文章目录
- 一、前言
- 二、训练命令
- 三、main.py
-
- 环境问题
- 解决方案(仅供参考):
- [快速修复(修改 `tools.py`)](#快速修复(修改
tools.py)) - 如果还想排查根因
- 额外提醒:全零样本问题
- 训练代码
- 四、论文训练结果
-
- 问题1:表2
- [一、OR(Observation Ratio)是什么?](#一、OR(Observation Ratio)是什么?)
- [二、Table II 中两行数据的区别](#二、Table II 中两行数据的区别)
-
- [第一行:Single model trained on 100% OR(在 100% OR 上训练的单一模型)](#第一行:Single model trained on 100% OR(在 100% OR 上训练的单一模型))
- [第二行:Separately trained on each OR(在每个 OR 上单独训练一个模型)](#第二行:Separately trained on each OR(在每个 OR 上单独训练一个模型))
- [InfoGCN++ 的厉害之处](#InfoGCN++ 的厉害之处)
- [三、X-Sub 和 X-View 是什么?你训的是哪个?](#三、X-Sub 和 X-View 是什么?你训的是哪个?)
- 四、一句话总结
- 问题2:表2和表3
- [一、Table II 和 Table III 到底在比什么?](#一、Table II 和 Table III 到底在比什么?)
- [二、"Two-stream setup" 是什么意思?](#二、"Two-stream setup" 是什么意思?)
- [三、为什么 Table III 中 NTU 60 X-Sub 打不赢 Foo et al. 21?](#三、为什么 Table III 中 NTU 60 X-Sub 打不赢 Foo et al. [21]?)
- [四、为什么 NTU 120 X-Sub 又打赢了 Foo 21?](#四、为什么 NTU 120 X-Sub 又打赢了 Foo [21]?)
- [五、为什么 NTU 60 X-View 只跟 Weng 26 比,不跟 Foo 21 比?](#五、为什么 NTU 60 X-View 只跟 Weng [26] 比,不跟 Foo [21] 比?)
- [六、为什么 Table II 中 80% 以后打不赢?](#六、为什么 Table II 中 80% 以后打不赢?)
- 七、论文到底想说什么?
- 一句话总结
- 问题3:和PoseC3D对比
- [一、三者在 NTU 上的指标对比](#一、三者在 NTU 上的指标对比)
- 二、谁高谁低?分场景
-
- [场景 1:离线识别(看完整视频再分类)](#场景 1:离线识别(看完整视频再分类))
- [场景 2:在线识别(看一半就要猜,AUC 综合指标)](#场景 2:在线识别(看一半就要猜,AUC 综合指标))
- 三、为什么会这样?
-
- [1. PoseC3D 在 NTU 60 X-Sub 上比 InfoGCN 高:3D 热图卷积的局部优势](#1. PoseC3D 在 NTU 60 X-Sub 上比 InfoGCN 高:3D 热图卷积的局部优势)
- [2. InfoGCN 在 X-View 和 NTU 120 上反超:图拓扑的泛化力](#2. InfoGCN 在 X-View 和 NTU 120 上反超:图拓扑的泛化力)
- [3. InfoGCN++ 的 100% OR 最低:在线模型的设计取舍](#3. InfoGCN++ 的 100% OR 最低:在线模型的设计取舍)
- [4. Table II 和 Table III 的 100% OR 为什么不一样?](#4. Table II 和 Table III 的 100% OR 为什么不一样?)
- 四、一句话总结
- 问题4:预训练权重的影响
- [一、InfoGCN++ 论文是否提到预训练权重?](#一、InfoGCN++ 论文是否提到预训练权重?)
- [二、PoseC3D 确实能加载预训练权重,而且确实用了](#二、PoseC3D 确实能加载预训练权重,而且确实用了)
- [三、PoseC3D 指标高的完整原因分析](#三、PoseC3D 指标高的完整原因分析)
-
- [因素 1:骨架数据来源完全不同(最大因素)](#因素 1:骨架数据来源完全不同(最大因素))
- [因素 2:3D-CNN vs GCN 的架构差异](#因素 2:3D-CNN vs GCN 的架构差异)
- [因素 3:预训练权重(你提到的)](#因素 3:预训练权重(你提到的))
- [因素 4:测试时增强(10-clip testing)](#因素 4:测试时增强(10-clip testing))
- [四、为什么 InfoGCN++ 不预训练也能"在线识别"这么强?](#四、为什么 InfoGCN++ 不预训练也能"在线识别"这么强?)
- 一句话总结
一、前言
论文地址:https://arxiv.org/pdf/2310.10547
Github地址:https://github.com/stnoah1/infogcn2/tree/main
训练代码:https://github.com/stnoah1/infogcn2/blob/main/main.py
作者的训练代码使用wandb,而我的环境不允许使用wandb,这迫使我修改代码为自己保存训练结果。 作者在论文实验部分的参数设置说的比较清楚,就是数据预处理的代码不完善我折腾了很久,自己完善预处理的代码之后,我试了一下训练,复现NTU RGB+D 60 Skeleton数据集的结果跟论文结果接近一致。
训练NTU 60 X-Sub:
epoch=70时,ACC100%=0.8427844, 原论文是85.38,这是完全看到动作时的准确率,掉了1个点,可能是自己下载的数据集有些残缺导致的
epoch=70时,eval/AUC=0.7008299827575684。
AUC 越高 = 模型在"看得很少"时就能猜对,且随着看的越来越多准确率稳步提升。

这一篇除了复现论文实验结果外,还在第四节讨论了infoGCN2的实验部分以及跟PoseC3D对比的一些问题。下一篇我们开始思考一些关于因果推理的问题,在经过一些问题的思考之后,目前认为infoGCN2的思路很好,但距离因果推理还是有距离,后续我们考虑转向因果推理的研究。
二、训练命令
作者在Readme中给出了训练NW-UCLA数据集的训练命令
python
python main.py --half=True --batch_size=32 --test_batch_size=64 \
--step 50 60 --num_epoch=70 --num_worker=4 --dataset=NW-UCLA --num_class=10 \
--datacase=ucla --weight_decay=0.0003 --num_person=1 --num_point=20 --graph=graph.ucla.Graph \
--feeder=feeders.feeder_ucla.Feeder --base_lr 1e-1 --base_channel 64 \
--window_size 52 --lambda_1=1e-0 --lambda_2=1e-1 --lambda_3=1e-3 --n_step 3然而我训练的是NTU RGB+D 60 Skeleton数据集,所以训练命令要改变,而且要训两个,一个是X-Sub,另一个是X-View
训练NTU 60 X-Sub:
python
python main.py --half=False --batch_size=32 --test_batch_size=64 \
--step 50 60 --num_epoch=60 --num_worker=4 --dataset=ntu --num_class=60 \
--datacase=NTU60_CS --weight_decay=0.0003 --num_person=2 --num_point=25 --graph=graph.ntu_rgb_d.Graph \
--feeder=feeders.feeder_ntu.Feeder --base_lr 1e-1 --base_channel 64 \
--window_size 64 --lambda_1=1e-0 --lambda_2=1e-1 --lambda_3=1e-3 --n_step 3训练NTU 60 X-View:
python
python main.py --half=False --batch_size=32 --test_batch_size=64 \
--step 50 60 --num_epoch=60 --num_worker=4 --dataset=ntu --num_class=60 \
--datacase=NTU60_CV --weight_decay=0.0003 --num_person=2 --num_point=25 --graph=graph.ntu_rgb_d.Graph \
--feeder=feeders.feeder_ntu.Feeder --base_lr 1e-1 --base_channel 64 \
--window_size 64 --lambda_1=1e-0 --lambda_2=1e-1 --lambda_3=1e-3 --n_step 3由于我们丢弃了wandb改成自己输出训练信息,args.py里面要新增一个参数用于放输出文件
python
parser.add_argument('--work_dir', type=str, default="./work_dir/my_experiment", help='')三、main.py
1.完全丢弃wandb,保存训练和验证的loss曲线图
2.训练的时候如果在某个epoch发现更优的模型要打印当前epoch的验证指标,并且保存当前最优模型
3.每轮验证的指标也写入一个csv,训练参数之类的参数也写入一个文件
4.最后再输出一个训练分析报告,分析清楚此次训练每个指标意味着什么。
环境问题
运行训练脚本可能会遇到一些环境问题:
报错:ModuleNotFoundError: No module named 'h5py'
解决方案:pip install h5py
报错:ModuleNotFoundError: No module named 'sklearn'
解决方案:pip install scikit-learn
报错:(infogcn2) D:\zero_track\Reset\infogcn2\data\ntu>python seq_transformation.py
Traceback (most recent call last):
File "D:\zero_track\Reset\infogcn2\data\ntu\seq_transformation.py", line 12, in
from utils import create_aligned_dataset
ModuleNotFoundError: No module named 'utils'
解决方案:可能是seq_transformation.py的 sys.path.append('.../...') 不起作用导致,改成项目根目录试试,还是不行就直接把项目的utils复制到data/ntu下面
报错:ModuleNotFoundError: No module named 'apex'
解决方案:可以考虑main.py通过--half=False禁用混合精度训练,避开这个问题。
报错:ModuleNotFoundError: No module named 'torch_dct'
解决方案:pip install torch-dct
ModuleNotFoundError: No module named 'matplotlib'
解决方案:pip install matplotlib
报错:ModuleNotFoundError: No module named 'resource'
解决方案:linux系统上不会出现这个问题,windows系统上会出现,把下面相关代码注释了即可
python
# import resource
# rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
# resource.setrlimit(resource.RLIMIT_NOFILE, (2048, rlimit[1]))报错:
python
Traceback (most recent call last):
File "D:\zero_track\Reset\infogcn2\main.py", line 654, in <module>
main()
File "D:\zero_track\Reset\infogcn2\main.py", line 651, in main
processor.start()
File "D:\zero_track\Reset\infogcn2\main.py", line 465, in start
self.train(epoch, save_model=save_model)
File "D:\zero_track\Reset\infogcn2\main.py", line 244, in train
for x, y, mask, index in tbar:
^^^^
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\tqdm\std.py", line 1181, in __iter__
for obj in iterable:
^^^^^^^^
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\utils\data\dataloader.py", line 701, in __next__
data = self._next_data()
^^^^^^^^^^^^^^^^^
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\utils\data\dataloader.py", line 1465, in _next_data
return self._process_data(data)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\utils\data\dataloader.py", line 1491, in _process_data
data.reraise()
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\_utils.py", line 715, in reraise
raise exception
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\utils\data\_utils\worker.py", line 351, in _worker_loop
data = fetcher.fetch(index) # type: ignore[possibly-undefined]
^^^^^^^^^^^^^^^^^^^^
File "D:\application\anaconda3\envs\infogcn2\Lib\site-packages\torch\utils\data\_utils\fetch.py", line 52, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
~~~~~~~~~~~~^^^^^
File "D:\zero_track\Reset\infogcn2\feeders\feeder_ntu.py", line 102, in __getitem__
data_numpy = tools.valid_crop_resize(data_numpy, valid_frame_num, self.p_interval, self.window_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\zero_track\Reset\infogcn2\feeders\tools.py", line 24, in valid_crop_resize
cropped_length = np.minimum(np.maximum(int(np.floor(valid_size*p)),64), valid_size)# constraint cropped_length lower bound as 64
^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: only 0-dimensional arrays can be converted to Python scalars解决方案(仅供参考):
这个错误的核心原因是:valid_crop_resize 里 valid_size * p 的结果是一个 numpy 数组 (而非标量),导致 int() 转换失败。
最可能的情况是:
valid_frame_num因为数据维度问题变成了数组- 或者
p的生成代码误用了np.random.rand(1)这类返回数组的写法
快速修复(修改 tools.py)
打开 feeders/tools.py,找到 valid_crop_resize 函数(约第24行),把原来的:
python
cropped_length = np.minimum(np.maximum(int(np.floor(valid_size*p)),64), valid_size)改成:
python
# 强制转为标量,防止 numpy 数组导致 int() 报错
valid_size = int(np.asarray(valid_size).item())
p = float(np.asarray(p).item())
cropped_length = np.minimum(np.maximum(int(np.floor(valid_size * p)), 64), valid_size)如果 valid_size 或 p 本身就是标量,.item() 不会破坏任何东西;如果是数组,它会安全地取出第一个元素。
如果还想排查根因
在 feeder_ntu.py 的 __getitem__ 里(调用 valid_crop_resize 之前),加两行打印:
python
# 在 feeder_ntu.py 约第 101~102 行之间插入
print(f"[DEBUG] valid_frame_num type={type(valid_frame_num)}, shape={getattr(valid_frame_num, 'shape', 'N/A')}, value={valid_frame_num}")
print(f"[DEBUG] data_numpy shape={data_numpy.shape}")
data_numpy = tools.valid_crop_resize(data_numpy, valid_frame_num, self.p_interval, self.window_size)跑一个 batch 看看输出:
- 正常情况下
valid_frame_num应该是一个普通整数(如64) - 如果它显示
shape=(1,)或shape=()但 dtype 是 array,说明数据加载阶段有问题
额外提醒:全零样本问题
你之前提到训练集有 8146908 个全零帧 。如果某些样本完全是零(valid_frame_num = 0),上面修复后代码能跑,但 cropped_length 会被 clamp 到 0,后续 crop 和 resize 逻辑可能仍然报错或产生异常数据。
建议在 feeder_ntu.py 的 __getitem__ 里加一道保护:
python
valid_frame_num = np.sum(data_numpy.sum(0).sum(-1).sum(-1) != 0)
# 如果全是零,至少保留一帧避免后续除零/空数组
if valid_frame_num == 0:
valid_frame_num = 1训练代码
python
#!/usr/bin/env python
from __future__ import print_function
import os
import math
import time
import glob
import json # 新增:保存参数
import csv # 新增:CSV 记录
import pickle
import random
import resource
from collections import OrderedDict
import matplotlib
matplotlib.use('Agg') # 新增:无头环境绘图
import matplotlib.pyplot as plt # 新增:绘制曲线
import apex
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch_dct as dct
import numpy as np
from tqdm import tqdm
from args import get_parser
from loss import LabelSmoothingCrossEntropy, masked_recon_loss
from model.sode import SODE
from utils import AverageMeter, import_class
from einops import rearrange, repeat
rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
resource.setrlimit(resource.RLIMIT_NOFILE, (2048, rlimit[1]))
def init_seed(seed):
torch.cuda.manual_seed_all(seed)
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
# torch.backends.cudnn.enabled = False
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
class Processor():
"""
Processor for Skeleton-based Action Recgnition
"""
def __init__(self, arg):
self.arg = arg
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.save_arg()
self.load_model()
A_vector = self.model.get_A(self.arg.k) if self.arg.k != 8 else None
self.load_optimizer()
self.load_data(A_vector)
self.best_acc = 0.0
self.best_acc_epoch = 0
self.log_recon_loss = AverageMeter()
self.log_auc = AverageMeter()
self.log_recon_2d_loss = AverageMeter()
self.log_cls_loss = AverageMeter()
self.log_kl_div = AverageMeter()
self.log_acc = [AverageMeter() for _ in range(10)]
self.log_feature_loss = AverageMeter()
# 新增:用于保存历史指标,供绘图和报告使用
self.history = {'train': {}, 'eval': {}}
model = self.model.to(self.device)
if self.arg.half:
self.model, self.optimizer = apex.amp.initialize(
model,
self.optimizer,
opt_level=f'O{self.arg.amp_opt_level}'
)
if self.arg.amp_opt_level != 1:
self.print_log('[WARN] nn.DataParallel is not yet supported by amp_opt_level != "O1"')
# self.model = torch.nn.DataParallel(model, device_ids=(0,1,2))
def load_data(self, A_vector):
Feeder = import_class(self.arg.feeder)
self.data_loader = dict()
data_path = f'data/{self.arg.dataset}/{self.arg.datacase}_aligned.npz'
self.data_loader['train'] = torch.utils.data.DataLoader(
dataset=Feeder(data_path=data_path,
split='train',
p_interval=[0.5, 1],
vel=self.arg.use_vel,
random_rot=self.arg.random_rot,
sort=False,
A=A_vector,
window_size=self.arg.window_size,
),
batch_size=self.arg.batch_size,
shuffle=True,
num_workers=self.arg.num_worker,
drop_last=True,
pin_memory=True,
worker_init_fn=init_seed)
self.data_loader['test'] = torch.utils.data.DataLoader(
dataset=Feeder(
data_path=data_path,
split='test',
p_interval=[0.95],
vel=self.arg.use_vel,
A=A_vector,
window_size=self.arg.window_size,
),
batch_size=self.arg.test_batch_size,
shuffle=False,
num_workers=self.arg.num_worker,
drop_last=False,
pin_memory=True,
worker_init_fn=init_seed)
def load_model(self):
self.model = SODE(
num_class=self.arg.num_class,
num_point=self.arg.num_point,
num_person=self.arg.num_person,
graph=self.arg.graph,
in_channels=3,
num_head=self.arg.n_heads,
ode_method=self.arg.ode_method,
k=self.arg.k,
base_channel=self.arg.base_channel,
depth=self.arg.depth,
device=self.device,
T=self.arg.window_size,
n_step=self.arg.n_step,
dilation=self.arg.dilation,
SAGC_proj=self.arg.SAGC_proj,
backbone=self.arg.backbone,
num_cls=self.arg.num_cls,
)
self.cls_loss = LabelSmoothingCrossEntropy(T=self.arg.window_size).to(self.device)
self.recon_loss = masked_recon_loss
if self.arg.weights:
self.print_log('Load weights from {}.'.format(self.arg.weights))
if '.pkl' in self.arg.weights:
with open(self.arg.weights, 'r') as f:
weights = pickle.load(f)
else:
weights = torch.load(self.arg.weights)
weights = OrderedDict([[k.split('module.')[-1], v.to(self.device)] for k, v in weights.items()])
keys = list(weights.keys())
for w in self.arg.ignore_weights:
for key in keys:
if w in key:
if weights.pop(key, None) is not None:
self.print_log('Sucessfully Remove Weights: {}.'.format(key))
else:
self.print_log('Can Not Remove Weights: {}.'.format(key))
try:
self.model.load_state_dict(weights, strict=False)
except:
state = self.model.state_dict()
diff = list(set(state.keys()).difference(set(weights.keys())))
print('Can not find these weights:')
for d in diff:
print(' ' + d)
state.update(weights)
self.model.load_state_dict(state)
def load_optimizer(self):
if self.arg.optimizer == 'SGD':
self.optimizer = optim.SGD(
self.model.parameters(),
lr=self.arg.base_lr,
momentum=0.9,
nesterov=self.arg.nesterov,
weight_decay=self.arg.weight_decay)
elif self.arg.optimizer == 'Adam':
self.optimizer = optim.Adam(
self.model.parameters(),
lr=self.arg.base_lr,
weight_decay=self.arg.weight_decay)
else:
raise ValueError()
self.print_log('using warm up, epoch: {}'.format(self.arg.warm_up_epoch))
def save_arg(self):
# save arg
arg_dict = vars(self.arg)
if not os.path.exists(self.arg.work_dir):
os.makedirs(self.arg.work_dir)
# 新增:保存训练参数到 JSON
with open(os.path.join(self.arg.work_dir, 'args.json'), 'w') as f:
json.dump(arg_dict, f, indent=4)
def adjust_learning_rate(self, epoch):
if self.arg.optimizer == 'SGD' or self.arg.optimizer == 'Adam' :
if epoch < self.arg.warm_up_epoch and self.arg.weights is None:
lr = self.arg.base_lr * (epoch + 1) / self.arg.warm_up_epoch
else:
lr = self.arg.base_lr * (
self.arg.lr_decay_rate ** np.sum(epoch >= np.array(self.arg.step)))
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
return lr
else:
raise ValueError()
def print_time(self):
localtime = time.asctime(time.localtime(time.time()))
self.print_log("Local current time : " + localtime)
def print_log(self, str, print_time=True):
if print_time:
localtime = time.asctime(time.localtime(time.time()))
str = "[ " + localtime + ' ] ' + str
print(str)
if self.arg.print_log:
with open('{}/log.txt'.format(self.arg.work_dir), 'a') as f:
print(str, file=f)
def train(self, epoch, save_model=False):
self.model.train()
[self.log_acc[i].reset() for i in range(10)]
self.log_cls_loss.reset()
self.log_auc.reset()
self.log_feature_loss.reset()
self.log_recon_loss.reset()
self.log_recon_2d_loss.reset()
self.print_log('Training epoch: {}'.format(epoch + 1))
lr = self.adjust_learning_rate(epoch)
idx10 = np.array([int(math.ceil(self.arg.window_size*ratio*0.1))-1 for ratio in range(10)])
tbar = tqdm(self.data_loader['train'], dynamic_ncols=True)
for x, y, mask, index in tbar:
cls_loss, recon_loss, feature_loss = torch.tensor(0.), torch.tensor(0.), torch.tensor(0.)
B, C, T, V, M = x.shape;
x = x.float().to(self.device)
y = y.long().to(self.device)
mask = mask.long().to(self.device)
y_hat, x_hat, z_0, z_hat, kl_div = self.model(x)
N_cls = y_hat.size(0)//B
if self.arg.lambda_1:
y = y.view(1,B,1).expand(N_cls, B, y_hat.size(2))
y_hat_ = rearrange(y_hat, "b i t -> (b t) i")
cls_loss = self.arg.lambda_1 * self.cls_loss(y_hat_, y.reshape(-1))
if self.arg.lambda_2:
N_rec = x_hat.size(0)//B
x_gt = x.unsqueeze(0).expand(N_rec, B, C, T, V, M).reshape(N_rec*B, C, T, V, M)
mask_recon = repeat(mask, 'b c t v m -> n b c t v m', n=N_rec).clone()
for i in range(N_rec):
if N_rec == self.arg.n_step:
mask_recon[i,:,:,:i+1,:,:] = 0.
else:
mask_recon[i,:,:,:i,:,:] = 0.
mask_recon = rearrange(mask_recon, 'n b c t v m -> (n b) c t v m')
recon_loss = self.arg.lambda_2 * self.recon_loss(x_hat, x_gt, mask_recon)
if self.arg.lambda_3:
N_step = self.arg.n_step
B_,C,T,V = z_0.shape
z_0 = repeat(z_0, 'b c t v-> n b c t v', n=N_step)
z_hat = z_hat.view(N_step, B_, C, T, V)
mask_feature = (z_hat != 0.)
feature_loss = self.arg.lambda_3 * self.recon_loss(z_hat, z_0, mask_feature)# F.mse_loss(z_0, z_hat)#
if self.arg.lambda_4:
kl_div = self.arg.lambda_4 * kl_div
loss = cls_loss + recon_loss + feature_loss + kl_div
# backward
self.optimizer.zero_grad()
if self.arg.half:
with apex.amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
self.optimizer.step()
value, predict_label = torch.max(y_hat.data, 1)
for i, ratio in enumerate([(i+1)/10 for i in range(10)]):
self.log_acc[i].update((predict_label == y.data)\
.view(N_cls*B,-1)[:,int(math.ceil(T*ratio))-1].float().mean(), B)
self.log_cls_loss.update(cls_loss.data.item(), B)
self.log_feature_loss.update(feature_loss.data.item(), B)
self.log_recon_loss.update(recon_loss.data.item(), B)
self.log_kl_div.update(kl_div.data.item(), B)
AUC = np.mean([self.log_acc[i].avg.cpu().numpy() for i in range(10)])
tbar.set_description(
f"[Epoch #{epoch}] "\
f"AUC:{AUC:.3f}, " \
f"CLS:{self.log_cls_loss.avg:.3f}, " \
f"FT:{self.log_feature_loss.avg:.3f}, " \
f"RECON:{self.log_recon_loss.avg:.5f}, " \
)
AUC = np.mean([self.log_acc[i].avg.cpu().numpy() for i in range(10)])
# 新增:记录训练指标到历史
self.history['train'][epoch] = {
'recon_loss': float(self.log_recon_loss.avg),
'cls_loss': float(self.log_cls_loss.avg),
'feature_loss': float(self.log_feature_loss.avg),
'kl_div': float(self.log_kl_div.avg),
'auc': float(AUC),
'acc': {f'{((i+1)/10):.1f}': float(self.log_acc[i].avg) for i in range(10)}
}
# statistics of time consumption and loss
if save_model:
state_dict = self.model.state_dict()
weights = OrderedDict([[k.split('module.')[-1], v.cpu()] for k, v in state_dict.items()])
torch.save(weights, f'{self.arg.work_dir}/runs-{epoch+1}.pt')
def eval(self, epoch, save_score=False, loader_name=['test']):
self.model.eval()
[self.log_acc[i].reset() for i in range(10)]
self.log_cls_loss.reset()
self.log_feature_loss.reset()
self.log_recon_loss.reset()
self.log_recon_2d_loss.reset()
self.log_kl_div.reset()
self.print_log('Eval epoch: {}'.format(epoch + 1))
for ln in loader_name:
loss_value = []
cls_loss_value = []
score_frag = []
label_list = []
pred_list = []
step = 0
time_lst = []
tbar = tqdm(self.data_loader[ln], dynamic_ncols=True)
idx10 = np.array([int(math.ceil(self.arg.window_size*0.1*i))-1 for i in range(1,11)])
for x, y, mask, index in tbar:
label_list.append(y)
with torch.no_grad():
B, C, T, V, M = x.shape
x = x.float().to(self.device)
y = y.long().to(self.device)
y_ = y.clone()
mask = mask.long().to(self.device)
x_gt = x
y_hat, x_hat, z_0, z_hat, kl_div = self.model(x)
N_cls = y_hat.size(0)//B
y = y.view(1,B,1).expand(N_cls, B, y_hat.size(2)).reshape(-1)
y_hat = rearrange(y_hat, "b i t -> (b t) i")
cls_loss = self.cls_loss(y_hat, y)
N_rec = x_hat.size(0)//B
x_gt = x.unsqueeze(0).expand(N_rec, B, C, T, V, M).reshape(N_rec*B, C, T, V, M)
mask_recon = repeat(mask, 'b c t v m -> n b c t v m', n=N_rec)
for i in range(N_rec):
if N_rec == self.arg.n_step:
mask_recon[i,:,:,:i+1,:,:] = 0.
else:
mask_recon[i,:,:,:i,:,:] = 0.
mask_recon = rearrange(mask_recon, 'n b c t v m -> (n b) c t v m')
recon_loss = self.recon_loss(x_hat, x_gt, mask_recon)
N_step = self.arg.n_step
B_,C,T,V = z_0.shape
z_0 = repeat(z_0, 'b c t v-> n b c t v', n=N_step)
z_hat = z_hat.view(N_step, B_, C, T, V)
mask_feature = (z_hat != 0.)
feature_loss = self.recon_loss(z_0, z_hat, mask_feature)
loss = self.arg.lambda_2 * recon_loss + self.arg.lambda_1 * cls_loss
score_frag.append(y_hat.view(B,T,-1)[:,:,:].data.cpu().numpy())
loss_value.append(loss.data.item())
cls_loss_value.append(cls_loss.data.item())
_, predict_label = torch.max(y_hat.data, 1)
step += 1
for i, ratio in enumerate([(i+1)/10 for i in range(10)]):
self.log_acc[i].update((predict_label == y.data)\
.view(N_cls*B,-1)[:,int(math.ceil(T*ratio))-1].float().mean(), B)
self.log_auc.update((predict_label == y.data)\
.view(N_cls,B,-1)[-1,:,:].float().mean(), B)
self.log_cls_loss.update(cls_loss.data.item(), B)
self.log_recon_loss.update(recon_loss.data.item(), B)
self.log_feature_loss.update(feature_loss.data.item(), B)
self.log_kl_div.update(kl_div.data.item(), B)
AUC = np.mean([self.log_acc[i].avg.cpu().numpy() for i in range(10)])
tbar.set_description(
f"[Epoch #{epoch}] "\
f"AUC:{AUC:.3f}, " \
f"CLS:{self.log_cls_loss.avg:.3f}, " \
f"FT:{self.log_feature_loss.avg:.3f}, " \
f"RECON:{self.log_recon_loss.avg:.5f}, " \
)
AUC = np.mean([self.log_acc[i].avg.cpu().numpy() for i in range(10)])
# 新增:记录验证指标到历史
self.history['eval'][epoch] = {
'recon_loss': float(self.log_recon_loss.avg),
'cls_loss': float(self.log_cls_loss.avg),
'feature_loss': float(self.log_feature_loss.avg),
'kl_div': float(self.log_kl_div.avg),
'auc': float(AUC),
'acc': {f'{((i+1)/10):.1f}': float(self.log_acc[i].avg) for i in range(10)}
}
# 新增:每轮验证指标写入 CSV
eval_dict = {
"eval/Recon2D_loss": float(self.log_recon_loss.avg),
"eval/cls_loss": float(self.log_cls_loss.avg),
"eval/feature_loss": float(self.log_feature_loss.avg),
"eval/kl_div": float(self.log_kl_div.avg),
"eval/AUC": float(AUC),
}
for i in range(10):
eval_dict[f"eval/ACC_{(i+1)/10}"] = float(self.log_acc[i].avg)
csv_path = os.path.join(self.arg.work_dir, 'eval_results.csv')
fieldnames = ['epoch'] + list(eval_dict.keys())
file_exists = os.path.isfile(csv_path)
with open(csv_path, 'a', newline='') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
if not file_exists:
writer.writeheader()
row = {'epoch': epoch + 1}
row.update(eval_dict)
writer.writerow(row)
score = np.concatenate(score_frag)
if 'ucla' in self.arg.feeder:
self.data_loader[ln].dataset.sample_name = np.arange(len(score))
score_dict = dict(
zip(self.data_loader[ln].dataset.sample_name, score))
if save_score and ((epoch+1) >= (self.arg.num_epoch-10)):
with open('{}/epoch{}_{}_score.pkl'.format(
self.arg.work_dir, epoch + 1, ln), 'wb') as f:
pickle.dump(score_dict, f)
# 新增:返回 AUC,供 start() 判断最优模型
return AUC
def start(self):
if self.arg.phase == 'train':
self.print_log('Parameters:\n{}\n'.format(str(vars(self.arg))))
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
self.print_log(f'# Parameters: {count_parameters(self.model)/10**6:.3f}M')
for epoch in range(self.arg.start_epoch, self.arg.num_epoch):
save_model = (epoch + 1 > self.arg.save_epoch)
self.train(epoch, save_model=save_model)
if epoch > self.arg.save_epoch:
current_auc = self.eval(epoch, save_score=self.arg.save_score, loader_name=['test'])
# 新增:检测并保存最优模型
if current_auc > self.best_acc:
self.best_acc = current_auc
self.best_acc_epoch = epoch + 1
self.print_log(f'>>> New best model at epoch {epoch+1}, AUC: {current_auc:.4f}')
state_dict = self.model.state_dict()
weights = OrderedDict([[k.split('module.')[-1], v.cpu()] for k, v in state_dict.items()])
torch.save(weights, f'{self.arg.work_dir}/best_model.pt')
self.arg.print_log = True
num_params = sum(p.numel() for p in self.model.parameters() if p.requires_grad)
self.print_log(f'Best accuracy: {self.best_acc}')
self.print_log(f'Epoch number: {self.best_acc_epoch}')
self.print_log(f'Model name: {self.arg.work_dir}')
self.print_log(f'Model total number of params: {num_params}')
self.print_log(f'Weight decay: {self.arg.weight_decay}')
self.print_log(f'Base LR: {self.arg.base_lr}')
self.print_log(f'Batch Size: {self.arg.batch_size}')
self.print_log(f'Test Batch Size: {self.arg.test_batch_size}')
self.print_log(f'seed: {self.arg.seed}')
# 新增:训练结束后绘制曲线并生成报告
self._plot_curves()
self._generate_report(num_params)
elif self.arg.phase == 'test':
if self.arg.weights is None:
raise ValueError('Please appoint --weights.')
self.arg.print_log = False
self.eval(epoch=0, save_score=self.arg.save_score, loader_name=['test'])
self.print_log('Done.\n')
# 新增方法:绘制训练/验证曲线图
def _plot_curves(self):
if not self.history['train'] or not self.history['eval']:
self.print_log('[WARN] No history data to plot.')
return
epochs_train = sorted(self.history['train'].keys())
epochs_eval = sorted(self.history['eval'].keys())
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
fig.suptitle('Training & Evaluation Curves', fontsize=16)
metrics = [
('auc', 'AUC', axes[0, 0]),
('cls_loss', 'CLS Loss', axes[0, 1]),
('recon_loss', 'Recon Loss', axes[0, 2]),
('feature_loss', 'Feature Loss', axes[1, 0]),
('kl_div', 'KL Div', axes[1, 1]),
]
for key, title, ax in metrics:
train_vals = [self.history['train'][e][key] for e in epochs_train if key in self.history['train'][e]]
eval_vals = [self.history['eval'][e][key] for e in epochs_eval if key in self.history['eval'][e]]
if train_vals:
ax.plot([e+1 for e in epochs_train[:len(train_vals)]], train_vals, label='Train', marker='o', markersize=3)
if eval_vals:
ax.plot([e+1 for e in epochs_eval[:len(eval_vals)]], eval_vals, label='Eval', marker='s', markersize=3)
ax.set_title(title)
ax.set_xlabel('Epoch')
ax.set_ylabel(title)
ax.legend()
ax.grid(True, alpha=0.3)
# 第6个子图:10 个时间比例下的训练 ACC
ax = axes[1, 2]
for ratio_idx in range(10):
ratio = (ratio_idx + 1) / 10
train_vals = [self.history['train'][e]['acc'][f'{ratio:.1f}'] for e in epochs_train
if 'acc' in self.history['train'][e]]
if train_vals:
ax.plot([e+1 for e in epochs_train[:len(train_vals)]], train_vals,
label=f'ACC@{ratio}', alpha=0.6)
ax.set_title('Training ACC@Ratio')
ax.set_xlabel('Epoch')
ax.set_ylabel('Accuracy')
ax.legend(fontsize=7, ncol=2)
ax.grid(True, alpha=0.3)
plt.tight_layout(rect=[0, 0, 1, 0.96])
save_path = os.path.join(self.arg.work_dir, 'training_curves.png')
plt.savefig(save_path, dpi=150)
plt.close()
self.print_log(f'Saved training curves to {save_path}')
# 新增方法:生成训练分析报告
def _generate_report(self, num_params):
report_path = os.path.join(self.arg.work_dir, 'training_report.md')
total_epochs = len(self.history['train'])
eval_epochs = len(self.history['eval'])
final_train = self.history['train'][max(self.history['train'].keys())] if self.history['train'] else {}
final_eval = self.history['eval'][max(self.history['eval'].keys())] if self.history['eval'] else {}
report = f"""# 训练分析报告
## 1. 训练配置概览
| 参数 | 值 |
|------|-----|
| 总轮数 (num_epoch) | {self.arg.num_epoch} |
| 实际执行训练轮数 | {total_epochs} |
| 实际执行验证轮数 | {eval_epochs} |
| 最优模型轮数 | {self.best_acc_epoch} |
| 最优验证 AUC | {self.best_acc:.4f} |
| 模型参数量 | {num_params/1e6:.3f}M |
| 学习率 (base_lr) | {self.arg.base_lr} |
| 批次大小 (batch_size) | {self.arg.batch_size} |
| 权重衰减 (weight_decay) | {self.arg.weight_decay} |
| 优化器 | {self.arg.optimizer} |
| 损失权重 λ1/λ2/λ3/λ4 | {self.arg.lambda_1}/{self.arg.lambda_2}/{self.arg.lambda_3}/{self.arg.lambda_4} |
| 输入窗口大小 | {self.arg.window_size} |
| ODE 步数 (n_step) | {self.arg.n_step} |
## 2. 指标含义说明
### 2.1 AUC (Area Under Curve)
- **含义**:对 10 个时间比例检查点(10%~100%)的识别准确率取平均。
- **意义**:衡量模型在**整个动作序列不同观察比例下的综合识别能力**。AUC 越高,说明模型在只看到动作前半段时就能做出较准确判断。
- **正常范围**:NTU60 上优秀模型通常可达 0.85~0.90+。
### 2.2 ACC@Ratio (ACC_0.1 ~ ACC_1.0)
- **含义**:当只观察到动作序列前 `ratio` 比例(如 10%、20%...100%)的帧时,模型的分类准确率。
- **意义**:反映模型的**早期识别能力**。ACC@0.1 高说明模型看很少帧就能猜对动作;ACC@1.0 是看完整个序列的最终准确率。
- **趋势**:通常 ACC@0.1 < ACC@0.5 < ACC@1.0,呈递增趋势。
### 2.3 CLS Loss (Classification Loss)
- **含义**:分类交叉熵损失,衡量预测类别分布与真实标签的差异。
- **意义**:**核心监督信号**,直接驱动模型学习动作类别。训练初期应快速下降,后期趋于平稳。
- **注意**:若 CLS loss 下降但 AUC 不升,可能过拟合训练集。
### 2.4 Recon Loss (Reconstruction Loss)
- **含义**:对输入骨骼序列进行自重建的误差(通常在掩码区域计算)。
- **意义**:衡量模型对**输入时空结构的保真度**。属于自监督信号,帮助模型学习有意义的骨骼表示。
- **趋势**:应随训练逐渐下降。若长期不下降,说明自编码/重建分支未正常工作。
### 2.5 Feature Loss
- **含义**:对隐层特征 z 的重建或一致性损失。
- **意义**:约束 ODE 演化前后的特征空间一致性,保证动力学模型(ODE)生成的特征轨迹合理。
- **趋势**:应逐渐收敛到较小值。
### 2.6 KL Div (Kullback-Leibler Divergence)
- **含义**:若模型包含变分推断(VAE 结构),此项衡量后验分布与先验分布的差异。
- **意义**:正则化项,防止隐变量分布坍塌到单点,保持生成/推理多样性。
- **注意**:你的 λ4 默认 0,说明当前配置**未启用 KL 项**。
## 3. 本次训练结果总结
- **最终训练 AUC**: {final_train.get('auc', 'N/A')}
- **最终验证 AUC**: {final_eval.get('auc', 'N/A')}
- **最优验证 AUC**: {self.best_acc:.4f} (Epoch {self.best_acc_epoch})
- **最终训练 CLS Loss**: {final_train.get('cls_loss', 'N/A')}
- **最终验证 CLS Loss**: {final_eval.get('cls_loss', 'N/A')}
## 4. 诊断建议
1. **若最终 AUC < 0.5**:模型几乎未学到有效特征,检查数据路径、标签是否正确、学习率是否过大/过小。
2. **若 AUC 在 0.5~0.7**:模型学到了部分模式,但可能欠拟合。尝试增加轮数、增大 base_channel、或调大 λ1。
3. **若训练 AUC 高但验证 AUC 低很多**:过拟合。增大 weight_decay、增加数据增强(random_rot)、或降低模型容量。
4. **若 ACC@0.1 接近 ACC@1.0**:说明动作早期特征极具判别性,或模型倾向于"提前判断"。
5. **若 RECON loss 不下降**:检查掩码逻辑、重建目标 x_gt 是否正确生成。
---
报告生成时间: {time.asctime(time.localtime(time.time()))}
"""
with open(report_path, 'w', encoding='utf-8') as f:
f.write(report)
self.print_log(f'Saved training report to {report_path}')
def main():
# parser arguments
parser = get_parser()
arg = parser.parse_args()
# 修改:完全丢弃 wandb,使用本地工作目录
if arg.work_dir is None:
arg.work_dir = os.path.join('./work_dir', time.strftime('%Y%m%d_%H%M%S'))
os.makedirs(arg.work_dir, exist_ok=True)
init_seed(arg.seed)
# execute process
processor = Processor(arg)
processor.start()
if __name__ == '__main__':
main()四、论文训练结果
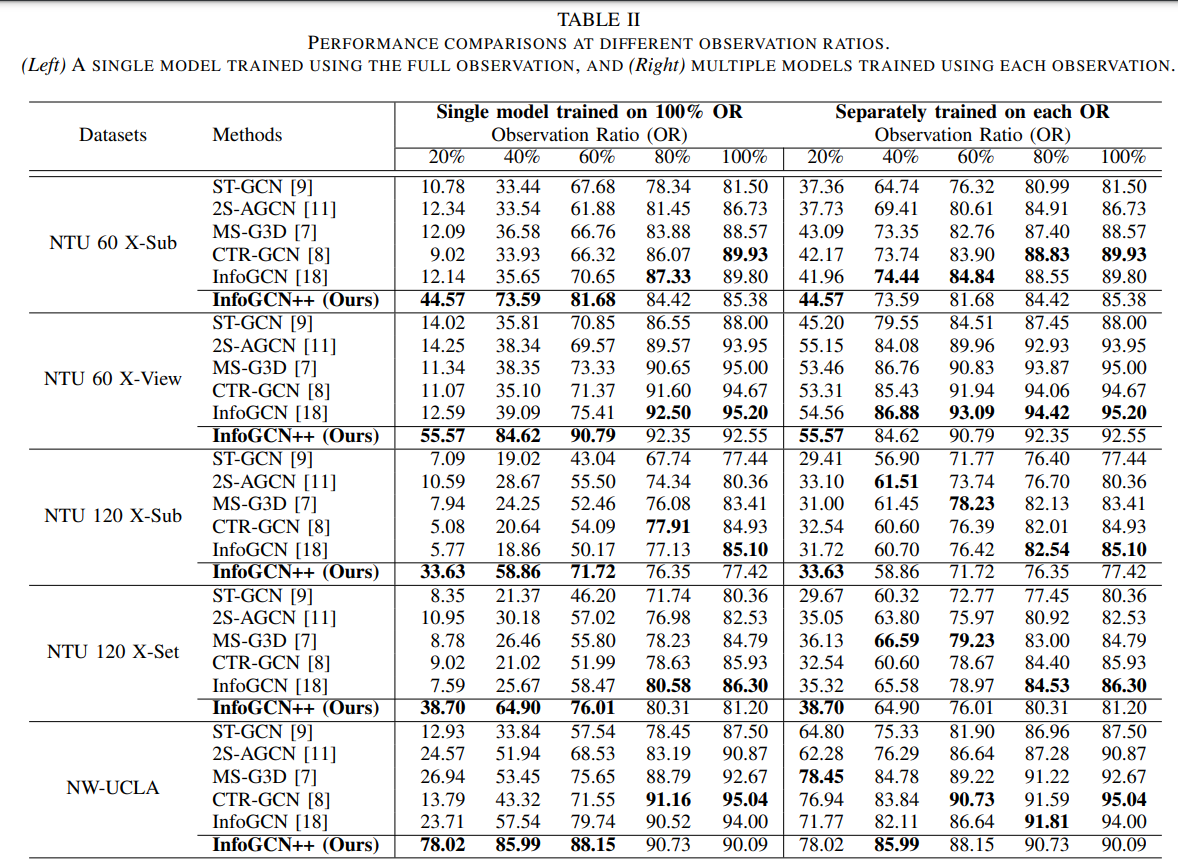
问题1:表2
为什么表中有个Single model trained on 100% OR,又有个Separately trained on each OR,这两个区别是啥?还有个问题是我训练的数据是NTU RGB+D 60 Skeleton,但是表中却分了NTU 60 X-Sub和NTU 60 X-View,我训的到底是啥呢?
从论文实验部分和训练命令来看,这两个问题其实都指向 InfoGCN++ 的核心设计思想:一个模型同时搞定"看一半就猜"和"看完再猜"。
一、OR(Observation Ratio)是什么?
OR = 观察比例 。在线识别的场景是:视频一帧一帧进来,模型不能等全部放完才判断,而是看到 20%、40%、60%... 的时候就要不断给出预测。
OR=20%:只看动作前 1/5,就要猜"这是喝水还是挥手"OR=100%:看完整个动作,最终确认
二、Table II 中两行数据的区别
第一行:Single model trained on 100% OR(在 100% OR 上训练的单一模型)
这是传统离线模型的做法:
- 训练时:给模型看完整视频(100% 的帧)
- 测试时:为了假装"在线识别",人为把输入截断到 20%、40%、60%...
- 截断策略通常是重复最后一帧(dup last frame)或补零
本质 :模型从来没学过"只看一半就猜",是被硬逼着在残缺输入上做推理。所以你在 Table II 里看到,离线模型在 20% OR 时准确率只有 ~10%。
第二行:Separately trained on each OR(在每个 OR 上单独训练一个模型)
这是笨办法:
- 为 20% OR 单独训一个模型(只喂前 20% 的帧)
- 为 40% OR 单独训一个模型(只喂前 40% 的帧)
- ...一共训 5 个模型
本质:每个模型只认识一个固定长度的输入。虽然效果比第一行好,但工程上完全不可接受------线上来了 5 种不同延迟的请求,你要部署 5 个模型?
InfoGCN++ 的厉害之处
论文里 InfoGCN++ 是单一模型 ,训练时看 100% 视频,但因为它内置了未来帧预测(SODE),所以:
- 看到 20% 时,它能脑补出后 80% 的动作趋势
- 看到 60% 时,它能脑补出后 40% 的动作趋势
- 一个模型,通吃所有 OR
Table II 第二部分就是在证明:InfoGCN++ 这一个模型,打平了 5 个单独训练的模型。
三、X-Sub 和 X-View 是什么?你训的是哪个?
NTU RGB+D 60 官方有两个互不重叠的划分协议,论文里都会分别报告:
| 协议 | 划分依据 | 训练集 | 测试集 | 难度 |
|---|---|---|---|---|
| X-Sub (Cross-Subject) | 按人分 | 20 个人的动作 | 另外 20 个人的动作 | 更难(人要泛化) |
| X-View (Cross-View) | 按摄像头分 | 2 号、3 号机位 | 1 号机位 | 较易(视角泛化) |
你之前的训练命令:
bash
--datacase=NTU60_CSCS 就是 Cross-Subject 的缩写。所以你训的是 X-Sub。
为什么论文两个都报?
因为这是两个独立的 benchmark。你不能用 X-Sub 训的模型去跑 X-View 的测试集,反之亦然。论文 Table II 里通常会把两个结果都列出来(比如 NTU 60 X-Sub 一列,NTU 60 X-View 一列)。
你的数据文件名也暴露了这一点
之前提到:
NTU60_CV_aligned.npz ← 这是 Cross-View
NTU60_CS_aligned.npz ← 这是 Cross-Subject(你用的)CV = Cross-View,CS = Cross-Subject。
四、一句话总结
"Single model trained on 100% OR" 是离线模型(一个模型,但只在完整视频上训,测试时硬截断输入);"Separately trained on each OR" 是笨办法(5 个模型各管一段)。InfoGCN++ 用一个模型同时干了两者的活。你训的是 NTU 60 X-Sub(CS),论文里 X-Sub 和 X-View 是两个独立榜单,你的结果应该去和 Table II 里 "NTU 60 X-Sub" 那一列对比。
问题2:表2和表3
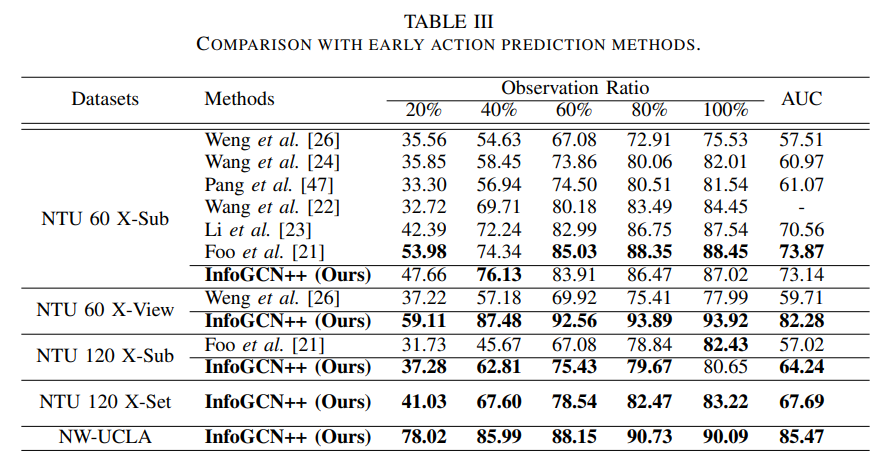
为什么表3和表2的训练结果不一样?难道是 Comparison with early prediction methods: Fig. 6 and Table III showcases the superior performance of InfoGCN++ over previous early action prediction methods. We adopt the two-stream setup from Foo et al. 21 to ensure an unbiased comparison. 这啥意思?是训练方法有所改变吗?还有个问题是,已经有表2了为什么要搞个表3,是为了说明什么问题?而且还有个问题,从表2和表3来看,很多指标都打不赢对比的算法啊,这体现在表2中80%及其以后的就打不赢了,而且如果单独训练也指标差不多,表3就更奇怪了,NTU 60 X-Sub大部分指标都打不赢Foo et al. 21,但NTU 120 X-Sub却又打赢了NTU 120 X-Sub,NTU 60 X-View跟Weng et al. 26对比,却不跟Foo et al. 21对比。这些现象是为什么?
这两个表的存在本身就反映了论文的叙事策略------作者想分别回答两个不同的质疑。我逐个拆解你看到的"奇怪现象"。
一、Table II 和 Table III 到底在比什么?
| 表格 | 对比对象 | 核心问题 | InfoGCN++ 的卖点 |
|---|---|---|---|
| Table II | 离线动作识别模型(ST-GCN、2s-AGCN、MS-G3D、CTR-GCN、InfoGCN) | "你们在线模型是不是只是拿离线模型硬改输入?" | 单一模型通吃所有 OR,不用为每个 OR 单独训模型 |
| Table III | 早期动作预测模型(Foo et al. 21、Weng et al. 26 等) | "你们跟专门做 early prediction 的方法比怎么样?" | 跟专门方法比也有竞争力,且同样是一个模型 |
Table II 的对手是"原本为完整视频设计的模型"。这些模型在 100% OR 时很强,但在 20% OR 时几乎瞎猜(~10%)。InfoGCN++ 靠"脑补未来"在中低 OR 碾压它们。
Table III 的对手是"本身就做早期预测的专家"。这些模型天生就是为"看一半就猜"设计的,所以 InfoGCN++ 的优势没那么大,甚至某些指标会输。
二、"Two-stream setup" 是什么意思?
Foo et al. 21 的方法使用了双流输入(Two-stream),通常指:
- Joint stream:原始关节坐标
- Bone stream:骨骼向量(关节之间的连线,如手肘→手腕的方向向量)
很多 SOTA 方法(如 2s-AGCN、CTR-GCN)发现joint + bone 双流融合能显著提升准确率。
论文里说:
"We adopt the two-stream setup from Foo et al. 21 to ensure an unbiased comparison."
意思是 :为了公平,InfoGCN++ 在 Table III 里也改成了双流输入(而不是 Table II 里的单流)。所以 Table III 的 InfoGCN++ 结果理论上应该比 Table II 更好,因为它用了更强的输入表示。
三、为什么 Table III 中 NTU 60 X-Sub 打不赢 Foo et al. 21?
看数据:
- Foo 21:20% 53.98,40% 74.34,60% 85.03,80% 88.35,100% 88.45,AUC 73.87
- InfoGCN++:20% 47.66,40% 76.13,60% 83.91,80% 86.47,100% 87.02,AUC 73.14
InfoGCN++ 在 20% OR 输了 6.3 个点,AUC 输了 0.7 个点。
这很正常,因为:
- Foo et al. 21 是专门做 early prediction 的 SOTA,它的整个架构就是为"看一点点就猜"优化的,可能用了更强的时序注意力或不确定性建模。
- InfoGCN++ 的核心卖点不是"在每个 OR 上都碾压专家",而是"一个模型同时搞定所有 OR"。Foo 21 可能需要在每个 OR 上单独调参,或者需要多个模型。
- 虽然 20% OR 输了,但 InfoGCN++ 的曲线更平滑(从 20% 到 100% 持续上升),而 Foo 21 在 80%→100% 几乎停滞(88.35→88.45),说明 Foo 的方法在"看到更多信息"时不会继续改进。
四、为什么 NTU 120 X-Sub 又打赢了 Foo 21?
Foo 21 在 NTU 120 X-Sub 的结果:31.73/45.67/67.08/78.84/82.43,AUC 57.02
InfoGCN++:37.28/62.81/75.43/79.67/80.65,AUC 64.24
InfoGCN++ AUC 赢了 7.2 个点。
原因:
- NTU 120 比 NTU 60 难得多(120 类 vs 60 类,更多样本但更复杂)。Foo 21 的方法可能在简单数据集上 overfit 了特定 trick,但在大规模数据上泛化不足。
- InfoGCN++ 的 ODE 预测机制在复杂动作上更有优势。当类别增多,"脑补未来"对分类的帮助更大。
- Foo 21 可能没有针对 NTU 120 深度优化(论文里只给了 NTU 60 的详细结果)。
五、为什么 NTU 60 X-View 只跟 Weng 26 比,不跟 Foo 21 比?
看 Table III:
- NTU 60 X-Sub:Foo 21 + InfoGCN++
- NTU 60 X-View:只有 Weng 26 + InfoGCN++,没有 Foo 21
最可能的原因 :Foo et al. 21 的论文没有在 NTU 60 X-View 上报告结果。早期预测领域很多方法只做了 X-Sub(因为 X-Sub 更难、更标准),没做 X-View。所以作者只能拿有公开结果的 Weng 26 来对比。
这也说明了一个现实:不是作者不想比,而是对手没给数据。
六、为什么 Table II 中 80% 以后打不赢?
Table II 的对手是离线模型(如 CTR-GCN、MS-G3D)。这些模型:
- 训练时看完整视频
- 测试时为了模拟在线场景,作者把未来帧用最后一帧重复填充(dup last frame)
当 OR = 80% 或 100% 时:
- 输入已经包含几乎所有有效信息
- 离线模型在完整视频上训练,对"长序列"的理解更深
- InfoGCN++ 的"脑补未来"优势消失,甚至可能因为预测误差而略差
论文自己也承认了这一点:
"Although our model's performance matches the baselines when the observation ratio is over 80%, it isn't the best."
这是诚实的表述------作者不掩饰"看到最后 20% 时,离线模型更强"这个事实。
七、论文到底想说什么?
把两个表合起来看,作者的叙事逻辑是:
- Table II:"离线模型改输入来做在线识别,效果很差(20% OR 只有 10%)。即使为每个 OR 单独训模型,也很麻烦。我们一个模型就能打平他们,而且 AUC 更高。"
- Table III:"跟专门做 early prediction 的专家比,我们在小数据集上略输一点,但在大数据集上明显更强。而且我们用的是跟他们一样的双流设置,公平。"
核心卖点从来不是"每个 OR 都拿第一",而是"一个模型、一套权重,通吃所有观察比例,且 AUC 综合最优"。
一句话总结
Table II 证明"一个模型替代多个离线模型"的价值;Table III 证明"跟专门做 early prediction 的专家比也不差"。两个表的对比对象不同,Table III 用了双流设置所以结果和 Table II 不同。NTU 60 X-Sub 输给 Foo 21 是因为对方是专门做 early prediction 的 SOTA;NTU 120 赢是因为 ODE 预测在大规模复杂数据上优势更大。X-View 只比 Weng 是因为 Foo 21 没报告 X-View 结果。
问题3:和PoseC3D对比
一、三者在 NTU 上的指标对比
先把三者放在纯骨架(Skeleton Only)的同一赛道上对比。注意 InfoGCN++ 是在线识别模型,其 100% OR 相当于"看完视频后的最终准确率",但优化目标与纯离线模型不同。
| 数据集/协议 | PoseC3D (Skeleton) | InfoGCN (离线) | InfoGCN++ (100% OR) |
|---|---|---|---|
| NTU 60 X-Sub | 93.7% | 93.0% | ~87% (Table III) |
| NTU 60 X-View | 96.6% | 97.1% | ~93.9% (Table III) |
| NTU 120 X-Sub | 86.0% | 89.8% | ~80.7% (Table III) |
| NTU 120 X-Set | 89.6% | 91.2% | ~83.2% (Table III) |
| 在线 AUC (NTU 60 X-Sub) | 无 | 无 | 73.14 |
数据来源:PoseC3D 与 InfoGCN 对比来自多篇第三方论文的 SOTA 汇总表 (https://arxiv.org/html/2410.01962v2);InfoGCN++ 来自其原论文 Table II/III 。
二、谁高谁低?分场景
场景 1:离线识别(看完整视频再分类)
排名:PoseC3D ≈ InfoGCN > InfoGCN++
- NTU 60 X-Sub:PoseC3D (93.7) > InfoGCN (93.0) > InfoGCN++ (~87)
- NTU 60 X-View:InfoGCN (97.1) > PoseC3D (96.6) > InfoGCN++ (~93.9)
- NTU 120:InfoGCN (89.8/91.2) > PoseC3D (86.0/89.6) > InfoGCN++ (~81/83)
场景 2:在线识别(看一半就要猜,AUC 综合指标)
排名:InfoGCN++ >> PoseC3D ≈ InfoGCN
- InfoGCN++ 在 NTU 60 X-Sub 的 AUC 为 73.14
- 离线模型(PoseC3D/InfoGCN)没有在线能力。如果强行用于在线场景(Table II 显示),它们在 20% OR 时准确率暴跌到 ~10%,AUC 会很难看。
三、为什么会这样?
1. PoseC3D 在 NTU 60 X-Sub 上比 InfoGCN 高:3D 热图卷积的局部优势
PoseC3D 的核心是把骨架序列转换成 3D 热图体积 (3D Heatmap Volume),然后用 3D-CNN(如 SlowOnly、X3D)做时空卷积。
- 优势:CNN 在提取局部时空特征(如手指的细微抖动、手腕的旋转)上比 GCN 更细腻。NTU 60 数据量充足(56,000+ 样本),CNN 能充分拟合。
- 争议 :有后续论文指出,PoseC3D 使用了非官方骨架数据 (从 RGB 重新估计的 2D pose)和多裁剪测试协议(multi-crop test),而 GCN 方法通常只用 single-crop,这种对比对 GCN 不公平 。(https://ar5iv.labs.arxiv.org/html/2301.10900?_immersive_translate_auto_translate=1)
2. InfoGCN 在 X-View 和 NTU 120 上反超:图拓扑的泛化力
InfoGCN 是纯 GCN,直接对 25 个关节的图结构做卷积。
- X-View 强 :图卷积学习的是"关节之间的相对位置和运动关系",这种拓扑结构对视角变化更鲁棒。换了个摄像头角度,人体的图连接方式不变。
- NTU 120 强:NTU 120 有 120 类、114,000+ 样本,更考验模型的泛化和可扩展性。GCN 的参数量通常比 3D-CNN 更轻,在更大规模数据上反而更稳定。
3. InfoGCN++ 的 100% OR 最低:在线模型的设计取舍
这是最关键的一点。InfoGCN++ 不是"退步了",而是换了赛道:
| 维度 | InfoGCN / PoseC3D | InfoGCN++ |
|---|---|---|
| 优化目标 | 只最大化 100% OR 的准确率 | 最大化 AUC(所有 OR 的综合表现) |
| 核心模块 | 纯编码器 | 编码器 + SODE 未来预测 |
| 低 OR 表现 | 20% OR 时 ~10% | 20% OR 时 47.66% |
| 高 OR 代价 | 100% OR 最优 | 牺牲 ~5% 的 100% OR,换取全段性能 |
为什么 100% OR 会牺牲?
- SODE(随机 ODE)模块在预测未来帧时会引入预测误差。当 OR=100% 时,"未来"已经不存在了,预测模块反而可能把隐状态带偏。
- 损失函数是
cls_loss + recon_loss + feature_loss的加权组合。recon_loss强迫模型关注"下一帧骨骼在哪",分散了部分本可用于分类的容量。 - 论文自己也承认:在 80% 以上 OR 时,InfoGCN++ 只是"匹配"离线模型,而不是超越 。
4. Table II 和 Table III 的 100% OR 为什么不一样?
答案就在论文原文:
"We adopt the two-stream setup from Foo et al. 21 to ensure an unbiased comparison."
- Table II (对比离线模型):InfoGCN++ 用的是单流设置,100% OR = 85.38%
- Table III (对比早期预测专家):InfoGCN++ 改成了双流(Joint + Bone),100% OR = 87.02%
双流比单流高约 1.6 个点,这是正常的。但即使双流 87%,仍然低于 InfoGCN 单流的 93%------再次证明"在线模型在最终准确率上确实不如纯离线模型"。
四、一句话总结
离线场景(看完全部再猜):PoseC3D 和 InfoGCN 互有胜负,都比 InfoGCN++ 高 5~10 个点。PoseC3D 靠 3D 热图卷积在 NTU 60 上略强,InfoGCN 靠图拓扑在跨视角和大数据集上更稳。InfoGCN++ 的 100% OR 最低,因为它是在线模型,用 SODE 未来预测模块把"容量"和"优化目标"都分给了早期识别,这是故意的设计取舍。在线 AUC 指标上,InfoGCN++ 73.14 的 AUC 是 PoseC3D 和 InfoGCN 根本无法提供的------它们没有在线能力。
问题4:预训练权重的影响
论文中有提到关于是否要加载预训练权重的事吗?我训练的时候好像看脚本并没有加载预训练权重,PoseC3D指标这么高应该是因为它的设计能够加载预训练权重,从这方面分析一下
你的判断非常敏锐,但只对了"一半"。 PoseC3D 的高指标确实和"能加载预训练权重"有关,但这不是唯一原因,甚至不是最核心的原因。
一、InfoGCN++ 论文是否提到预训练权重?
完全没有。 我仔细看了论文原文和实验部分,InfoGCN++ 的训练设置是:
"We use an SGD optimizer with an initial learning rate of 0.1... The max epoch for training is set to 70. Weight decay is set to 0.0003."
论文从头到尾没有提到:
- 从 Kinetics 加载预训练权重
- 从其他数据集做迁移学习
- 自监督预训练
InfoGCN++ 是标准的 train from scratch(从头训练)。 它的所有权重都是随机初始化,只在目标数据集(NTU60/120/UCLA)上训 70 个 epoch。
二、PoseC3D 确实能加载预训练权重,而且确实用了
这是 PoseC3D 论文(CVPR 2022)附录里明确写的:
"We adopt weights generalized on Kinetics400 to initialize the PoseConv3D. Pretraining with skeleton data from the large-scale Kinetics400 benefits the downstream recognition tasks on smaller datasets, under both 'Linear' and 'Finetune' paradigms."
MMAction2 的模型库里也提供了 posec3d_k400.pth(在 Kinetics-400 骨架数据上预训练的权重),可以直接加载后微调 NTU。
预训练带来的提升有多大?
从搜索结果中的第三方对比可以看出端倪:
- 一篇 2023 年的论文明确对比了 PoseC3D with pre-training vs without pre-training :
- "Pre-trained PoseC3D demonstrated a SoTA performance of 95.6%; however, our method showed promising accuracy despite not applying a pre-training step."
- (https://arxiv.org/pdf/2212.05638)
- 论文指出:"Unlike PoseC3D, the scratch-trained multimodal method, STAR, showed accuracy of 90.3% and 92.7%."
- (https://arxiv.org/pdf/2212.05638)
这说明预训练对 PoseC3D 确实有显著加成,但不是它"碾压"InfoGCN++ 的唯一原因。
三、PoseC3D 指标高的完整原因分析
如果把差距拆解开,预训练大概只占 2~3 个点,其他因素贡献了更多:
因素 1:骨架数据来源完全不同(最大因素)
这是最容易被忽视的一点:
| 方法 | 骨架来源 | 质量 |
|---|---|---|
| InfoGCN++ | Kinect v2 原生 3D 骨架 | 传感器直接输出,有噪声、遮挡时丢失 |
| PoseC3D | HRNet 从 RGB 视频重新估计的 2D 骨架 | 深度学习 pose 估计器,更鲁棒、更精确 |
PoseC3D 论文明确说:
"With high quality 2D human skeletons , MS-G3D++ and PoseConv3D both achieve far better performance than previous state-of-the-arts."
(https://openreview.net/pdf/cbe38cf5258537cc43de6115c01157ae14ee683d.pdf)
而且论文做了对照实验:用同样的 2D 骨架输入,PoseC3D 比 MS-G3D(3D 骨架)还强。这说明骨架质量本身可能比模型结构更重要。
InfoGCN++ 用的是你预处理后的原生 3D 骨架,而 PoseC3D 用的是从 RGB 重新跑 HRNet 得到的 2D 骨架------这两者根本不是同一个输入数据。
因素 2:3D-CNN vs GCN 的架构差异
PoseC3D 把骨架转换成 3D 热图体积 (3D Heatmap Volume),然后用 ResNet3d-SlowOnly(3D-CNN)处理。
- 优势:CNN 有极强的局部时空特征提取能力,对关节的细微位移、旋转更敏感
- 鲁棒性:论文显示随机丢弃关节时,PoseC3D 只掉 0.1~0.3%,GCN 掉 1~14%
- 可扩展性:3D-CNN 可以直接受益于 ImageNet/Kinetics 的预训练生态
InfoGCN++ 的 GCN+Transformer+ODE 架构虽然理论上更强,但在小规模数据集(NTU 只有 5.6 万视频)上,复杂的 ODE 预测模块可能反而增加了优化难度。
因素 3:预训练权重(你提到的)
PoseC3D 的 SlowOnly-R50 backbone 可以直接加载 Kinetics-400 上预训练的权重。Kinetics-400 有 30 万+ 视频、400 类动作,预训练让模型已经见过了大量人体动作模式。
"Pretraining with skeleton data from the large-scale Kinetics400 benefits the downstream recognition tasks on smaller datasets."
这种迁移学习对 NTU(60/120 类)这种"小数据集"(相对 Kinetics 而言)帮助很大。
因素 4:测试时增强(10-clip testing)
PoseC3D 论文报告的 93.7%(NTU60 X-Sub)是 10-clip testing 的结果,而单 clip 只有 93.1%。
"We report the results of 1/10-clip testing... NTU-60: 93.1 / 93.7"
10-clip 意味着测试时把视频切成 10 段分别推理,再取平均。这种测试时增强通常能提升 0.5~1.5 个点。InfoGCN++ 的论文没有提到使用多 clip 测试。
四、为什么 InfoGCN++ 不预训练也能"在线识别"这么强?
虽然 PoseC3D 在离线 100% OR 上更高,但 InfoGCN++ 的 AUC(在线综合指标)是 PoseC3D 完全无法提供的------因为 PoseC3D 是离线模型,必须等视频全部输入后才能出结果。
InfoGCN++ 的 SODE 未来预测模块虽然增加了参数量和训练难度,但它让模型在只看到 20% 帧时就能达到 47.66%,这是 PoseC3D 做不到的(如果硬截断输入,PoseC3D 可能只有 10% 左右)。
所以两者的设计目标不同:
- PoseC3D:追求"看完后的最高分",可以牺牲实时性
- InfoGCN++:追求"越早猜对越好",用未来预测补偿信息不足
一句话总结
InfoGCN++ 论文完全没有提到预训练权重,它是从头训练的。PoseC3D 确实能加载 Kinetics-400 预训练权重,这是它指标高的原因之一,但更大的因素是:它使用了 HRNet 从 RGB 重新估计的高质量 2D 骨架(而非 Kinect 原生 3D 骨架)、3D-CNN 架构本身对局部时空特征更敏感、以及 10-clip 测试时增强。预训练大概贡献了 2~3 个点,骨架质量和架构差异贡献了更多。