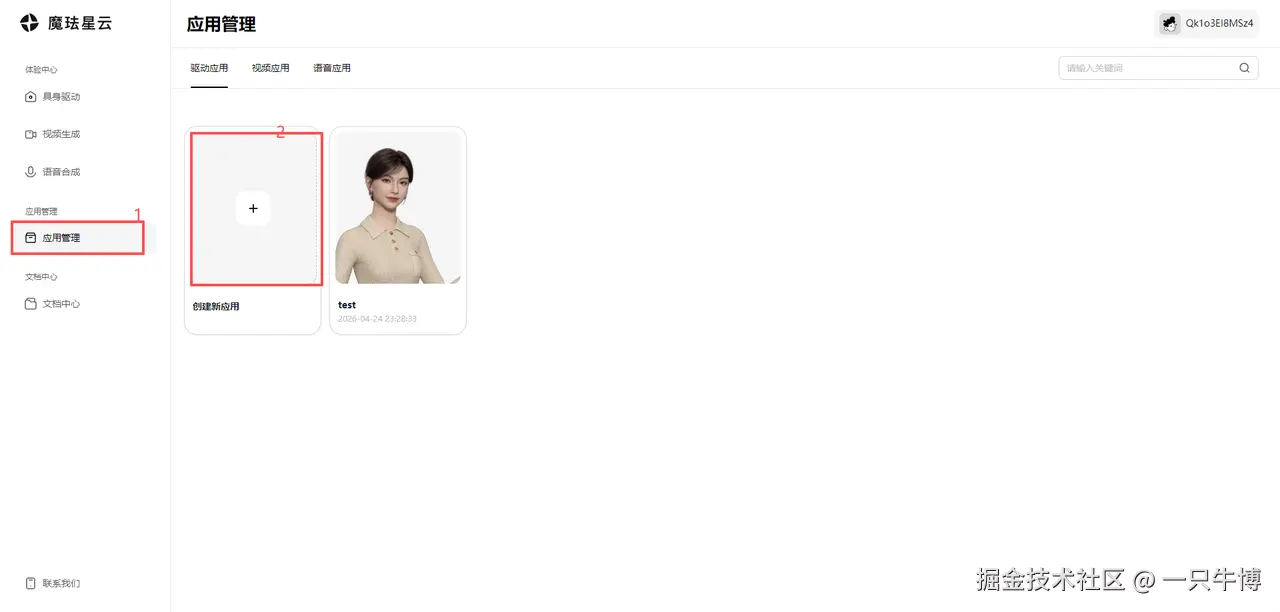
步骤1:创建应用
- 登录魔珐星云控制台(xingyun3d.com)
- 创建具身驱动应用,选择适合的形象和场景
- 获取AppID和AppSecret
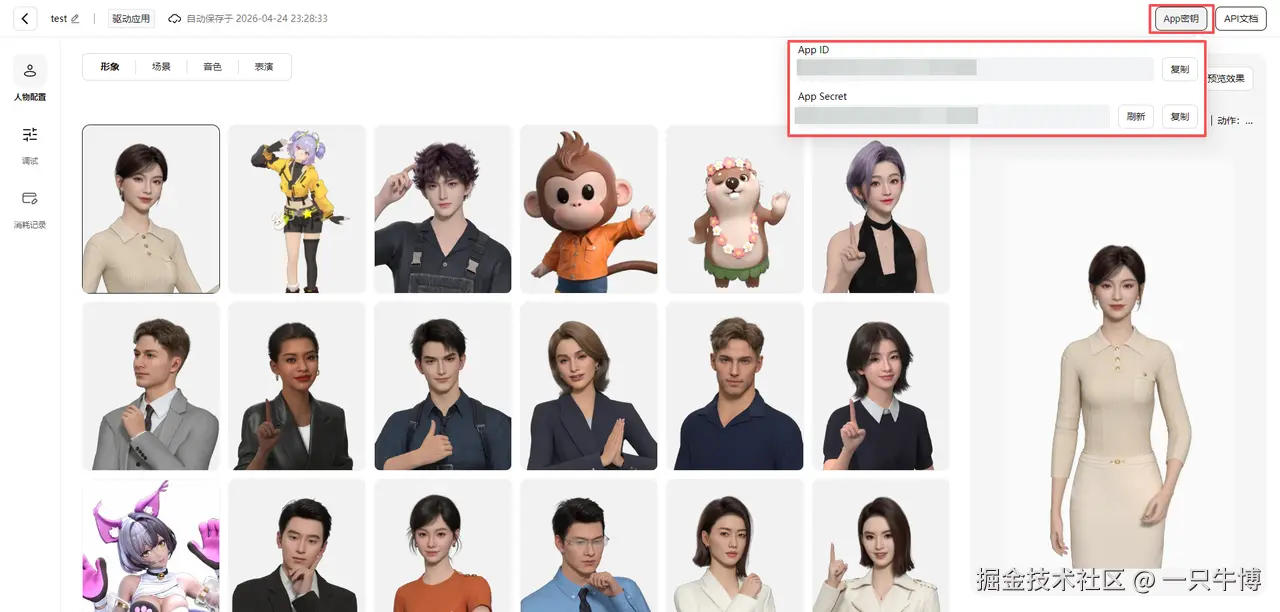
步骤2:使用官方Demo快速验证
H5部署不显示(仅作记录)
xml
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<!-- 页面标题 -->
<title>我的第一个数字人</title>
<style>
<!-- [关键配置] 容器比例需与您在控制台选择的"应用类型"保持一致 -->
#avatar-container {
width: 800px;
height: 450px;
position: relative;
}
<!-- 定义数字人呈现的容器样式 -->
#sdk {
width: 100%;
height: 100%;
}
</style>
</head>
<body>
<!-- 定义SDK容器 -->
<div id="avatar-container">
<!-- 数字人将在此容器中显示 -->
<div id="sdk"></div>
</div>
<!-- 引入魔珐星云数字人SDK -->
<!-- 初始化SDK -->
<script>
// 创建XmovAvatar SDK实例
const sdk = new XmovAvatar({
// 指定数字人渲染的容器ID(CSS选择器格式)
containerId: "#sdk",
// 魔珐星云具身驱动应用App ID(用于身份验证)
appId: "xxxxxxxx",
// 魔珐星云具身驱动应用App Secret(用于身份验证)
appSecret: "xxxxxxxx",
// 数字人模型资源网关服务器地址
gatewayServer: "https://nebula-agent.xingyun3d.com/user/v1/ttsa/session",
// 数字人消息通知回调函数
onMessage: (message) => {
console.log("SDK message:", message);
},
});
// 初始化SDK实例并设置回调函数
sdk.init({
// 资源下载进度回调函数
onDownloadProgress: (progress) => {
console.log("资源下载进度:", progress + "%");
},
});
</script>
</body>
</html>Vue 3 + TypeScript
为了确保最佳兼容性,我们使用魔珐官方提供的JS Demo(基于Vue 3 + TypeScript,因为H5大多数浏览器不显示数字人):
bash
# 克隆Demo仓库
git clone https://gitee.com/xmovmaster/XmovLiteAvatarJSDemo.git
# 安装依赖
cd XmovLiteAvatarJSDemo
npm install
# 启动开发服务器
npm run dev
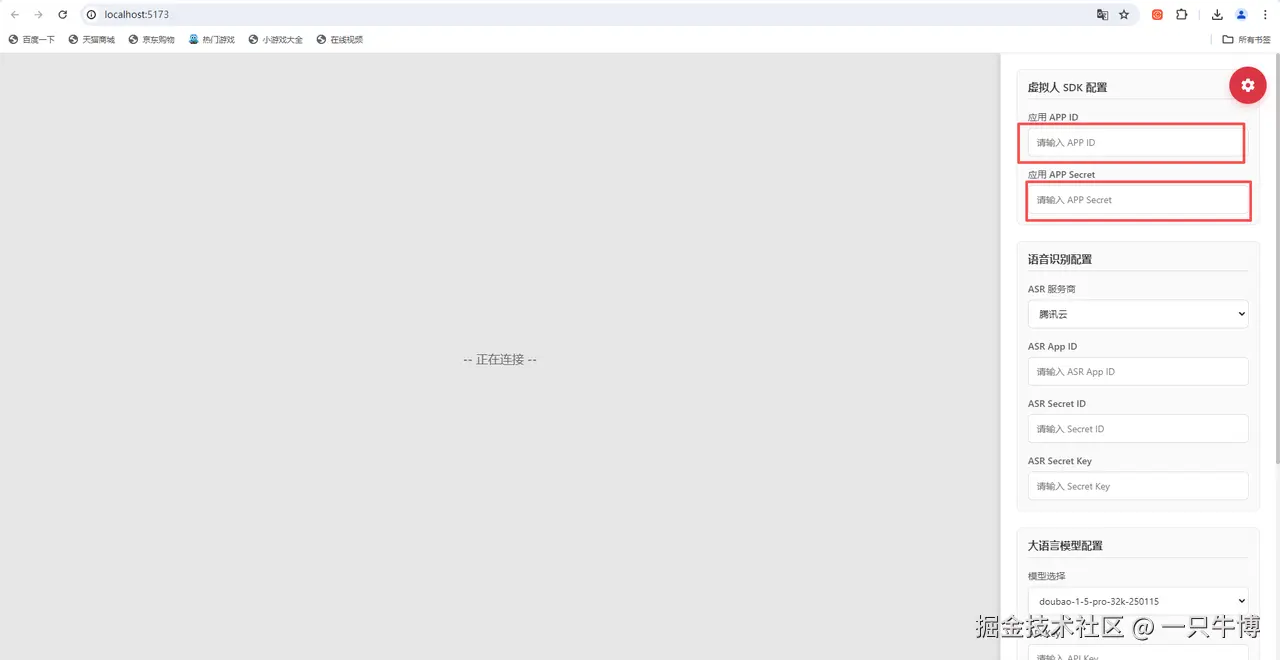
步骤3:配置密钥
在Demo的配置面板中填入你的AppID、AppSecret,以及腾讯云ASR配置(用于语音识别)和LLM配置(用于智能对话)。
4.2 核心代码解析:从"能说"到"会思考"
Demo的核心逻辑在src/stores/app.ts中,实现了"语音输入 → LLM处理 → 数字人播报"的完整闭环:
csharp
// 发送消息给LLM并驱动数字人播报
async function sendMessage(content: string) {
// 1. 调用LLM获取回复(流式)
const replyStream = await llmService.sendMessageWithStream(content);
// 2. 智能分句处理
const sentences = splitSentence(replyStream);
// 3. 逐句推送给数字人播报
for (const sentence of sentences) {
await avatar.speak(sentence);
}
}技术亮点:
- 流式处理:LLM回复无需等待完整生成,实现"边想边说"的低延迟体验
- 智能分句:自动识别中英文标点,确保播报自然流畅
- 多模态同步:语音、表情、口型自动匹配,无需手动对齐
4.3 效果验证
运行项目后,你将看到:
- 数字人实时渲染在浏览器中
- 点击"语音输入"可进行实时对话
- 数字人会根据LLM的回复内容自动播报,表情和口型自然匹配
五、 技术解构:星云如何用"参数流"架构破解难题
5.1 传统方案为什么"重"?
传统方案需要开发者自己串联多个系统:
LLM → TTS → 3D渲染引擎 → 动作引擎 → 屏幕每个环节都有延迟,且需要处理复杂的同步问题。
5.2 星云的"端侧渲染+参数流"架构
魔珐星云采用 "云端理解-本地表达" 的三层架构:
- 云端大脑:处理LLM推理和语义理解
- 参数流传输:只传输轻量的驱动参数(文本、情感、动作指令)
- 端侧渲染:在终端设备上实时合成语音和3D动画
核心优势:
- 低延迟:参数流仅几KB,传输极快
- 高并发:云端不传输视频流,支持高并发、万级以上并发
- 低成本:百元级芯片即可运行,无需昂贵GPU集群
六、 测评总结:这是"基础设施"该有的样子
经过实战验证,魔珐星云确实配得上"AI屏幕操作系统"的称号:
6.1 实际体验优势
| 对比维度 | 传统数字人方案 | 魔珐星云 |
|---|---|---|
| 开发周期 | 数周~数月(需要自建渲染/动作/语音链路) | 最快1小时内完成demo接入,大幅降低开发周期 |
| 交互延迟 | 1-2秒(云端视频流渲染,无法随时打断) | 端到端约500毫秒低延时,支持随时打断 |
| 部署成本 | 依赖自建GPU集群或云端渲染服务,成本高 | 端测AI渲染,百元芯片即可运行,按需调用成本可控 |
| 终端适配 | 对设备/浏览器系列要求高,兼容性受限 | 跨端适配web、 App、大屏等终端,支持国产信创 |
6.2 适合谁用?
- 开发者:快速为应用添加拟人化交互界面
- 企业:将现有的信息屏、一体机升级为智能服务点
- 终端厂商:让任何屏幕都具备AI交互能力
6.3 生态展望
魔珐星云定义了"表达层"的标准,正如Android定义了移动应用的标准。它让构建"具身智能应用"变得像开发网页一样简单,这可能是具身智能规模化最快的路径。魔珐星云不是另一个数字人工具,它是让AI真正拥有"身体"的基础设施。 从"会思考"到"能表达",我们刚刚迈出了第一步。
你给大模型做过具身交互吗?用在客服、导览还是陪练?评论区聊聊你的场景~
魔珐星云体验入口: