同属"先生成执行视频、再学习式提取动作"的级联式 WAM,This&That 把矛头对准了一个被前作忽视的痛点:当桌上摆着好几个一模一样的杯子,纯语言指令根本说不清"哪一个"。它的解法是给视频扩散模型同时喂入"this/that 指示语"和"首帧上的两个手势坐标点",让任务指令既简洁又毫无歧义。
前三篇里,UniPi 奠定了"视频生成 + 逆动力学"的级联框架,VLP 和 RoboEnvision 各自从"树搜索"和"非自回归"两条路解决长程误差累积。但它们有一个共同的、未被正视的盲区------任务到底是怎么告诉机器人的?答案清一色是"一句自然语言"。
This&That(发表于 ICRA 2025)偏偏揪住了"纯语言指令"这件事的死穴。它提出的核心改进是:让人像跟同伴说话那样指挥机器人------用最朴素的指示代词"this/that"配上手指一点,而不是费劲描述"第三排那个蓝色的、把手朝左的杯子" 。再把这套"语言+手势"的条件,灌进视频生成模型里去。配套的动作提取器,作者命名为 DiVA(Diffusion Video to Action)。
一、要解决什么问题:纯语言指令的"指代困境"
先用一个再日常不过的场景把痛点摆出来。
你家餐桌上摆了五个长得几乎一样的玻璃杯。你想让机器人帮你拿一个。如果只能用语言,你得说:"给我拿那个蓝色的、在第三排、把手朝右、离桌边大概十厘米的玻璃杯。"------又啰嗦,又充满歧义(万一有两个都符合呢?)。
可如果是跟身边的人说,你只会手一指 ,配一句"给我那个",对方秒懂。这里的"那个(that)"就是指示语(deictic word,即依赖语境'指指点点'才能确定所指的词,如这/那、这里/那里) 。指示语的威力在于:它把"精确描述物体属性"的重担,转移给了一个简单的指向动作。
这正是 This&That 要补的拼图。前作的视频生成模型都只吃文字条件,于是:
- 遇到多个同类物体,语言说不清到底操作哪一个,模型只能瞎猜;
- 遇到复杂或不确定的场景,纯语言要么冗长、要么模糊,生成的视频常常"答非所问"。
论文把这归纳为视频驱动机器人规划的三大根本挑战 :(1) 如何用简单的人类指令无歧义地传达任务 ;(2) 如何让视频生成可控、忠实于用户意图 ;(3) 如何把视觉计划翻译成机器人动作。This&That 用"语言+手势"的双条件一次性回应了前两个,用 DiVA 回应了第三个。
二、核心思想与直觉:把"指指点点"变成模型的条件信号
This&That 的核心 idea 一句话:
让用户在第一帧画面上点两个点------红点指"操作哪个物体(this)"、绿点指"放到哪里(that/there)"------再配一句极简的指示语指令(如"pick this to there");视频扩散模型同时以"语言"和"这两个手势坐标"为条件,生成一段忠实于用户真实意图的执行视频。
为什么"语言+手势"比"纯语言"或"纯手势"都强?这是个很有意思的互补关系:
- 纯语言:碰到同类物体就指代不清(前述的杯子困境)。
- 纯手势 :2D 屏幕上的一个点,存在 3D 歧义------图像里的一个像素坐标,对应的真实三维位置其实不唯一(远近说不准),而且光一个点也表达不了"要做什么动作"。
- 语言 + 手势:语言负责说清"做什么动作"(拿、放、叠、开关),手势负责精确锁定"对哪个、到哪儿"。二者各补对方的短,合起来既简洁又无歧义。
这依然是一个标准的级联式 WAM :第一阶段语言-手势条件视频生成,第二阶段用 DiVA 这个行为克隆模型把视频变动作。它的革新不在"级联"这个骨架,而在给世界模型的'输入接口'动了刀------从"只能打字"升级为"能打字 + 能指点"。
三、方法详解:怎么把"两个点"喂进扩散模型
3.1 第一阶段:语言-手势条件视频生成
底座选的是 Stable Video Diffusion(SVD) ------一个预训练好的、图像到视频的隐空间视频扩散模型。这意味着它天生会"从一张图往后续生成一段视频",This&That 要做的是教它"听语言、看手势"。目标分布写出来是 pθ(I₁,...,Iₜ | I₀, C_text, C_gest):给定首帧 I₀、语言条件 C_text、手势条件 C_gest,生成后续视频帧。
训练分两步走,循序渐进:
第一步:先教它听语言。
在 Bridge 机器人数据集(约 25,767 段视频)上微调 SVD 的 U-Net。语言用 CLIP(一个把图文映射到同一向量空间的模型)编码成嵌入向量,然后和图像嵌入拼接 起来(文本 77×1024 维 + 图像 1×1024 维 = 78×1024 维)一起作为条件。这里有个关键的稳定性技巧:对拼接后的 CLIP 嵌入做层归一化(LayerNorm),消融实验显示这一步对性能很重要------不做归一化,指标会变差。
第二步:再教它看手势(核心创新)。
这一步冻结上一步的 U-Net,额外挂一条 ControlNet 风格的旁路分支专门处理手势。ControlNet 是给扩散模型外接"额外空间条件"的经典做法(原本常用于线稿、姿态控制),这里被用来注入手势点。具体操作很讲究:
- 手势就是用户在首帧点的 2D 像素坐标点,红点=要操作的物体(this),绿点=目标位置(there)。
- 这些点不是一个孤零零的像素,而是用 2D 高斯滤波"晕染"成一个小光斑(论文里表示为约 10 像素见方的方块),让网络更容易"看见"。
- 手势只出现在两帧里 (开头和动作关键处),把"编码后的首帧
ℰ(I₀)、噪声ϵ、编码后的手势ℰ(C_gest)"在通道维拼成一个张量喂进去。 - 还用了一个**隐空间掩码(以概率 p 随机遮住手势输入)**的技巧,防止模型过度依赖手势而退化。
一个很实用的工程细节:手势点不需要人工标注,而是自动生成的------用一个基于 YOLOv8 的夹爪检测器(在 450 张标注图上训练)找到机器人夹爪位置,再用 TrackAnything 跟踪物体,自动定位出"抓取点"和"放置点"。这让方法能在大规模数据上自动扩展。
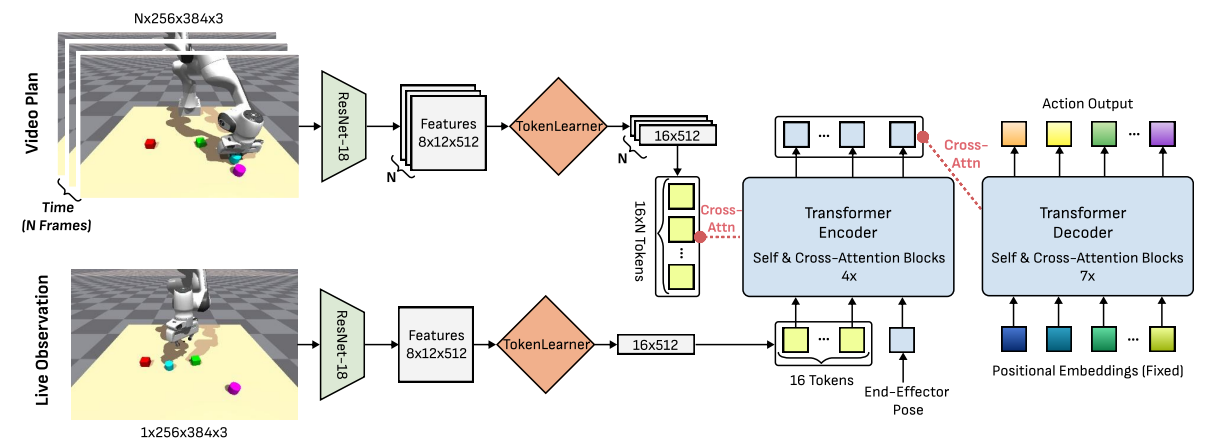
3.2 第二阶段:DiVA------把生成视频变成动作
视频画好了,轮到 **DiVA(Diffusion Video to Action)把它翻译成机器人动作。它本质是一个 行为克隆(behavior cloning,即从演示数据里模仿"看到什么状态就做什么动作")**模型,架构上借鉴了 ACT(Action Chunking Transformer,一种一次预测一段连续动作的 Transformer):
- 用 ResNet-18 提取视频帧和当前观测帧的视觉特征;
- 用 TokenLearner 把每张图压成 16 个 token(降低计算量);
- 让"当前实时观测的 token"和"生成视频计划的 token"做交叉注意力------也就是让机器人一边看着自己当前的画面,一边对照着"计划视频"该往哪走;
- 末端执行器位姿经 MLP 编码成一个额外 token 一起送入。
它学习的是 πθ(a_{t:t+k} | o_t, s_t, τ):给定当前观测 o_t、末端位姿 s_t、以及生成视频里抽取的一组目标帧 τ(N 个目标帧),输出未来一段动作。训练时取 N 个均匀间隔的真实帧当目标。
这里有个对"级联式"通病的精妙修补------时间噪声(temporal noise)训练 。级联式有个老问题:训练时 DiVA 看的是真实视频 ,部署时看的却是模型生成的视频 ,两者有差距(domain gap),生成视频里物体可能略微变形、位置略偏。This&That 的对策是:训练时不固定取某几帧当目标,而是从相邻的几帧里随机采样 ,人为制造抖动,逼 DiVA 学会"即使目标帧不那么精确也能照着干",从而对生成视频的瑕疵更鲁棒。消融也证实:只给 1 个目标帧几乎完全失败,给到 15--25 帧才稳定------光看终点不够,得让它看清整个过程。
3.3 一图看清数据流
| 阶段 | 组件 | 输入 → 输出 | 关键创新 |
|---|---|---|---|
| 任务指定 | 用户 | 首帧点红/绿两点 + 一句指示语 | this/that 消歧 |
| 视频生成 | SVD + ControlNet 旁路 | 首帧+语言+手势 → 执行视频 | 高斯晕染手势点、CLIP 嵌入 LayerNorm、隐空间掩码 |
| 动作提取 | DiVA(ACT 式 BC) | 当前观测+生成视频帧 → 动作序列 | 交叉注意力 + 时间噪声抗 domain gap |
核心公式与逻辑梳理
This&That 整套方法可以拆成 5 步:
- 双模态指令输入:用户在首帧上点红/绿两个点,再说一句极简的"this/that"指示语,作为联合条件。
- 语言条件预训练:先用 CLIP 编码语言和首帧、做 LayerNorm 后拼接,把 SVD 微调成一个会"听语言"的视频扩散模型。
- 手势条件分支:冻结上一步的 U-Net,再挂一条 ControlNet 风格的旁路,专门处理被"高斯晕染"过的手势点。
- 隐空间掩码正则:训练时以一定概率把手势输入遮掉,防止模型一味依赖手势而退化。
- DiVA 动作提取:行为克隆策略通过交叉注意力比对"当前观测"和"生成视频帧",输出动作序列;训练时通过时间噪声采样抵抗 domain gap。
公式 1:语言-手势联合条件视频生成的目标分布
pθ ( I1,...,IT ∣ I0, Ctext, Cgest )p_{\theta}\!\left(\,I_{1},\ldots,I_{T}\ \Big|\ I_{0},\ C_{\mathrm{text}},\ C_{\mathrm{gest}}\,\right)pθ(I1,...,IT I0, Ctext, Cgest)
- 符号说明 :I0I_0I0 是用户提供的首帧画面,I1:TI_{1:T}I1:T 是要生成的 TTT 帧执行视频;CtextC_{\mathrm{text}}Ctext 是语言指令(如 "pick this to there"),CgestC_{\mathrm{gest}}Cgest 是手势条件(两个点经过高斯晕染后的隐编码);θ\thetaθ 是模型参数。
- 这条式子在做什么 :和 UniPi 的 ρ(⋅∣x0,c)\rho(\cdot\mid x_0,c)ρ(⋅∣x0,c) 相比,条件项里多了一个 CgestC_{\mathrm{gest}}Cgest。这一项虽然写起来不起眼,却把"指代"从 vague 的语言空间挪到了精确的像素空间,是整篇论文的"杀手锏"。
公式 2:CLIP 嵌入的拼接与层归一化
yhs=LayerNorm ( CLIP(xtext); CLIP(xI0) ),yhs∈Rb×78×1024y_{\mathrm{hs}} = \mathrm{LayerNorm}\!\Big(\big\\,\\mathrm{CLIP}(x_{\\mathrm{text}});\\ \\mathrm{CLIP}(x_{I_0})\\,\\big\Big),\qquad y_{\mathrm{hs}}\in\mathbb{R}^{b\times 78\times 1024}yhs=LayerNorm(CLIP(xtext); CLIP(xI0)),yhs∈Rb×78×1024
- 符号说明 :CLIP(xtext)\mathrm{CLIP}(x_{\mathrm{text}})CLIP(xtext) 是 77 个文本 token 的嵌入(77×102477\times 102477×1024),CLIP(xI0)\mathrm{CLIP}(x_{I_0})CLIP(xI0) 是首帧的 1 个图像嵌入(1×10241\times 10241×1024);⋅;⋅\\cdot;\\cdot⋅;⋅ 表示沿序列维度拼接成 78 个 token;bbb 是批大小;LayerNorm\mathrm{LayerNorm}LayerNorm 沿最后一维做归一化。
- 这条式子在做什么:让文本和图像在同一个"语义画布"上对齐,再用 LayerNorm 稳住两种来源向量的尺度差异。消融实验显示------去掉这一层归一化,FID/FVD 都明显变差。看似工程细节,实则是"听话"的稳定性根基。
公式 3:手势条件分支的输入构造
yGest=Z ( Mp(E(I0)); ϵ; E(Cgest) )y_{\mathrm{Gest}}=\mathcal{Z}\!\Big(\big\\,\\mathcal{M}_{p}(\\mathcal{E}(I_0));\\ \\epsilon;\\ \\mathcal{E}(C_{\\mathrm{gest}})\\,\\big\Big)yGest=Z(Mp(E(I0)); ϵ; E(Cgest))
- 符号说明 :E(⋅)\mathcal{E}(\cdot)E(⋅) 是 VAE 编码器,把图像或手势图压成隐特征;CgestC_{\mathrm{gest}}Cgest 是把两个手势点经过 2D 高斯滤波"晕染"成约 10 像素见方光斑后的图;ϵ\epsilonϵ 是与隐空间同形状的噪声张量;Mp\mathcal{M}_pMp 表示以概率 ppp 随机遮住首帧隐特征(latent masking);Z\mathcal{Z}Z 是"零卷积"(ControlNet 的标志性组件,初始化为零、训练时逐渐生效,避免破坏预训练 U-Net);⋅;⋅\\cdot;\\cdot⋅;⋅ 沿通道维拼接。
- 这条式子在做什么 :用"高斯晕染 + 零卷积 + 隐掩码"三件套,把"两个像素点"温柔地、可控地塞进预训练扩散模型。高斯晕染 让稀疏的两个点变成模型容易感知的小光斑;零卷积 保证旁路一开始不破坏原模型;隐掩码则强迫模型不能完全依赖手势,必须把语言也利用起来。三者合力,才让"指尖一点"真正成为有效条件。
公式 4:DiVA 的策略分布
πθ ( at:t+k ∣ ot, st, τ )\pi_{\theta}\!\left(\,a_{t:t+k}\ \Big|\ o_t,\ s_t,\ \tau\,\right)πθ(at:t+k ot, st, τ)
- 符号说明 :oto_tot 是当前真实观测帧、sts_tst 是当前末端执行器位姿,τ={I^t1,...,I^tN}\tau=\{\hat I_{t_1},\ldots,\hat I_{t_N}\}τ={I^t1,...,I^tN} 是从生成视频里抽出的 NNN 个目标帧(实验显示 N∈15,25N\in15,25N∈15,25 才稳);at:t+ka_{t:t+k}at:t+k 是接下来 kkk 步的动作 chunk;策略以 L1 损失监督,借鉴 ACT 的 action chunking 思想。
- 这条式子在做什么 :把"行为克隆 + 视频引导"写成一个条件策略。注意 τ\tauτ 不是单帧而是一组帧------这是 DiVA 区别于普通 BC 的关键:让策略一边看自己当下、一边对照计划视频的整段轨迹,而不是只盯一个终点。配合"时间噪声训练"(训练时随机从相邻几帧采目标,而非固定取帧),策略学会了对生成视频里的小瑕疵保持鲁棒,从根上压住了"训练用真视频、部署用生成视频"的 domain gap。
四、实验怎么做·结果说明了什么
4.1 数据与平台
- 真机数据:Bridge V1 & V2(复杂家居场景的真机操作),约 25,767 段用于第一步语言微调,过滤后约 14,735 段用于第二步手势训练;测试集 646 段视频。
- 仿真:Isaac Gym 桌面环境,用 4 个方块做抓取-放置(DiVA 的闭环执行目前主要在仿真里验证,因为缺对应的 WidowX 250 真机)。
4.2 视频生成质量:大幅甩开一众基线
在 Bridge 测试集上(FID/FVD/LPIPS 越低越好,PSNR/SSIM 越高越好):
| 方法 | FID↓ | FVD↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|
| SVD(原始底座) | 29.49 | 657.49 | 11.17 | 0.285 | 0.473 |
| StreamingT2V | 42.57 | 780.81 | 10.48 | 0.303 | 0.570 |
| DragAnything | 34.38 | 764.58 | 9.88 | 0.283 | 0.590 |
| AVDC | 163.93 | 1512.25 | 19.43 | 0.649 | 0.517 |
| This&That(本文) | 17.28 | 84.58 | 20.03 | 0.761 | 0.137 |
差距相当悬殊,尤其 FVD 从基线动辄六七百降到 84.58 。这说明加上手势条件后,生成的视频不仅更清晰,而且运动方向和操作对象都对得上用户意图了------条件越精确,生成越"听话"。
4.3 用户意图对齐:手势把成功率从 51% 拉到 92%
这是本文最能说明问题的一组实验。请 3 位机器人研究者,对 24 个测试序列,评判"生成的视频是否真的完成了用户想要的任务"(成功率 %):
| 条件 | 抓取放置 | 堆叠 | 折叠 | 开关 | 平均 |
|---|---|---|---|---|---|
| 纯视觉 | 0.0 | 6.6 | 11.1 | 60.0 | 16.7 |
| 视觉+语言(前作的做法) | 37.5 | 26.7 | 50.0 | 100.0 | 51.4 |
| 视觉+手势 | 58.3 | 66.7 | 55.6 | 100.0 | 68.1 |
| 视觉+语言+手势(本文) | 95.8 | 80.0 | 88.9 | 100.0 | 91.7 |
这张表把 This&That 的论点钉得死死的:只用语言(前作范式)平均才 51.4% ;只用手势 因为有 3D 歧义、说不清动作,也只有 68.1%;语言+手势合体直接冲到 91.7%。尤其"抓取放置"这类最容易因同类物体而指代不清的任务,从 37.5% 暴涨到 95.8%------手势消歧的价值在这里体现得淋漓尽致。
4.4 仿真闭环:视频驱动 + 手势条件最稳
在 Isaac Gym 里跑完整的"生成视频→DiVA 执行"闭环,对比纯行为克隆(ACT)和不同条件(报告分布内/分布外两种成功数):
- 纯 ACT(无条件)几乎完全失败;
- ACT 加语言+手势能完成一部分;
- 视频驱动 + 语言+手势 表现最好,抓取/放置/整体成功率在分布内和分布外都显著领先。
这说明:把"语言+手势条件视频"当作中间计划,比让策略直接从指令端到端学动作,要稳健得多------视频这个中间表征,承载了更丰富、更具体的"该怎么做"的信息。
4.5 消融:每个设计都不是摆设
- 手势注入方式 :朴素的 ControlNet(只加零卷积)跟不上手势线索 ,效果差;加了语义分割掩码(SAM)反而没用,因为 SAM 常常圈错物体;最终方案最好。
- CLIP 嵌入的 LayerNorm:去掉它,FID/FVD 都变差,证明这个稳定性细节确有必要。
- DiVA 的目标帧数 N:N=1 几乎 0% 成功,N 在 15--25 之间性能趋于稳定;时间噪声训练比固定取帧更鲁棒。
五、亮点与为什么重要
- 重新设计了"人机指令接口" :前作执着于"怎么生成、怎么解码",This&That 第一个认真追问"任务该怎么输入",并用"指示语+手势"给出了简洁而无歧义的答案。这是把 HRI(人机交互)的直觉引入视频驱动机器人规划的一次漂亮尝试。
- 手势条件可自动标注、可扩展:靠 YOLOv8 夹爪检测 + TrackAnything 自动生成手势点,不依赖人工标注,能在大规模数据上铺开。
- 对级联式 domain gap 的实用解法:DiVA 的"时间噪声训练"专门缓解"训练用真视频、部署用生成视频"的分布差距,是个可迁移的小而美的技巧。
- 结果有说服力:视频质量 FVD 数量级下降,用户意图对齐从 51% 提到 92%,把"手势消歧"的收益量化得很清楚。
六、局限与未解
作者很坦诚地列了几条:
- 物体形状会随时间变形:缺少 3D 几何约束,生成视频里物体形状常常"漂移"。
- 只能做短而模块化的任务 :目前局限于抓放、堆叠这类短任务,长程任务(如做一顿饭)还没法用多模态指令组织------这恰是 VLP / RoboEnvision 攻的方向,二者正好互补。
- 手势自动标注不够鲁棒:受运动模糊等图像伪影影响,自动标注偶尔出错。
- 2D 手势的 3D 歧义仍在 :一个 2D 点决定不了唯一的 3D 位置,所以纯手势会失败、必须配语言------这也解释了为什么作者坚持"语言+手势"而非"纯手势"。
- 真机闭环尚缺:DiVA 的执行验证目前主要在仿真里,受限于没有对应的 WidowX 250 真机(作者援引 Bridge 数据"仿真-真机高度相关"的既有结论作为间接佐证)。
七、在 WAM 谱系中的位置
This&That 同样属于级联式 → 像素空间显式规划 → 学习式动作提取这一支,与前三篇是"修补 UniPi 不同侧面"的兄弟工作:
- 与 UniPi(本系列 01):UniPi 只用文字当条件,遇到同类物体会指代不清;This&That 给世界模型加上"手势坐标"这条新的条件通道,正面解决指令歧义。可以理解为------UniPi 关心"想象得准不准",This&That 关心"你有没有告诉清楚它该想象什么"。
- 与 VLP / RoboEnvision(本系列 02、03)的分工:后两者攻"长程不崩",This&That 攻"指令不歧义"。它自陈"目前只能做短任务",恰恰说明它和长程方法是正交互补的------未来完全可以把"语言+手势消歧"嫁接到长程规划框架上。
- 承上启下:它把"可控视频生成"这件事,从"文字可控"推进到"文字+空间指点可控",为后续更丰富的人机条件接口(轨迹、草图、3D 指点等)开了个头。
如果说 UniPi 让机器人学会了"照着想象做",那 This&That 解决的是更前置、却同样要命的一环:先让机器人毫不含糊地搞懂------你到底要它对哪个东西、做什么、放到哪儿。指尖一点,胜过千言。
八、参考
- 论文:《This&That: Language-Gesture Controlled Video Generation for Robot Planning》
- 会议:ICRA 2025(IEEE International Conference on Robotics and Automation)
- arXiv:https://arxiv.org/abs/2407.05530
- 代码(视频生成部分官方实现):https://github.com/Kiteretsu77/This_and_That_VDM
注:本文为基于该论文公开信息的学习性解读,方法名、数据集与数字均取自论文以便检索与复核;解读、类比与组织为作者原创,未照搬原文表述。