概述
GDR含义
GPUDirect RDMA是GPU direct技术体系的一部分,用于跨机或者跨机柜级别的GPU互联通信的加速。GPUDirect RDMA主要是利用PCIe p2p的技术将GPU的内存暴露给RDMA网络设备进行data transfer,将传统通过系统内存的RDMA操作bypass掉,避免GPU mem和host mem之间的mem copy。
发展
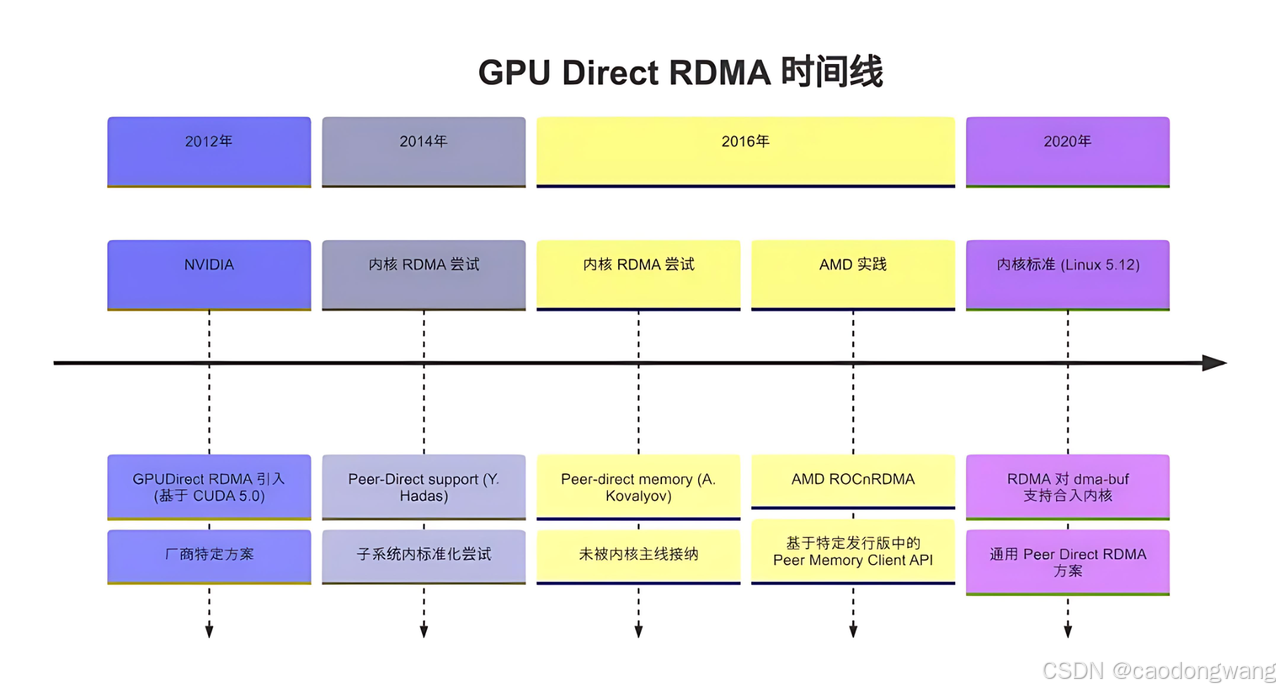
在早期版本的GPUDirect,数据依然需要在RDMA网卡和GPU显存之间经由系统内存进行中转,如下图所示。
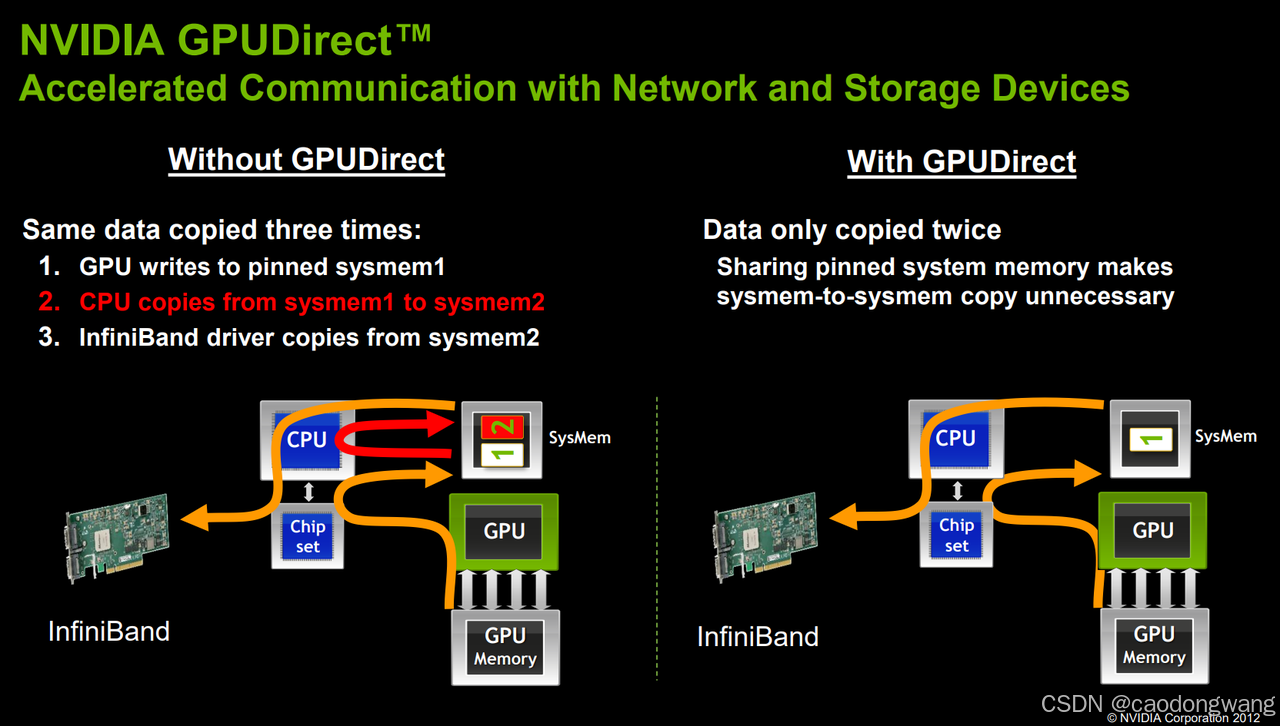
在认识到CPU中转和内存拷贝是GPU加速计算的主要性能障碍后,NVIDIA公司率先着手解决这一问题,启动了GPUDirect技术项目,旨在优化GPU与系统中其他设备(包括其他 GPU 或 I/O 设备)之间的数据传输路径,也就是后续的GDR、GDS、GDA等技术。
早期的GPUDirect进一步迭代就有了GPUDirect RDMA技术,也就是GDR,如下图所示。
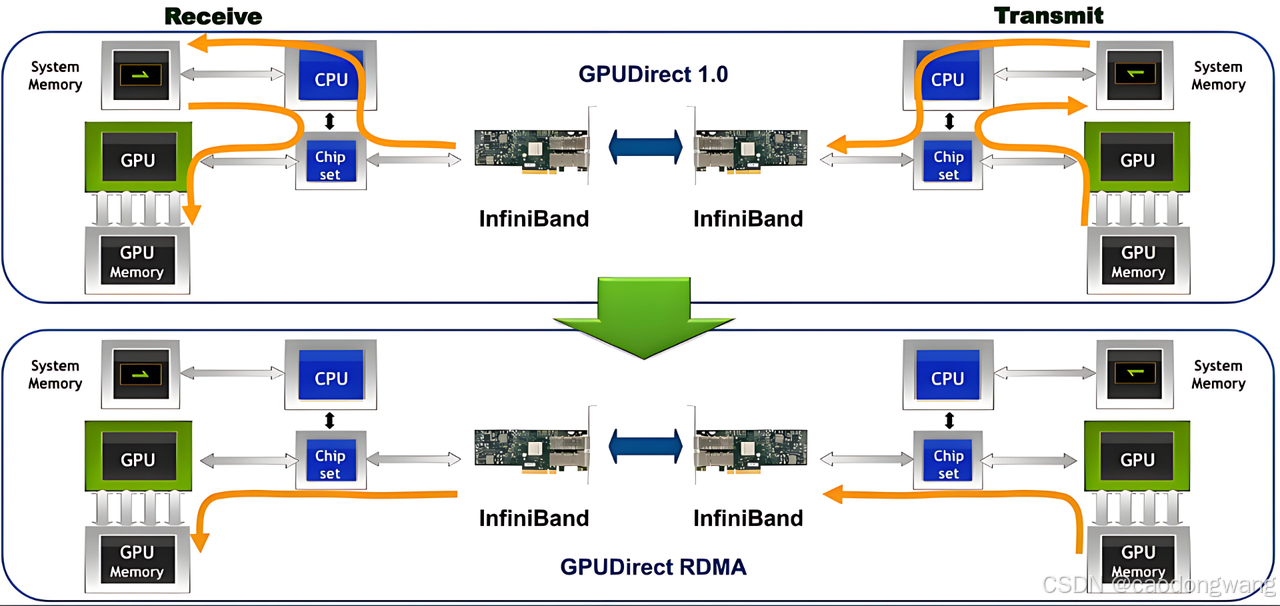
想要实现
GPUDirect RDMA技术,其关键在于让 RDMA 网卡的 DMA 引擎能够理解并访问 GPU 的物理内存地址。
GDR实现探索
Mellanox
Mellanox的开发者提出了一些基于Peer Memory Client API的提案,比如Peer-Direct support和 Peer-direct memory。
这些提案的核心思想是:
-
建立一个注册机制:管理
P2P可访问内存的设备驱动(如GPU驱动)可以通过ib_core提供的ib_register_peer_memory_clientAPI,将自身注册成为一个Peer Memory Client。 -
提供地址翻译回调: 这些
Peer Memory Client的实现需要提供一组回调函数。其中一个关键的回调函数get_pages, 使得RDMA驱动在需要访问对等内存(如GPU显存)时,能将传入的设备虚拟地址翻译成为该地址对应的、可供RDMA网卡DMA使用的物理地址列表。
这个提案旨在RDMA框架内解决P2P内存注册的核心问题:地址翻译。这种设计直接解决了在ibv_reg_mr流程中处理非系统内存的痛点,对RDMA开发者来说是很友好的。
然而,这套在RDMA子系统ib_core内部提供Peer Memory Client API的方案却最终未能合并到Linux内核主线,最主要的原因在于其缺乏通用性。P2P DMA的需求并不仅限于RDMA,图形(DRM)、视频(V4L2)、存储等其他子系统同样存在设备间直接内存共享的需求。
AMD
Linux内核主线最终拒绝了在RDMA子系统ib_core内实现的Peer Memory Client API。 然而,这套API框架实际上已通过特定的RDMA发行版(例如某些OFED版本)得以应用,证明这套API是可用的。
既然linux内核没法立即满足GPU与RDMA网卡间高效P2P通信的强烈需求,那其他GPU厂商也开始投入Peer Memory Client API的怀抱。
AMD为了给 ROCm (Radeon Open Compute platform) 计算平台提供类似NVIDIA GPUDirect RDMA的功能,以便在高性能计算场景下与RDMA网络高效配合。AMD基于Peer Memory Client API 实现了ROCnRDMA(后来合入ROCK项目并集成在amdkfd驱动中的P2P支持当中)。通过实现Peer Memory Client接口,AMD的软件栈能够与RDMA子系统对接,使得RDMA子系统能够查询并获取GPU显存的物理地址信息,进而用以配置RDMA网卡进行直接DMA操作。
linux内核
经过对Peer Memory Client等特定子系统内方案的探索和讨论,Linux内核社区最终将目光投向了一个已有的、更为通用的框架 ------ dma-buf,将其作为实现RDMA网卡和设备(包括GPU)之间P2P DMA的标准机制。这份提案最终在Linux 5.12版本加入。
dma-buf完美契合了P2P DMA的需求:
-
真正的通用性与标准化:
dma-buf是独立于特定子系统的内核标准框架,已被GPU、多媒体等多个驱动广泛采用。将其用于RDMA P2P符合内核寻求通用解决方案的理念,避免了Peer Memory Client方案绑定ib_core的问题。 -
无需
struct page依赖:dma-buf通过map_dma_buf操作允许导出器直接提供sg_table,无需依赖与普通系统内存关联的struct page结构。 -
用户空间友好:基于
fd的接口便于用户空间应用程序管理和传递缓冲区句柄。 -
解耦与灵活性:
RDMA驱动与GPU驱动通过标准接口交互,降低耦合度。dma_buf_ops提供了足够的灵活性,允许导出器根据其内存特性实现具体逻辑。
唯一的劣势就是对linux内核版本有要求 ------ linux 5.12 及以上。
原理
目前GDR主流实现就两种:Peer Memory Client方案和dma-buf方案。
看看NVIDIA官网中对比,如下图所示。

大多数GPU厂商都默认会支持dma-buf,因为主机内GPU之间buf导出导入的实现方式之一就是dma-buf。
dma-buf
dma-buf核心工作模式基于"导出器"(Exporter)和"导入器"(Importer):
-
导出器 (
Exporter):拥有内存缓冲区的设备驱动(如GPU驱动)可以将这块内存导出为一个dma-buf对象,并生成一个用户空间可见的文件描述符(fd)作为句柄。导出器需要实现一套dma_buf_ops回调函数。 -
导入器 (
Importer):需要访问该缓冲区的另一个设备驱动(如RDMA网卡驱动)可以通过这个fd导入该dma-buf对象,并调用导出器实现的dma_buf_ops来操作缓冲区。 -
关键操作 (
map_dma_buf):dma_buf_ops中最关键的操作之一是map_dma_buf。当导入器调用它时,导出器负责提供将该缓冲区映射到导入器设备地址空间所需的信息,通常是以struct sg_table(包含物理地址或总线地址列表)的形式。
linux内核在5.12版本中为ib_core增加了dma-buf支持,也就是为RDMA子系统增加了作为导入器的能力。
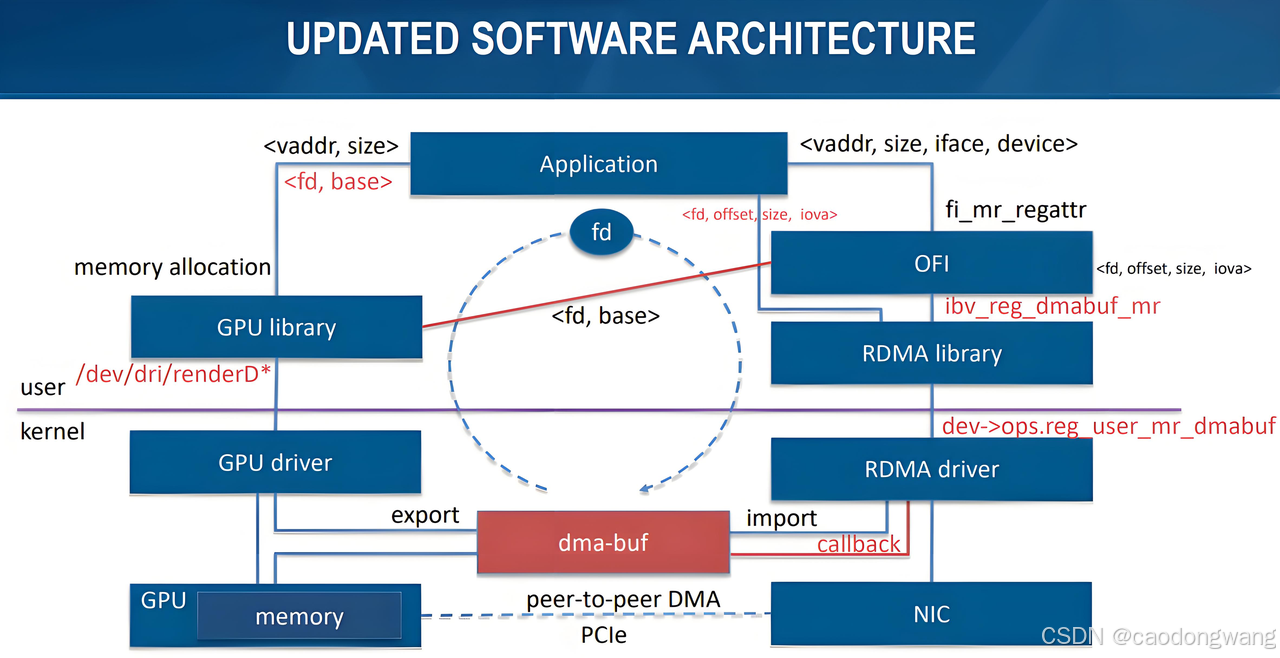
与正常接口接口的差异:
c++
正常接口
struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd,
void *addr,
size_t length,
int access);
dma-buf接口多了dma-buf的fd
struct ibv_mr *ibv_reg_dmabuf_mr(struct ibv_pd *pd,
uint64_t offset,
size_t length,
uint64_t iova,
int fd,
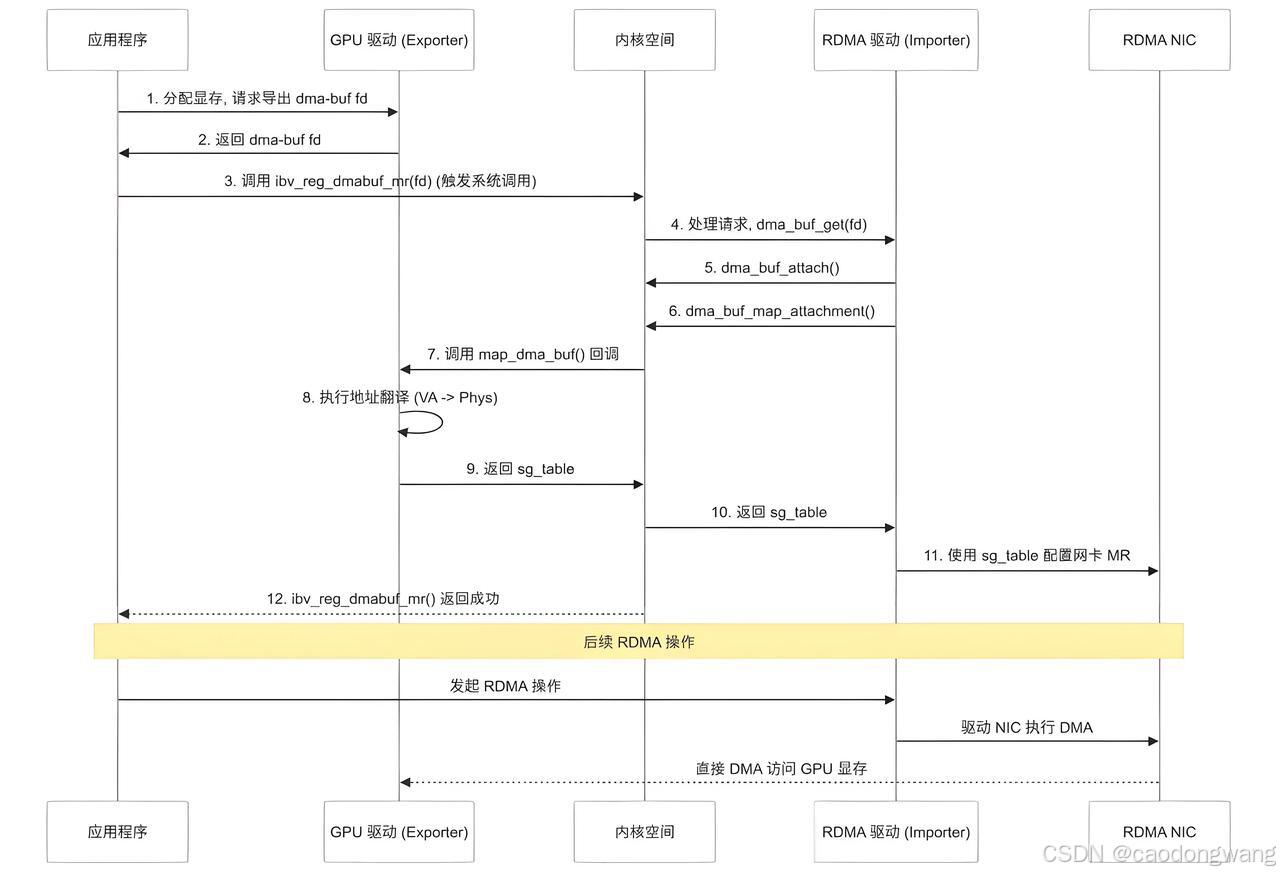
int access) 典型工作流程如下:
-
GPU 端导出: 应用程序使用
GPU厂商提供的API(如CUDA中cuMemAlloc()、ROCm中hipMalloc())分配GPU显存,并调用相应的API(例如 CUDA 中的cuMemGetHandleForAddressRange()或ROCm中的hsa_amd_portable_export_dmabuf())将这块显存导出为一个dma-buf文件描述符fd。底层的GPU驱动负责创建dma-buf对象并实现相应的dma_buf_ops。 -
用户空间传递 dma-buf fd: 应用程序通过
RDMA用户库提供的新接口ibv_reg_dmabuf_mr()将获取到的dma-buf_fd传递给内核。 -
内核 RDMA 驱动处理 dma-buf fd: 用户库接口会通过系统调用触发内核中
RDMA驱动实现的reg_user_mr_dmabuf函数回调,并将dmabuf_fd传递进去。 -
内核 RDMA 驱动映射:
-
RDMA驱动接收到dma-buf_fd,调用dma_buf_get()将其转换为内核struct dma_buf *。 -
调用
dma_buf_attach()将设备attach到dma-buf。 -
调用
dma_buf_map_attachment()。这个调用会触发导出器(GPU驱动)实现的map_dma_buf回调函数。 -
GPU驱动在其map_dma_buf实现中,执行内部的地址翻译(GPU VA -> PCI域地址),并将结果以struct sg_table的形式返回给RDMA驱动。 -
RDMA驱动使用这个sg_table来创建内存区域 (MR) 并配置到RDMA网卡的MRCTX当中。
-
-
执行 P2P RDMA 操作:
MR创建成功后,应用程序即可使用此MR发起RDMA操作,网卡将直接访问GPU显存。
dma-buf为Linux内核中的GPUDirect RDMA提供了一条标准化的实现路径。它通过通用的缓冲区共享机制,使得不同厂商的GPU和RDMA网卡能够以统一的方式协同工作,实现了绕过CPU和系统内存的直接数据传输。
实现
以Mellanox实现接口为例,简单看看ibv_reg_dmabuf_mr函数调用过程。
c
cuMemAlloc(&d_A, buf_size);
cuMemGetHandleForAddressRange(
(void *)dmabuf_fd,
(void *)d_A, buf_size,
CU_MEM_RANGE_HANDLE_TYPE_DMA_BUF_FD,
CU_MEM_RANGE_FLAG_DMA_BUF_MAPPING_TYPE_PCIE);
mr = ibv_reg_dmabuf_mr(pd,
offset,
size,
(uint64_t)d_A,
dmabuf_fd,
IBV_ACCESS_LOCAL_WRITE |
IBV_ACCESS_REMOTE_WRITE |
IBV_ACCESS_REMOTE_READ);
1.ibv_reg_dmabuf_mr -> mlx5_reg_dmabuf_mr -> ibv_cmd_reg_dmabuf_mr -> execute_ioctl -> ioctl (内核态 ib_uverbs_ioctl)
2.ib_uverbs_ioctl 调用 UVERBS_METHOD_REG_DMABUF_MR 方法,即 ib_uverbs_handler_UVERBS_METHOD_REG_DMABUF_MR 函数
3.ib_uverbs_handler_UVERBS_METHOD_REG_DMABUF_MR 调用 .reg_user_mr_dmabuf 回调函数,即 mlx5_ib_reg_user_mr_dmabuf
4. mlx5_ib_reg_user_mr_dmabuf -> ib_umem_dmabuf_get
和dmabuf相关接口实现
ib_umem_dmabuf_get
-> dmabuf = dma_buf_get(fd);
-> umem_dmabuf->attach = dma_buf_dynamic_attach(dmabuf, ...);
dma_buf_dynamic_attach
-> dmabuf->ops->attach(dmabuf, attach);
-> attach->dmabuf = dmabuf;
ib_umem_dmabuf_map_pages
-> sg_table = dmabuf->ops->map_dma_buf(attach, direction);其中map_dma_buf函数钩子就是将GPU VA换成IOVA地址,以nvidia为例,简单描述一下实现。
c
AMD的ops实现在amdgpu_dma_buf.c文件中
const struct dma_buf_ops amdgpu_dmabuf_ops
nvidia的ops实现在nv-dmabuf.c文件中
const struct dma_buf_ops nv_dma_buf_ops
static const struct dma_buf_ops nv_dma_buf_ops = {
.attach = nv_dma_buf_attach,
.map_dma_buf = nv_dma_buf_map,
.unmap_dma_buf = nv_dma_buf_unmap,
.release = nv_dma_buf_release,
.mmap = nv_dma_buf_mmap,
#if defined(NV_DMA_BUF_OPS_HAS_MAP)
.map = nv_dma_buf_map_stub,
.unmap = nv_dma_buf_unmap_stub,
#endif
#if defined(NV_DMA_BUF_OPS_HAS_MAP_ATOMIC)
.map_atomic = nv_dma_buf_map_atomic_stub,
.unmap_atomic = nv_dma_buf_unmap_atomic_stub,
#endif
};dma-buf export
c
1.将上层 mapping_type(CU_MEM_RANGE_FLAG_DMA_BUF_MAPPING_TYPE_PCIE)保存到dma-buf相关结构。
2.将VA/IPA对应的BO关联到dma-buf相关结构,导出dma-buf fd。attach
sql
if (priv->mapping_type == FORCE_PCIE) {
if (!nv_pci_is_valid_topology_for_direct_pci(priv->nv, to_pci_dev(attach->dev)))
return -ENOTSUPP;
priv->skip_iommu = NV_TRUE;
} else {
nv_dma_device_t peer = { .dev = &to_pci_dev(attach->dev)->dev,
.addressable_range.limit = to_pci_dev(attach->dev)->dma_mask };
if (!nv_grdma_pci_topology_supported(priv->nv, &peer))
return -ENOTSUPP;
/* DEFAULT 路径不设 skip_iommu, 保持 false */
}
1.对于 FORCE_PCIE 路径,应检查iommu group,即(pdev0->dev.iommu_group == pdev1->dev.iommu_group)。另外,设置跳过iommu标志,即skip_iommu = true。
2.对于 DEFAULT 路径,检查NIC和GPU的pci连通性,即必须要有共同祖先(pci_p2pdma_distance),后期最追求更高性能还可以要求同pcie switch。
3.增加BO引用计数,防止上层意外释放BO导致访问错误。
4.对于5.8以上内核版本,还需要增加以下判断。
if (attach->importer_ops && !attach->peer2peer)
return -ENOTSUPP;
importer_ops:用于识别新老attach初始化流,与peer2peer结合使用。
peer2peer:5.8以后内核在 dma_buf_attachment 增加 peer2peer 标志。
主流 RDMA importer 都设此标志为 true,比如mlx。
通过allow_peer2peer = true 声明能处理没有 struct page 的 MMIO 内存(BAR)。map_dma_buf
c
1.根据VA/IPA查找到vram offset。
2.对于 skip_iommu == true,填充sgt中dma_addres为vram bar base + offset(严格意义上应使用pci域base)。
3.对于 skip_iommu == false,先获取vram bar base + offset数组,依次执行dma_map_resource映射填充sgt。unmap_dma_buf
c
1.对于 skip_iommu == true,释放sgt。
2.对于 skip_iommu == false,解映射之后释放sgt。release
c
1.释放BO引用计数。Peer Memory Client
Peer Memory Client方式不需要用户调用特殊接口,统一使用ibv_reg_mr,以rdma性能测试工具为例,看看rdma驱动和GPU驱动怎么协同工作的。
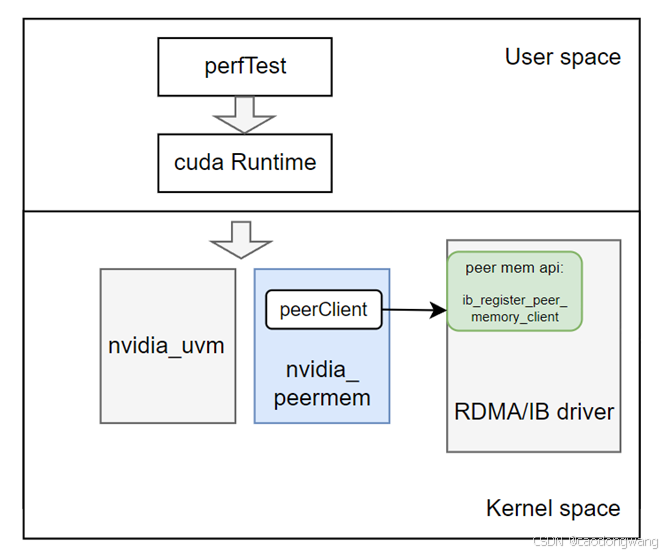
虽然都是调用ibv_reg_mr接口,但和正常RDMA的处理最大差别在于mem map和pin/unpin具有加大差别,即mem map、pin/unpin需要调用gpu driver自身api进行处理,因此,对于device memory的rdma操作,rdma定义了Peer Memory Client api用于peer device注册peer mem的相关操作。
简单来说,就是RDMA驱动维护了虚拟peer client bus并提供相关注册接口,而GPU驱动中需要实现client中函数钩子,并在加载驱动时候注册到RDMA驱动当中,函数钩子如下。
java
struct peer_memory_client {
char name[IB_PEER_MEMORY_NAME_MAX];
char version[IB_PEER_MEMORY_VER_MAX];
int (*acquire)(unsigned long addr, size_t size,
void *peer_mem_private_data, char *peer_mem_name,
void **client_context);
int (*get_pages)(unsigned long addr, size_t size, int write, int force,
struct sg_table *sg_head, void *client_context,
u64 core_context);
int (*dma_map)(struct sg_table *sg_head, void *client_context,
struct device *dma_device, int dmasync, int *nmap);
int (*dma_unmap)(struct sg_table *sg_head, void *client_context,
struct device *dma_device);
void (*put_pages)(struct sg_table *sg_head, void *client_context);
unsigned long (*get_page_size)(void *client_context);
void (*release)(void *client_context);
};典型调用流程:
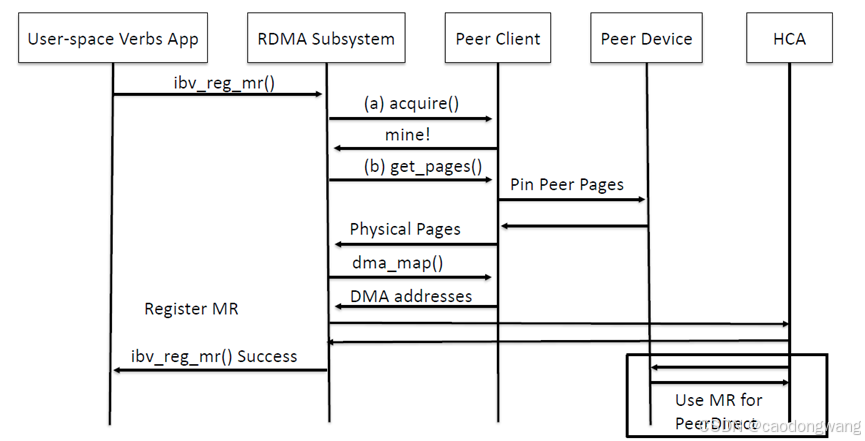
从调用过程看,主要是注册memory region的时候,rdma需要调用nvidia_peermem提供的acquire()函数判断是否是peer mem,然后调用nvidia_peermem接口提供的get_pages()函数pin住内存,并且得到物理地址,接着调用nvidia_peermem的dma_map函数得到IO地址,最后再送到RDMA网卡硬件进行memory注册(填充MRCTX)。
实现
AMD和nvidia当前最新驱动代码中依然会使用。
c
AMD实现在kfd_peerdirect.c文件中
static struct peer_memory_client amd_mem_client = {
.acquire = amd_acquire,
.get_pages = amd_get_pages,
.dma_map = amd_dma_map,
.dma_unmap = amd_dma_unmap,
.put_pages = amd_put_pages,
.get_page_size = amd_get_page_size,
.release = amd_release,
.get_context_private_data = NULL,
.put_context_private_data = NULL,
};
nvidia实现在nvidia-peermem.c文件中
static struct peer_memory_client nv_mem_client_nc = {
.acquire = nv_mem_acquire,
.get_pages = nv_mem_get_pages_nc,
.dma_map = nv_dma_map,
.dma_unmap = nv_dma_unmap,
.put_pages = nv_mem_put_pages_nc,
.get_page_size = nv_mem_get_page_size,
.release = nv_mem_release,
};实现
简单描述一下nvidia实现,nvidia开源驱动中维护了一个256大小的进程信息数组,记录了使用的GPU list以及每个GPU使用的设备内存虚拟地址以及对应的PCIe BAR地址(间接查找),acquire就是去遍历是否属于设备内存虚拟地址区间范围内,get_pages就是返回对应的PCIe BAR地址,dma_map就是调用dma_map_resource做DMA映射。
总结
贯穿整个GDR技术演进的核心挑战始终如一:如何安全、高效地将应用程序层面使用的GPU虚拟地址,转换为一组RDMA网卡DMA引擎能够理解并直接使用的物理地址(或总线地址)。无论Peer Memory Client的回调机制,还是dma-buf的map_dma_buf操作,本质上都是在解决这一关键的地址翻译问题, 因此,GPU驱动中如何高效组织和管理进程使用设备内存是需要好好考量的要点。