级联式 WAM 系列的第七站。上一篇 Gen2Act 选择不微调视频模型、让策略直接消化人类视频;这一篇 Vidar 走的是另一条路------把一个互联网级视频大模型继续在具身领域"深造",让它学会把人类操作视频转译成机器人执行视频 ,再用一个只盯着"交互关键区"的逆动力学模型把动作抠出来。它最惊人的卖点是:只用 20 分钟的人类演示,就能让一台从没见过的新机器人上手干活。
Vidar 在 WAM(World Action Model,世界动作模型,即"先在脑海里预演未来、再据此行动"的一类具身模型)里属于级联式中的"像素空间 + 学习式动作提取"一支,与 UniPi、TesserAct、Gen2Act 同源。但它瞄准的痛点格外具体、也格外现实------怎样让一套操作能力低成本地迁移到全新的机器人本体上?
它给出的答案是一句很有号召力的口号:"一个先验,多种本体"(one prior, many embodiments)。即先砸资源训一个强大、通用、廉价的视频先验,再对每台具体机器人只做极少量的"对齐"。
一、要解决什么问题:每换一台机器人,就要重训一遍?
把通用操作能力扩展到新的机器人平台,长期以来卡在两个死结上:
- 数据的"同质化"诅咒 :每一种机器人本体,通常都要采集一大批同构的(同一种机器人、同一套相机布局)演示数据才能训出能用的策略。换一台机器人、挪一下相机,往往就得从头再来一遍。
- 端到端"像素到动作"的脆弱:那种直接从画面像素映射到动作的策略,一旦背景换了、视角变了,性能就容易崩------因为它把背景里的无关杂物也一股脑学进了决策依据。
打个比方:这就像每招一个新员工,都得让他从认字开始重学一遍整套业务,而且只要换了间办公室、挪了张桌子,他就不会干活了。显然不可持续。
Vidar 想要的是一个"老师傅 + 速成"的模式:先有一个见多识广、懂得操作物理规律的"老师傅"(视频先验),新来的机器人只需跟着学很短一段时间(20 分钟演示),就能把老师傅的本事对齐到自己的身体上。
为什么把"先验"放在视频这个层面特别合理?因为操作任务的核心知识,很大程度上是与机器人本体无关的物理常识------"杯子被推会沿桌面滑动""抽屉沿导轨被拉出""布料被抓起会褶皱"。这些规律对人手、对夹爪、对双臂机器人都成立。视频生成模型在互联网海量画面上学到的,恰恰就是这层"东西会怎么动"的通用先验。而每台机器人各自不同的,只是"我这具身体的关节如何运动、相机装在哪、看到的画面长什么样"这些相对表层、容易快速学到的东西。把通用的沉淀进先验、把本体相关的留给轻量对齐,分工就清晰了。
二、核心思想与直觉:先验 + 适配器,两件套
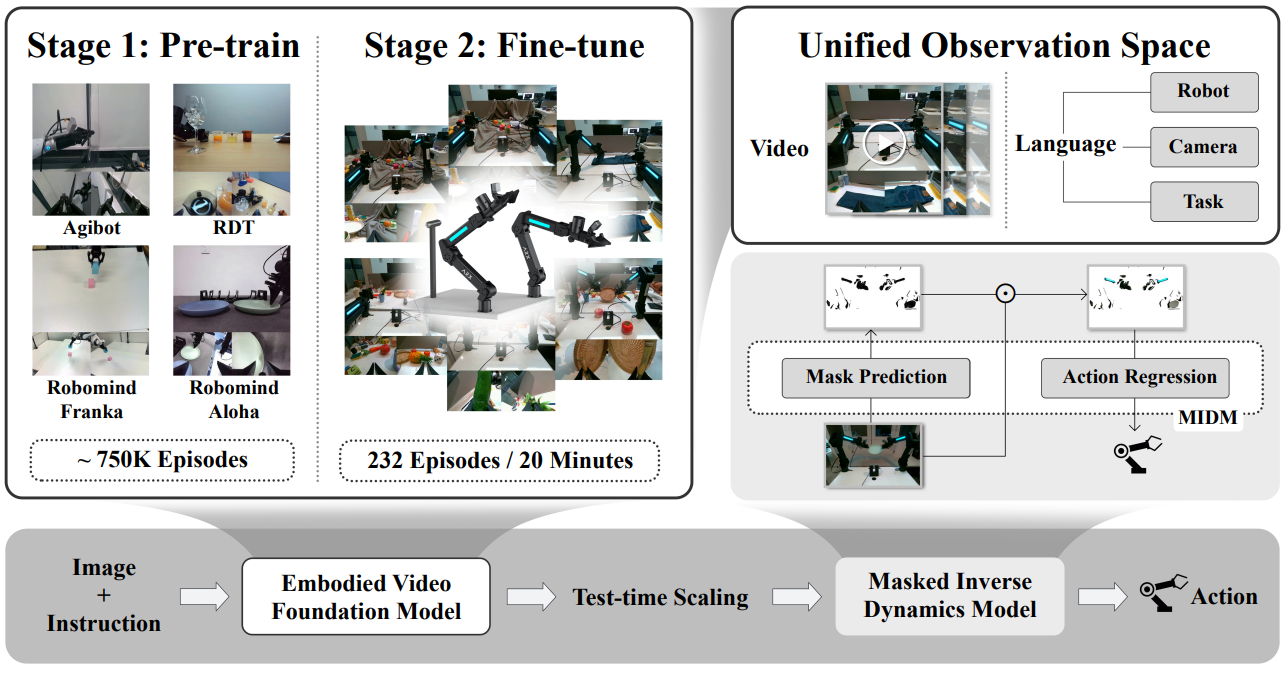
一句话概括 Vidar:它由两部分组成------一个作为"通用先验"的具身视频扩散模型,负责生成"该任务该怎么做"的执行视频;外加一个作为"适配器"的掩码逆动力学模型(MIDM),负责把这段视频接地到目标机器人的动作空间上,同时自动忽略画面里的干扰物。
这套设计的两个直觉支点:
- 视频先验管"怎么做",与机器人本体无关:操作任务的物理过程(杯子怎么被推、抽屉怎么被拉)在很大程度上是跨本体共通的。把这份知识沉淀在一个视频生成模型里,就成了所有机器人都能共享的"通用教材"。
- 适配器管"我这具身体怎么落实",且只看该看的地方 :不同机器人手臂不同、相机不同,需要一个轻量模块把通用视频翻译成自己的关节指令。Vidar 的巧思是让这个适配器学会自动聚焦于"交互关键区"(手和物体接触的地方),把背景、无关杂物统统屏蔽掉------这正是它对"背景/视角变化"鲁棒的根源。
为了让先验真正通用,Vidar 还引入了一个统一观测空间 ,把"机器人类型、相机布局、任务指令、场景上下文"全都编码成视频生成的全局条件------这样一个模型就能横跨多种本体,而不是各训各的。它也顺带解决了统一的双臂机器人建模问题。
三、方法详解:从通用视频先验到机器人动作
Vidar 的流水线分三层:在通用视频大模型上做具身领域的持续预训练 → 统一观测空间把异构条件标准化 → 掩码逆动力学模型(MIDM)把视频接地成动作。
3.1 具身视频先验:在大模型上"继续深造"
底座是一个互联网级预训练的视频生成模型(论文主体用的是 Vidu 2.0,基于 rectified flow / 流匹配这类"把噪声沿直线流向数据"的生成范式;作者还用开源的 HunyuanVideo 验证了方法的通用性)。
关键不是从头训,而是持续预训练(continual pre-training) :在通用大模型的基础上,再用 75 万条多视角轨迹(采自三个真实机器人平台)继续训练,把模型从"懂通用世界"调教到"懂具身操作"。规模上,整个训练约 23000 步、64 张 80GB GPU、约 64 小时------其中 1 万步具身预训练 + 1.3 万步在目标域上的微调。
3.2 统一观测空间:把"机器人是谁、相机在哪"都写进条件
这是 Vidar 处理"多本体、多视角"的核心机制。它不为每台机器人单独设计输入格式,而是把所有异构信息标准化进一份统一表征:
| 条件成分 | 内容 |
|---|---|
| 多视角 RGB 帧 | 把多个相机视角的画面拼合(主视角全分辨率、腕部视角下采样) |
| 空间元数据 | 每个相机视角的置信度权重 |
| 语言条件 | 拆成三段:机器人类型描述、相机配置描述、任务指令 |
| 数据集标识 | 平台专属标签,便于域适配 |
直觉上,这相当于在每段观测前面附了一张"身份说明书":告诉模型"这是哪种机器人、相机怎么摆、要干什么任务"。有了这份说明书,同一个视频模型在不同平台间的协变量偏移(covariate shift,即输入分布的漂移)被大大压低,语义和运动学上下文都被保留下来。论文中这三个平台来自 Agibot、RDT、RoboMind 等真实数据来源。
3.3 掩码逆动力学模型(MIDM):只盯着"该动手的地方"
视频先验生成了"该怎么做"的画面,但怎么把它变成机器人动作、又怎么不被背景干扰?这就是 MIDM(Masked Inverse Dynamics Model)的活儿。它由两个网络组成:
- 掩码预测网络(U-Net) UUU:从输入帧 xxx 预测出一张空间掩码 m∈0,1H×Wm \in 0,1^{H \times W}m∈0,1H×W,标出画面里"和动作相关"的区域;
- 动作回归网络(ResNet) RRR:把掩码与原图逐像素相乘后(即只保留掩码圈出的区域),从这张"抠图"里回归出动作。
最妙的是,这张掩码完全不需要人工分割标注 。它是被一个稀疏性约束"逼"出来的------训练损失里加了一项 λ∥m∥1\lambda \|m\|_1λ∥m∥1(掩码的 L1 范数,λ\lambdaλ 约 3×10−33\times10^{-3}3×10−3),逼着掩码只点亮尽可能少 的、对预测动作真正关键的像素。换句话说,模型为了在"只能看一小块画面"的限制下还能准确预测动作,被迫学会把注意力收敛到手---物交互的关键区,自动把背景、无关物体过滤掉。掩码取整为二值时,用直通估计器(straight-through estimator,一种让"不可导的取整操作"也能反向传播梯度的技巧)保证可训练。
这一招的威力很直接:在测试环境中,纯 ResNet 基线的动作预测准确率只有 24.3%,加上 MIDM 后跃升到 49.0%------聚焦交互区、屏蔽干扰物,正是 Vidar 跨背景、跨视角泛化的关键。
不妨把 MIDM 的逻辑和前一篇 Gen2Act 的"点轨迹辅助损失"放在一起品味:两者其实在用不同手段回答同一个问题------怎样从一段含有大量无关信息的视频里,只把"对动作真正重要"的那部分抽出来? Gen2Act 用点轨迹把运动意图显式剥离;Vidar 则用稀疏掩码在空间上把交互区域圈出来。前者过滤的是"外观噪声",后者过滤的是"背景空间噪声"。它们共同体现了级联式 WAM 在动作提取这一环上的一个深刻共识:视频里能看到的东西很多,但真正该喂给动作模型的,应该是经过提纯的、与任务强相关的精华。 否则背景一变、视角一换,没被过滤的噪声就会把策略带偏。
3.4 测试时扩展:生成多个候选,挑最好的
为压低视频生成的随机性,Vidar 在推理时还用了一个轻量技巧:用不同随机种子生成 K=3K=3K=3 段候选视频,再用 GPT-4o 当"评委"给它们打分排序,选出质量最高的那段去执行。开销不大,却能稳定提升下游成功率。
核心公式与逻辑梳理
把 Vidar 的整套方法压成一条逻辑链:多视角 RGB + 机器人/相机/任务的统一观测条件 → 在互联网级视频先验上继续预训练(用流匹配损失)→ 推理时生成 K 个候选视频,由 GPT-4o 评委挑出最佳 → 掩码逆动力学模型用稀疏掩码圈出"交互关键区"→ 在屏蔽背景后的画面上回归动作。下面拆开几个核心式子。
(1) 流匹配 ODE(rectified flow)。 这是 Vidar 视频先验的生成范式:
dxtdt=v(xt, t, c),t∈0,1\frac{d\mathbf{x}_t}{dt} = v(\mathbf{x}_t,\,t,\,c),\quad t \in 0,1dtdxt=v(xt,t,c),t∈0,1
符号说明 :xt\mathbf{x}_txt 是时刻 ttt 的视频潜变量;ttt 沿 0,10,10,1 从纯噪声(t=0t=0t=0)流向真实数据(t=1t=1t=1);v(⋅)v(\cdot)v(⋅) 是一个学习出来的"速度场",告诉你当前点该朝哪个方向走;ccc 是条件信息------在 Vidar 里就是那份"身份说明书"(机器人类型 + 相机配置 + 任务指令 + 多视角观测)。这条式子在做什么:把"从噪声生成视频"形式化成"沿一条平滑路径在噪声与数据之间走"。相比标准扩散需要曲折地分很多步去噪,流匹配让这条路径尽量平直,采样更高效。直觉上,模型学的不是"如何一步步去噪",而是"在每个中间状态、该朝哪个方向走才能到真实数据"。
(2) 流匹配训练损失。 怎么把这个速度场学出来:
LG=Ec, t, x0, x1 ∥(x1−x0)−v(tx1+(1−t)x0, t, c)∥2 \mathcal{L}G = \mathbb{E}{c,\,t,\,\mathbf{x}_0,\,\mathbf{x}_1}\Big\\,\\big\\\|(\\mathbf{x}_1-\\mathbf{x}_0) - v\\big(t\\mathbf{x}_1+(1-t)\\mathbf{x}_0,\\,t,\\,c\\big)\\big\\\|\^2\\,\\BigLG=Ec,t,x0,x1 (x1−x0)−v(tx1+(1−t)x0,t,c) 2
符号说明 :x0\mathbf{x}_0x0 是高斯噪声起点;x1\mathbf{x}_1x1 是真实目标视频;tx1+(1−t)x0t\mathbf{x}_1+(1-t)\mathbf{x}_0tx1+(1−t)x0 是在两者之间线性插值得到的中间样本;x1−x0\mathbf{x}_1-\mathbf{x}_0x1−x0 是这条直线的"理想速度"(直接指向终点的恒定方向);v(⋅)v(\cdot)v(⋅) 是模型预测的速度;E\mathbb{E}E 是在条件、时间、视频对上求期望。这条式子在做什么 :让模型学会的"速度",无论被丢到这条直线的哪个中点,都能稳定地指向真实数据 x1\mathbf{x}_1x1。在通用大模型权重上用 75 万条多视角机器人轨迹继续优化这个损失,就是把"通用先验"调教成"具身先验"------把"懂世界怎么动"细化成"懂操作场景里东西怎么动"。
(3) 分类器自由引导。 推理时用来增强条件控制力:
v′(xt, t, c)=v(xt, t, c)+ω (v(xt, t, c)−v(xt, t, ∅))v'(\mathbf{x}_t,\,t,\,c) = v(\mathbf{x}_t,\,t,\,c) + \omega\,\big(v(\mathbf{x}_t,\,t,\,c) - v(\mathbf{x}_t,\,t,\,\emptyset)\big)v′(xt,t,c)=v(xt,t,c)+ω(v(xt,t,c)−v(xt,t,∅))
符号说明 :∅\emptyset∅ 表示"扔掉条件、什么都不告诉模型"的空条件;v(⋅,c)v(\cdot,c)v(⋅,c) 是有条件预测的速度;v(⋅,∅)v(\cdot,\emptyset)v(⋅,∅) 是无条件预测的速度;ω\omegaω 是引导强度(越大越"忠实于条件",越小越自由)。这条式子在做什么 :把"条件带来的方向差"放大 ω\omegaω 倍叠加到无条件方向上。直觉是:条件方向和无条件方向之差,正是"条件特有的影响";放大它能让生成结果更紧贴指令和当前画面,而不被通用先验拐跑。
(4) 掩码逆动力学模型(MIDM)。 全文最点睛的设计:
m=U(x),a^=R(round(m)⊙x)m = U(x),\qquad \hat{a} = R\big(\mathrm{round}(m)\odot x\big)m=U(x),a^=R(round(m)⊙x)
符号说明 :xxx 是输入帧(或相邻帧对);UUU 是一个 U-Net,输出空间掩码 m∈0,1H×Wm \in 0,1^{H\times W}m∈0,1H×W,每个像素的值代表"这里对动作预测有多重要";round(m)\mathrm{round}(m)round(m) 把软掩码取整为二值(用直通估计器 STE 解决取整不可导的问题------前向取整、反向把梯度"直通"过去);⊙\odot⊙ 是逐像素相乘;RRR 是一个 ResNet,从被掩码屏蔽后的"抠图"里回归动作 a^\hat{a}a^。这条式子在做什么 :让动作回归网络"戴着眼罩"只看一小块画面。要在这种苛刻条件下还能预测准动作,掩码就不得不学会自动锁定手---物接触的关键区域,把背景、无关物体一律遮掉。在测试集上,纯 ResNet 准确率 24.3%,加上这个掩码门控跃升到 49.0%------证明这层"被迫聚焦"确实把对动作真正重要的信息提炼出来了。
(5) MIDM 训练损失。 一个 L1 正则就把掩码"逼"出来:
LI=Ex,a ℓ(a\^−a)+λ ∥m∥1 ,λ≈3×10−3\mathcal{L}I = \mathbb{E}{x,a}\Big\\,\\ell(\\hat{a}-a) + \\lambda\\,\\\|m\\\|_1\\,\\Big,\qquad \lambda \approx 3\times 10^{-3}LI=Ex,aℓ(a\^−a)+λ∥m∥1,λ≈3×10−3
符号说明 :ℓ(a^−a)\ell(\hat{a}-a)ℓ(a^−a) 是动作回归损失(例如 MSE,衡量预测动作和示范动作的差距);∥m∥1\|m\|_1∥m∥1 是掩码的 L1 范数,等于所有像素值之和,鼓励掩码尽量稀疏(多数像素接近 0) ;λ\lambdaλ 是稀疏正则的权重。这条式子在做什么 :用两股相反的力量博弈出一张漂亮的掩码------一边逼模型"动作预测要准"(必须保留足够多有用像素),一边逼"掩码要尽量小"(不能多保留无关像素)。两股力量的平衡点,恰恰就是"刚好覆盖手---物交互区"。整个过程不需要任何人工分割标注,仅靠一个稀疏先验就把"该看哪里"自我涌现出来------这正是 Vidar 跨背景、跨视角泛化能力的根源。把它和上一篇 Gen2Act 的点轨迹辅助损失对照看,会发现两者都在用"额外约束"逼策略只关注与任务真正相关的信号;Gen2Act 过滤的是外观噪声,Vidar 过滤的是空间噪声------殊途同归。
四、实验怎么做·结果说明了什么
4.1 数据效率:20 分钟,对齐一台没见过的机器人
这是 Vidar 最硬核的卖点。在一台从未见过的目标机器人(Aloha 双臂平台)上做适配,只需 20 分钟的演示(232 条轨迹、81 个任务):
- 这仅相当于 RDT-1B 训练数据(27 小时)的 1%;
- 更只相当于 π₀.₅ 训练数据(400 小时)的 1/1200。
用如此少的真机数据,撬动一台新本体------这正是"一个先验、多种本体"口号的底气。
4.2 成功率:跨任务、跨背景全面碾压
在 Aloha 目标平台上,与 UniPi、VPP 等基线对比:
| 场景 | Vidar | UniPi | VPP |
|---|---|---|---|
| 见过的任务和背景 | 68.2% | 36.4% | 4.5% |
| 未见过的任务 | 66.7% | 6.7% | 13.3% |
| 未见过的背景 | 55.6% | 22.2% | 0.0% |
最值得玩味的是后两行:在未见过的任务 上,Vidar 仍有 66.7%,而 UniPi 只剩 6.7%、VPP 仅 13.3%------几乎是数量级的差距。在未见过的背景上,VPP 直接归零,Vidar 却还能保持 55.6%。这组对比把"视频先验 + 聚焦交互区的 MIDM"在泛化上的价值体现得淋漓尽致。
4.3 消融:拆掉哪块都疼
- 去掉 MIDM(退回纯 ResNet):见过场景 59.1%、未见任务 26.7%、未见背景 22.2%------相比完整版的 68.2/66.7/55.6 全面下滑,尤其在"未见背景"上几乎腰斩(55.6 → 22.2)。这印证了掩码屏蔽干扰物对跨背景泛化的决定性作用。
- 去掉测试时扩展(不再生成 3 个候选挑最优):三档分别降到 45.5% / 33.3% / 44.4%,说明"多生成几个、挑最好的"确实在稳定地兜底。
4.4 视频质量:先验"深造"后画面更连贯
在未见域上用 VBench(视频生成质量基准)衡量,具身持续预训练带来的提升很显著:主体一致性 0.565 → 0.855(+51%)、背景一致性 0.800 → 0.909(+14%)、成像质量 0.345 → 0.667(+93%)。生成的视频越连贯、越保真,下游 MIDM 提动作自然越准。
4.5 可复现性的诚实交代
作者坦言主体所用的 Vidu 2.0 是闭源的,因此特意用开源的 HunyuanVideo(130 亿参数)重做了一遍,在六个代表性任务上仍达到 58.3%,证明方法本身不绑定某个特定的闭源模型。
五、亮点与为什么重要
- "一个先验,多种本体"的范式:Vidar 给出了一条清晰且可扩展的配方------把昂贵的能力沉淀进一个通用、廉价的视频先验,新本体只付极小的对齐成本。这对苦于"换台机器人就要重采一大批数据"的产业界极具吸引力。
- 统一观测空间 + 统一双臂建模:用一份"身份说明书"式的全局条件,让单个模型横跨多平台、多视角,并优雅地把双臂机器人纳入统一框架。
- 无标注的掩码 IDM(MIDM):不靠任何分割标注,仅用稀疏性约束就逼出"聚焦交互区、屏蔽干扰物"的掩码,是全文最点睛的设计,也是跨背景/视角鲁棒性的根源。
- 极致的数据效率:20 分钟、1% 数据就迁移到新机器人,这个数字本身就是对该范式有效性的最有力背书。
六、局限与未解
- 强依赖视频先验质量:整套能力的天花板由视频生成模型决定。生成的执行视频若不合理,MIDM 再准也无能为力。
- 闭源底座的隐忧:主体最佳结果建立在闭源的 Vidu 2.0 上;虽用 HunyuanVideo 验证了通用性,但开源版与闭源版之间仍有性能落差(58.3% vs 68.2%)。
- 生成的随机性:需要靠"生成 3 个候选 + GPT-4o 挑选"来兜底,说明单次生成的稳定性仍不足,且引入了对外部大模型评委的额外依赖。
- 像素级生成的固有开销:和所有像素空间级联方法一样,先生成视频再提动作的链路,离高频实时控制仍有距离。
七、在 WAM 谱系中的位置
Vidar 与 UniPi、TesserAct、Gen2Act 同属"级联式 → 像素空间 → 学习式动作提取"一类。在这条线上,它代表了**"把方法跨不同具身类型与数据来源扩展"** 的努力方向------核心命题是迁移与泛化。
它和上一篇 Gen2Act(第 06 篇)构成一组极佳的对照:两者都想榨取互联网视频先验、都想省机器人数据,但路线相反。Gen2Act 不微调 视频模型、生成的是人类 视频、让策略直接消化;Vidar 则选择继续预训练 视频模型、把人类视频转译成机器人执行视频 ,并主打"20 分钟真机演示对齐新本体"。一个赌"少改模型、多靠策略",一个赌"重塑先验、轻量对齐"------它们从两端逼近了 WAM 的同一核心难题:面对具身数据稀缺,视频模型该改多少、机器人该学多少。
而在动作提取的"聚焦"思想上,Vidar 的 MIDM(用掩码屏蔽干扰、专注交互区)也与 WAM 里 MWM 那类"用语义掩码替代 RGB 预测以抗视觉扰动"的隐式规划工作遥相呼应------殊途同归地指向同一个洞见:别让背景的噪声污染了决策。
八、参考
- 论文:Vidar: Embodied Video Diffusion Model for Generalist Manipulation(Yao Feng, Hengkai Tan, Xinyi Mao, Chendong Xiang, Guodong Liu, Shuhe Huang, Hang Su, Jun Zhu, 2025)
- arXiv:https://arxiv.org/abs/2507.12898
- 评测:仿真 RoboTwin 2.0;真机 Aloha 双臂平台
注:本文为基于该论文公开信息的学习性解读,方法、数据集与基准名称保留英文原名以便检索;具体数字以原论文为准。论文主体视频底座为 Vidu 2.0(闭源),并以开源 HunyuanVideo 验证通用性。