这篇名为 《Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation》 的论文由 Meta AI、香港大学和滑铁卢大学的研究人员合作发表。
该论文提出了一项极具颠覆性的研究成果:在构建原生的统一多模态模型(UMM)时,完全抛弃了传统的预训练视觉编码器(如 CLIP、SigLIP)和变分自编码器(VAE),证明了直接基于像素嵌入(Pixel Embeddings)进行端到端训练,能够在多模态理解和生成任务上达到甚至超越现有依赖复杂组件的SOTA(State-of-the-Art)模型。
首先看TUNA,TUNA 所使用的理解和生成的 Unified Representation,是用 VAE 接一个 Representation Encoder (文中使用 SigLIP 2) 得到的。作者借助 Representation Encoder 从 VAE latents 里面抽语义特征。然后,把这个特征当作 Visual Representation,参与统一模型的训练。
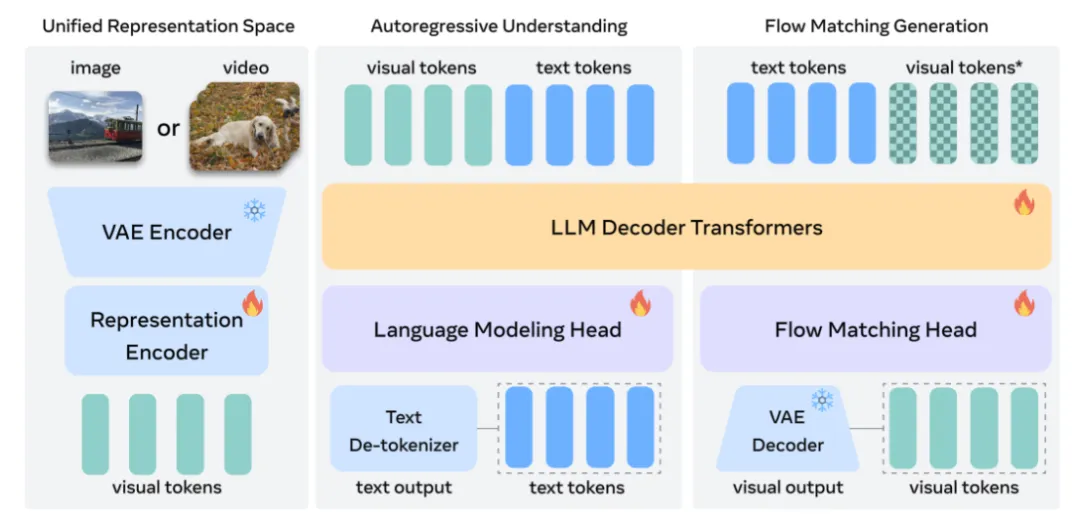
TUNA 架构。把一个 VAE 串接一个 Representation Encoder,抽取视觉特征。TUNA 是一个非常典型的理解生成统一模型,自回归方式生成文本,Flow Matching 方式生成图像或者视频。
TUNA 是一个非常典型的理解生成统一模型,自回归方式生成文本,Flow Matching 方式生成图像或者视频。Attention Mask 的设计也跟统一模型的惯例保持一致:
- language token 之间:一直 causal mode。
- visual token 之间:一直 bidirectional mode。
- visual token 与 language token:生成时:text 看不到 visual,(noised) visual 可以看到 text;理解时:text 看得到 visual,visual 看不到 text。
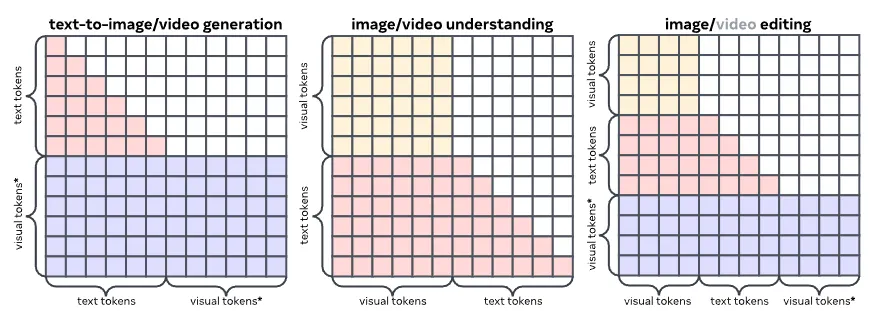
TUNA 的 Attention Mask 设计。* 代表 visual token 加噪
TUNA架构能训起来需要3个阶段:
- 训练 Representation Encoder 和 Flow Matching head: 使用的训练目标是 image captioning 和 T2I 生成。
- 训练整个模型: 使用的训练目标依然是 image captioning 和 T2I 生成。在最后的 training steps 里面,引入 image instruction-following, image editing, 和 video-captioning。
- SFT: 引入 image editing, image/video instruction-following, 以及高质量 image/video 生成。
TUNA 使用 VAE 和 Representation Encoder 建模视觉表征。TUNA-R 去掉了 VAE,只保留了 Representation Encoder。TUNA-2 把 Representation Encoder 替换为了 Patch Embedding 层。
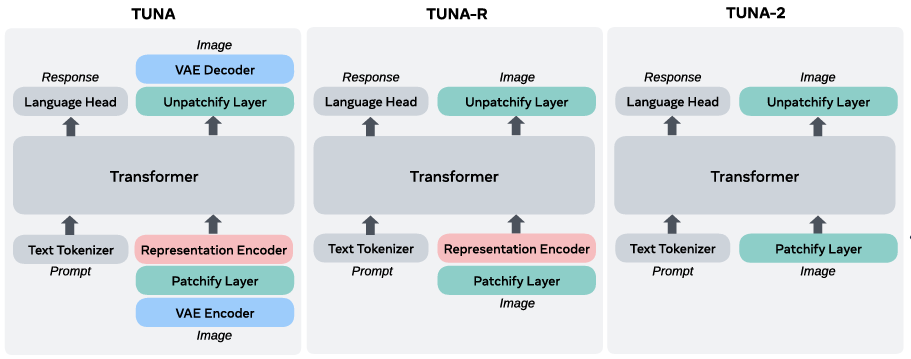
TUNA-2 架构与前代的对比。作者逐步把 TUNA 的 vision encoder 进行简化,一步步变成 TUNA-2。中间过程 TUNA-R 只保留了 representation encoder,去掉了 VAE
1. 研究背景与核心痛点
当前的范式:
目前,希望同时实现"看图说话"(视觉理解)和"文生图"(视觉生成)的统一多模态模型(UMM),通常依赖于模块化设计。它们高度依赖预训练的视觉组件:
- 表征编码器(Representation Encoder, 如 CLIP/SigLIP): 用于提取图像的语义特征以进行理解。
- 变分自编码器(VAE): 用于将图像压缩到隐空间(Latent Space),以降低扩散模型/流匹配的生成难度(如 Stable Diffusion 的做法)。
存在的痛点:
- 模态不对齐与次优解: 理解和生成使用不同的视觉表征,导致任务之间存在"错位",无法实现从原始像素出发的完全端到端优化。
- 信息丢失: VAE 和表征编码器在压缩图像时,会丢失大量细粒度的底层视觉细节,这对于需要精确感知的任务(如OCR、极小物体识别)非常不利。
论文的疑问与目标:
我们能否彻底摆脱预训练的视觉编码器,直接从原始像素的端到端学习中构建强大的统一多模态模型?
2. 模型架构演进:从 Tuna 到 Tuna-2
论文通过"做减法"的方式,展示了模型架构的演进:
- Tuna(前作): 依赖 VAE 进行隐空间生成,并使用表征编码器进行理解。
- Tuna-R(过渡版本):
- 去除了 VAE,改在像素空间(Pixel-space)直接进行流匹配(Flow Matching)生成图像。
- 但保留了表征编码器(SigLIP 2)来提取视觉特征喂给大语言模型(LLM)。
- Tuna-2(最终版本 - 极简架构):
- 彻底去除了表征编码器和 VAE。
- 使用极其简单的 Patchify Layer(线性块嵌入层) 将原始图像像素直接切块并转化为 Token。
- 这些视觉 Token 和文本 Token 一起输入到一个单一的 Transformer 解码器(基于 Qwen2.5-7B)中进行联合处理。
- 输出端:语言头(Language Head)负责自回归生成文本;流匹配头(Flow Matching Head)负责直接在像素空间生成干净的图像。
3. 核心技术与训练策略
为了让这种"没有预训练视觉先验"的极简架构生效,论文引入了几个关键技术:
A. 像素空间流匹配(Pixel-space Flow Matching)
去掉了 VAE,意味着不能再做隐空间扩散。Tuna-2 采用了直接在原始像素上预测干净图像(x-prediction)并回归速度场(v-loss)的方法。
B. 基于掩码的特征学习(Masking-based Feature Learning)
这是训练成功的关键。 像素空间维度极高且充满冗余信息,模型很容易学到"捷径"而非真正的语义。为此,作者引入了掩码机制(类似 MAE):
- 在生成任务中: 随机遮挡部分噪声图像,要求模型预测完整的干净图像。这迫使模型学习上下文关系,而不是单纯的局部去噪。
- 在理解任务中: 让模型看着被遮挡的图像来回答问题(生成文本)。这作为一种正则化手段,迫使模型进行更深度的多模态推理,学出更鲁棒的像素级表征。
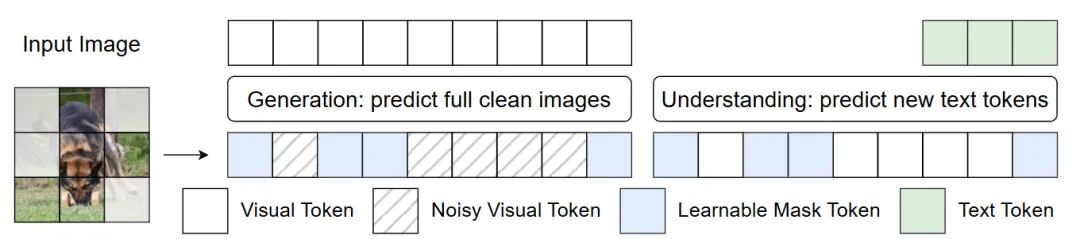
在理解和生成中对图像做随机 Masking
C. 训练流水线(完全端到端)
- 阶段一(全模型预训练): 使用图文对(Captioning)和文生图(T2I)数据,联合训练 LLM 和流匹配头,建立视觉和语言的初始对齐。(注:最佳的数据采样比例是 生成7 : 理解3)。
- 阶段二(监督微调 SFT): 使用高质量的指令跟随、图像编辑和高保真生成数据进行微调,提升各项具体能力。
4. 实验结果与核心发现
论文在大量基准测试上对比了 Tuna-2、Tuna-R 和其他原生 UMMs,得出了几个令人振奋的结论:
A. 视觉理解:像素级嵌入完胜,尤其在细粒度任务上
- Tuna-2 在 7B 参数规模的统一模型中取得了 SOTA 的成绩。
- 重大发现: 尽管 Tuna-2 没有任何预训练视觉编码器,但它的理解能力超越了保留编码器的 Tuna-R。
- 尤其是在需要精细视觉感知的"像素级基准测试"(如 V* 寻找微小物体、CountBench 计数、OCRBench 文本识别)上,Tuna-2 优势明显。这证明抛弃 VAE/编码器避免了底层信息的丢失。
B. 视觉生成:与隐空间模型平分秋色
- 即使没有 VAE,Tuna-2 依然能生成高质量、高保真度的图像,且在指令图像编辑(ImgEdit)上表现出色。
- 相比于 Tuna(使用 VAE),Tuna-2 生成的图像具有更好的多样性。
C. 训练动态学(Training Dynamics):先验 vs. 规模
论文进行了一个非常深刻的对比分析:
- 训练初期: 带有预训练编码器的 Tuna-R 学得更快,因为 SigLIP 赋予了它丰富的先验语义知识。
- 随着数据规模扩大: 无编码器的 Tuna-2 实现了反超。这表明:单体、无编码器的原生架构,在经过大规模多模态预训练后,能够发展出比拼接模块更强的多模态理解能力。上限更高。
D. 注意力机制更精准
可视化分析显示,由于是在像素空间端到端训练,Tuna-2 的注意力图(Attention Map)非常精准。它不容易被文本提示中的误导性词汇或图像中显眼的干扰物欺骗,展现出极强的鲁棒性。

5. 总结与意义
《Tuna-2》的里程碑意义在于:
它打破了多模态大模型领域的思维定势(即"必须用 CLIP 提特征,必须用 VAE 降维")。它证明了:
- 预训练视觉编码器对于多模态建模并非必需。
- 端到端的像素空间学习(Pixel-space learning)提供了一条可扩展的道路。 只要有足够的训练和巧妙的策略(如 Masking),大语言模型可以直接从原始像素的 Patch 中自己学到卓越的理解和生成能力。
这为未来开发更简洁、更原生的多模态通用大模型(Native UMMs)指明了新的发展方向,极简 Transformer 架构完全具备统治多模态领域的潜力。