摘要:你有没有遇到过这种情况------跟大模型聊了半天,它下一秒就不认识你了?这不是大模型高冷,是它真的"失忆"。大模型每次被调用都像刚睡醒,完全不记得上一秒你们聊了啥。本文带你用LangChain.js手搓一个对话记忆系统,让大模型从"金鱼脑"进化成"靠谱秘书"。我们踩过的坑、填过的雷,全部奉上。
一、故事从一个"失忆客服"说起
想象一个场景:你打电话给客服,说了十分钟你的问题,客服说"我帮您转接",然后------下一个客服对你说"您好,请问有什么可以帮您?"
你崩溃吗?崩溃。但这就是大模型的工作方式。
每次调用LLM,它都是一张白纸。 它不会记住你上一轮说了什么,不会记得你的名字,不会记得你五分钟前刚说过"我是前端工程师"。你和它之间的每一次交互,对它来说都是初次见面。
arduino
第1轮:你:"我叫小明" → 大模型:"你好小明!"
第2轮:你:"我叫什么?" → 大模型:"抱歉,我不知道您叫什么" 🤡所以,对话记忆不是LLM自带的功能,而是我们需要手动实现的。 这就是今天要做的事。
二、先跑通最小闭环------跟大模型说上话
在实现记忆之前,我们得先让程序能跟大模型说上话。这是整个项目的地基。
2.1 项目初始化
bash
mkdir agent && cd agent
npm init -y
npm install typescript @types/node tsx --save-dev
npm install @langchain/core langchain @langchain/openai dotenv
npx tsc --init依赖说明:
| 包名 | 作用 | 类比 |
|---|---|---|
@langchain/core |
核心抽象层,定义Runnable等接口 | USB接口标准 |
langchain |
链、记忆等高级组件 | 基于USB标准造的设备 |
@langchain/openai |
OpenAI协议的具体实现 | OpenAI牌的U盘 |
dotenv |
读取.env环境变量 | 不想把密码写代码里的安全措施 |
这里有个关键设计:LangChain的三层架构。
less
┌─────────────────────────────┐
│ 应用层 (Chain / Agent) │ ← 组装:把模型、工具、记忆拼起来
├─────────────────────────────┤
│ 核心抽象层 (@langchain/core)│ ← 接口:定义Runnable、Tool等抽象
├─────────────────────────────┤
│ 集成层 (@langchain/openai) │ ← 实现:具体的模型连接
└─────────────────────────────┘这三层设计最妙的地方在于:换模型不用改代码。你今天用OpenAI,明天想换讯飞、DeepSeek,只需要改一行配置,业务代码零修改。就像你把手机SIM卡从移动换到联通------手机不用换,换张卡就行。
2.2 连接大模型
环境变量配置(.env文件):
bash
OPENAI_API_KEY=sk-your-api-key-here
OPENAI_MODEL=gpt-4o-mini
typescript
const model = new ChatOpenAI({
modelName: process.env.OPENAI_MODEL || "gpt-4o-mini",
temperature: 0.7,
});ChatOpenAI会自动读取.env中的OPENAI_API_KEY。如果你用的是兼容OpenAI协议的服务(如DeepSeek),只需要在.env中加上OPENAI_BASE_URL,代码一行不用改------这就是LangChain抽象层的威力:换模型像换SIM卡,手机不用换。
2.3 第一次对话
typescript
import "dotenv/config";
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage, SystemMessage } from "@langchain/core/messages";
const model = new ChatOpenAI({
modelName: process.env.OPENAI_MODEL || "astron-code-latest",
temperature: 0.7,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
});
const messages = [
new SystemMessage("你是一个知识渊博且风趣的AI助手。回答要简洁,但要有意思。"),
new HumanMessage("用一句话解释什么是RAG?"),
];
const response = await model.invoke(messages);
console.log(response.content);运行结果:
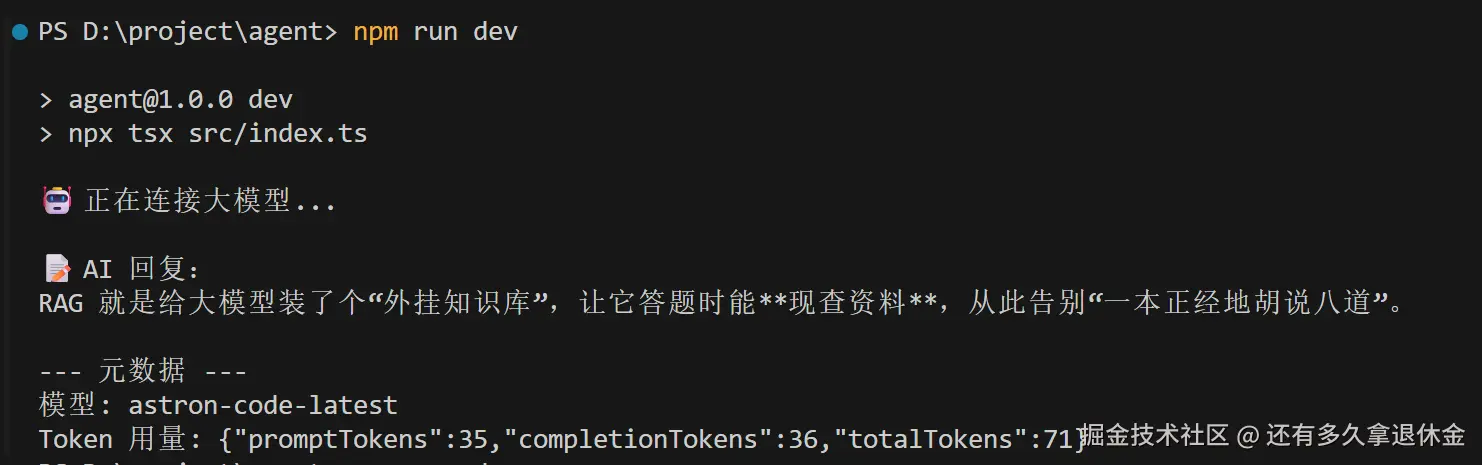
跑通了!但问题是------下一次调用,它又失忆了。
三、核心实战:手搓对话记忆
3.1 记忆的本质是什么?
先想明白一个核心问题:LLM的记忆是怎么实现的?
答案出乎意料的简单------每次都把聊天历史一起发过去。
arduino
第1轮:发送 [系统提示, 用户: "我叫小明"]
→ 大模型回复 "你好小明!"
第2轮:发送 [系统提示, 用户: "我叫小明", AI: "你好小明!", 用户: "我叫什么?"]
→ 大模型回复 "你叫小明呀!"看到没?第2轮的时候,我们把第1轮的完整对话记录一起塞给了LLM。它不是"记住"了,而是每次都重新读了一遍完整聊天记录。
这就像你每次去同一家理发店------理发师本人记不住你,但你每次去都把之前的照片带给他看,他就能接着剪。照片就是messages数组。
3.2 手写一个记忆管理器
理解了原理,代码就很自然了:
typescript
import {
HumanMessage,
AIMessage,
SystemMessage,
BaseMessage,
} from "@langchain/core/messages";
class ConversationMemory {
private messages: BaseMessage[] = [];
constructor(systemPrompt: string) {
// 系统提示词始终放在第一条,设定AI角色
this.messages.push(new SystemMessage(systemPrompt));
}
/** 添加用户消息 */
addUserMessage(content: string) {
this.messages.push(new HumanMessage(content));
}
/** 添加AI回复 */
addAIMessage(content: string) {
this.messages.push(new AIMessage(content));
}
/** 获取所有消息(发给LLM用) */
getMessages(): BaseMessage[] {
return [...this.messages];
}
/** 清空对话(保留系统提示词) */
clear() {
const systemPrompt = this.messages[0];
this.messages = systemPrompt ? [systemPrompt] : [];
}
}几个设计细节:
-
为什么要用
[...this.messages]返回副本? 防止外部直接修改内部数组。你把聊天记录的复印件给别人,别人在上面乱画不影响你的原件。 -
clear()为什么保留系统提示词? 清空的是对话历史,但大模型的角色设定不应该丢。就像你换了个新话题,但对面那个人没换。 -
为什么用
HumanMessage/AIMessage而不是纯字符串? 因为LLM需要区分"谁说的"。HumanMessage代表用户,AIMessage代表模型,SystemMessage代表系统指令。角色标记让模型理解对话结构。
3.3 完整的多轮对话循环
typescript
// 初始化记忆
const memory = new ConversationMemory(
"你是一个知识渊博且风趣的大模型助手,名叫小星。" +
"回答要简洁有趣。如果用户问你之前聊过什么,你要能回忆起来。",
);
// 每轮对话的核心流程
// 1. 把用户消息加入记忆
memory.addUserMessage(input);
// 2. 把完整记忆发给LLM(关键步骤!)
const response = await model.invoke(memory.getMessages());
// 3. 把AI回复也加入记忆(下次就能"记住"了)
memory.addAIMessage(response.content as string);就这么一个循环:用户说话 → 加入数组 → 全量发给LLM → 大模型回复 → 也加入数组 → 重复。
运行效果:
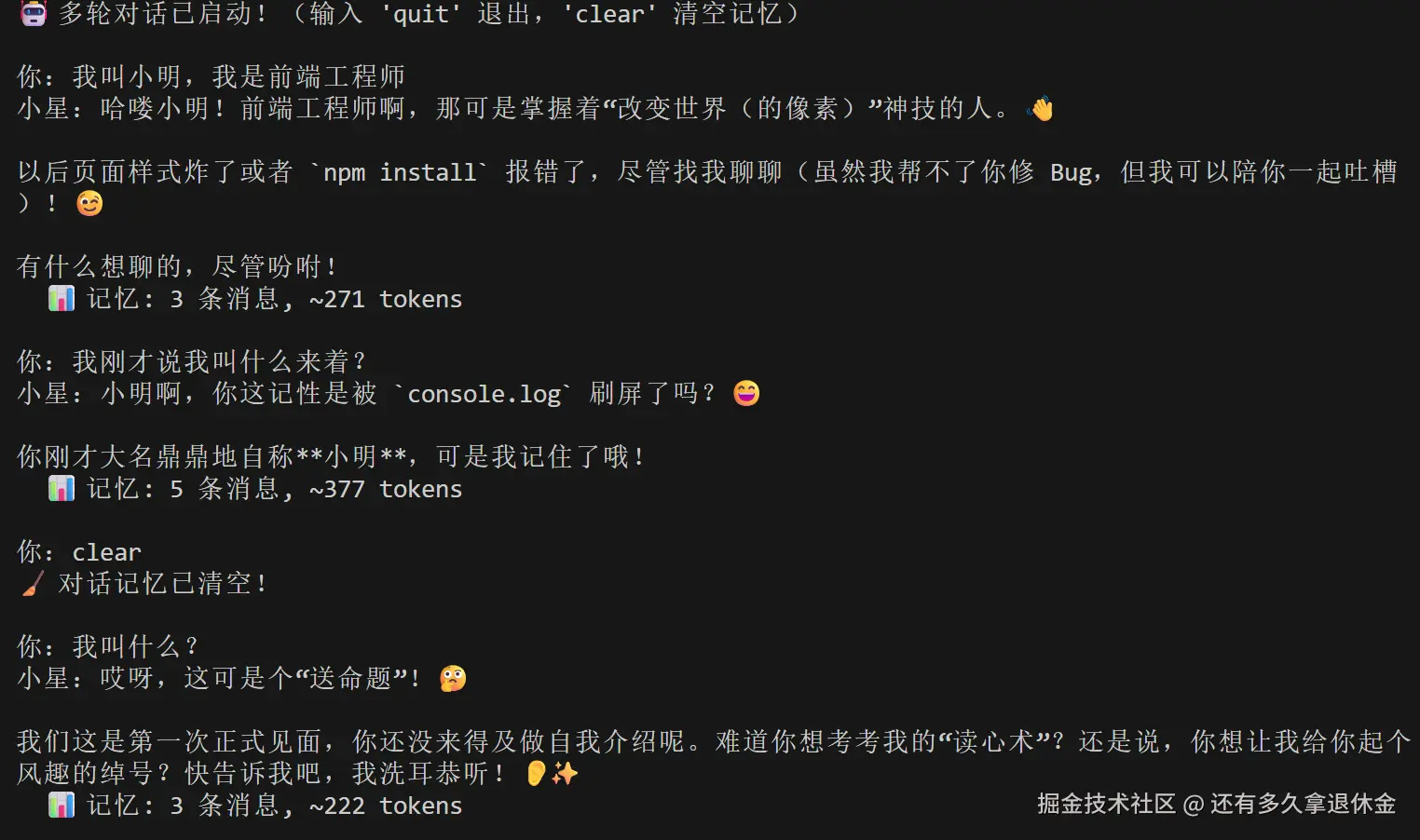
看到了吗?清空后AI确实"忘了"。这就是Buffer记忆的朴素与真实。
四、开发难点与踩坑记录
难点①:Token膨胀------聊着聊着就炸了
Buffer记忆最大的问题:每多聊一轮,发送的Token就更多。
第1轮:~100 tokens
第5轮:~500 tokens
第20轮:~2000 tokens
第50轮:~5000 tokens ← 大部分都是历史消息,真正的新问题只有几十token这就像你去打印店------每次都把从开天辟地到现在的所有文件重新打印一遍,只为了在最后一页加一行字。费纸(费Token)又费时。
解决方案:
| 策略 | 做法 | 适用场景 |
|---|---|---|
| 滑动窗口 | 只保留最近K轮对话 | 客服聊天,旧对话不重要 |
| 摘要压缩 | 用LLM把旧对话压缩成摘要 | 需要保留关键信息的长对话 |
| 混合策略 | 最近几轮保留原文+更早的压缩成摘要 | 生产环境推荐方案 |
在代码中我加了一个estimateTokens()方法来实时监控Token消耗,让你直观感受"记忆是有成本的":
typescript
estimateTokens(): number {
return this.messages.reduce((sum, msg) => {
const text = typeof msg.content === "string"
? msg.content
: JSON.stringify(msg.content);
return sum + Math.ceil(text.length * 1.5);
}, 0);
}难点②:Message类型不是纯字符串
踩坑现场: 我一开始直接response.content当字符串用,结果运行时报错------因为content的类型是string | string[][],不一定是纯字符串。
typescript
// ❌ 危险写法:可能不是string
memory.addAIMessage(response.content);
// ✅ 安全写法:做类型判断
const aiContent =
typeof response.content === "string"
? response.content
: JSON.stringify(response.content);
memory.addAIMessage(aiContent);为什么会这样? 因为LLM的回复可能包含多模态内容(文本+图片),所以LangChain把content设计成了联合类型。在纯文本场景下它确实是string,但TypeScript的类型系统要求你处理所有可能性。
这个坑很小,但不处理就会在运行时炸。TypeScript的意义就在于此------把运行时的惊喜变成编译时的提醒。
难点③:系统提示词的地位
你可能会想:系统提示词不也是一条消息吗?为什么clear()要特殊处理它?
因为系统提示词和对话历史的作用完全不同:
- 系统提示词:定义AI是谁、怎么行为,是"人设"
- 对话历史:记录你们聊了什么,是"经历"
清空对话=失忆,但失忆不等于人格重塑。你的AI助手忘了你们聊过什么,但它还是那个助手,不会突然变成一个厨师。
typescript
clear() {
const systemPrompt = this.messages[0]; // 保留人设
this.messages = systemPrompt ? [systemPrompt] : [];
}难点④:环境变量与模型切换
踩坑现场: 一开始代码里硬编码了模型名gpt-4o-mini,后来想换模型时发现要改好几处代码。
解决: 统一用环境变量,一处配置,全局生效:
typescript
// ❌ 硬编码:换模型要改代码
const model = new ChatOpenAI({ modelName: "gpt-4o-mini" });
// ✅ 环境变量:换模型只改.env
const model = new ChatOpenAI({
modelName: process.env.OPENAI_MODEL || "gpt-4o-mini",
});改.env就行,业务代码零修改。同样的思路,如果你用兼容OpenAI协议的服务,加一行OPENAI_BASE_URL即可,代码不用动。
五、总结------我们学到了什么
核心知识点
| 知识点 | 一句话总结 |
|---|---|
| LLM无状态 | 每次调用都是全新对话,模型本身没有记忆 |
| 记忆的本质 | 每次把完整聊天历史一起发给模型 |
| Buffer记忆 | 最朴素的记忆策略------全量保留,简单但Token消耗线性增长 |
| LangChain三层架构 | 核心抽象+集成实现+应用组合,换模型不换代码 |
| Message类型体系 | System/Human/AI三种消息角色,让模型理解对话结构 |
记忆策略演进路线
css
Buffer(全量) → Window(滑动窗口) → Summary(摘要压缩) → 混合策略
超级简单 控制长度 保留关键信息 生产级方案下一步,我们会在Buffer记忆的基础上实现RAG------让AI不仅能记住对话,还能"查阅资料"。从"靠谱秘书"进化成"带资料库的研究员"。
本文是「LLM应用开发」系列第一篇。下一期:给AI装上外挂知识库------RAG检索增强从零实战。