一个大模型说"帮我查北京天气",你以为它真的去查了?
没有。它连天气预报网站都没访问过。
它干的事很简单------输出了一张JSON格式的"工单",写着{"city": "北京"},然后等你去执行。你拿到结果喂回去,它才假装自己"查了天气"。
这就是Function Calling的全部真相:LLM只决定"调什么、传什么参数",绝不自己执行。
今天我手敲了完整的FC代码跑通整个流程,还顺着这条线往前推------从FC到MCP到Skills到A2A,四个概念一条进化线,看透AI工具系统是怎么从"一个人干活"进化到"团队协作"的。
一、Function Calling的真相:两轮对话,LLM不下单不说话
FC的本质用一个类比就能理解:
想象你在公司是个项目经理,你不会写代码也不会焊电路,但你能看懂需求、判断该找谁干活。
- 你收到需求:"帮我查北京天气"
- 你不是自己去查------你输出一张工单:"调用get_weather函数,参数city='北京'"
- 你的下属(代码)拿着工单真正执行,拿到结果"25°C 晴"
- 下属把结果交回给你,你才生成最终回答:"北京今天25度,晴天"
整个流程是两轮对话:
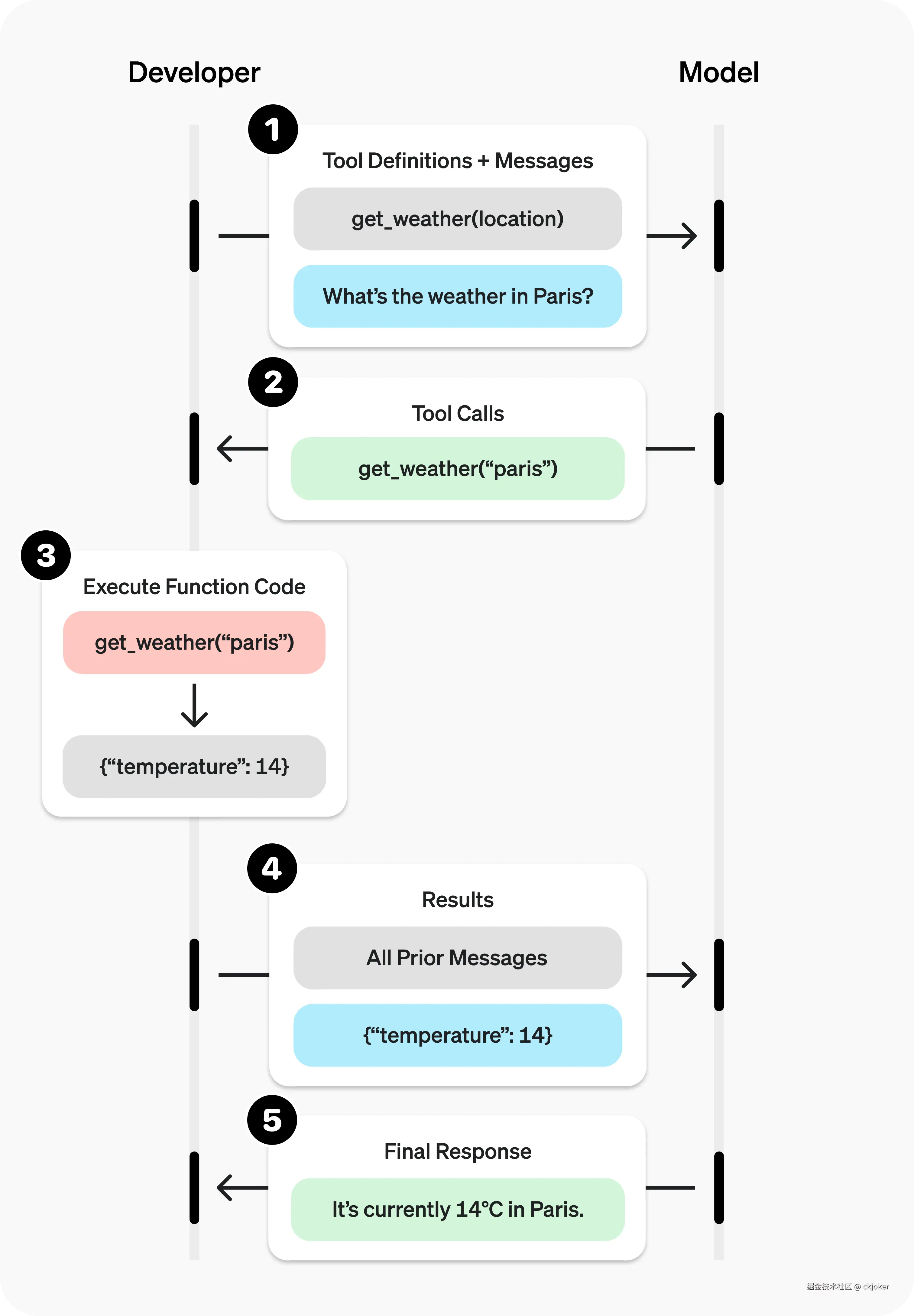
第1轮:用户提问 → LLM输出tool_calls(调用意图) → 你的代码执行函数 → 拿到结果 第2轮:把结果喂回去 → LLM生成最终回答
💡 三个反直觉的事实:
- 有tool_calls时,LLM的message.content是空的------不下单不说话
- arguments是JSON字符串,不是Python dict,你得手动json.loads()
- tool message三要素缺一不可:role="tool" + tool_call_id + content
还有一个有意思的事------LLM可以一次下多张工单。问"帮我查上海天气再算25加17",它会同时返回两个tool_call:一个调get_weather,一个调calculate。你的for循环逐个执行,结果一起喂回去,LLM一次汇总回答。这叫Parallel Tool Calling。
二、手敲代码验证:从定义工具到跑通闭环
代码不多,60行就搞定完整的两轮对话。
定义工具(给LLM看的产品说明书)
python
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如'北京'、'上海'"
}
},
"required": ["city"]
}
}
},
{
"type": "function",
"function": {
"name": "calculate",
"description": "执行数学计算,支持加减乘除",
"parameters": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "数学表达式,如'2+3'、'10*5'"
}
},
"required": ["expression"]
}
}
}
]⚠️ description是给LLM看的说明书,不是给代码执行的。写得好坏直接影响LLM能不能正确选择工具------这跟写API文档一个道理,描述模糊,调用者就迷路。
函数实现(真正干活的人)
python
def get_weather(city: str) -> str:
"""模拟天气查询"""
weather_data = {
"北京": "25°C,晴天,空气质量良",
"上海": "28°C,多云,东南风3级",
"深圳": "32°C,雷阵雨,湿度85%",
}
return weather_data.get(city, f"{city}:暂无天气数据")
def calculate(expression: str) -> str:
"""安全计算数学表达式"""
try:
allowed = set("0123456789+-*/.() ")
if not all(c in allowed for c in expression):
return "错误:表达式包含非法字符"
result = eval(expression)
return str(result)
except Exception as e:
return f"计算错误:{e}"完整的两轮对话闭环
python
def chat_with_tools(user_message: str):
"""完整的FC两轮对话"""
# ===== 第1轮:用户提问 → LLM返回调用意图 =====
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": user_message}],
tools=tools
)
message = response.choices[0].message
# LLM不需要工具,直接回答
if not message.tool_calls:
print(f"LLM直接回答: {message.content}")
return message.content
# LLM决定调用工具------把意图消息加入对话历史
messages = [
{"role": "user", "content": user_message},
message # tool_calls消息原样保留
]
# 逐个执行LLM要求的工具调用
for tc in message.tool_calls:
func_name = tc.function.name
func_args = json.loads(tc.function.arguments)
if func_name == "get_weather":
result = get_weather(**func_args)
elif func_name == "calculate":
result = calculate(**func_args)
else:
result = f"未知函数: {func_name}"
# 结果喂回------必须是tool message格式
messages.append({
"role": "tool",
"tool_call_id": tc.id, # 绑定到对应的调用ID
"content": result
})
# ===== 第2轮:工具结果喂回去 → LLM生成最终回答 =====
response2 = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools
)
return response2.choices[0].message.content跑出来的真实结果
场景1:天气查询(两轮对话)
css
用户: 北京今天天气怎么样?
🔧 LLM决定调用: get_weather({'city': '北京'})
📋 执行结果: 25°C,晴天,空气质量良
✅ 最终回答: 北京今天25°C,晴天,空气质量良,适合外出活动场景2:数学计算(两轮对话)
css
用户: 帮我算一下123乘以456
🔧 LLM决定调用: calculate({'expression': '123*456'})
📋 执行结果: 56088
✅ 最终回答: 123乘以456的结果是56088场景3:不需要工具(直接回答)
makefile
用户: 给我讲个冷笑话
LLM直接回答: 为什么企鹅的肚子是白色的?因为企鹅的手太短了,洗澡只能搓到肚子前面 🐧场景4:并行工具调用(一次下两张工单)
css
用户: 帮我查上海天气,再算25加17
🔧 LLM决定调用: get_weather({'city': '上海'})
📋 执行结果: 28°C,多云,东南风3级
🔧 LLM决定调用: calculate({'expression': '25+17'})
📋 执行结果: 42
✅ 最终回答: 上海28°C多云东南风3级,25+17=42四个场景跑通,FC的真相彻底清楚了。
三、FC不够用?从一个人干活到团队协作的四层进化
FC有个致命问题:工具定义硬编码在你的应用里,换个项目你得重写一遍。再换一个LLM应用,又写一遍。
这就好比你自己家里有一套工具箱,出门到公司还得再买一套------每个应用都是一座孤岛。
顺着这条线往前推,整个AI工具系统经历了四层进化:
第一层:Function Calling------一个人干活
FC的本质是LLM和工具的一次性约定。你写好tools定义,LLM按定义下单。
局限很明显:工具定义跟应用绑定,换应用重写。就像你一个人有套工具箱,去哪儿都得随身带着。
第二层:MCP------供应商入驻
MCP(Model Context Protocol)是Anthropic 2024年底推出的开放标准。核心变化是工具跟应用解耦了。
MCP的架构三层:
- Host:你的LLM应用(比如Claude Desktop、OpenClaw)
- Client:协议翻译层,把LLM的工具调用翻译成标准请求
- Server:工具提供者,自己描述"我有什么工具、参数是什么"
关键进化点------Server自描述:
FC(你替工具写简历):
- 每个应用自己定义tools
- 换应用 → 重写
- 工具没有话语权
MCP(工具自带简历):
- Server自己声明能力
- 所有Host自动发现
- 写一次,到处用
类比一下:FC是你去超市自己找货;MCP是电商平台,供应商自己上架产品目录,所有买家自动看到。
MCP还有三种能力:Tools(函数调用)、Resources(上下文数据)、Prompts(提示词模板)。今天重点是Tools,其他两个知道就行。
传输层两种方式:stdio (本地快,进程间通信)和SSE(HTTP远程,Java天然擅长)。
第三层:Skills------开源社区插件
Skill不是函数,是能力包。包含指令(SKILL.md)、实现代码、领域知识,甚至能让Agent自我改进。
跟MCP Tool的核心区别:
| 维度 | MCP Tool | Agent Skill | 直觉类比 |
|---|---|---|---|
| 是什么 | 一个函数 | 能力包(指令+代码+知识) | 电钻 vs 木工师傅 |
| 粒度 | 单次调用 | 多步骤流程 | 钻一下 vs 整个项目 |
| 智能度 | 无状态,调完就完 | 有状态,能判断怎么用 | 机器 vs 专家 |
| 进化 | 人工更新 | 自进化(反思后改进) | 手册 vs 实战经验 |
你身边就有真实例子------OpenClaw的Skill系统。你现在用的feishu-calendar、feishu-task不是简单的函数调用,它们包含SKILL.md(使用指南)、专用工具、错误处理策略。一个Skill让任何Agent都能操作飞书日历,不需要理解飞书API细节。
第四层:A2A------联邦协作
A2A(Agent to Agent)是Google 2025年推出的协议。到了这一层,Agent之间不再是"人调工具"的关系,而是平等协作。
跟前三层根本性的区别:
| 维度 | FC / MCP / Skills | A2A |
|---|---|---|
| 关系 | 主人 → 工具 | 同事 → 同事 |
| 决策 | 一个人(Host)决策 | 多个Agent协商决策 |
| 通信 | 单向(调用→返回) | 双向(委托+汇报+协商) |
| 主体性 | 工具无主体性 | 每个Agent有目标和边界 |
类比:FC/MCP = 你一个人干活偶尔叫外卖;Skills = 你学会了新技能越来越强;A2A = 你组建团队每个人有专长互相委托。
Google A2A协议的核心三件套:
- Agent Card(自描述卡片:"我是代码审查Agent,擅长Java审查")
- Task委托("帮我审查这段代码")
- 结果推送("审查完了,发现3个问题")
Java后端的直觉桥梁
作为Java程序员,这四层其实有熟悉的对应:
| 概念 | Java对应 | 理解桥梁 | 一句话 |
|---|---|---|---|
| FC | 反射 method.invoke() | 调哪个方法传什么参数 | 你写调用规则 |
| MCP | SPI | 服务自注册自描述 | 供应商自己上架 |
| Skills | Spring Boot Starter | 引入依赖就获得能力 | 能力包,引入即可 |
| A2A | 微服务 RPC/gRPC | 服务互相调用 | 团队互相委托 |
四、总结:一条线看清AI工具系统的进化方向
从FC到A2A,进化的方向很明确:从被动工具到自主协作。
- FC:LLM下单,你干活------最原始但最实用
- MCP:工具自带说明书,所有应用自动对接------解决复用问题
- Skills:能力包不是工具,能让Agent自进化------解决智能问题
- A2A:Agent之间平等协作------解决复杂任务问题
🧬 判断标准:多个LLM应用复用工具 → MCP;Agent可进化能力 → Skills;多Agent协作复杂任务 → A2A。大部分场景FC就够了,别过度设计。
对于Java后端同学,好消息是------MCP的SSE传输是HTTP-based,Java天然擅长;Spring AI已经支持FC和MCP Client;Skills概念跟Spring Boot Starter一模一样,理解门槛为零。
说白了,这四层进化就是Java生态走过的路:从反射调用 → SPI插件机制 → Starter能力包 → 微服务RPC。换了个皮,内核一模一样。
完整代码在GitHub
有问题评论区聊,下篇讲 LangChain4j agentic模块:@Agent注解 + AgenticScope + 工具函数定义------从Python战场回到Java,用注解驱动的方式玩Agent。