在AI Agent技术快速演进的当下,无论是Cursor中的编码助手技能,还是Claude Code中的多步骤编程能力,"Agent Skill"正成为大模型能力扩展的核心范式。Agent Skills技术体系的出现,标志着AI Agent开发范式从依赖庞大而脆弱的单体提示词,向模块化、可组合、可工程化的数字能力封装体系的根本性转变。它把零散的提示词升级为可复用、可管理的工程能力,让AI从"聪明的助手"进化为"可靠的专业执行者"。
然而,这些花里胡哨的Skills,在底层的HTTP传输中究竟是如何与大模型交互的?本文从HTTP底层交互的视角,剖析Agent Skill功能从"定义"到"执行"的全链路技术原理。
一、核心结论:Skill是应用层抽象,而非协议层概念
在OpenAI兼容协议(以及Anthropic Messages API)中,根本不存在"Skill"这个字段或角色。Skill是一个纯粹的应用层抽象,它最终被Cursor等AI应用"编译"成三种协议原语的组合:
- System/Developer Message --- 把Skill的指令文本注入到System Prompt中
- Tools Definition --- 把Skill需要用到的工具(Shell、Read、Write等)注册为
tools数组 - Multi-turn Tool Calling Loop --- LLM根据注入的指令,自主决策发起
tool_calls,宿主执行后把结果喂回去
一句话总结:Skill = 动态注入的System Prompt片段 + 预定义的Tool Schema + 多轮Tool Calling循环。
这个结论意味着,无论Skill的功能多么复杂------从网页抓取、代码生成到多文件重构------它在HTTP层面始终"退化"为标准的LLM对话与工具调用交互。理解了这一点,我们就掌握了Agent Skill底层机制的全貌。
二、前置知识:OpenAI兼容协议的两个核心机制
在深入Skill的HTTP交互流之前,需要先理解支撑整个体系的两个基础机制。
2.1 Tool Calling(函数调用)
Tool Calling允许模型在生成文本回复的过程中,"中断"并请求调用外部函数。它的工作流程如下:
- 请求端 :客户端在API请求的
tools数组中注册可用工具,每个工具包含name、description和parameters(JSON Schema定义)。 - 模型端 :模型根据上下文判断是否需要调用工具,如果需要,则返回一个
tool_calls数组,包含函数名和序列化为JSON的参数。 - 客户端 :宿主程序执行函数,将结果作为
tool角色的消息追加到消息列表。 - 继续对话:将包含工具执行结果的完整消息列表再次发送给模型,模型据此生成最终回复或发起新一轮工具调用。
这一机制构成了Agent Skill得以执行的"动力引擎"------Skill的每一步具体操作,最终都转化为标准化的工具调用。
2.2 System Prompt注入
System Prompt是在对话开始前,以system角色注入给模型的顶层指令。它定义了模型的行为边界、角色定位和任务约束。在OpenAI兼容协议中,System Prompt作为messages数组中的首条消息存在:
json
{
"messages": [
{"role": "system", "content": "You are a helpful assistant..."},
{"role": "user", "content": "用户问题"}
]
}理解以上两个机制后,就能明白Agent Skill在HTTP层面的承载方式:System Prompt负责"告诉模型有哪些技能以及何时使用",Tool Calling负责"执行技能所需的具体操作"。
三、完整的HTTP交互流分步拆解
下面以Cursor中的mp-read技能(拉取微信公众号文章文本)为例,逐步拆解从Skill加载到任务完成的完整HTTP交互流。
3.1 第0步:Skill发现与描述摘要注入(对话开始前)
在用户打开Cursor、还没有说话的时候,Cursor就已经完成了Skill的预加载工作:
-
目录扫描 :扫描
.cursor/skills/、.agents/skills/等目录,收集所有Skill的元数据(来自YAML frontmatter中的name和description)。 -
渐进式加载 :Cursor采用"Progressive Loading"机制------首先只提取每个Skill的名称和描述摘要,而不加载完整的
SKILL.md正文。这样做的目的是节约珍贵的上下文窗口token。 -
注入System Prompt:将这些摘要信息注入到System Prompt中,形成类似如下的静态上下文片段:
Extract plain text from Tencent MP (mp.weixin.qq) articles using a headless
Chrome browser. Use when the user wants to read, fetch, extract, summarize,
or reference a MP article, or when a mp.weixin.qq URL appears in conversation.
此时,模型已经"知道"了有哪些技能可用以及各自的触发条件,但还没有获取技能的具体执行指令------这些指令只在技能被触发时才被注入。
关键设计原则:渐进式加载。 大型Agent系统可能有数十甚至上百个Skills,如果全部加载会消耗大量token,因此元数据预注入+正文按需加载是最优方案。
3.2 第1步:用户发问,触发Skill匹配
假设用户发了一句:帮我读一下这篇公众号文章:https://mp.weixin.qq.com/s/HHPK6QvclYaxlDg28elN8w。
Cursor作为客户端,构造出第一次API请求。请求中包含两个关键组件:
组件一:Skill指令注入。 System Prompt中包含了技能触发条件------当检测到mp.weixin.qq URL时,系统自动加载完整的SKILL.md正文,将具体的执行步骤注入到System Prompt中。
组件二:工具注册。 Skill所需的底层工具(Shell命令执行、文件读取等)被注册为tools数组:
json
{
"model": "claude-4.6-opus",
"messages": [
{
"role": "system",
"content": "You are an AI coding assistant...\n\n<available_skills>\n- mp-read: Extract plain text from Tencent MP articles...\n</available_skills>\n\n<skill_instructions>\n## mp-read Skill\n\n### Steps:\n1. Use headless Chrome to fetch the article URL\n2. Extract plain text content from the rendered page\n3. Return the extracted text\n</skill_instructions>"
},
{
"role": "user",
"content": "帮我读一下这篇公众号文章:https://mp.weixin.qq.com/s/HHPK6QvclYaxlDg28elN8w"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "execute_command",
"description": "Execute a shell command in the terminal",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string"},
"requires_approval": {"type": "boolean"}
}
}
}
}
]
}关键设计原则:指令与工具分离。 System Prompt告诉模型"做什么、何时做、怎么做",Tool Schema则告诉模型"用什么做"。二者分层清晰,共同构成Skill在HTTP层面的完整表示。
3.3 第2步:LLM发起Tool Call
LLM收到请求后,根据System Prompt中的Skill指令,判断需要调用execute_command工具来拉取网页。LLM不会真正执行命令,而是返回一个结构化的tool_calls响应,其中finish_reason为tool_calls:
json
{
"id": "msg_abc123",
"choices": [{
"finish_reason": "tool_calls",
"message": {
"role": "assistant",
"content": null,
"tool_calls": [{
"id": "call_xyz789",
"type": "function",
"function": {
"name": "execute_command",
"arguments": "{\"command\": \"node mp-read-cli.js https://mp.weixin.qq.com/s/HHPK6QvclYaxlDg28elN8w\", \"requires_approval\": false}"
}
}]
}
}]
}模型的content为null------当模型发起工具调用时,它不产生文本内容,只产生工具调用请求。这是Tool Calling区别于普通对话的关键特征。
3.4 第3步:宿主执行工具,结果回传
Cursor接收到tool_calls响应后,解析出函数名和参数,由宿主环境(本地Shell)执行该命令。工具执行完成后,Cursor将结果以tool角色消息的形式追加到消息列表中,发起第二次API请求:
json
{
"model": "claude-4.6-opus",
"messages": [
{"role": "system", "content": "..."},
{"role": "user", "content": "帮我读一下这篇公众号文章:..."},
{"role": "assistant", "content": null, "tool_calls": [...]},
{"role": "tool", "tool_call_id": "call_xyz789", "content": "【公众号文章标题】大模型的Agent Skill功能...\n\n【正文】前几天我在司内论坛..."}
]
}关键点:工具执行结果以纯文本形式回传。模型看到的不是原始HTTP响应或网页HTML,而是经过Skill脚本处理后的结构化文本。
3.5 第4步:LLM基于结果生成最终回复
模型收到工具执行结果后,将其融入上下文,生成面向用户的最终回复。此时finish_reason为stop,content字段包含完整文本,对话完成一轮闭环。
四、高级扩展:MCP协议与A2A协议的技术定位
上述流程展示了单个Skill在应用层如何"编译"为HTTP协议原语。但随着Agent生态的演进,工具复用与Agent间协作的需求催生了两大开放协议:MCP和A2A。它们各自解决不同层面的问题,共同构成Agent Skill的技术生态底座。
4.1 MCP协议:标准化工具调用
MCP(Model Context Protocol) 由Anthropic提出,旨在标准化LLM与外部工具、数据源的交互方式。它的核心价值在于:让不同来源的工具能够被统一发现、描述和调用,而无需为每个工具编写适配代码。
从HTTP底层来看,MCP的核心贡献包括:
- JSON-RPC 2.0通信:客户端与MCP服务器之间通过JSON-RPC进行结构化交互。
- Streamable HTTP传输 :支持
application/json、SSE和Streamable HTTP三种传输方式。其中Streamable HTTP允许在长连接中保持双向通信,支持实时推送和异步响应。 - 工具发现机制 :MCP服务器以标准化格式暴露
tools/list接口,客户端可以动态发现可用工具及其Schema。 - 安全授权框架:基于OAuth 2.1的完整授权框架,确保工具调用的安全可控。
如果将上一节的Tool Calling比作"函数调用的HTTP承载",那么MCP就是将这种能力标准化为跨平台、跨应用的协议层基础设施。Skill定义了"做什么",MCP定义了"如何连接工具"。
4.2 A2A协议:Agent间的协作层
如果说MCP解决的是"模型到工具"的垂直连接问题,那么A2A(Agent-to-Agent Protocol)解决的就是"Agent到Agent"的水平协作问题。
A2A协议由Google在2025年4月推出,它的核心特性包括:
- Agent Card:每个Agent通过标准的JSON格式宣告自己的能力,实现Agent间的自动发现。
- 任务委托:一个Agent可以将子任务委托给另一个专门的Agent,后者完成后返回结果。
- 多模态通信:支持文本、文件、流式数据等多种交互形式。
- 跨框架互操作:无论Agent基于LangGraph、CrewAI还是Google ADK构建,只要遵循A2A协议即可协作。
在企业级场景中,A2A和MCP呈现出清晰的协同分工:MCP为每个Agent提供访问外部工具和数据源的标准化通道,确保Agent"做事有据可依";A2A则让多个专业Agent之间实现任务分发与结果汇总,使复杂的端到端流程能够在Agent间无缝流转。二者共同构成了Skill生态的两大支柱。
4.3 协议与Skill的协同全景图
至此,我们可以绘制出Agent Skill技术栈的完整分层视图:
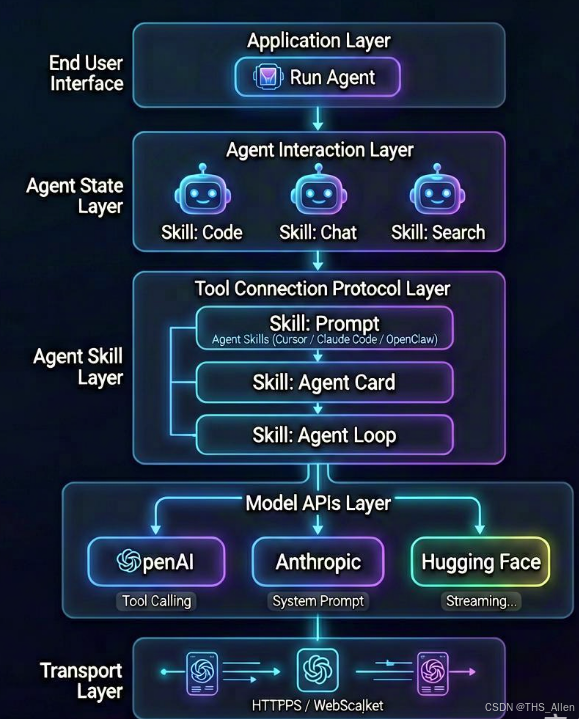
Skill位于最顶层,它向下依赖MCP获取工具能力,依赖A2A实现多Agent协作,最终将所有行为收敛为标准的LLM API调用。 正因为每一层都有清晰的边界和标准化的协议定义,Skill的开发门槛才能从"代码级"降低到"文件夹级"------开发者仅需创建一个包含执行脚本和说明文档的文件夹,即可完成一个Skill的定义。
4.4 前沿研究方向
在协议标准化之外,学术界正在探索Skill技术的更深层优化:
- SkillRouter(技能路由) :当Agent拥有数十甚至数百个Skills时,如何高效地将用户任务路由到正确的技能成为一个关键挑战。SkillRouter提出了一种检索-重排序的两阶段路由方法,在基准测试中实现了74.0%的Top-1路由准确率,且仅需1.2B参数即可在消费级硬件上运行。
- SkillSmith(技能编译) :当前Skills的文本表示虽然灵活,但运行时需要将完整指令注入上下文,造成大量token浪费。SkillSmith提出了一种离线编译框架,将Skill的文本描述编译为最小化的可执行接口,使Agent在运行时只需加载必要组件,从而最小化上下文注入和推理开销。
五、总结与展望
本文从HTTP底层交互视角出发,揭示了Agent Skill的核心本质:它不是协议层的新概念,而是应用层的巧妙抽象------将复杂的技能分解为System Prompt注入、Tool Schema注册、多轮Tool Calling循环这三个HTTP协议原语的有机组合。
理解这一本质后,Agent Skill的工程实践思路便豁然开朗:
- 想要实现类似功能?不需要自研新协议,只需在现有OpenAI兼容协议的框架内,实现System Prompt动态注入和Tool Calling循环。
- 想要扩展工具生态?拥抱MCP协议,让工具定义标准化、可复用。
- 想要实现多Agent协作?引入A2A协议,让Agent之间能够发现、委托和协同。
展望未来,随着Agent Skills从"文本驱动"向"结构化编译"演进(如SkillSmith的离线编译方案),以及从"小规模技能库"向"大规模技能路由"扩展(如SkillRouter的检索-重排序方案),Agent Skill技术正在快速走向成熟。对于企业和开发者而言,Skill不是魔法,但理解了它在HTTP层面的承载方式,就掌握了构建下一代AI Agent应用的钥匙。