摘要
工业物联网的真正瓶颈,往往不在于单种数据"存不下"或"算不快",而在于不同类型的数据"各管各的"------传感器时序数据在时序库里,设备台账在关系库里,运维日志在 Elasticsearch 里,AI 模型特征向量又在外部平台上。跨库关联、跨格式对齐、跨频率融合,每一步都是工程噩梦。本文从工业物联网"数据孤岛"这一普遍痛点出发,深入剖析 DolphinDB 多模存储引擎(TSDB、OLAP、PKEY、IMOLTP、VECTORDB)如何在一个平台内统一管理时序、关系、内存和向量等多种数据形态,结合 AsOf Join 多频对齐、2000+ 内置函数库内融合计算、丰富的外部数据源生态和云边协同架构,展示 DolphinDB 如何帮助工业企业实现从"数据孤岛"到"数据融合"的跃迁。以能源电力、车联网、地震监测、海关政务等领域的真实落地案例为佐证,探讨工业物联网数据融合的实践路径。
一、引言:工业数据"各管各的"困境
在工业物联网领域,一个被忽视但极其普遍的现象是:企业花大力气把各类数据都采回来了,但它们被锁在不同的"牢笼"里。
走进一家大型水电站的控制中心,你会发现数据分散在至少四五个系统中:SCADA 系统管理实时传感器数据,设备台账存在 Oracle 或 MySQL 中,运维日志存在 Elasticsearch 或 HDFS 里,历史趋势分析又依赖一套独立的时序数据库。当工程师需要回答一个看似简单的问题------"编号为 GT-03 的水轮机组,在过去 24 小时内振动异常时,其维护记录和所在流域水文数据分别是什么?"------他需要跨越至少三个不同的数据库,手动导出、拼接、对齐数据。这个过程可能耗时数小时,而答案的时效性早已丧失。
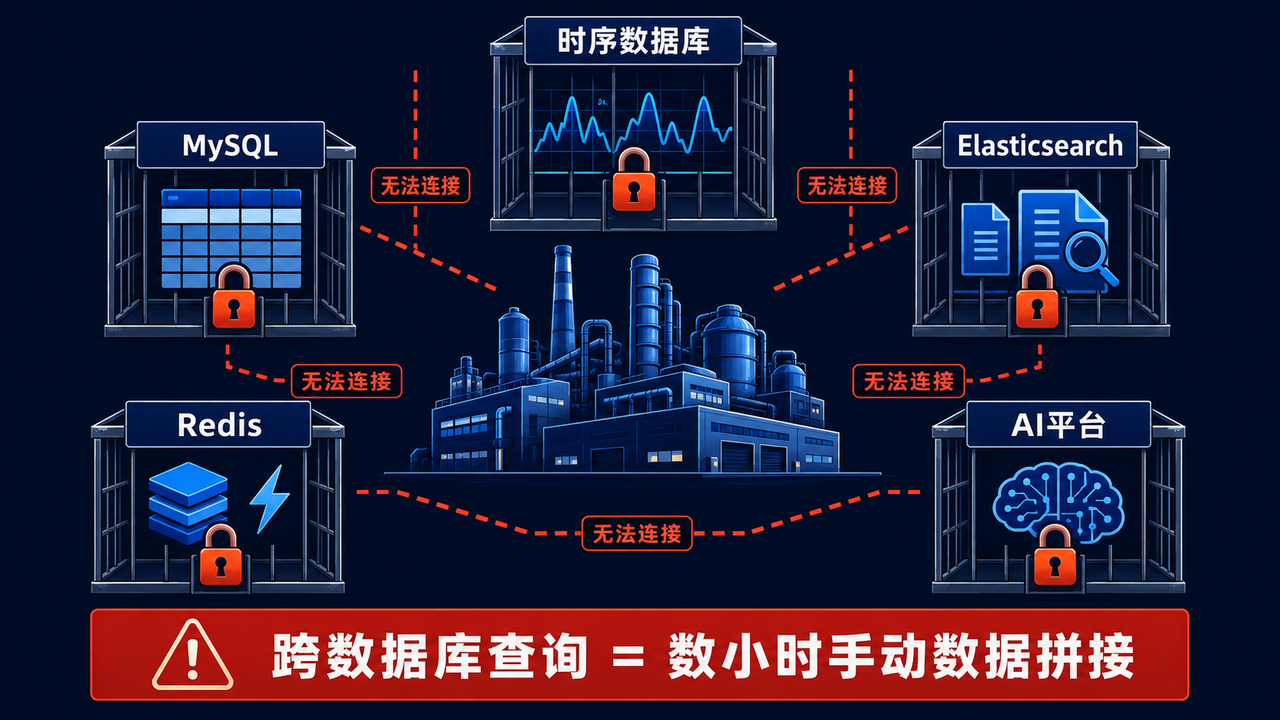
这不是个别现象。在车联网、智能制造、能源电力、地震监测等行业,"数据孤岛"是数字化转型的头号障碍。问题的本质在于:工业物联网的数据是多模态的------传感器产生高频时序数据,设备管理系统维护关系型台账,AI 平台消费向量特征数据------而传统数据库被设计为管理单一类型的数据。用 5 种数据库管理 5 种数据,然后试图把它们"拼"在一起做分析,这条路注定崎岖。
DolphinDB 选择了一条不同的路:它不是又一个时序数据库,而是一个多模融合的数据平台------在一个系统内,用不同的存储引擎统一管理时序数据、关系型数据、内存数据和向量数据,让跨类型的联合分析变得原生且高效。
二、孤立之源:工业数据为什么"拼不到一起"?
2.1 难题一:不同类型数据的"语言不通"
工业场景中存在至少五类核心数据:
- 高频时序数据:温度、压力、振动、电流等传感器数据,采样频率从毫秒到秒级不等,数据量极大
- 关系型业务数据:设备台账、工单记录、人员排班等,需要主键唯一性保证和事务支持
- 实时状态数据:需要毫秒级读写的在线状态,如设备当前运行模式、报警状态等
- AI 特征数据:机器学习模型的嵌入向量,用于相似性检索和在线推理
- 日志与配置数据:运维日志、系统配置等半结构化数据
每种数据都有其最佳的存储方式。高频时序数据适合列式存储压缩,关系型数据需要 B+ 树索引和事务保障,向量数据需要近似最近邻索引。传统方案是"各用各的"------TSDB 存时序、MySQL 存关系、Redis 存实时状态、Milvus 存向量。但问题是:当分析需要跨越这些数据类型时,数据在系统间的搬运成本、格式转换开销和一致性风险,足以抵消单一系统优化的所有收益。
2.2 难题二:不同频率数据的"时间错位"
即使都是时序数据,不同传感器的采样频率也天差地别。一台数控机床的振动传感器以 10kHz 采样,温度传感器以 1Hz 采样,而设备的运行模式切换可能每几分钟才记录一次。当需要分析"振动异常发生时的设备温度和运行模式"时,必须将这些不同频率的数据精确对齐到同一时间点。
传统 Join 操作按照时间戳精确匹配,但在不同频率数据之间,时间戳几乎不可能完全一致。结果要么丢失大量无法匹配的数据,要么被迫降采样到最低频率,白白浪费了高频数据的价值。
2.3 难题三:多源数据的"链路断裂"
工业企业的数据来源多样且分散。以某海关电子口岸为例,数据来自海关、外管、国税、边防检查等多个政府部门,底层技术栈涵盖 MongoDB、Oracle、MySQL 等多种数据库。要将这些异构数据源融合到统一的数仓中进行分析,传统方案需要搭建复杂的 ETL 链路------每接入一个新数据源,就需要开发对应的适配器、编写数据清洗脚本、配置同步任务。链路越长,断裂的风险越大,数据时效性越差。
三、融合之解:DolphinDB 多模引擎如何"一统江湖"?
DolphinDB 对数据融合的理解不是"加一个统一查询层"那么简单,而是在存储引擎层面就实现了多模态数据的原生管理,让不同类型的数据在同一个平台内"出生即融合"。

3.1 五大存储引擎:各有所长、共处一室
DolphinDB 提供了五种存储引擎,覆盖工业物联网场景中的主要数据类型:
TSDB 引擎采用 PAX 行列混存方式,是高频时序数据的最佳载体。在工业场景中,一台设备的振动传感器每秒可产生上万条记录,TSDB 引擎通过有序存储和高效压缩(支持 LZ4、Delta-of-Delta、ZSTD、CHIMP 等多种算法,压缩率可达 4:1 至 10:1),使得海量时序数据的存储和点查性能卓越。某新能源车企每秒 1.8 亿测点的数据写入,正是由 TSDB 引擎承担。
OLAP 引擎采用列式存储,更适合对长时间跨度数据的聚合分析。例如分析过去一年内某台设备的月度能耗趋势,OLAP 引擎可以只读取需要的列,避免全表扫描,大幅提升查询效率。
PKEY 引擎提供主键唯一性保证,支持实时更新和高效查询。这一引擎完美对接了从传统 OLTP 数据库(如 MySQL)通过 CDC(变更数据捕获)同步过来的关系型数据。中核集团某研究院从 MySQL 迁移到 DolphinDB 时,正是 PKEY 引擎保证了关系型数据的平滑过渡。
IMOLTP 引擎是内存数据库引擎,支持事务和 B+ 树索引,应对高频度、高并发的实时更新和查询操作。在工业场景中,设备的实时运行状态、报警确认状态等需要毫秒级读写的场景,IMOLTP 引擎提供了极致的响应速度。
VECTORDB 引擎支持向量数据的索引和近似最近邻搜索。在 AI 场景中,将设备的运行特征提取为向量后存入 VECTORDB,可以快速检索"历史上与当前异常模式最相似的设备运行记录",为预测性维护提供有力支撑。
3.2 AsOf Join:多频数据的"时间缝合术"
前面提到的"时间错位"难题,DolphinDB 用 AsOf Join 给出了一个优雅的解法。
AsOf Join(时序连接)不是按照时间戳精确匹配,而是将低频数据按照最近时间戳对齐到高频数据上。例如,温度传感器每秒采集一次,振动传感器每秒采集一万次------AsOf Join 会为每一条振动数据找到"此刻最近的"温度值,构建出一张完整的多维数据表。

在实际测试中,将 10kHz 的振动数据与 1Hz 的温度数据进行关联,AsOf Join 的性能比传统 Join 提升百倍以上。这意味着"振动异常时温度是多少"这类跨频率关联查询,可以在毫秒级完成------不是事后离线分析,而是实时在线查询。
更重要的是,AsOf Join 在流计算场景下也可以实时执行。高频振动数据与低频温度数据在写入的同时就被"缝合"在一起,为后续的异常检测和状态分析提供了完整的多维数据视图。
3.3 库内融合计算:数据不动、函数动
多模存储解决了"数据住在一起"的问题,但融合分析还需要"计算能力到位"。DolphinDB 内置了超过 2000 个函数,覆盖时序处理、信号处理、统计分析、机器学习等广泛领域,且全部经过向量化优化。配合 SQL-92 标准的支持和多范式编程能力(命令式、函数式、向量式、SQL),开发者能够直接在数据库内完成跨引擎、跨数据类型的联合分析,无需将数据导出到外部计算平台。
某地震台网中心的案例最能说明这一点。该中心需要在每 10 毫秒采集一条的地震波形数据上进行傅里叶变换、小波变换等复杂信号处理,同时关联设备台账数据和 MiniSeed 文件元信息。在 DolphinDB 中,这些操作全部在库内完成------时序数据在 TSDB 引擎中存储,信号处理由内置函数直接执行,无需导出到 MATLAB 或 Python 环境再导入回来。端到端的计算响应延迟控制在毫秒级。
3.4 外部数据源生态:让"搬运"变成"接入"
DolphinDB 提供了丰富的外部数据源接入能力,支持 MQTT、OPC UA/DA、Modbus、IEC 104 等工业协议直接采集,同时通过插件支持从 Kafka、MySQL、Oracle、MongoDB、HDFS 等主流数据平台导入数据。这意味着企业现有的数据资产可以无缝迁移到 DolphinDB 平台,而不需要从零开始。
某海关电子口岸的案例就是典型代表。该机构原有数据分布在 MongoDB、Oracle、MySQL 等多个系统中,数据量达 TB 级。通过 DolphinDB 的多源数据接入能力,将不同业务系统的数据融合到统一的实时数据仓库中,复杂计算和业务逻辑处理的响应时间从分钟级缩短到秒级,同时数据处理链路极大简化。

3.5 云边协同:分散数据的"虚拟集中"
工业设备的地理位置分散是常态。某水电企业在多个水电站部署了超过 200 万个测点,各电站相距数百公里。DolphinDB 的云边协同架构让分散在各电站的数据实现"虚拟集中"------各边缘端 DolphinDB 节点独立处理本地数据,云端节点进行全量汇聚与融合分析,边缘端脚本由云端统一下发。对于企业而言,数据在物理上是分散的,但在逻辑上是统一的------无论查询哪个电站的数据,使用的是同一套 SQL、同一套函数、同一套分析逻辑。
在数据同步层面,DolphinDB 支持跨集群的异步复制,以事务为单位进行数据同步,保障不同集群之间的数据一致性。某世界 500 强企业利用这一能力搭建了异地多中心数据中台,集群间同步超 4000 张数据表,单表数据量最高达千亿级,百万级数据的同步延迟控制在毫秒级。
四、融合之证:真实场景中的数据融合实践
4.1 案例一:某海关电子口岸------从"多库并存"到"一库融合"
背景:该海关电子口岸自研数据仓库平台,采用 MongoDB、Oracle、MySQL 等产品构建离线数仓方案,使用 Java 实现业务逻辑。数据量达到 TB 级,最大单表记录数达 10 亿级别,业务逻辑复杂,平台运行效率极其低下。
挑战:
- 多源数据接入:需要兼容多数据源,能够从不同的数据源接入数据
- SQL 兼容:兼容标准 SQL,支持复杂的多表关联
- 高性能低时延:对复杂查询实现秒级响应
- 缩短数据处理链条:减少运维和开发成本
方案:利用 DolphinDB 丰富的外部数据源生态,支持 Kafka、MQTT、MySQL、Oracle 等多种数据源的写入,通过合理的分区策略和向量化编程,实现多业务系统数据融合和高效实时处理。流计算框架支持毫秒级更新插入(Upsert)和逻辑删除(Delete),格式化清洗规则函数化自定义。
成效:
- 复杂计算和复杂业务逻辑处理的秒级响应
- 极大简化数据处理链路,多源异构数据统一入仓
- 降低人员投入和运维成本
这个案例的核心价值在于"融合"------过去分散在 MongoDB、Oracle、MySQL 中的数据,现在统一汇聚到 DolphinDB 一个平台中。跨系统的关联查询不再需要导出拼接,而是直接在库内完成,效率提升何止十倍。
4.2 案例二:某地震台网中心------多模态地震数据的实时融合分析
背景:每 10 毫秒采集一条地震监测记录,需要将 MiniSeed 格式的波形数据、设备元信息、历史地震数据等多种模态的数据进行联合分析和实时预警。
挑战:
- MiniSeed 格式数据的解析和结构化存储
- 毫秒级延迟的实时异常检测、定位和预测
- 波形数据与元信息的跨模态关联
方案:基于 DolphinDB 构建地震波形分析预警架构。数据分区列式存储,采用时间 + ID 组合分区,多线程并行操作。内置 FilterPicker、RTSeis 和 TensorFlow 插件,支持在 DolphinDB 内部直接进行复杂的波形数据异常检测和预测,实现存储、计算、AI 推理的全链路融合。
成效:
- 毫秒级计算响应延时
- 从 MiniSeed 解析到异常检测到预测预警,全流程在库内闭环
- 大幅提升全流程效率
这个案例展示了数据融合的极致形态:不仅时序数据与关系型元信息在一个平台内联合分析,连 AI 模型推理都在数据库内部完成。地震预警这一对实时性要求极高的场景,得益于数据不需要在系统间搬运,端到端延迟被压缩到了毫秒级。
4.3 案例三:某世界 500 强企业------异地多中心的跨地域数据融合
背景:该企业随着业务规模扩大,需要在多个城市(上海、北京、深圳)之间实现数据的实时同步和统一分析,集群间同步超 4000 张数据表,单表数据量最高达千亿级。
挑战:
- 海量历史数据同步:跨集群数据一致性保障
- 增量同步实时性:新增数据需要实时同步
- 多中心协同分析:统一的查询和分析框架
方案:利用 DolphinDB 异步复制框架搭建异地多中心数据中台。只需简单参数配置即可建立多个集群之间的主从关系,以事务为单位进行数据同步,同时支持 DDL 和 DML 操作。DolphinDB 还具备完善的备份恢复机制,支持历史数据迁移。
成效:
- 百万级数据毫秒级同步延迟
- 极大提升集群容错性和容灾能力
- 降低用户请求响应时间,实现多中心数据"逻辑统一"
4.4 案例四:中核集团某研究院------从 MySQL 到 DolphinDB 的跨类型数据迁移
背景:原基于 MySQL 搭建的工业组态监控体系,随仪表测点增多和采样频率增加,MySQL 无法满足海量数据的并发写入和毫秒级查询需求。
挑战:
- 从关系型数据库到时序数据库的平滑迁移
- 保证迁移过程中数据的完整性和一致性
- 在新平台上实现原有功能并超越
方案:基于 DolphinDB 搭建新的组态监控体系。PKEY 引擎保证了从 MySQL CDC 同步过来的关系型数据的完整性,TSDB 引擎处理海量时序数据的存储和查询。依托 DolphinDB 强大的函数库和流计算框架,简化了数据流处理流程,减轻了部署架构。
成效:
- 单表百亿数据量级下的毫秒级查询响应
- 实现了对 MySQL 的平滑替代,无需重写上层应用
- 系统高可用性和容灾能力得到保障
这个案例展示了多模存储在数据迁移场景中的独特优势:PKEY 引擎保证关系型数据"原封不动"地迁移过来,TSDB 引擎则承载了原来 MySQL 根本无法胜任的高频时序数据。两种数据类型在同一个平台内自然融合,无需额外的数据搬运。
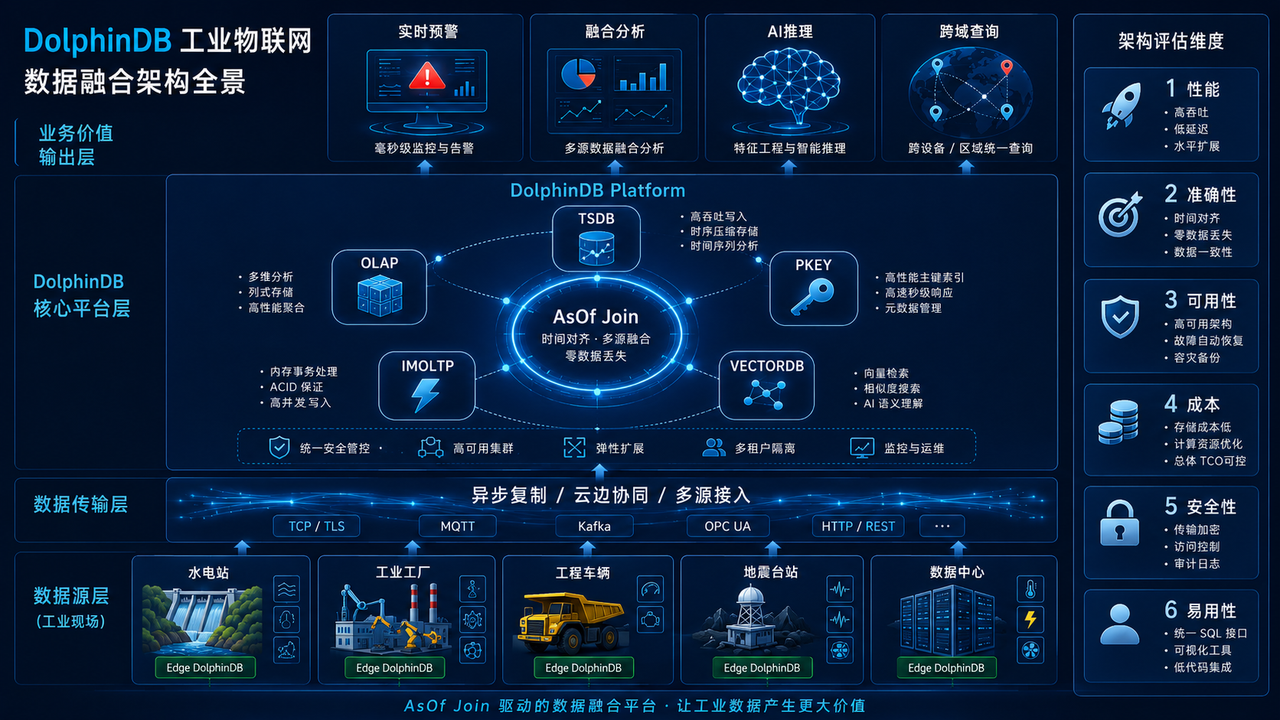
五、选型思考:如何评估时序平台的数据融合能力?
基于以上分析与案例,对于正在选型工业物联网数据平台的企业,我提炼出评估"数据融合能力"的六个维度:
维度一:多模存储是否原生支持? 如果一个平台只能存储时序数据,那么关系型数据、向量数据就必须存储在外部系统中,"融合"无从谈起。原生多模存储是数据融合的基础设施。
维度二:跨频率数据关联是否高效? 工业场景中不同传感器频率差异巨大,AsOf Join 等时序关联能力决定了跨频率分析的性能上限。如果每次关联都需要全表扫描,实时融合就是空谈。
维度三:外部数据源生态是否丰富? 企业的存量数据分散在多种系统中,如果新平台无法便捷地接入现有数据源,"融合"就变成了"重头再来"。丰富的数据接入生态是融合的加速器。
维度四:库内计算能力是否足够? 数据融合之后需要联合计算。如果分析能力不足,数据还是要导出到外部平台,那么"存储融合"的价值就大打折扣。丰富的内置函数和编程接口是融合的价值兑现。
维度五:云边协同是否完善? 工业设备的地理分散是常态。如果边缘端和云端是两套技术栈,那么"融合"在物理层面就被割裂了。统一的云边架构是分布式融合的保障。
维度六:数据一致性如何保障? 跨集群、跨地域的数据同步如果缺乏事务级别的保障,融合的代价就是一致性的牺牲。ACID 事务和异步复制框架是大规模融合的安全网。
DolphinDB 在这六个维度上都给出了完整的答案。它不是在某个单点上做到极致,而是用多模存储引擎、AsOf Join、丰富的函数库、外部数据源生态和云边协同架构,构建了一个从存储到计算到分析的全链路数据融合平台。
六、结语
工业物联网的数据融合,不是一个可选的"锦上添花",而是一个必须解决的"生死攸关"。
当传感器数据、设备台账、运维日志、AI 模型特征分别锁在不同的数据库中时,所谓的"工业智能"只能停留在演示层面------因为真正的智能需要多维数据的联合分析,需要跨频率数据的精确对齐,需要从存储到计算到推理的全链路融合。
DolphinDB 的多模引擎给出了一条可行的路径:在一个平台内统一管理时序数据、关系型数据、内存数据和向量数据,用 AsOf Join 解决多频对齐,用 2000+ 内置函数实现库内融合计算,用丰富的外部数据源生态实现存量数据的无缝迁移,用云边协同架构解决地理分散的融合难题。
从海关多源数据融合的秒级响应,到地震波形数据与 AI 推理的毫秒级闭环,再到千亿级数据的异地多中心同步------这些案例印证了一个事实:当数据不再"各管各的",工业物联网的真正价值才能被释放。
工业数据的下一站,不是更多的数据库,而是更好的融合。这或许就是 DolphinDB 多模引擎给工业物联网最重要的启示。